本文根據《Journal of the American College of Cardiology》上曾發表的一篇文章《Making Sense of Statistics in Clinical Trial Reports》,來全面而具體地說明臨床試驗論文中,各種類型數據與結果使用圖表的正確展示方法。
本文將著重介紹基線數據、試驗信息以及結局數據中二分類頻數資料和計量資料的展示方法。
一、基線(Baseline)數據展示
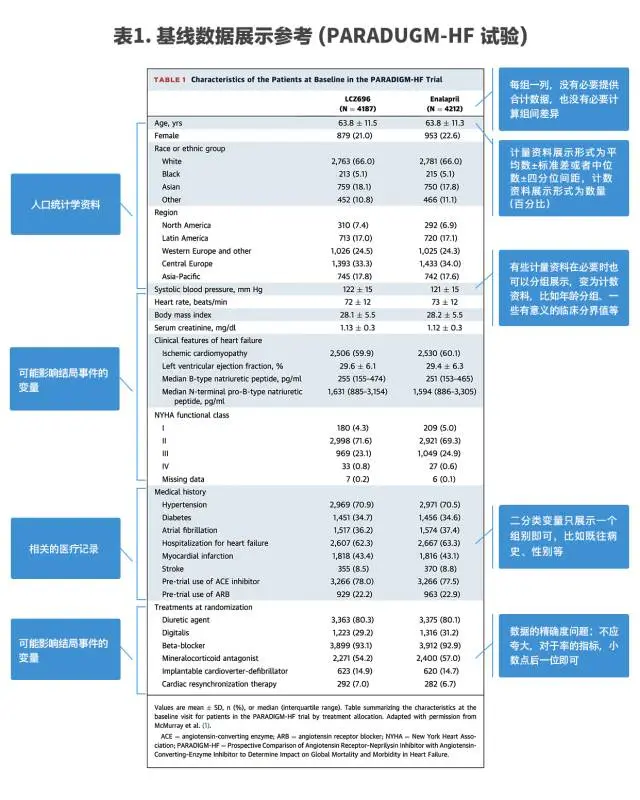
基線(Baseline)數據是所有類型的試驗所必須要提供和展示的信息,具有描述研究所納入的樣本特征、標示研究所關注的變量等重要作用。
基線(Baseline)數據的展示多以表格的方式,以各種變量的名稱為表格每行的標題,而不同的組名為表格每列的標題,需要涵蓋的變量包括人口學資料、可能影響結局事件的變量以及相關的醫療記錄,每列提供一個組別的數據,在RCT中沒有必要提供合計數據或進行組間差異比較。
下方提供一個研究的表格作為范本,數據的展示方法、可能遇到的情況及相關注意事項標注在相應位置(表1)。
二、試驗信息(Trial profile)展示
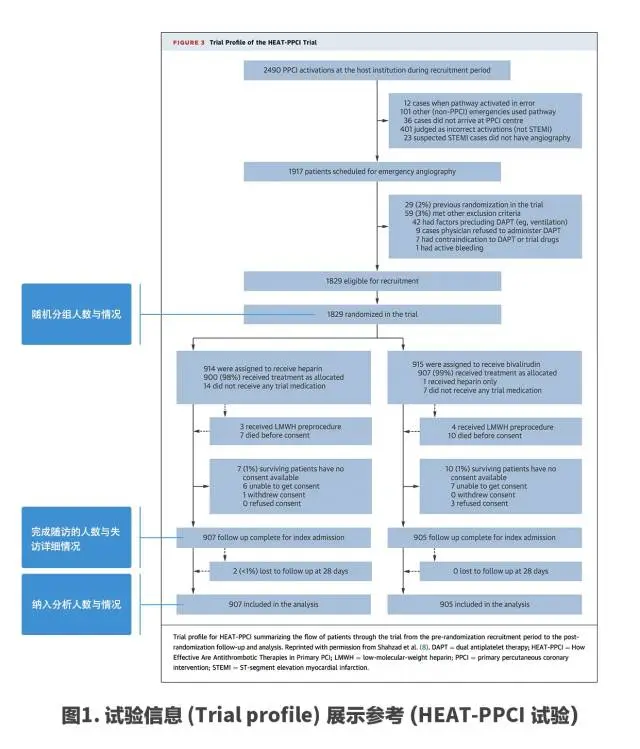
試驗信息(Trial profile)也是需要展示的部分,用以清晰直觀的描述在試驗進程中各個時間點的操作,以及在各個操作過后各組人數的變化及原因,方便讀者對研究有直觀的了解。
試驗信息(Trial profile)多以流程圖的形式進行展示,按照時間和操作順序排列,清晰列出每一部分的人數,需要展示的重要操作節點至少應包括隨機分組、完成隨訪及數據分析。
下圖展示的是一個研究中所提供的試驗信息(Trial profile)圖,作為示例范本供參考,可行的展示方式多種多樣,樣式不用局限于示例,但主要信息要清晰地提供出來(圖1)。
三、二分類頻數資料的結果展示
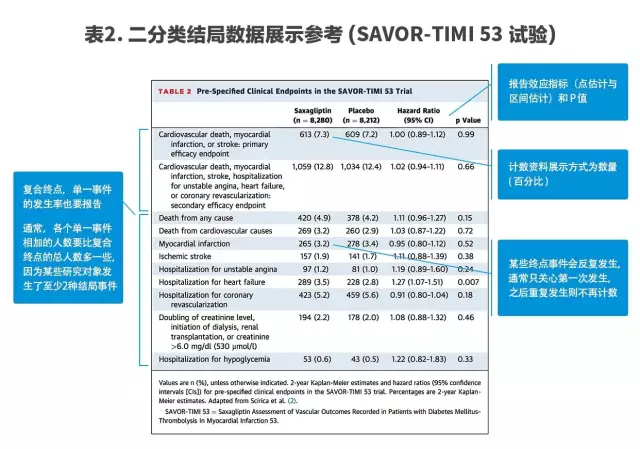
二分類頻數資料在試驗研究中經常被涉及,例如:性別、各種事件發生與否等,是結果展示中的重要組成部分,主要結局數據表格和副作用表格均包含大量二分類資料。
在主要結局數據表格中,與基線(Baseline)數據形式類似,同樣是以各種變量或事件的名稱作為表格每行的標題,而不同的組名為表格每列的標題,不同之處在于需要增加兩列,分別報告效應指標的大小和P值。
值得注意的是,在事件的展示中,許多研究的主要終點為復合終點,此時需同時在下方依次提供各個事件單獨發生的數量與百分比。
效應指標需要包括點估計值與區間估計。在這里,強調一下區間估計的重要性,并解釋一下點估計值與區間估計的關系:點估計可以得到一個具體的數值,表示結果的大小,而這一結果存在很大程度的不確定性,區間估計即可表達這種不確定性,通常用95%置信區間(Confidence Interval)。
之所以選擇95%,主要是為保證研究的一致性,方便與他人研究進行比較,因為大部分的研究都選擇了95%這一數值;同時,與通常設定的顯著性水平0.05保持一致,方便與P<0.05進行關聯。樣本量越大,這種不確定性越小,置信區間越窄,點估計值估計越精確。因此,單獨報告點估計值是不夠嚴謹的,需要同時報告區間估計的結果。
下圖同樣提供一個研究的表格作為范本,注意事項標注在旁(表2)。
對于研究的效應分析可以用到多種不同的效應指標,表3總結了各個效應指標的概念及計算方法。通常,兩個組別時,先列好數據的四格表,計算發生率,再進行相應的效應指標計算。
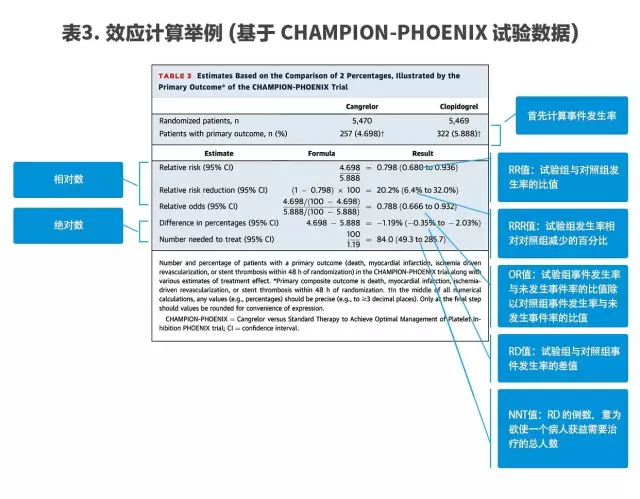
效應指標包括絕對數(如危險度差(Risk difference, RD/Difference in percentages)、需治療人數(Number needed to treat, NNT)等)和相對數(如相對危險度(Relative risk, RR)、相對危險降低(Relative risk reduction, RRR)和比值比(Odds ratio, Relative odds, OR)等)兩類。相對數指標具有統計學優點,且對于不同類型的人群的一致性較好,結果易于推廣,而絕對數指標則更有實際價值和意義。
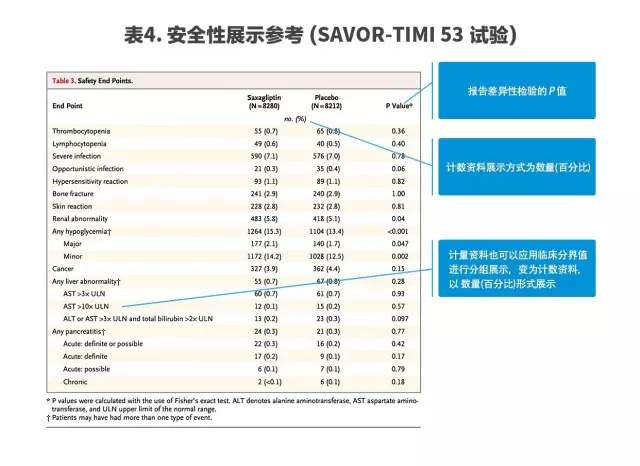
此外,除了要報告詳細記錄和主要結局指標外,安全性信息也要進行報告,安全性表格也多為二分類資料。
與主要結局事件表格類似,同樣是以各種變量或事件的名稱為表格每行的標題,而不同的組別為表格每列的標題,不同之處在于只需要進行組間差異性檢驗,報告P值的大小。
下圖即為一個研究中所展示的安全性表格,作為內容與樣式的參考(表4)。
四、計量資料的結果展示
1. 單個時間點的組間均值比較
在分析定量結局指標時,一般比較常見的分析策略就是直接比較不同干預組結局指標的組間差異。然而,考慮到多數情況下這些結局指標都會在基線時被測量,一個更加合理的方法是比較結局指標相對于基線的平均變化值。
但是這里也同樣存在一個Bug——這種變化值往往會受到基線水平的影響,比如我們常說的“向均數回歸(regression to the mean)”——在同等的干預條件下,那些結局指標基線水平比較高的研究對象可能會獲得更大的下降。為了解決這樣問題,就需要另一種統計學分析方法——協方差分析(ANCOVA),即在比較結局指標變化值時調整其基線水平。
來看一個實例,SYMPLICITY HTN-3研究[6]是一項隨機、雙盲、假手術對照試驗,共招募 535 例嚴重難治性高血壓患者,按照 2:1 進行隨機分組,分別進行去腎交感神經術或假手術治療。研究主要終點為治療6個月時患者收縮壓(SBP)下降。
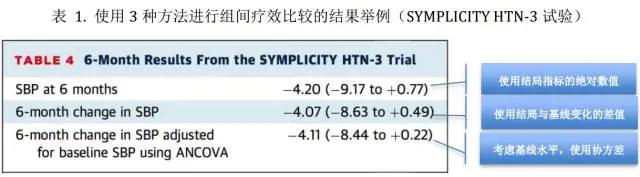
如表1所示,首先進行去腎交感神經術和假手術治療組6個月時SBP的組間比較,其次在比較兩組SBP 6個月的變化值時考慮是否調整其基線水平。可以比較明顯地看到第一種組間比較得到的95%CI比后兩種情況更“寬”,而在調整了SBP基線水平的第三種情況比較時95%CI最“窄”。
比較遺憾的是,上述95%CI仍跨越“0”,即組間差異無統計學意義。提示去腎交感神經術與假手術相比并未減少難治性高血壓患者的6個月時收縮壓水平。
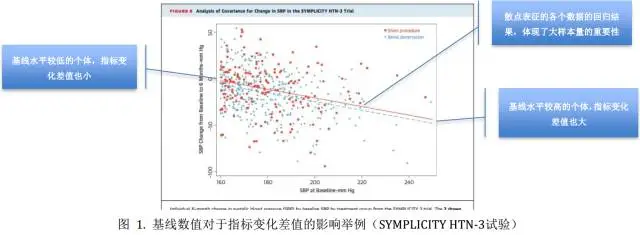
調整SBP基線水平真的有必要嗎?下圖中去腎交感神經術和假手術治療組兩條回歸線顯示,兩組中基線SBP水平較高的研究對象,6個月后SBP下降值也更大。如果不進行SBP基線水平調整,實際的效應值可能會被錯誤估計(4.07 vs. 4.11adjusted mmHg)。
此外,從下圖中也可以明確另一點,即不同研究對象的研究結果差別很大,這也是為什么臨床試驗通常需要納入足夠的研究對象(樣本量太少,結果可能并不穩定)。
細心的小伙伴可能會提另外一個問題,實際分析中是選擇結局變化的差值,還是選擇相對于基線水平的變化百分比?從統計上講,這時候就要看哪種情況更適合使用協方差分析。(詳見:手把手教你協方差分析的SPSS操作!)
2. 多個時間點計量數據的分析與結果展示方法
以上我們討論了,如何利用結局指標的基線數據來使干預措施的臨床療效估計更為合理。實際上,很多時候一個臨床研究在設計數據收集時,往往不會只收集開始(基線)和結束(隨訪終點)兩個時間點的數據。當遇到結局指標多個時間點數據時,就需要采取不同的方法,當然也取決于研究目的。
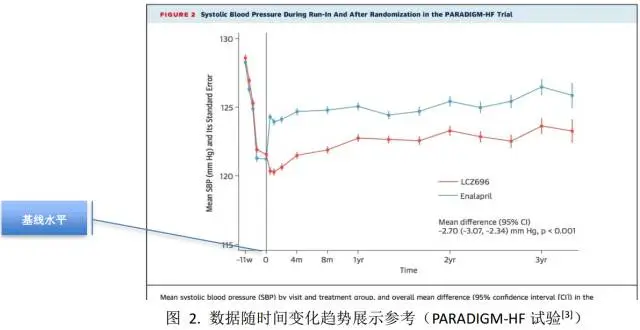
①兩組均值隨時間的變化趨勢
多個時間點的計量數據可以以時間為橫坐標、指標數值為縱坐標繪制折線圖展示,下圖為一項研究的結果圖,每個時間點都描繪了均值與標準誤(下圖)。
② 不同下降率(或升高率)的組間比較
許多研究的結局指標中,后續時間點較基線時的變化數值所占百分比(下降率或升高率)具有重要的臨床意義,比如在呼吸系統功能損傷的研究中用力肺活量的下降率,此時可計算不同時間點的結局指標下降率或升高率,再進行組間比較及后續分析。
③ 在隨訪過程中某一特定時間點的獨特價值
如在18個月時檢測糖化血紅蛋白來評價一種糖尿病藥物的療效,這樣的情況下,特定時間的數據應著重分析。
因為多個時間點的計量資料往往存在相關性,不同于一般的統計分析方法(要求各數據彼此相互獨立),此時應該選擇重復測量分析。(詳見:SPSS:單因素重復測量方差分析(史上最詳細教程))
3. 計量資料呈偏態分布的分析方法
有時候計量資料的數據呈偏態分布,此時組間均值比較的傳統分析方法可能受一些極端值的影響而扭曲,此時可以選擇如下的處理方法:
① 采取合適的數據轉換
例如,將原始數值取自然對數后,數據呈正態分布,此時采用幾何均數來進行組間差異的比較。
② 使用非參數檢驗
非參數檢驗中,比較常用的是采用中位數對兩組療效進行描述,并用非參數方法(例如常用的秩和檢驗)對組間療效差異進行分析可避免極端值的影響。
③ 設定特定的臨界值,將原來的連續性變量轉換為二分類變量
例如,計算超過肝臟功能指標上限數值的人數占總人數的百分比,這時采用卡方檢驗比較組間的百分比有無差異即可。
參考文獻
-
J Am Coll Cardiol 66(22):2536–2549
-
N Engl J Med 2014;371:993–1004.
-
N Engl J Med 2013;369:1317–26.
-
Lancet 2014;384:1849–58.
-
N Engl J Med 2013;368:1303–13.
-
N Engl J Med. 2014; 370:1393–401.


)



![[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝](http://pic.xiahunao.cn/[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝)








使用)
)

——JS介紹)
