1. 中華人工智能研究中心,鄭州。 2. 鵬程實驗室,深圳。 3. 上海數學與交叉學科研究所,上海。 4. 中國科學院計算技術研究所,北京。 5. 寧波人工智能產業研究所,寧波。 6. 滑鐵盧大學計算機科學學院,加拿大安大略省渥太華。 7. 大連理工大學數學科學學院,大連。?
nature machine intelligence
Lossless data compression by large models | Nature Machine Intelligence

數據壓縮是一項基礎性技術,能夠實現信息的高效存儲與傳輸。然而,經過 80 年的研究與發展,傳統壓縮方法正逐漸接近其理論極限。與此同時,大型人工智能模型應運而生,這些模型通過在海量數據上訓練,能夠 “理解” 各種語義信息。直觀來看,語義能夠簡潔地傳遞數據的含義,因此大型模型有望為壓縮技術帶來革命性變革。
本文提出了一種名為 LMCompress 的新方法,該方法利用大型模型進行數據壓縮。LMCompress 在文本、圖像、視頻和音頻這四種媒體類型上打破了所有以往的無損壓縮記錄。它將圖像壓縮領域 JPEG-XL、音頻壓縮領域 FLAC 以及視頻壓縮領域 H.264 的壓縮率降低了一半,并且在文本壓縮方面達到了 zpaq 壓縮率的近三分之一。我們的研究結果表明,模型對數據的理解越好,其壓縮效果就越顯著,這揭示了理解與壓縮之間存在著深刻的聯系1。
無損數據壓縮是一項關鍵技術,它能確保壓縮后的數據可以被完美重構。在可執行程序、文本文檔、基因組學、密碼學以及多媒體存檔或制作等領域,無損數據壓縮都不可或缺2。
目前已開發出多種無損壓縮方法,例如 7z(參考文獻 1)、FLAC、PNG 以及無損 H.264(參考文獻 4)/H.265(參考文獻 5)。這些方法在很大程度上局限于香農 80 多年前建立的信息論框架。它們依靠各種可計算特征,如復雜的規則和變換,來識別并消除數據中的冗余。經過 80 年的研究,這類方法已達到其性能極限3。
隨著大型模型的出現,一場深刻的變革拉開了序幕。大型模型的原理可追溯至 20 世紀 60 年代提出的著名的所羅門諾夫歸納法 7。與定義可計算特征不同,大型模型通過大量數據來逼近不可計算的所羅門諾夫歸納法 8。通過這種方式,大型模型實現了對數據的理解,就像我們在日常生活中所做的那樣,從而能夠實現高效壓縮4。
基于上述觀察,我們提出了一種新的壓縮方法,即利用大型模型理解各類數據并進而對其進行壓縮(總體概述見圖 1)。
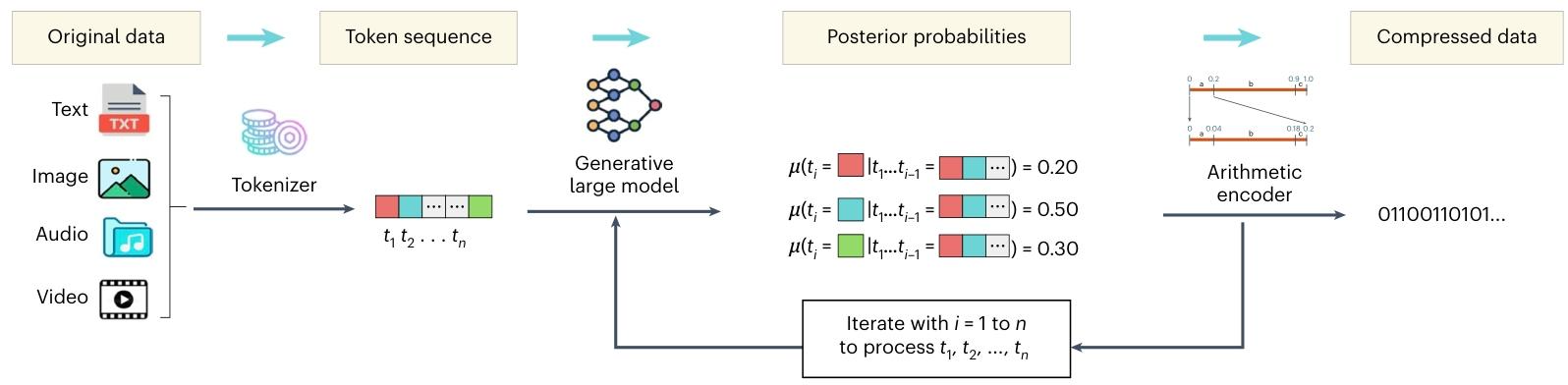
圖1?LMCompress 轉換為一系列令牌。然后,該令牌序列被輸入至圖1 | 我們的LMCompress架構。首先,原始數據是生成式大型模型,該模型會輸出每個令牌的預測分布。 最后,算術編碼基于預測分布對原始數據進行無損壓縮。令牌化工具和生成式大型模型可能會根據數據類型的不同而有所差異。
這是?LMCompress(基于大模型的無損壓縮方法)的工作流程圖?,清晰展示了如何用生成式大模型對文本、圖像、音頻、視頻等數據進行無損壓縮,拆解步驟如下:
1. 原始數據(Original data)
涵蓋文本(Text)、圖像(Image)、音頻(Audio)、視頻(Video)等不同類型的數據,是壓縮的輸入源頭。
2. 令牌化(Tokenizer → Token sequence)
通過 “令牌化工具(Tokenizer)”,把原始數據轉換成令牌序列(Token sequence,即?t?, t? … t??)?。
-
簡單理解:類似把文本拆成單詞、圖像 / 音頻拆成特征片段,讓大模型能 “讀懂” 數據,是統一處理不同數據類型的基礎。
3. 生成式大模型(Generative large model)
接收令牌序列,輸出后驗概率(Posterior probabilities)?,即基于前面令牌(t?…t????),預測下一個令牌?t??出現的概率(比如紅、藍、綠塊的概率分別是 0.20、0.50、0.30 )。
-
核心邏輯:大模型通過學習海量數據,“理解” 數據規律,用概率量化這種理解,為壓縮做準備。
4. 算術編碼(Arithmetic encoder → Compressed data)
依據大模型輸出的概率,用算術編碼器(Arithmetic encoder)?對原始數據無損壓縮,最終輸出二進制壓縮結果(如?01100110101…?)。
-
關鍵作用:概率越精準(大模型 “理解” 越好 ),壓縮效率越高,實現用更少二進制位存儲原始數據。
整個流程的核心是?“用大模型理解數據規律(概率預測),再用算術編碼實現高效壓縮”?,體現了 “理解驅動壓縮” 的思路
我們之前已獨立發表過相關前期研究 9,DeepMind 團隊也發表過類似工作 10,此外文獻 11 也表達了相似的觀點。從本質上來說,是將數據輸入自回歸生成模型,該模型會生成一系列下一個令牌的概率分布。這些概率分布進而通過算術編碼將原始數據等效轉換為二進制字符串。參考文獻 9 和參考文獻 10 中的研究表明,這種新方法在性能上遠超 7z 等常用的頂級壓縮工具數倍。不過,這些研究主要聚焦于文本壓縮領域5。
本文旨在全面驗證 “更好的理解意味著更好的壓縮” 這一觀點。為了增強對不同類型數據的理解,對于圖像和視頻,我們使用圖像生成預訓練 Transformer(GPT)12 而非普通的大型語言模型(LLM);
對于音頻,我們使用在原始音頻字節上預訓練的大型模型 bGPT-audio13;而對于特定領域的文本,我們則采用經過專門微調的大型語言模型。在對數據有了一定理解的基礎上,我們接下來應用算術編碼(詳見補充材料第 4 節)對數據進行壓縮。
無損壓縮實驗表明,通過使用大型語言模型理解數據,我們在包括文本、圖像、視頻和音頻在內的所有類型數據的壓縮率上都有了顯著提升。我們的方法比傳統算法性能高出數倍,并且與使用普通大型語言模型的變體相比,優勢也十分明顯67。
基于此,我們有理由認為理解意味著壓縮。而我們在參考文獻 14 中,在合理的定義下證明了反向關系,即壓縮意味著理解。綜上所述,我們得出了 “理解即壓縮” 這一見解,如圖 2 所示8。

圖2 | 本文的核心見解。該見解指出理解等同于壓縮,搭建起了認知概念與技術概念之間的橋梁 。
結果
我們將壓縮率作為衡量壓縮性能的主要指標,壓縮率指的是壓縮后的數據大小與原始數據大小的比值。在壓縮率這一指標下,數值越低越好。其他指標,如時間成本,將在補充材料第 3 節中討論9。
大多數基線方法,如 H.264 視頻壓縮標準,既可以工作在有損模式下,也可以工作在無損模式下。為了進行公平比較,在我們的實驗中,所有基線方法都被設置為無損模式10。
此外,由于一種算法的壓縮率會因數據集的不同而有所變化,為了減輕潛在的數據偏差帶來的影響,每種壓縮算法都在至少兩個不同的數據集上進行評估11。
圖像壓縮
模型:我們使用圖像 GPT(iGPT)模型作為圖像壓縮的生成式大型模型12。
數據集:我們在兩個基準圖像數據集上評估了 LMCompress 的圖像壓縮性能,這兩個數據集分別是:(1)ILSVRC2017(參考文獻 15),這是一個大規模數據集,包含來自 ImageNet 語料庫的數百萬張分屬數千個類別的帶標簽圖像;(2)CLIC2019 professional16,該數據集是專門為評估圖像壓縮算法而設計的。CLIC2019 包含高質量圖像,這些圖像具有多種不同特征,包括自然場景、紋理、圖案和結構等13。
最終,算術編碼根據預測分布對原始數據進行無損壓縮。針對不同類型的數據,所使用的令牌化工具和生成式大型模型可能會有所不同14。
由于數據集規模過大,我們從其中抽取了 197 張圖像。這些圖像的總大小為 128 兆字節。為了適配 iGPT 的上下文窗口,上下文長度被設置為 102415。
圖 3 展示了基線方法和 LMCompress 在兩個數據集上的壓縮率。結果表明,我們的 LMCompress 在兩個數據集上都顯著優于所有基線方法,將壓縮率降低了一半以上。值得注意的是,DeepMind 的方法也使用了大型模型,即 Chinchilla 系列。但其壓縮率遠高于 LMCompress,這可能是因為 Chinchilla 僅在語言語料庫上訓練,而 iGPT 在圖像語料庫上訓練,能夠更好地理解圖像16。
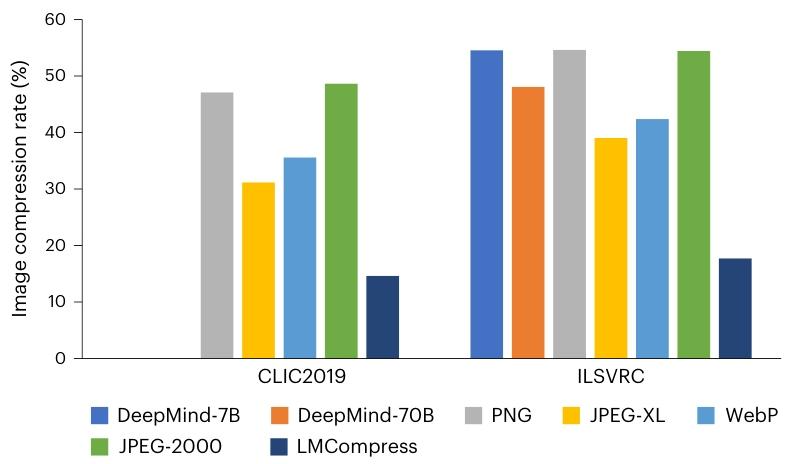
圖 3 | 圖像壓縮率。數據集為 CLIC2019 和 ILSVRC。ILSVRC 上 DeepMind 方法的結果來自參考文獻 10,而 CLIC2019 上的結果為空白,因為既沒有公開此類結果,也沒有公開 Chinchilla 模型25。
視頻壓縮
模型:我們同樣使用 iGPT 作為視頻壓縮的生成式大型模型17。
數據集:我們使用了來自Xiph.org(參考文獻 17)的測試數據,該數據集包含超過 1000 個未壓縮的 YUV4MPEG 格式視頻片段。由于數據集規模龐大,我們選取了一個子集進行測試。該子集包括一個高分辨率視頻片段(4096×2160)、五個靜態場景視頻片段和五個動態場景視頻片段,靜態和動態場景視頻片段均為低分辨率(352×288)。如果一個視頻片段的連續幀變化較小,例如課堂錄制視頻,則稱其為靜態場景視頻;否則,如動作電影,則稱為動態場景視頻。這三類視頻片段的總大小分別為 759 兆字節、162 兆字節和 237 兆字節18。
如圖 4 所示,LMCompress 在兩種視頻類型上都優于所有基線方法。在高分辨率數據上,與基線方法相比,LMCompress 的壓縮率提升了 20% 以上。在低分辨率靜態場景數據上,LMCompress 的壓縮率提升超過 30%。在低分辨率動態場景數據上,LMCompress 依然保持優勢,壓縮率至少提升 30%。我們還觀察到,動態場景比靜態場景更難壓縮。一個可能的原因是,在動態場景視頻片段中,演員的姿勢往往是瞬時變化的,難以理解和預測19。
?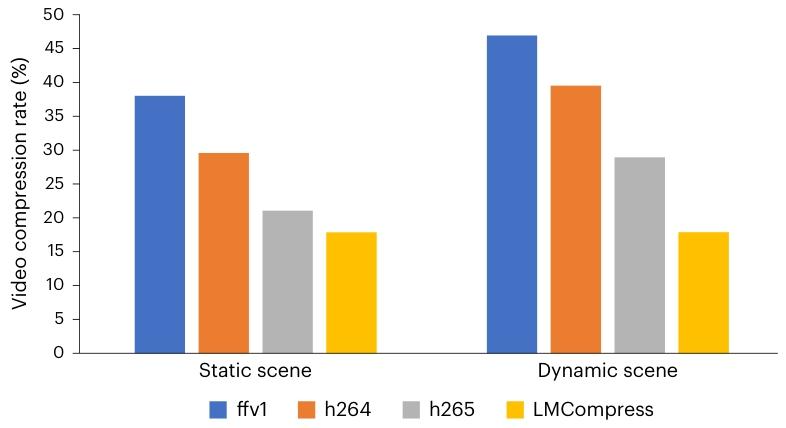
圖 4 | 視頻壓縮率。數據集來自Xiph.org,包括高分辨率和低分辨率視頻片段。低分辨率視頻片段進一步分為 “靜態場景” 和 “動態場景”32。
音頻壓縮
模型:我們使用 bGPT-audio 作為音頻壓縮的生成式大型模型20。
數據集:由于 bGPT-audio 是在 LibriSpeech 數據集 18 上預訓練的,因此我們在另外三個數據集上評估其壓縮性能:LJSpeech19、Mozilla Common Voice 11(參考文獻 20)和 VoxPopuli21。LibriSpeech 和 LJSpeech 都源自 LibriVox 項目,包含近 1000 小時的 16 千赫茲英語有聲書錄音。Mozilla Common Voice 11 是一個多語言語音數據集,由 Common Voice 項目整理而成,在該項目中,用戶通過朗讀提供的文本貢獻語音錄音。VoxPopuli 是另一個多語言語音數據集,由 2009 年至 2020 年期間歐洲議會活動的錄音組成2122。
對于每個數據集,我們首先將音頻文件標準化為 16 千赫茲采樣率、單聲道和 8 位深度。隨后,從每個數據集隨機抽取一段約 100 兆字節的連續音頻用于壓縮。對于 Mozilla Common Voice 11 和 VoxPopuli,采樣僅限于英語錄音。在由 bGPT-audio 處理之前,每個采樣片段都被轉換為原始字節,并分割成最大長度為 8160 字節的塊。這種分割方式與該模型 8192 字節的上下文窗口相適配,以滿足包含 16 字節序列開始令牌和 16 字節序列結束令牌的格式要求23。
結果如圖 5 所示。我們得出兩個觀察結論:(1)LMCompress 在所有數據集上的性能都優于 DeepMind 的方法,這可能是因為 LLaMA 模型系列僅在語言語料庫上訓練,而 bGPT-audio 在音頻數據上訓練;(2)LMCompress 相較于最高效的傳統方法 OptimFROG 具有顯著優勢,甚至超過了基于大型模型的 DeepMind 方法。具體而言,與 OptimFROG 相比,LMCompress 在 LJSpeech、Mozilla Common Voice 11 和 VoxPopuli 數據集上的壓縮率分別降低了 28%、35% 和 23%24。
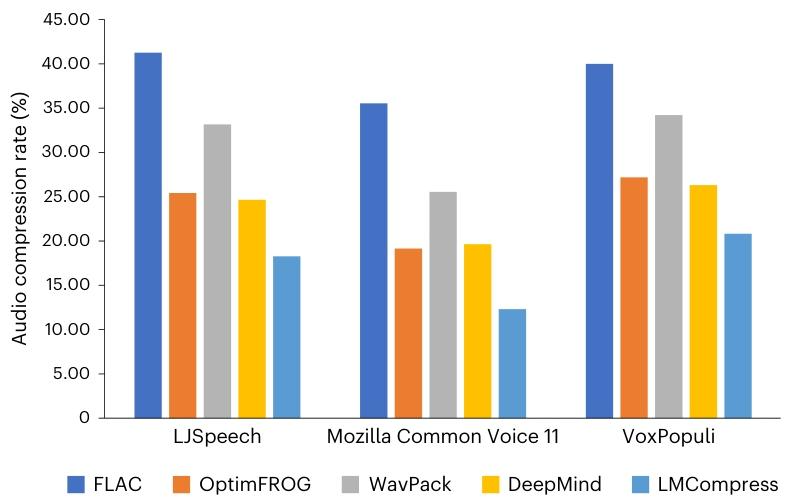
圖 5 | 音頻壓縮率。數據集為 LJSpeech、Mozilla Common Voice 11 和 VoxPopuli。為了與我們的 LMCompress 進行公平比較,DeepMind 方法是在參考文獻 10 的基礎上通過將 LLaMA2 替換為 LLaMA3-8B 進行調整得到的42。
文本壓縮
模型:在 LMCompress 的文本壓縮中,我們選擇通過低秩適應進行領域特定微調的 LLaMA3-8B 作為生成式大型模型26。
數據集:我們用于文本壓縮的基準數據集是 MeDAL22 和 Pile of Law23。MeDAL 是一個醫學領域的數據集,由 2019 年年度基線中發布的 PubMed 摘要創建而成,主要用作理解醫學縮寫的語料庫。另一方面,Pile of Law 是一個法律領域的數據集,它包含從 35 個來源匯編的法律和行政文本27。
在實驗中,我們從 MeDAL 和 Pile of Law 語料庫的 eurlex 分集中提取了前約 180 兆字節的數據。為了適配 LLaMA3-8B 的上下文窗口,上下文長度被設置為 102428。
對于每個領域的數據集,我們使用前 64 兆字節的數據對 LLaMA3-8B 進行微調,接下來的 16 兆字節用于驗證,其余數據用于測試29。
如圖 6 所示,LMCompress 優于所有基線模型,在每個數據集上的壓縮率都不到最佳傳統基線 zpaq 的三分之一。與 LMCompress * 相比,它也展現出更低的壓縮率,這凸顯了領域特定微調在增強文本壓縮效果方面的有效性3031。
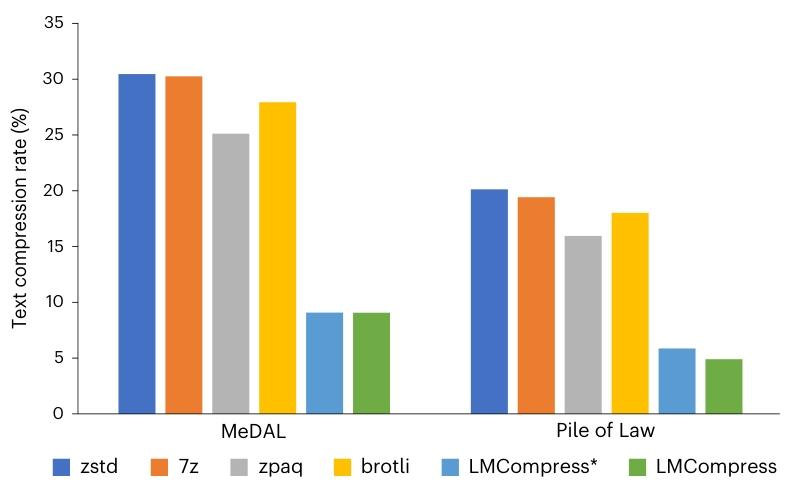
圖 6 | 文本壓縮率。數據集為 MeDAL 和 Pile of Law。LMCompress * 方法是在參考文獻 9、10 的基礎上通過將 LLaMA2-7B 替換為 LLaMA3-8B 進行調整得到的,用于公平比較。它與 LMCompress 類似,但使用未經微調的原始 LLaMA3-8B 模型43。
總之,在各種類型的數據上,LMCompress 的壓縮率都高于所有傳統基線方法和原始基于大型語言模型的算法。這一證據支持了我們的觀點,即更好的理解能帶來更好的壓縮效果33。
討論
過去的通信通常受香農范式支配,編碼效率以香農熵為上限。盡管探索其他可計算特征能夠進一步改善壓縮效果,但大型模型或許可以被視為對不可計算的所羅門諾夫歸納法的逼近,從而開啟壓縮領域新的柯爾莫哥洛夫范式。正如我們所展示的,這種新的無損壓縮方法在各類數據上都取得了顯著的改進。只要大型語言模型在某種數據類型或領域上經過訓練能夠實現良好的預測,它就可以用于以更高的效率對該數據進行壓縮。這種范式使我們能夠系統地理解我們所傳輸的數據,將我們從香農熵的限制中解放出來34。
LMCompress 的一個潛在應用場景是 6G 通信,特別是在衛星帶寬有限的情況下 24。通過在通信兩端利用大型模型進行編碼和解碼,借助對數據的理解,通信性能將得到顯著提升。隨著大型模型作為智能體被專門化,在檢索增強生成技術的輔助下,人工智能將能更好地理解待傳輸的數據。當數據需要加密時,我們的壓縮操作需要在加密之前完成。甚至可以想象,擁有更優模型的一方公開廣播壓縮消息,只有擁有同等模型的一方才能對其進行解密,這可作為第一級加密,且無需額外成本35。
我們已經測試了 LMCompress 的編碼時間成本,結果如補充材料第 2 節所示。LMCompress 的編碼時間成本甚至低于一些傳統方法,這意味著編碼時間并非 LMCompress 在音頻壓縮應用中的障礙。然而,考慮到非音頻數據的時間成本較高,更不用說大型模型高昂的資源和能源消耗,LMCompress 距離實際部署還有一定距離。但這并非長期需要擔憂的問題,原因如下36。
首先,大型模型領域的研究者們正積極致力于推理加速和模型規模縮減的研究。我們有理由預期,在不久的將來會出現快速且強大的大型模型,這將使 LMCompress 能夠在壓縮效率和成本之間取得令人滿意的平衡37。
其次,LMCompress 的編碼過程相對容易加速,因為不同令牌的預測概率分布計算可以并行進行。這種經過編碼加速的 LMCompress 特別適用于靜態存儲場景,在這類場景中,數據需要長期存儲但很少被訪問。靜態存儲的需求正在不斷增長,例如監控數據存檔、醫療記錄和在線交易日志等3839。
方法
無論是有損還是無損的傳統壓縮方法,都依賴可計算函數來表征數據。在此,我們提出 LMCompress,這是一種基于不可計算的所羅門諾夫歸納法的柯爾莫哥洛夫范式壓縮方法 25。大型模型通過不斷輸入數據來逼近所羅門諾夫歸納法。隨著對所羅門諾夫歸納法的逼近程度越高以及對數據的理解越好,壓縮率也會相應提高40。
LMCompress 的流程如圖 1 所示。首先,我們將原始數據分解為一系列令牌。然后,我們將這個令牌序列輸入大型生成模型,該模型會輸出每個令牌的預測分布。最后,我們基于這些預測分布使用算術編碼對原始數據進行無損壓縮。為了增強對各類數據的理解,我們針對不同數據類型使用不同的令牌化工具和生成式大型模型,下文將對其進行更詳細的描述41。
圖像壓縮
我們使用 iGPT 作為圖像的生成式大型模型。選擇 iGPT 主要基于兩個關鍵因素44。
首先,iGPT 是一種大規模視覺模型,它在海量圖像語料庫上進行過訓練,具備對視覺數據的深入理解能力。這使得 iGPT 非常適合用于圖像的分析和處理45。
其次,iGPT 是一種自回歸模型。當輸入一序列像素時,它能夠為序列中的每個像素生成預測概率分布。而概率分布的可獲得性是算術編碼的前提條件46。
由于GPT 的令牌是灰度值,我們將一張圖像視為三個灰度圖像,分別對應 RGB 三個通道,并對每個通道獨立進行壓縮。具體來說,對于每個通道,我們將灰度圖像的各行連接成一個灰度像素序列,將該序列輸入 iGPT,然后將 iGPT 生成的概率分布輸入算術編碼器,完成該通道的壓縮。在解壓縮過程中,每個通道被獨立解壓縮,之后三個通道被合并以重構原始圖像。
然而,由于 iGPT 的上下文窗口有限,一個通道的整個像素序列通常無法一次性輸入 iGPT。因此,我們將該序列劃分為不重疊的片段(其長度稱為上下文長度),每個片段都能適配 iGPT 的上下文窗口。這些片段隨后被輸入 iGPT 并獨立進行壓縮。
視頻壓縮
我們尚未發現公開可用的、能自回歸生成像素級概率分布的大型視頻模型。這一限制可通過利用視頻的固有結構來克服。由于視頻由一系列幀組成,我們將每個幀視為一幅圖像,如 “圖像壓縮” 部分所述,使用 iGPT 逐幀對視頻進行壓縮。具體而言,各幀被獨立壓縮并按原始順序存儲。在解壓縮過程中,各幀被獨立解碼,然后按順序排列,以重構原始視頻。
在現階段,我們選擇不利用幀間信息進行壓縮,主要基于以下兩方面考慮。
首先,不考慮幀間信息可使視頻編解碼器具有可擴展性,能有效避免錯誤隨時間傳播,適用于網絡環境和點對點場景,且支持隨機幀訪問。事實上,一些已確立的視頻標準并不依賴幀間信息,例如 FFV1(參考文獻 26)和 Motion JPEG 2000(參考文獻 27)。
其次,LMCompress 難以有效利用幀間信息。一方面,我們觀察到幀間信息對 LMCompress 的幫助小于幀內信息。另一方面,由于 iGPT 的上下文窗口固定,納入幀間信息會減少幀內信息的使用,從而導致性能下降。
音頻壓縮
音頻本質上是一種時序媒體。一段音頻由一系列時域幀組成,每個幀使用固定數量的字節對特定時間點的振幅信息進行編碼。因此,利用大型自回歸模型對音頻進行壓縮是很自然的選擇。
我們使用 bGPT 模型對音頻進行壓縮,該模型直接在原始音頻字節上進行預訓練。它接收音頻字節序列作為輸入,并為序列中的每個字節生成預測概率分布。這些分布隨后被輸入算術編碼器進行壓縮。
由于 bGPT 的上下文窗口有限,長音頻字節序列將如 “音頻壓縮” 部分所述進行分段壓縮。
文本壓縮
大型語言模型在普通文本壓縮方面已展現出令人印象深刻的能力 9,10。有趣的是,如果待壓縮文本局限于特定領域,大型語言模型有望實現更高效的壓縮。關鍵在于使大型語言模型更好地理解目標領域。這通過在特定領域的文本語料庫上對大型語言模型進行微調來實現,使模型適應該領域的特征。然后,為了壓縮該領域的文本,我們將其輸入經過微調的大型語言模型。該大型語言模型會估計文本中令牌的預測概率,這些概率可被算術編碼用于壓縮。同樣,當大型語言模型的上下文窗口有限時,文本將如 “音頻壓縮” 部分所述進行分段壓縮。
數據可用性
ILSVRC 可通過ImageNet獲取。
CLIC 可通過https://clic.compression.cc/2019/獲取。
LibriSpeech 可通過www.openslr.org/12獲取。
LJSpeech 可通過The LJ Speech Dataset獲取。
Mozilla Common Voice 11 可通過https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0獲取。
VoxPopuli 可通過https://huggingface.co/datasets/facebook/voxpopuli獲取。
MeDAL 可通過https://github.com/McGill-NLP/medal獲取。
Eurlex 可通過https://huggingface.co/datasets/pile-of-law/pile-of-law獲取。
CIPR SIF 可通過Xiph.org :: Derf's Test Media Collection獲取。
代碼可用性
我們的代碼可通過 Code Ocean 獲取,鏈接為https://doi.org/10.24433/CO.9735997.v1(參考文獻 28)。













)



)

