本文將要介紹的文獻主題為浮點存內計算,題目為《A 16nm 96Kb Integer/Floating-Point Dual-Mode-Gain-CellComputing-in-Memory Macro Achieving 73.3-163.3TOPS/W and 33.2-91.2TFLOPS/W for AI-Edge Devices》,下面本文將從文章基本信息與背景知識、創新點解析和現有工作對比三個方面進行論文詳解。
一.文章基本信息[1]
(1)研究團隊:
臺灣臺積電,臺灣國立清華大學,臺灣工業技術研究院。
(2)研究背景:
當前先進的AI邊緣芯片需要計算靈活性和高能效,并對推理精度提出了更高的要求。浮點(FP)數值表示可用于需要高推理精度的復雜神經網絡,然而,這種方法比定點整數(INT)數值表示需要更高的能量和更多的參數存儲。目前許多存內計算(CIM)架構針對?INT乘累加運算(INT-MAC)具有良好的能效,然而很少能夠支持FP乘累加運算(FP-MAC)。因此,開發既支持INT又支持FP運算且能有效應對上述挑戰的計算架構變得尤為重要。
(3)面臨挑戰:
FP運算可支持需要高精度的復雜神經網絡,但是通常需要更多的功耗,特別是在高密度存儲單元內進行計算時,如何有效管理能耗和散熱已成為一個關鍵科學問題。此外,FP運算提出更多參數存儲需求,而隨著大模型技術的發展,神經網絡本身也需要越來越多的參數存儲需求,因此FP存算的網絡部署面臨著空間和資源不足的挑戰。
在本文介紹的文獻中,研究團隊實現INT/FP雙模(DM)乘累加操作(MAC)時,主要面臨以下挑戰:
①低面積效率:在執行INT-MAC操作期間,FP-MAC功能會閑置,導致資源未充分利用;
②高系統級延遲:小容量SRAM-CIM在沒有同時寫入與計算功能的情況下,神經網絡數據更新中斷會導致延遲增加;
③高能耗:計算過程中系統到CIM架構的頻繁數據傳輸增加了能耗。
(4)本文工作:
為了解決上述面臨挑戰,研究團隊提出了一種INT/FP DM宏結構,簡要概括如下:
①DM區域輸入處理方案(ZB-IPS):消除指數計算中的減法,并在INT模式下復用對齊電路,從而提升能效比和面積效率;
②DM本地計算單元(DM-LCC):復用指數加法作為INT-MAC中的加法樹階段,進一步提高INT模式下的面積效率;
③基于靜止的雙端口增益單元陣列(SB-TP-GCA):支持數據的同時更新與計算,減少系統到CIM架構及內部數據訪問,從而改善能效和降低延遲。
- 相關名詞解釋:
①FP:Floating Point,浮點數。浮點數由三部分組成:符號位、指數部分、尾數部分,根據這三部分的不同,浮點數具有多個種類,其中FP32和FP16是常用的浮點數類型。FP32如圖1所示,一共有32bit,符號位為1bit、指數位8bit、尾數位23bit,提供了較高的精度和動態范圍,適用于大多數科學計算和通用計算任務;FP16如圖2所示,一共有16bit,符號位為1bit、指數位5bit、尾數位10bit,相對于FP32提供了較低的精度,但可以減少存儲空間和計算開銷,主要應用于深度學習和機器學習等計算密集型任務[2]。

圖1 FP32位數組成[2]
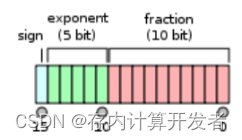
圖2 FP16位數組成[2]
②INT:Integer,整數。INT8表示8位整數,是常用的整數類型,使用8bit內存來存儲每個數值,最高位代表符號位,可以表示范圍從-128到127的整數。主要用于對圖像、音頻等進行量化處理,以減少計算量和存儲需求。
③MAC:Multiply Accumulate,是在數字信號處理器或一些微處理器中的特殊運算,具體是將乘法器乘積結果輸入累加器,累加器再將幾個周期的乘積相加。
④BF:BF16指的是一種16位寬的浮點數據類型,全稱為Bfloat16。這種數據類型由Google的TensorFlow團隊提出,用于優化深度學習模型的性能,近年來在深度學習和高性能計算領域受到越來越多的關注,因為它在保持良好的數值范圍的同時,減少了數據的位寬,從而可以提高計算速度和降低功耗。它包含:1位符號位(Sign bit)、8位指數(Exponent)、7位尾數(Mantissa)。與傳統的IEEE 754標準的單精度浮點數(FP32)相比,FP32有1位符號位、8位指數和23位尾數。盡管BF16的尾數較短,但它保持了與FP32相同的指數范圍,這意味著它在表示數值的范圍上與FP32相當,但在精度上有所降低。
二.本文主要工作
1.雙模CIM(DM-CIM)的結構與數據流
本文創新性的提出了面積利用率更高的雙模CIM結構和數據流,可以支持整型數INT8和浮點數BF16兩種模式的計算。相比于傳統的雙模CIM結構,傳統雙模CIM在進行INT計算時的exp加法器與對齊電路處于閑置狀態,使得芯片面效與面積利用率較低。在本文的工作中,INT模式下DM-ADD結構充當2*NACCU的加法器樹,并利用對齊電路作為輸入稀疏感知電路(INAC),極大的提升了INT模式下的能效與面效。

圖3 傳統雙模CIM在INT模式下存在資源閑置
雙模CIM包括基于DM區域的輸入處理單元(ZB-IPU)、DM-GC計算陣列(DM-GCCA)、數字移位加法器(DSaA)和時序控制器(CTRL)。其中的DM-GCCA由64個GC計算模塊(GC-CB)組成,每個GC計算塊包含一個用于64b存儲數據和16b固定數據的SB-TP-GCA,以及一個包含DM-ADD和DM多路復用器(DM-MUX)的DM-LCC。DM-GCCA可以執行兩種模式的計算:
1)BF16模式:
在此模式下,DM-CIM的各個模塊均處于工作狀態。SB-TP-GCA存儲1b符號數+7b尾數+8b指數。第一步,DM-ADD會將8b的輸入指數和8b的權重指數相加,也即得到了指數部分積(PDE);第二步,ZB-IPU找到最大的PDE值并根據對齊的INMA來對齊每一個輸入尾數INM;第三步,選擇器(DM-MUX)計算PDM;第四步,DSaA將指數和尾數相結合,輸出結果。
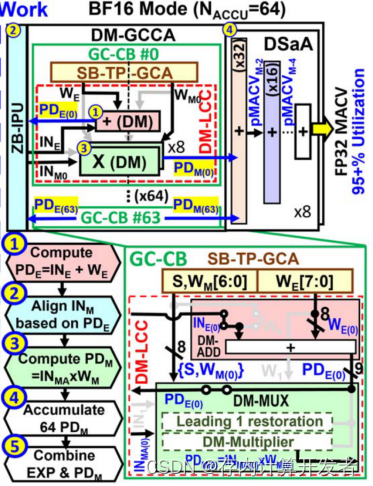
圖4 BF16模式下的數據流
2)INT8模式:
在此模式下,DM-CIM的各個模塊同樣均處于工作狀態。SB-TP-GCA存儲兩個8b的權重。第一步,DM-ADD將兩個權重相加得到pSUM,通過利用權重數據復用可以將其用于多個計算;第二部,ZB-IPU檢測輸入值的稀疏度來減少DM-GCCA和DSaA中的MAC能耗,并解碼兩個按位IN0[k]和IN1[k]作為DM-MUX的選擇信號;第三步,DM-MUX對IN0和IN1執行部分MAC運算并生成pMAC值;第四步,DSaA累加64個pMACV,輸出結果。

圖5 INT8模式下的數據流
2.基于DM區域的輸入處理單元操作(ZB-IPU方案)
ZB-IPU方案/模塊是處理BF16模式下的對齊和INT8模式下的稀疏性檢測的關鍵模塊,該模塊創新性地提出了基于區域檢測對齊的方案(ZDBA),在這個方案下的對齊操作僅使用3個反相器就能完成,代替傳統的n比特減法器,顯著降低了模塊的能量與面積開銷。此外,ZB-IPU模塊也支持INT8模式下的稀疏性檢測,總之,他也可以執行兩種模式的計算:
1)BF16模式:
在此模式下,ZDBA方案下的對齊操作分為兩步。第一步,pEMAXF 查找 PDE-MAX?的 MSB-6b (PDE-MAX[8:3])。然后ZBU根據PDE-MAX[8:3]生成3個區域參考(PDE-REF1~3),這三個區域參考將作為后續對齊時的重要依據;第二步,每個PDE(n)根據以下條件被分類為三個區域(ZFG=1/2/3)中的一個,DM-IPB根據通過反轉PDE[2:0](LSB3b)獲得的區域移位數(NSHZ)來對齊INM,這是PDE和PDE-REF之間的差值。以圖中的PDE(0)=011111101 (253)為例,它是PDE-MAX,并且PDE-REF1=011111111(255),則PDE(0)位于 zone-0(ZFG=1),它僅需對PDE(0)[2:0]進行反轉,即101反轉為010,反轉值為2(NSH(0)=2),這樣一來,就可以利用三個反相器完成對齊的操作。如圖6為BF16模式下的對齊分類區域、對齊輸出和時序示意圖。

圖6 BF16模式下的對齊操作
2)INT8模式:
在此模式下,我們只需要對ZDBA方案下的參考值置0,即可完成稀疏度檢測,ZB-IPU此時相當于輸入稀疏感知電路,可以大幅降低后續計算的功耗與面積,在圖7的表格中可以明顯看出其對于輸入的操作。
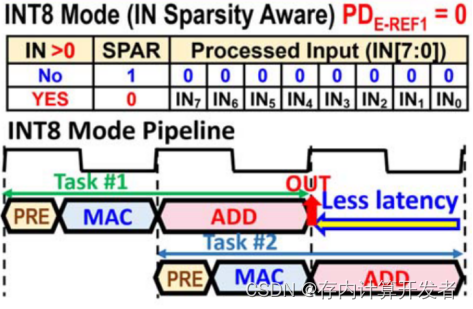
圖7 INT8模式下的稀疏度檢測
3.基于固定端口的雙端口增益單元(SB-TP-GCA)
為了應對傳統CIM在計算過程中反復進行系統和CIM的數據傳輸所造成的高能耗的挑戰,本文提出了一種支持并行數據更新和計算的方法,減少系統與CIM交換內部數據間的時間,改善延時和能量消耗。

圖8 雙端口計算流程
如上圖所示,是SB-TP-GCA這一設計的雙端口工作時序圖。對比傳統CIM的順序執行,本文介紹的工作使用了雙口工作,一口負責讀寫、一口負責計算,以解決延時問題,提升計算效率。能效方面的提升主要依靠數據復用,降低讀寫次數的方式來實現。
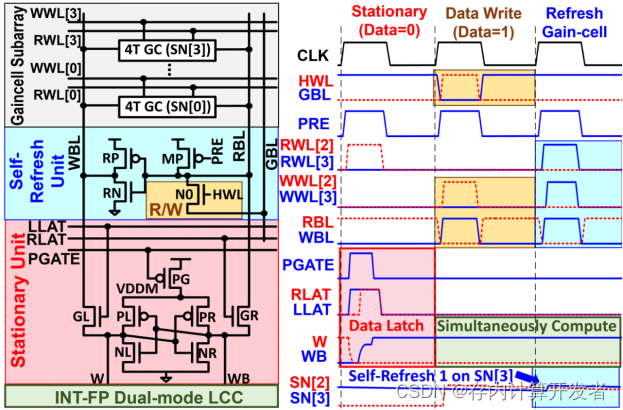
圖9 芯片雙端口中三個模式對應執行電路與執行時序圖
上圖所示是電路的設計圖和時序圖。
SB-TP-GCA結構允許在進行乘加運算的同時進行數據更新。這種并行操作減少了系統在不同時間段內需要進行的數據傳輸次數,從而降低了總能耗。并且,陣列內部的靜態單元可以在多個計算周期內重用權重數據,減少了每次計算所需的數據傳輸量。通過減少內部數據訪問頻率,有效地降低了能耗。每個SB-TP-GCA列由四個4T增益單元(GC)、一個4T自刷新單元(SRU)和一個7T靜態單元(STU)組成。在存儲更新模式下,數據從全局位線(GBL)傳輸到SRU,然后通過SRU驅動寫入位線(WBL)以更新選定的GC單元。這種存儲單元設計減少了不必要的數據移動和功耗。SB-TP-GCA提供了三種操作模式(靜態更新、存儲更新和自刷新),針對不同模式的分類可以針對使用場景管理數據的存取和刷新,進一步減少了功耗。例如,在靜態更新模式下,存儲的數據可以通過讀位線(RBL)傳輸到自刷新單元(SRU)進行刷新,而無需頻繁的全局數據傳輸。
通過這以上幾點改進,優化高功耗問題。
三、性能對比與拓展
文中將該工作與已有的相似工作進行對比,性能對比表和芯片電鏡圖如圖所示,可以看到本工作在面積效率和能效上更優。
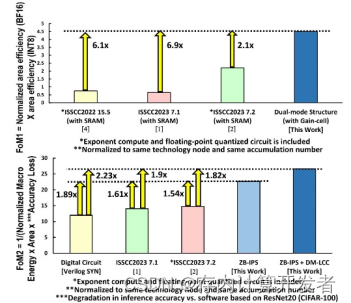

圖10 本文芯片性能對比
本工作與以往工作的主要區別在于采用雙端口設計,本文基于這一想法開展多項優化。從本文針對的計算能效、傳輸延時、浮點/整數計算支持三個角度來看:
(1)計算能效/面效方面:[1]采用雙端口設計,提高數據復用,減少數據流動,提高計算能效;[3]模擬域和數字域結合,將兩類計算模式按照一定比例進行耦合,兼具兩種計算模式的優點來提高計算效率和準確度;[4]設計雙位存儲器和FCU浮點計算單元,提升吞吐率,采用高精確低近似的乘法器,提高面銷和能效;[5]提出BM2控制器,使用按位輸入的Booth編碼,部分積重編碼,減少近50%的循環次數和位乘法次數,以提升計算能效。
(2)傳輸延時方面:[1]采用雙端口設計,讀寫和計算并行,提高計算效率;[3]使乘法的中間結果在同一列累積。
(3)浮點支持方面:[1]設計了同芯片雙模式,針對該模式設計了一種新型輸入數據處理方式,在計算浮點數時將其用于尾數對齊,計算整數時將其用于稀疏度檢測,最大化面積利用效率;[4]提出了FCU,解決浮點與整數映射不一致的問題,利用同一個MAC模塊;[5]實現了一種無指數對齊的浮點乘累加計算流水線,使CIM專注提升尾數乘累加的計算速度
針對浮點支持方面,已有的工作主要針對尾數計算算法進行改進,以提升效率。在思路上是共性的,即對浮點計算部分尾數乘累加計算流程進行優化,以盡可能減小計算周期數。早期的浮點存算正如本文背景所說,采用分離程度較高的硬件進行工作。近期的浮點存算工作,已進行了一定改進,但也未能充分利用面積資源,主要的資源浪費集中在指數對齊計算方面,整數計算本不需該計算模式,因此在計算整數時,這部分浮點計算硬件未能得到應用,如下圖所示。
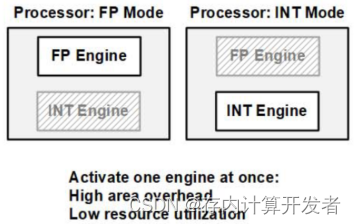
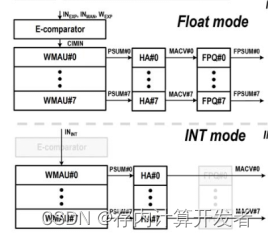
圖11 已有浮點存算工作中存在的問題
相比之下,本文方案在設計了ZB-IPS的輸入調整模塊設計,在整數計算和浮點計算時只有數據流的不同,在實現浮點存算計算效率提升的同時,使所有硬件模塊均被充分利用。
綜上,本文所介紹的ISSCC2024 34.2這篇工作向浮點存算中引入雙端口以支持浮點/整數雙模計算,最大化面積利用效率并提升計算速度、提升能效。其中輸入處理單元是將尾數對齊于整數稀疏度判斷繼承在一起,是極其巧妙的設計。
參考文獻
[1]W. -S. Khwa et al,“34.2 A 16nm 96Kb Integer/Floating-Point Dual-Mode-Gain-Cell-Computing-in-Memory Macro Achieving 73.3-163.3TOPS/W and 33.2-91.2TFLOPS/W for AI-Edge Devices,”2024 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2024.
[2]FP32、FP16 和 INT8-CSDN博客.
[3]?Wu, Ping-Chun, et al. “A 22nm 832Kb hybrid-domain floating-point SRAM in-memory-compute macro with 16.2-70.2 TFLOPS/W for high-accuracy AI-edge devices.” 2023 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2023.
[4]?Guo, An, et al. “A 28nm 64-kb 31.6-TFLOPS/W digital-domain floating-point-computing-unit and double-bit 6T-SRAM computing-in-memory macro for floating-point CNNs.” 2023 IEEE International Solid-State Circuits Conference (ISSCC). IEEE, 2023.
[5]?Tu, Fengbin, et al. “A 28nm 29.2 TFLOPS/W?BF16 and 36.5 TOPS/W?INT8 reconfigurable digital CIM?processor with unified FP/INT?pipeline and bitwise in-memory booth multiplication for cloud deep learning acceleration.” 2022 IEEE International Solid-State Circuits Conference (ISSCC). Vol. 65. IEEE, 2022.








)



![[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝](http://pic.xiahunao.cn/[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝)






