1.引言
傳統搜索系統基于關鍵字匹配,缺少對用戶問題理解和答案二次處理能力。本文探索使用大語言模型(Large Language Model, LLM),通過其對自然語言理解(Natural Language Understanding,NLU)和生成(Natural Language Generation,NLG)的能力,深入理解用戶意圖,并對原始知識點進行匯總、整合,生成更貼切的答案。
大模型能夠回答較為普世的問題,但是若要服務于垂直專業領域,也會存在知識深度、知識準確度和時效性不足的問題。為了滿足汽車行業的需求,團隊投入了大量的時間和精力,構建一個強大的汽車領域知識庫。
2.方案分析
2.1
結合傳統搜索技術構建基礎知識庫
為了構建基礎知識庫,我們可以利用傳統的搜索技術進行查詢。這種方法具有以下優勢:
- 較高的問答可控性:通過使用傳統搜索技術,可以更好地控制問題和回答的準確性。借助精確的搜索匹配,提供更準確和可靠的答案。
- 適應常見知識庫應用場景:不論是處理大規模數據、實現快速查詢還是及時更新,傳統搜索技術都能滿足常見知識庫應用場景的需求。其成熟的技術棧可以提供穩定的性能和功能。
- 技術風險較低:傳統搜索技術已經得到廣泛應用并積累了豐富的實踐經驗,能夠降低技術探索的風險。
同時,利用語言模型 (LLM) 作為用戶與搜索系統之間的交互媒介,能夠充分發揮其強大的自然語言處理能力:
- 實現對用戶請求的理解:LLM可以進行糾錯、關鍵點提取等預處理,從而更好地理解用戶的意圖和問題。
- 對搜索結果進行二次加工:在保證正確性的前提下,LLM可以進一步概括、分析和推理搜索結果,以提供更全面和深入的答案。
結合兩者,能夠優化基礎知識庫的構建和查詢過程,從而更高效地處理業務問題。
2.2
方案設計
? 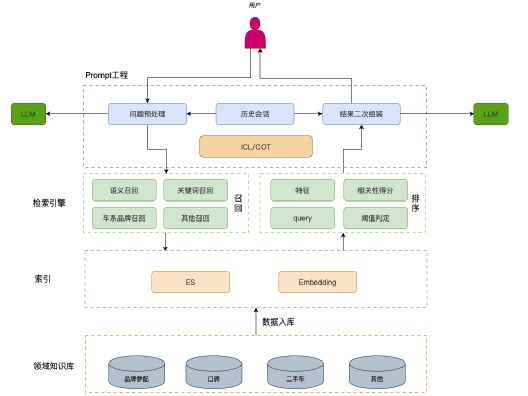
?2.3.1 LLM
LLM(Large Language Model)具有以下主要功能:
- 理解用戶問題:LLM可以對用戶的問題進行理解,包括糾錯和提取關鍵詞等操作。它還能引導用戶提供更多信息,以便更好地理解用戶意圖。
- 對本地檢索結果進行二次處理整合:LLM可以對本地檢索的TopK答案進行二次加工。例如,可以概括、推理等操作,以提供更全面和深入的答案。
- 具備上下文交互能力:LLM能夠處理各種類型的上下文交互,比如車系比較、油耗、加速性能等各類配置相關的問題。它可以根據上下文信息來給出更準確和個性化的回答。
?2.3.2本地搜索系統
-
本地搜索系統解決了查詢匹配的問題,并具備以下功能:
-
ES Search:通過Elasticsearch(ES)的能力,將結構化數據接入系統,提供車系、關鍵詞等的全文檢索功能。
-
Embedding Search:將文字形式的查詢請求轉換為數值向量形式,并接入Milvus等向量數據庫,提供在線相似度查詢功能。
-
去重:在搜索結果中可能存在重復內容,去重操作可以增加大模型接收的信息量,避免重復答案的出現。
-
相關性排序:針對搜索結果,進行相關性排序,選取TopK最相關的答案,以提供更精準和有用的答案。
3.方案實現
3.1
工程架構
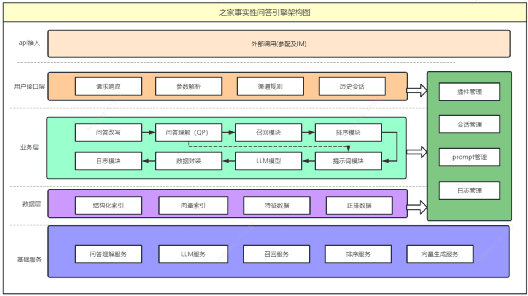
?3.1.1通用模塊
通用模塊包括以下功能:
-
問答改寫:根據用戶輸入信息和上下文歷史信息,對輸入進行改寫,以便更好地理解用戶意圖。
-
問答理解:對經過改寫的用戶輸入進行理解,生成向量、關鍵詞、標簽、分類等信息,為后續處理提供基礎。
-
召回模塊:根據用戶的意圖和實體信息,召回相關內容,以提供更多可能的答案。
-
排序模塊:通過相關性模型,對召回的內容進行排序,選擇與問答最相關的topN內容,并進行數據抽取。
-
提示詞模塊:根據用戶輸入和處理流程,調用不同的提示詞(prompt),為生成對話內容提供指導。
-
LLM模型:根據提示詞和排序生成的相關數據,生成對話內容,以提供給用戶。
-
日志模塊:記錄請求全流程日志,用于模型訓練、性能分析和案例查詢等目的。
?3.1.2管理模塊
管理模塊包括以下功能:
- 會話管理:保存用戶的歷史問答信息,以便在對話過程中進行上下文的保持和引用。
- Prompt管理:配置不同場景下的提示詞信息,以適應不同的用戶需求和使用場景。
- 插件管理:針對不同渠道的用戶,可以使用不同的插件配置,例如IM用戶可以選擇是否訪問產品庫插件。
- 日志管理:管理請求日志、性能日志和結果日志,以便進行日志的存儲、檢索和分析。
?3.1.3知識入庫
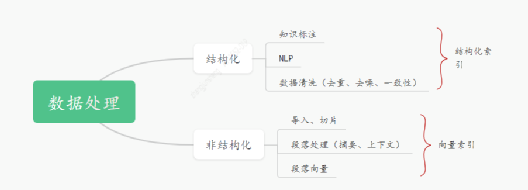
? 目前采用Elasticsearch(ES)作為結構化數據的存儲支持,并利用ES的IK分詞插件實現全文檢索功能。
- 在數據向量化方面,我們使用了大語言模型生成的向量來更準確地捕捉語義相關性。向量化的處理流程如下:
- 數據導入:根據不同的數據源內容,如數據庫、PDF、Word等,進行數據導入操作。
- 數據處理:對目錄、無效信息等進行數據預處理,將文檔切片以便更容易捕捉到語義相關的內容(文章長度越長,語義粒度越粗)。
- 段落處理:基于上下文相關性,生成段落信息。
- 模型處理:選擇適配的模型對段落數據進行向量化。
? 在存儲方面,盡管許多傳統數據庫或存儲中間件已經提供了向量化支持,但專業的解決方案是使用向量數據庫,例如Vearch、Milvus等。本文中我們選擇了Milvus作為向量索引的存儲,根據實際情況可以選擇適合的向量索引數據庫。
3.2
搜索
? 3.2.1召回
當前的召回設計分為兩類:
- **明文召回:**首先,通過API對用戶問題進行解析,提取關鍵詞(例如車系、品牌、分類等)。然后,利用這些關鍵詞從ES索引中進行全文檢索,找到與之最匹配的N條記錄。
- **非明文召回:**在這種方法中,我們使用嵌入模型將用戶問題進行嵌入,并獲取問題向量。接下來,使用問題向量在Milvus中進行檢索,找到與之最匹配的N條記錄。
通過這樣的召回方式,我們可以針對用戶問題進行全文檢索或基于嵌入模型的向量檢索,以獲取與之最相關的記錄。這種設計能夠提高召回的準確性和效率,為后續的答案生成和排序提供更可靠的基礎。
?3.2.2相關性(TopK選取)
目前,我們采用了基于Boosting算法集成的xgboost模型作為相關性模型,其重點在于確保最終結果的穩定性和可控性。這個模型的實現與傳統搜索邏輯類似:
首先,我們將查詢(Query)特征、物品(Item)特征和相關性特征進行組合,同時也考慮了查詢和物品之間的交叉特征。經過特征轉換模塊,如歸一化和取對數等操作,我們將這些特征輸入到xgboost模型中進行預測得分。然后,我們選取TopK個預測結果作為最終的排序。
通過這樣的優化設計,我們能夠更好地利用xgboost模型的強大分類能力,并確保結果的穩定性和可控性。
3.3
大模型
***?*3.3.1模型介紹
? 我們構建了一個汽車領域的大語言模型倉頡,旨在解決看車、買車、用車、換車全流程問題。該模型基于先進的自然語言處理技術和深度學習算法,具備強大的語義理解和信息處理能力。無論是了解車型性能、比較品牌優劣,還是尋找購車建議或了解保養、維修等知識,我們的模型都能提供準確、全面的答案。
?3.3.2模型數據
為了滿足汽車行業的需求,團隊投入了大量的時間和精力,構建一個強大的汽車領域知識庫。下面是是訓練模型使用的部分數據介紹:
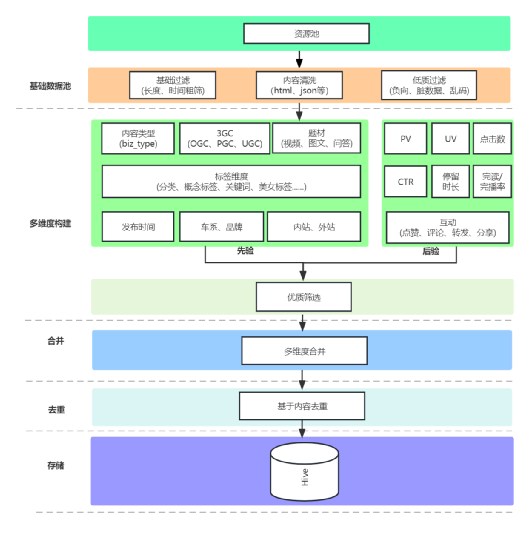
- 口碑文章:我們收集了大量的口碑文章,涵蓋了各種汽車品牌和型號的評價和評論。這些文章包含了消費者對汽車性能、外觀、舒適度等方面的真實反饋,為我們的模型提供了寶貴的參考。
- 問答數據:我們整理了大量的汽車領域問答數據,包括消費者提出的問題以及專家給出的回答。這些問答涉及到汽車購買、保養、維修等方面的知識,為我們的模型提供了廣泛而豐富的信息。
- 參配品庫:我們建立了一個詳盡的汽車參配品庫,包含了各種汽車配件和配置的信息。這些數據可以幫助用戶了解不同汽車型號的配置選項,從而做出更明智的購買決策。
- 百科知識:我們清洗和過濾了大量的百科知識數據,包括來自公開領域的百科的高質量內容。這些數據涵蓋了汽車行業的歷史、技術、發展趨勢等方面的知識,為我們的模型提供了全面而準確的背景信息。
- 網頁和書籍數據:我們還整理了大量的網頁和書籍數據,其中包含了關于汽車領域的專業知識和研究成果。這些數據來源廣泛,覆蓋了汽車行業的各個方面,為我們的模型提供了多樣化的學習材料。
通過對以上數據的深度清洗和過濾,我們的模型已經取得了令人矚目的訓練效果。它能夠準確理解和回答與汽車相關的問題,提供有用的建議和信息,幫助用戶更高效地處理業務問題。
?3.3.3模型訓練
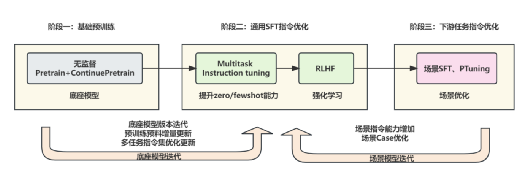
大語言模型訓練采用了一系列創新的技術,包括 LoRA、QLoRA、RoPE scaling 插值、DPO training 以及 dataset streaming。
首先,采用了 LoRA 和 QLoRA 技術,這兩種技術都能有效地減少內存和 GPU 的使用,從而縮短訓練時間。這意味著我們可以更快地處理數據,為公司節省寶貴的時間和資源。
其次,使用了 RoPE scaling 插值技術來擴展 LLaMA 模型的上下文長度。這使得我們的模型能夠更好地理解和處理復雜的語言環境,從而提供更準確的結果。
此外,還采用了 DPO training 技術來簡化 RLHF。通過只需要訓練單獨的 DPO 模型,我們成功地替代了 RLHF 的獎勵模型+PPO 強化模型,解決了 RLHF 訓練極不穩定,超參敏感,調參困難的問題。這使得我們的模型訓練過程更加穩定,也更容易進行參數調整。
最后,使用了 dataset streaming 技術實現大模型流式訓練。這一技術解決了大模型數據集加載內存的開銷問題,明顯提升了訓練速度。這意味著我們可以更快地處理大量數據,帶來更高的效率。
3.4
效果評測
為了滿足汽車領域的特有評測指標,通過構建了汽車領域的專業評測集,自研大模型在汽車領域遠超開源模型,并在通用領域與主流開源模型持平。以下是我們部分評測項:
?3.4.1評估標準
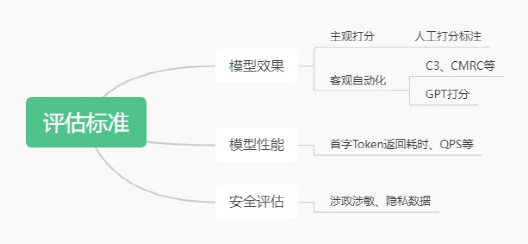
?3.4.2汽車領域評測集
-
exam:涵蓋車系品牌、參配等相關信息,判斷是否能夠準確理解和回答相關問題能力。
-
領域情感:對于用戶在汽車領域的情感表達,判斷情感分析和信息反饋能力。
-
類目:針對汽車領域的不同類目,判斷是否具備豐富的知識和理解能力。
-
auto_rc、qcr_rc:這兩個評測項用于判別汽車領域的閱讀理解任務。
-
領域問答:涵蓋領域內各方向問題
***?*3.4.3通用領域評測集
? 除了在汽車領域的評測,在通用領域的評測集上也做了相關對比評測。以下是一些評測集的示例:
- afqmc:句子對匹配任務,判斷兩個句子之間的關系能力。
- ocnli:自然語言推理任務,對給定的前提和假設進行推理和判斷。
- weibo:微博文本分類任務,對微博文本進行準確分類判斷。
- c3:中文閱讀理解任務,理解并回答相關問題能力。
- cmrc:機器閱讀理解任務,閱讀理解的能力。
- harder_rc:更具挑戰性的閱讀理解任務,判斷應對復雜的問題和場景的能力。
- 通用問答:涵蓋知識問答、寫文章、推理、娛樂等問答知識
? 在汽車垂直領域取得了明顯的效果,當然,在評測時也出現了一些模型幻覺、格式異常等情況,我們也在對模型進行持續的迭代和優化。
3.5
結果整合
? 結果整合,可以對本地搜索系統返回的結果進行進一步加工和優化,充分發揮LLM的多項能力,從而使文章表述更加精煉明確,提高文章的可讀性和信息傳達效果:
-
總結和概括:對搜索結果進行總結和概括,提取出關鍵信息,使其更具有可讀性和易理解性。
-
格式整理:進行格式化整理,使其呈現方式更加清晰和統一,提高用戶閱讀體驗。
-
去重和翻譯:排除搜索結果中的重復內容,確保給用戶呈現唯一性的答案。同時,LLM還支持翻譯功能,可以將搜索結果翻譯為用戶需要的語言,滿足多語言環境下的需求。
-
上下文分析和處理:通過分析會話歷史和提取上下文信息,LLM能夠更好地理解用戶意圖,并在結果整合過程中考慮到上下文的影響。這使得生成的答案更加準確和個性化。
4.示例展示
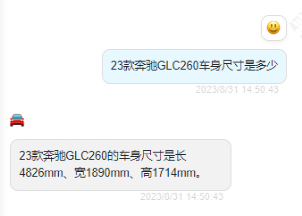
以參配場景為例:
23 款奔馳 GLC260 車身尺寸是多少?
?
?
?
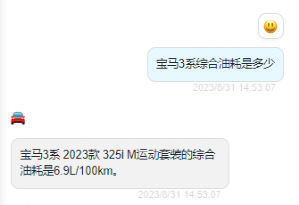
寶馬 3 系綜合油耗是多少?
?
?
GL8 的后備箱能放下行李箱和嬰兒車嗎?
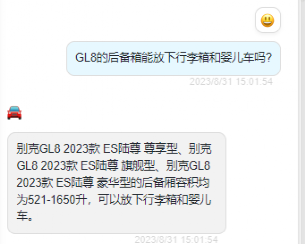
?
朗逸 1.2t 動力夠用嗎?
?
?
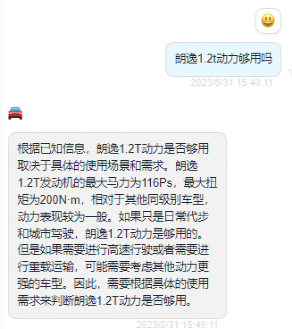
?
5. 總結
? LLM+搜索架構融合了意圖理解、智能搜索、結果增強等模塊。深入理解用戶指令,精確驅動查詢詞的搜索,結合大語言模型技術來優化模型結果生成的可靠性。通過這一系列協同作用,大模型實現了更精確、智能的模型結果回答,通過這種方式減少了模型的幻覺。
?
如何學習AI大模型?
作為一名熱心腸的互聯網老兵,我決定把寶貴的AI知識分享給大家。 至于能學習到多少就看你的學習毅力和能力了 。我已將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

一、全套AGI大模型學習路線
AI大模型時代的學習之旅:從基礎到前沿,掌握人工智能的核心技能!

二、640套AI大模型報告合集
這套包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

三、AI大模型經典PDF籍
隨著人工智能技術的飛速發展,AI大模型已經成為了當今科技領域的一大熱點。這些大型預訓練模型,如GPT-3、BERT、XLNet等,以其強大的語言理解和生成能力,正在改變我們對人工智能的認識。 那以下這些PDF籍就是非常不錯的學習資源。

四、AI大模型商業化落地方案

作為普通人,入局大模型時代需要持續學習和實踐,不斷提高自己的技能和認知水平,同時也需要有責任感和倫理意識,為人工智能的健康發展貢獻力量。




)

)


)




的方式)



時需要使用哪些工具?)
)