美團外賣搜索基于Elasticsearch的優化實踐–圖文解析
前言
美團在外賣搜索業務場景中大規模地使用了 Elasticsearch 作為底層檢索引擎,隨著業務量越來越大,檢索速度變慢了,CPU快累趴了,所以要進行優化。經過檢測,發現最耗資源(性能熱點)的地方是倒排鏈的檢索與合并,**Run-length Encoding(RLE)**技術設計實現了一套高效的倒排索引,使倒排鏈合并時間降低了 96%。將這一索引能力開發成了一款通用插件集成到 Elasticsearch 中,使得 Elasticsearch 的檢索鏈路時延降低了 84%。
離線數倉:
離線數倉之所以被稱為“離線”,是因為它處理的數據不是實時的,而是在一定時間周期內進行計算和存儲。這與實時數據倉庫(例如實時流數據)不同,后者可以立即處理和分析數據。所以,離線數倉更像是一個歷史數據的“存儲室”,用于長期分析和決策。
知名:Snowflake,Amazon Redshift,Google BigQuery等
近線檢索:
近線檢索是一種根據數據的相似性,在數據庫中尋找與目標數據最相似的項目的技術。這個技術認為,特征數據的值約相近,之間的相似性就越高。
B端檢索與C端檢索:面向商家,企業,團隊的檢索。舉例:商城app首頁的搜索框是面向普通用戶的C端檢索,用來檢索商品。而商城后臺的運維等人員,商家檢索該平臺或同類別網店的歷史數據進行決策分析等操作,屬于B端檢索。
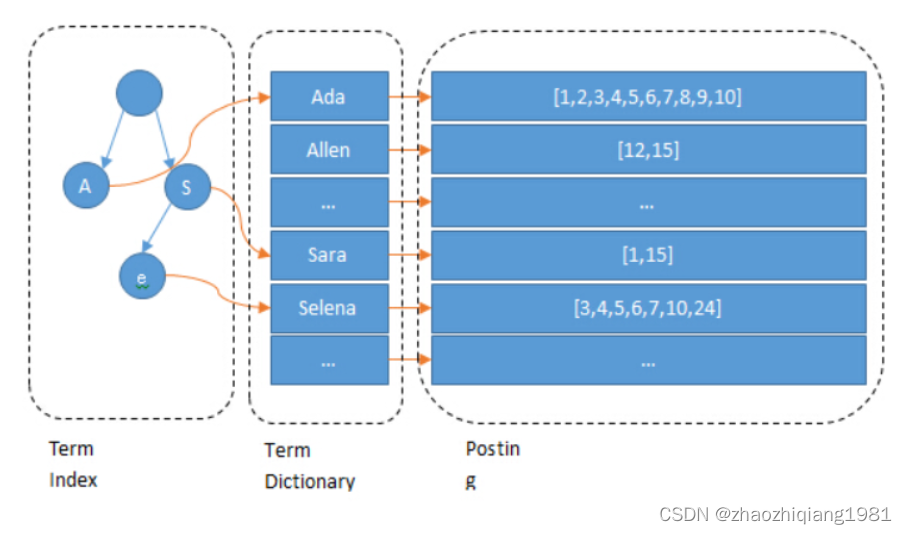
倒排索引:
文中多次提到的 Posting List就是指的倒排鏈
通過一個單詞,找到含有單詞有關系的文章,是倒排索引
下圖中包括程序員,產品經理,運維以及對應的docId的表就是倒排所以,其中每一個分詞(或叫做詞條,文中的Term)所以應的DocId就是該Term的倒排鏈:

為了增加查詢效率,節省磁盤與內存資源,增加了字典樹 term index概念:
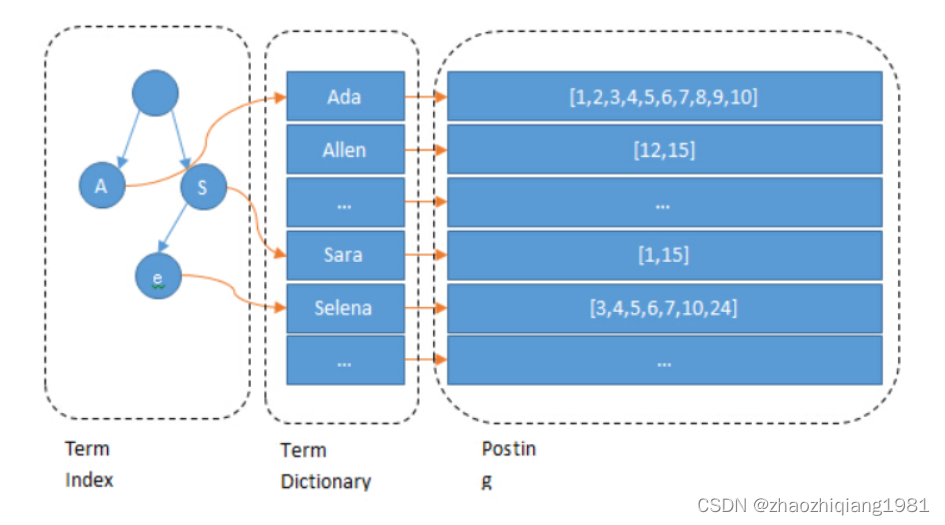
倒排鏈的合并:
如果用戶的查詢包含多個關鍵詞,搜索引擎會合并這些關鍵詞的倒排列表,找到同時包含這些關鍵詞的文檔。

背景
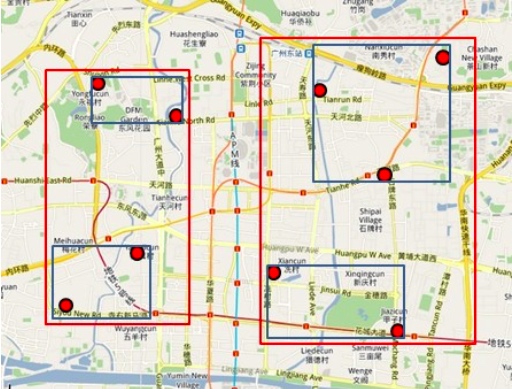
當前,外賣搜索主要為 Elasticsearch,具有較強的 Location Based Service(LBS) 依賴(其實就是地理位置有限制,太遠了送不了),即用戶所能點餐的商家,是由商家配送范圍決定的。對于每一個商家的配送范圍,大多采用多組電子圍欄進行配送距離的圈定,一個商家存在多組電子圍欄,并且隨著業務的變化會動態選擇不同的配送范圍,電子圍欄示意圖如下:
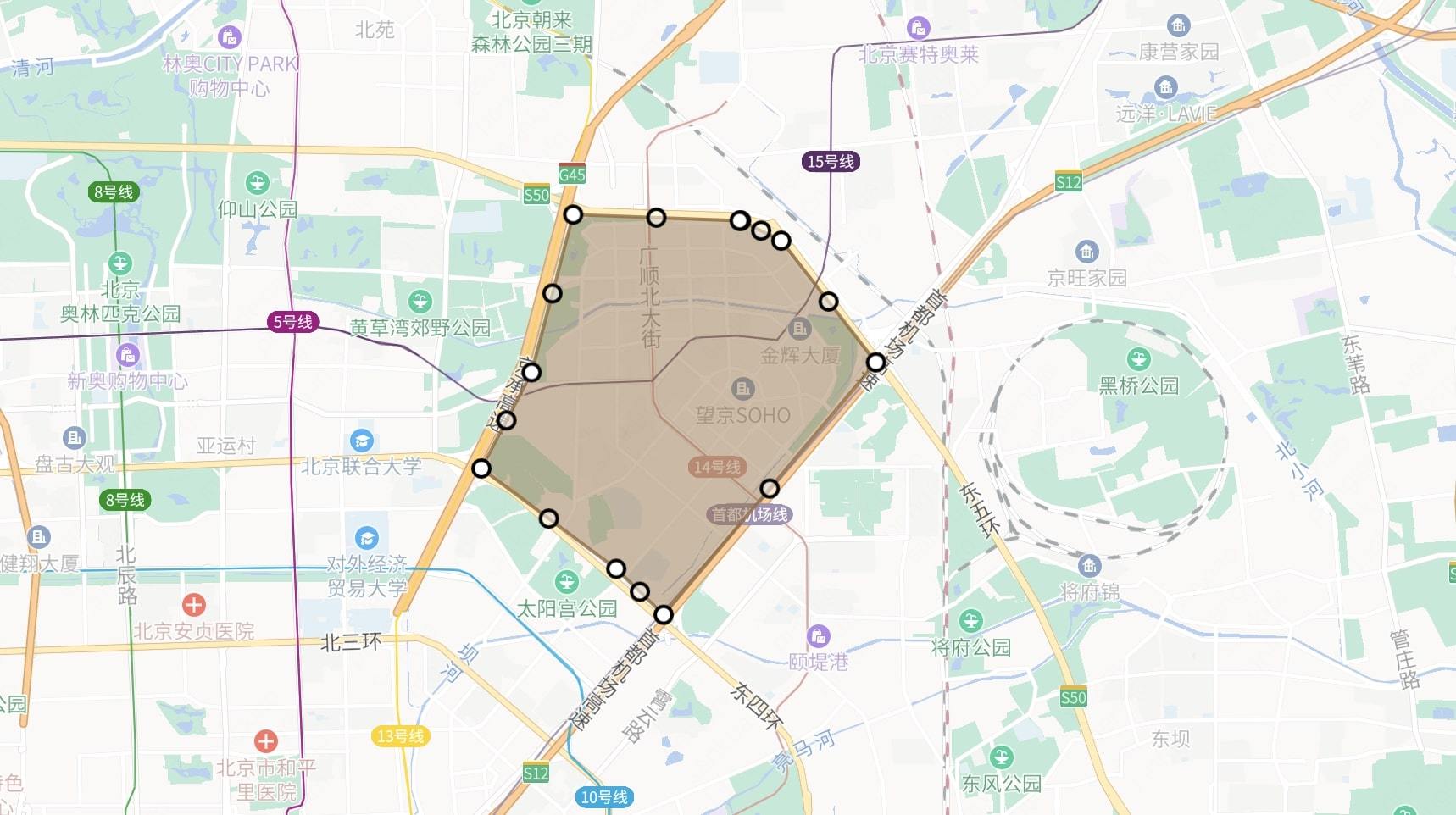
- 電子圍欄:
- 定義:電子圍欄是一種虛擬的地理邊界,可以通過定位系統或其他位置服務技術來創建。
- 作用:商家可以使用電子圍欄來限定配送范圍,確保配送員在指定區域內進行配送。以及用來限制用戶在自己的可配送范圍內,搜索到可配送范圍內的商家對應的商品。
- 多組電子圍欄動態選擇不同的配送范圍:
- 定義:商家可能需要不止一個電子圍欄來定義不同的配送區域,用來應對可能會隨著時間和情況變化的業務需求。
- 例子:商家在城南開了一家烤串店,如果城北的用戶點餐外賣,則會觸發更大范圍的電子圍欄,提高配送費用等。
原文:
考慮到商家配送區域動態變更帶來的問題,通過上游一組 R-tree 服務判定可配送的商家列表來進行外賣搜索。因此,LBS 場景下的一次商品檢索,可以轉化為如下的一次 Elasticsearch 搜索請求:
POST food/_search
{"query": {"bool": {"must":{"term": { "spu_name": { "value": "烤鴨"} }//...},"filter":{"terms": {"wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上萬}}}}//...
}
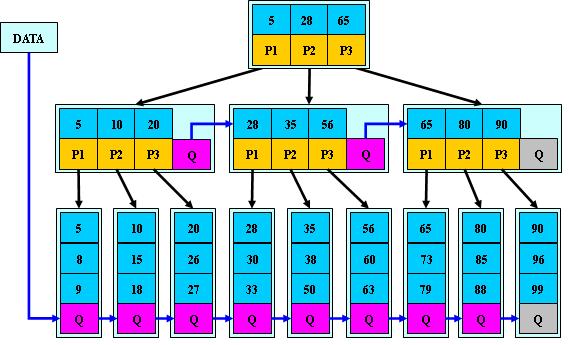
R-tree
B樹向多維空間發展的另一種形式
先說B樹:
圖片來自百度百科
比如我要查找id是38的數據,范圍在28-65之間,選中28的p2,發現了范圍在35-65之間,選擇35的p2最后快速找到了38,而且是比SSD還要快的多的順序查找。
R樹和B樹有點像:
圖片來自百度百科
A和B是兩個大的區域,里面包含了若干小區域,在R樹中可以通過下圖呈現(注意我們發現A和B其實里面有重疊的部分):
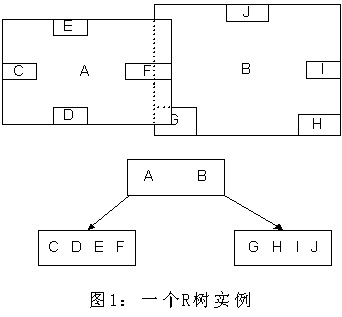
用地圖的例子來解釋,就是所有的數據都是餐廳所對應的地點,先把相鄰的餐廳劃分到同一塊區域,劃分好所有餐廳之后,再把鄰近的區域劃分到更大的區域,劃分完畢后再次進行更高層次的劃分,直到劃分到只剩下兩個最大的區域為止。要查找的時候就方便了。
下圖以及進一步詳細解釋的內容來自:
https://blog.csdn.net/wzf1993/article/details/79547037
最后在解釋一下如果發現重合區域怎么辦:
-
S1:[查找子樹] 如果T是非葉子結點,如果T所對應的矩形與S有重合,那么檢查所有T中存儲的條目,對于所有這些條目,使用Search操作作用在每一個條目所指向的子樹的根結點上(即T結點的孩子結點)。
簡單說就是兩個同級別非葉子節點有重合區域了,檢測已存儲對應的子節點,檢查指向到底是哪一個。
-
S2:[查找葉子結點] 如果T是葉子結點,如果T所對應的矩形與S有重合,那么直接檢查S所指向的所有記錄條目。返回符合條件的記錄。
簡單說就是父子節點有重合,檢查父節點的條目看看有沒有這個子節點
這里要注意的是Elasticsearch本身并不提供R-Tree功能,原文中也說了是上游提供的功能,需要先在程序中找到用戶所在區域的葉子節點,再找到里面的所有商家,之后進行搜索。
POST food/_search
{"query": {"bool": {"must":{"term": { "spu_name": { "value": "烤鴨"} }//...},"filter":{"terms": {"wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上萬}}}}//...
}
代碼中的wm_poi_id可能是使用到了Elasticsearch中的父子關系映射,用來模擬R-Tree,為了更好理解,下面例子中是一家店與這家店菜品的模擬
PUT /food/restaurants/1
{"name": "烤鴨之家","address": "北京市朝陽區XXX路123號","phone": "123-456-7890","wm_poi_id": 1
}POST /food/dishes
{"wm_poi_id": 1, // 父文檔的 wm_poi_id"spu_name": "北京烤鴨","price": 88.0,"description": "傳統的烤鴨,外酥里嫩,美味可口。"
}POST /food/dishes
{"wm_poi_id": 1,"spu_name": "蔥爆牛肉","price": 58.0,"description": "香辣的蔥爆牛肉,下飯絕佳。"
}原文:對于一個通用的檢索引擎而言,Terms 檢索非常高效,平均到每個 Term 查詢耗時不到0.001 ms。因此在早期時,這一套架構和檢索 DSL(ES的領域專用語言) 可以很好地支持美團的搜索業務——耗時和資源開銷尚在接受范圍內。然而隨著數據和供給的增長,一些供給豐富區域的附近可配送門店可以達到 20000~30000 家,這導致性能與資源問題逐漸凸顯。這種萬級別的 Terms 檢索的性能與耗時已然無法忽略,僅僅這一句檢索就需要 5~10 ms。
挑戰及問題
倒排鏈查詢流程
1,從內存中的 Term Index 中獲取該 Term 所在的 Block 在磁盤上的位置。
“Block” 指的是磁盤上存儲相關詞條信息的數據塊。這個概念與數據庫中的"塊"或"頁"(通常是數據存儲的基本單位)有些相似。在 Elasticsearch 中,倒排索引由多個這樣的 Block 組成,每個 Block 包含了一組詞條的信息,以及這些詞條在文檔中出現的位置。為了提高性能,同時又節約內存空間,所以不會在內存中直接存儲詞條對應的信息,而是存儲一個block的位置,通過這個位置到硬盤上去查找具體的位置以及數據信息。
2,從磁盤中將該 Block 的 TermDictionary 讀取進內存。
Block存儲的所有詞條信息被統稱為TermDictionary,Elasticsearch 在處理查詢時,通過加載整個 Block 來提高效率,因為通常情況下,相關的詞條會被存儲在相同或相近的位置。在TermDictionary中,存放的基本都是該詞條以及和該詞條相關的詞條內容。
3,對倒排鏈存儲格式的進行 Decode,生成可用于合并的倒排鏈。
倒排鏈的存儲格式通常是壓縮的,為了使用這些數據,需要先對它們進行解碼也就是Decode。解碼后就可以得到一個可用于查詢合并的倒排鏈,包含了所有包含該詞條的文檔ID的列表。
原文:
可以看到,這一查詢流程非常復雜且耗時,且各個階段的復雜度都不容忽視。所有的 Term 在索引中有序存儲,通過二分查找找到目標 Term。這個有序的 Term 列表就是 TermDictionary ,二分查找 Term 的時間復雜度為 O(logN) ,其中 N 是 Term 的總數量 。Lucene 采用 Finite State Transducer(FST)對 TermDictionary 進行編碼構建 Term Index。FST 可對 Term 的公共前綴、公共后綴進行拆分保存,大大壓縮了 TermDictionary 的體積,提高了內存效率,FST 的檢索速度是 O(len(term)),其對于 M 個 Term 的檢索復雜度為 O(M * len(term))。
公共前綴:如果多個詞條有相同的開始部分,比如 “search”, “seek”, 和 “seem” 都以 “se” 開頭,FST 會將 “se” 存儲一次,然后鏈接到不同的后續字符。
公共后綴:同樣地,如果多個詞條在結尾處相同,FST 也會對這些后綴進行合并存儲。
通過這種方式,FST 可以大大減少存儲每個獨立詞條所需的空間,因為它只存儲每個唯一的前綴和后綴一次。
O(len(term)):因為前綴與后綴的原因,查找速度與詞條的長度有關。
前綴類似于這張圖。
倒排鏈合并流程
在經過上述的查詢,檢索出所有目標 Term 的 Posting List 后,需要對這些 Posting List 求并集(OR 操作)。在 Lucene 的開源實現中,其采用 Bitset 作為倒排鏈合并的容器,然后遍歷所有倒排鏈中的每一個文檔,將其加入 DocIdSet 中。
偽代碼如下:
Input: termsEnum: 倒排表;termIterator:候選的term
Output: docIdSet : final docs set
for term in termIterator: //遍歷倒排表中的每一個詞條if termsEnum.seekExact(term) != null: //如果存在,不為空docs = read_disk() // 磁盤讀取docs = decode(docs) // 倒排鏈的decode流程,解壓縮,找到這個詞條的倒排鏈for doc in docs:docIdSet.or(doc) //代碼實現為DocIdSetBuilder.add。 //將倒排鏈中存放的doc信息存入docIdSet
end for
docIdSet.build()//合并,排序,最終生成DocIdSetBuilder,對應火焰圖最后一段。
原生es倒排鏈合并問題:
假設我們有 M 個 Term,每個 Term 對應倒排鏈的平均長度為 K,那么合并這 M 個倒排鏈的時間復雜度為:O(K * M + log(K * M))。 可以看出倒排鏈合并的時間復雜度與 Terms 的數量 M 呈線性相關。在我們的場景下,假設一個商家平均有一千個商品,一次搜索請求需要對一萬個商家進行檢索,那么最終需要合并一千萬個商品,即循環執行一千萬次,導致這一問題被放大至無法被忽略的程度。
下圖說明了查找,讀取,合并的火焰圖確實存在高耗時。
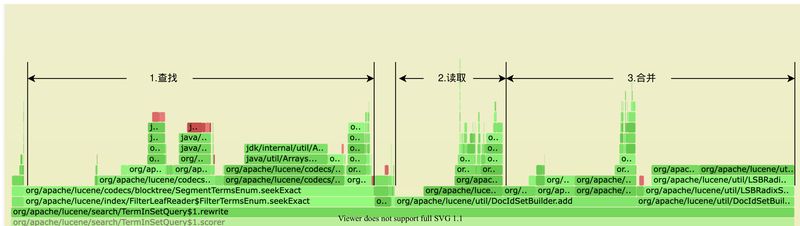
PS火焰圖

技術探索與實踐
倒排鏈查詢優化
默認使用FST本身也是不錯的選擇,但在原文提到的背景中有些不適用,原因如下:
考慮到在外賣搜索場景有以下幾個特性:
- Term 的數據類型為 long 類型。(可以巧妙利用long類型特有的壓縮算法)
- 無范圍檢索,均為完全匹配。
- 無前綴匹配、模糊查找的需求,不需要使用前綴樹相關的特性。(用不著FTS的特性)
- 候選數量可控,每個商家的商品數量較多,即 Term 規模可預期,內存可以承載這個數量級的數據。(我家內存夠大)
最終方案:時間換空間,選擇了查詢復雜度O(1)的哈希表LongObjectHashMap,和傳統的HashMap相比,LongObjectHashMap 可以存儲更多的數據,對Long類型友好。

倒排鏈合并
原生實現
RoaringBitmap
原文:
當前 Elasticsearch 選擇 RoaringBitMap 做為 Query Cache 的底層數據結構緩存倒排鏈,加快查詢速率。
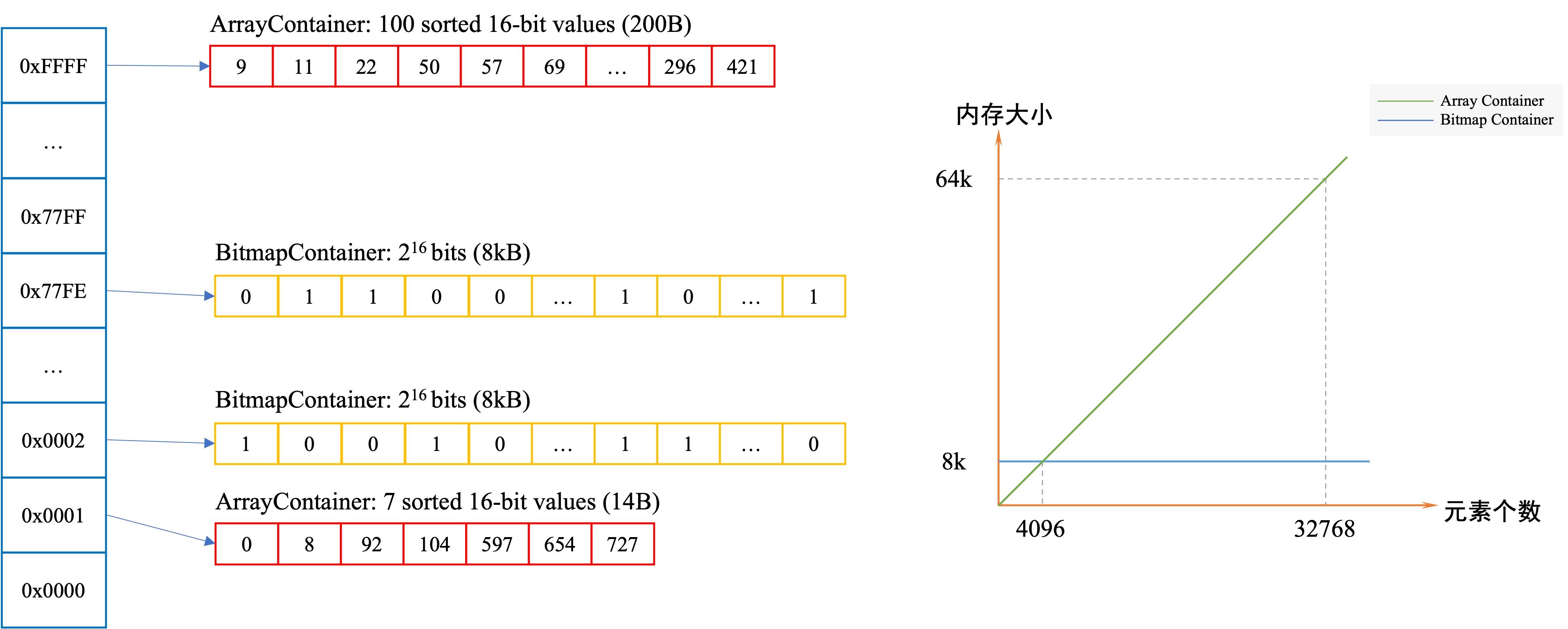
RoaringBitmap 是一種壓縮的位圖,相較于常規的壓縮位圖能提供更好的壓縮,在稀疏數據的場景下空間更有優勢。以存放 Integer 為例,Roaring Bitmap 會對存入的數據進行分桶,每個桶都有自己對應的 Container。在存入一個32位的整數時,它會把整數劃分為高 16 位和低 16 位,其中高 16 位決定該數據需要被分至哪個桶,我們只需要存儲這個數據剩余的低 16 位,將低 16 位存儲到 Container 中,若當前桶不存在數據,直接存儲 null 節省空間。 RoaringBitmap有不同的實現方式,下面以 Lucene 實現(RoaringDocIdSet)進行詳細講解:
如原理圖中所示,RoaringBitmap 中存在兩種不同的 Container:Bitmap Container 和 Array Container。
圖3 Elasticsearch中Roaringbitmap的示意圖
這兩種 Container 分別對應不同的數據場景——若一個 Container 中的數據量小于 4096 個時,使用 Array Container 來存儲。當 Array Container 中存放的數據量大于 4096 時,Roaring Bitmap 會將 Array Container 轉為 Bitmap Container。即 Array Container 用于存放稀疏數據,而 Bitmap Container 用于存放稠密數據,這樣做是為了充分利用空間。下圖給出了隨著容量增長 Array Container 和 Bitmap Container 的空間占用對比圖,當元素個數達到 4096 后(每個元素占用 16 bit ),Array Container 的空間要大于 Bitmap Container。
針對上面原文的解析:
要了解RoaringBitmap,首先要簡單了解下Bitmap:
假設要緩存這樣一些數字到Bitmap中: 2,5,7,9

首先,創建一個數組,長度為要緩存數字的最大值+1,例子中最大數字是9,則創建的數組長度為9+1=10
數組中只存放0或1,為1表示存放的數字存在,0表示不存在
因為數組下標是從0開始的,實際的值就是數組值為1的下標值+1
Bitmap有一個很嚴重的缺陷就是:如果數據稀疏,比如1,2,3,999999999999,一共四個數字,但要創建一個特別特別大的數組來存放,中間有一大段數組值為0,數據稀疏問題需要通過RoaringBitmap來解決。
RoaringBitmap優化Bitmap
1.將存儲容器分為Bitmap Container(位圖容器) 和 Array Container(數組容器),數據量小于4096使用數組容器
數據量大于4096使用位圖容器
其中的位圖容器和傳統bitmap特性相似,用來存儲應對數據稠密場景,而稀疏數據通過數組存儲。在儲存時,RoaringBitmap算法會安排數組容器適當的占用位圖容器中的稀疏空間,從而更小有效的利用內存。
原文中的分桶,高16位,低16位又是什么意思呢:
假設我們有一些整數:65537, 65538, 131073。在 RoaringBitmap 中,這些數會被分為高16位和低16位:
對于 65537(二進制為 00000001 00000000 00000001),高16位是 00000001 00000000(即1),低16位是 00000001(即1)。
對于 65538(二進制為 00000001 00000000 00000010),高16位是 00000001 00000000(即1),低16位是 00000010(即2)。
對于 131073(二進制為 00000010 00000000 00000001),高16位是 00000010 00000000(即2),低16位是 00000001(即1)。
在這個例子中,65537 和 65538 會被放入編號為1的"桶"中,而 131073 會被放入編號為2的"桶"中。這樣,當我們需要查找一個數是否存在時,我們先看它的高16位,確定去哪個"桶"查找,然后在那個"桶"里用低16位找到具體的數。這種方法使得存儲更加緊湊,檢索也更快速。
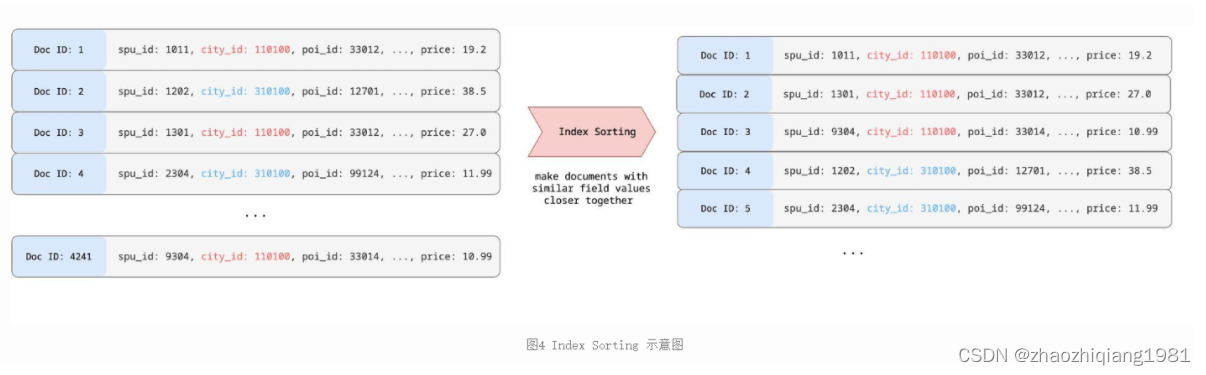
Index Sorting
這個比較好理解,就是說Elasticsearch 從 6.0 版本開始在索引階段可以配置多個字段進行排序了。
基于 RLE 的倒排格式設計
Run-Length Encoding
原理:對于完全連續數字{1,2,3,4,5,6,7,8,9,10} —>經過RLE壓縮為—>{1,10} 也就是{start,length}
RoaringBitmap對于美團外賣場景仍然需要進一步優化,通過使用Index Sorting對多個字段進行排序后得到一個突破性進展,即通過一些字段進行排序后,商家的商品ID完全連續了。
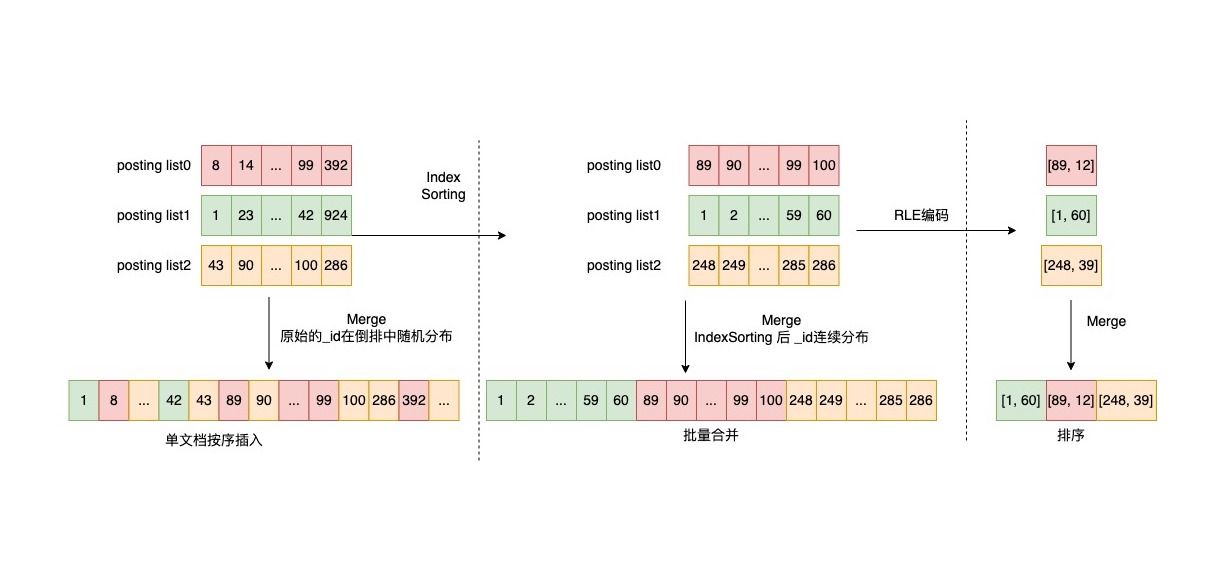
在 bitmap 這一場景之下,主要通過壓縮連續區間的稠密數據,節省內存開銷。以數組 [1, 2, 3, …, 59, 60, 89, 90, 91, …, 99, 100] 為例(如下圖上半部分):使用 RLE 編碼之后就變為 [1, 60, 89, 12]——形如 [start1, length1, start2, length2, …] 的形式,其中第一位為連續數字的起始值,第二位為其長度。
同時還對倒排鏈的合并做了修改,由原來的單文檔按序插入優化為批量合并,最終通過Index Sorting排序后,通過RLE編碼對完全連續的數字進行了壓縮:
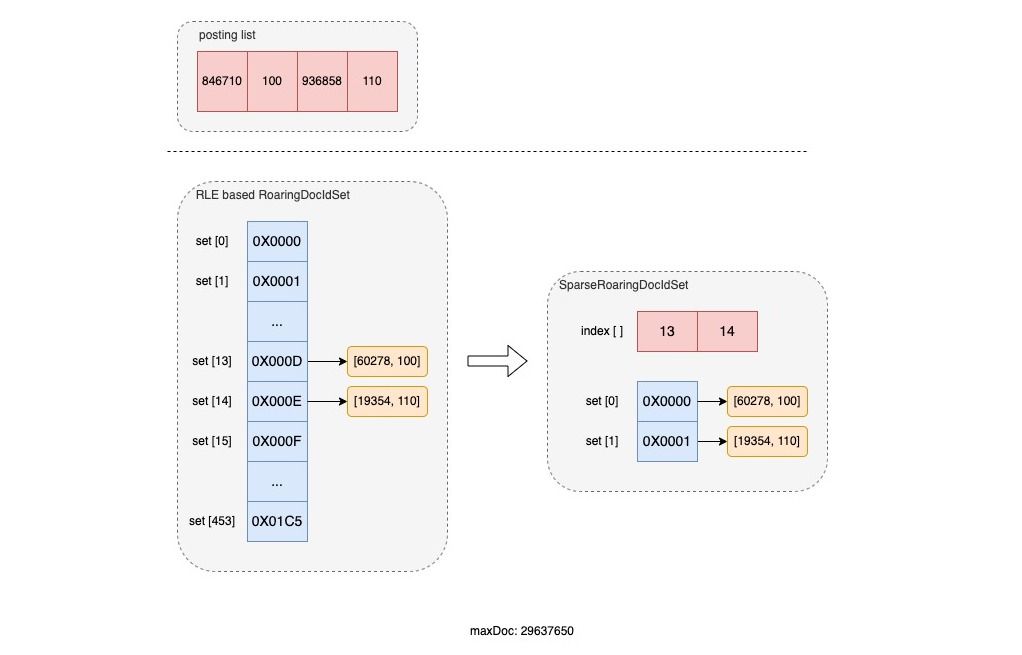
SparseRoaringDocIdSet
RoaringBitmap中存在分桶操作,如下圖,可能存在有些桶是空的,美團技術團隊通過實現SparseRoaringDocIdSet,額外使用一組索引記錄所有有值的 桶的 位置。
原文也介紹了ES也通過算法優化節約開銷了:在 Elasticsearch 場景上,RoaringDocIdSet 在申請 bucket 容器的數組時,會根據當前 Segment 中的最大 Doc ID 來申請**,**這種方式可以避免每次均按照 Integer.MAX-1 來創建容器帶來的無謂開銷。
經過上述修改,倒排鏈合并耗時節約了96%
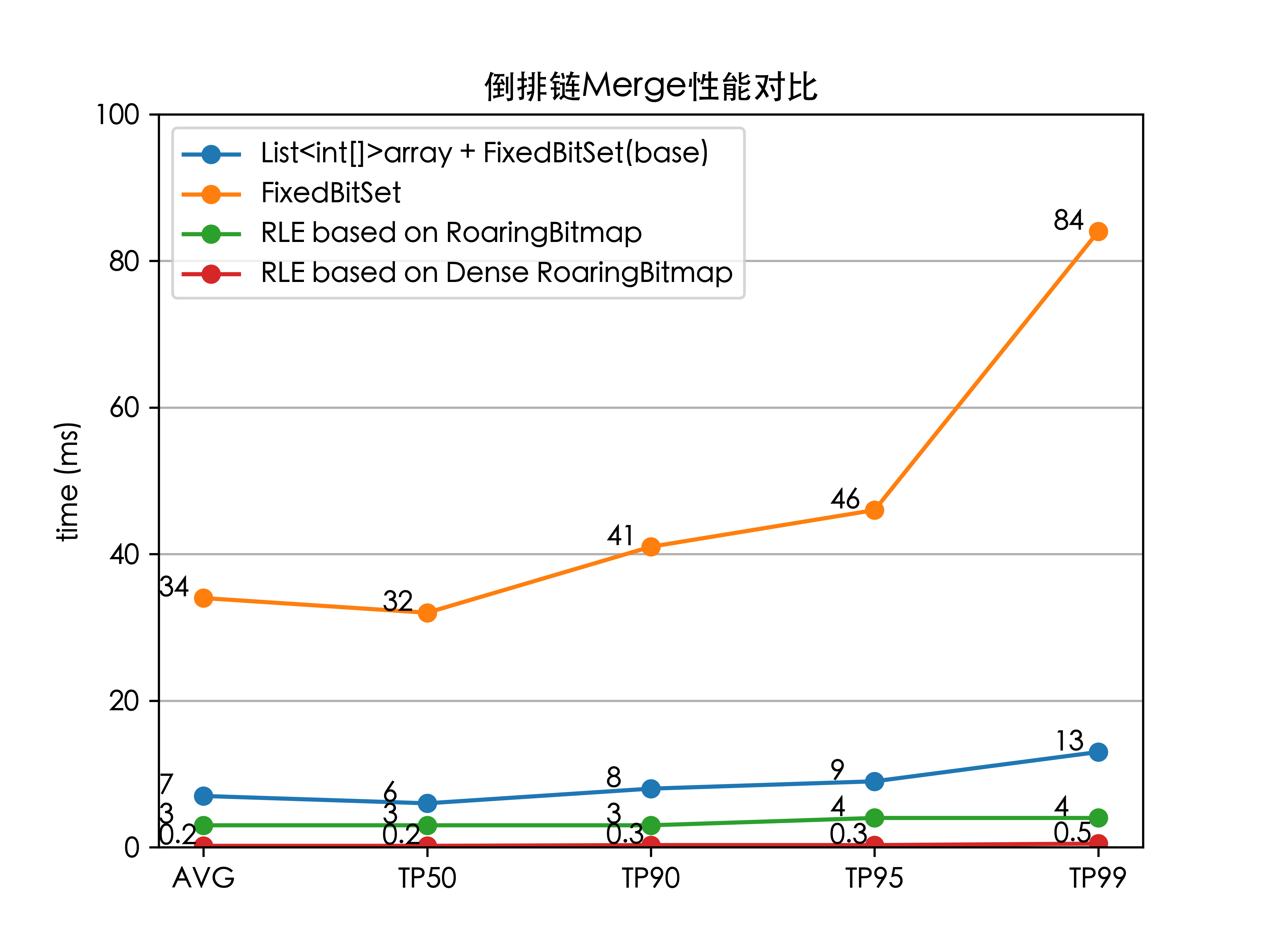
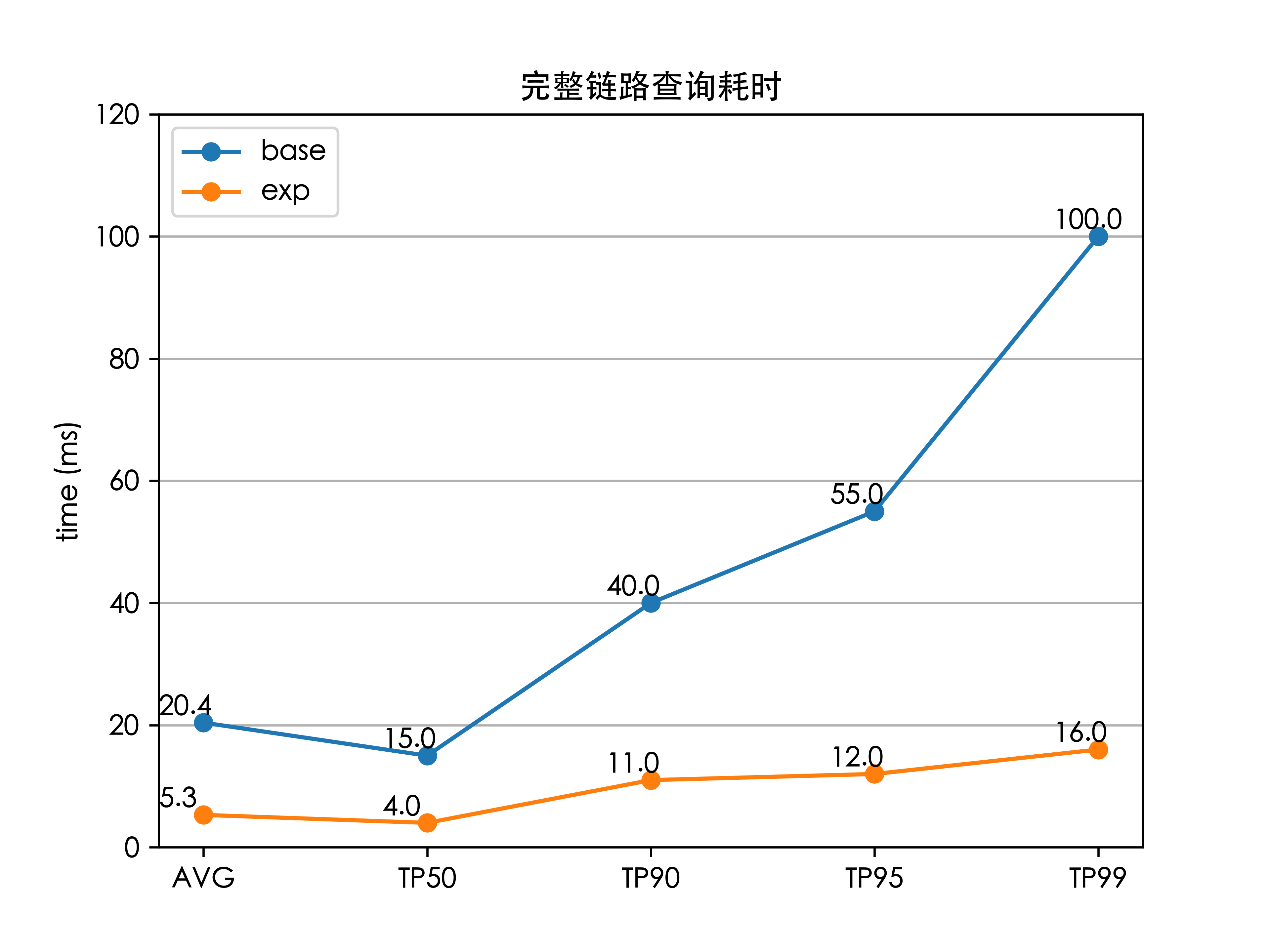
最終將上述優化集成到ES中,以及做了若干調整上線測試后,全鏈路的檢索時延(TP99)降低了 84%(100 ms 下降至 16 ms),解決了外賣搜索的檢索耗時問題,并且線上服務的 CPU 也大大降低。
位置。
原文也介紹了ES也通過算法優化節約開銷了:在 Elasticsearch 場景上,RoaringDocIdSet 在申請 bucket 容器的數組時,會根據當前 Segment 中的最大 Doc ID 來申請**,**這種方式可以避免每次均按照 Integer.MAX-1 來創建容器帶來的無謂開銷。
[外鏈圖片轉存中…(img-TzaAhAdI-1719651983203)]
經過上述修改,倒排鏈合并耗時節約了96%
[外鏈圖片轉存中…(img-JsIhX5W7-1719651983204)]
最終將上述優化集成到ES中,以及做了若干調整上線測試后,全鏈路的檢索時延(TP99)降低了 84%(100 ms 下降至 16 ms),解決了外賣搜索的檢索耗時問題,并且線上服務的 CPU 也大大降低。

![[SAP ABAP] 數據字典](http://pic.xiahunao.cn/[SAP ABAP] 數據字典)


——策略模式)

代碼實踐 -卷積神經網絡-21多輸入多輸出通道)

![[leetcode hot 150]第一百二十二題,買賣股票的最佳時機Ⅱ](http://pic.xiahunao.cn/[leetcode hot 150]第一百二十二題,買賣股票的最佳時機Ⅱ)
)
在現代計算中的應用與挑戰(研究論文框架))








代碼實踐 -計算機視覺-47轉置卷積)