李宏毅深度學習筆記
圖像分類
圖像可以描述為三維張量(張量可以想成維度大于 2 的矩陣)。一張圖像是一個三維的張量,其中一維代表圖像的寬,另外一維代表圖像的高,還有一維代表圖像的通道(channel)的數目。
通道:彩色圖像的每個像素都可以描述為紅色(red)、綠色(green)、藍色(blue)的組合,這 3 種顏色就稱為圖像的 3 個色彩通道。
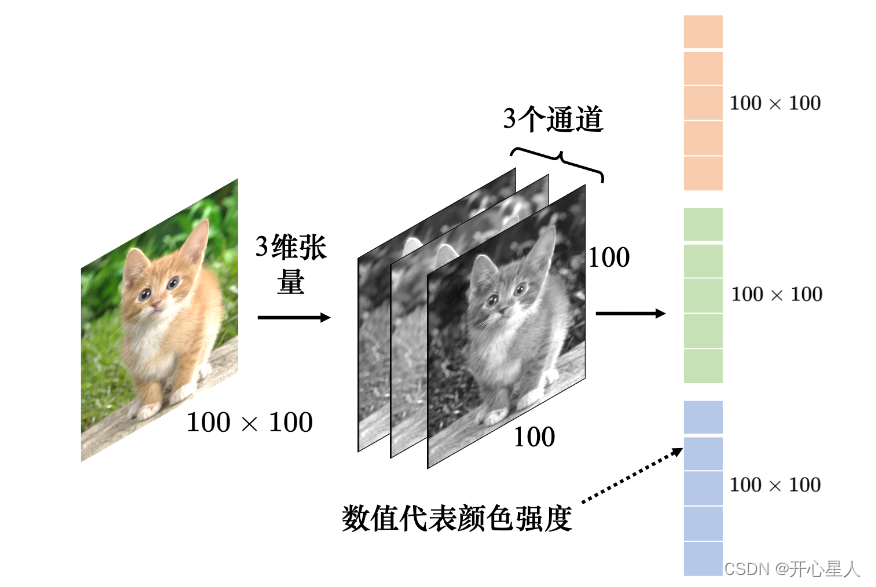
如果把向量當做全連接網絡的輸入,輸入的特征向量的長度就是 100 × 100 × 3。這是一個非常長的向量。由于每個神經元跟輸入的向量中的每個數值都需要一個權重,所以當輸入的向量長度是 100 × 100 × 3,且第 1 層有 1000 個神經元時,
第 1 層的權重就需要 1000 × 100 × 100 × 3 = 3 × 107 個權重。
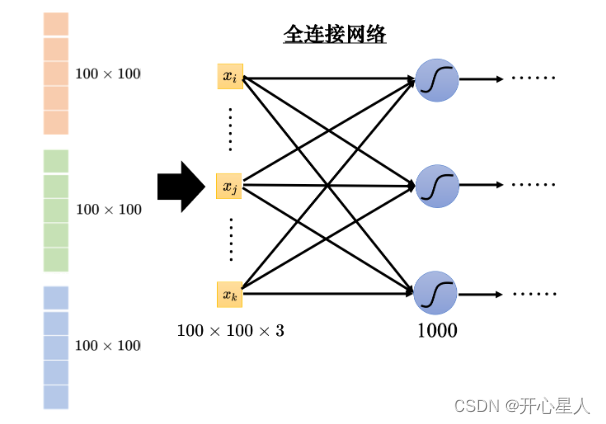
更多的參數為模型帶來了更好的彈性和更強的能力,但也增加了過擬合的風險。模型的彈性越大,就越容易過擬合。為了避免過擬合,在做圖像識別的時候,考慮到圖像本身的特性,并不一定需要全連接,即不需要每個神經元跟輸入的每個維度都有一個權重。
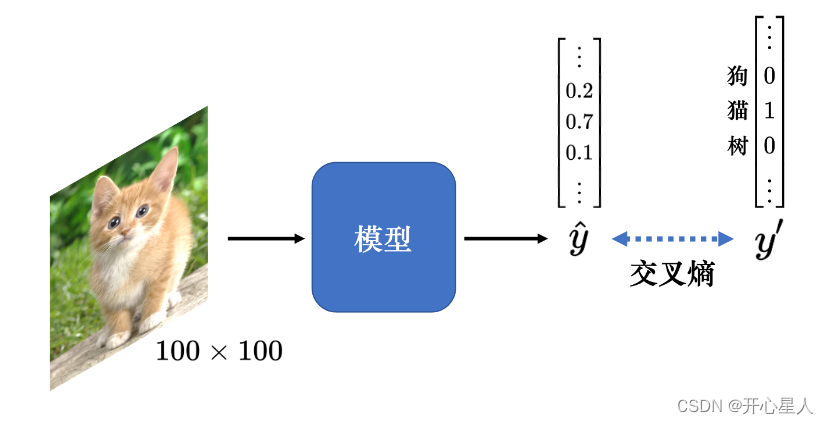
模型的目標是分類,因此可將不同的分類結果表示成不同的獨熱向量 y’。模型的輸出通過 softmax 以后,輸出是 ?y。我們希望 y′ 和 ?y 的交叉熵越小越好。
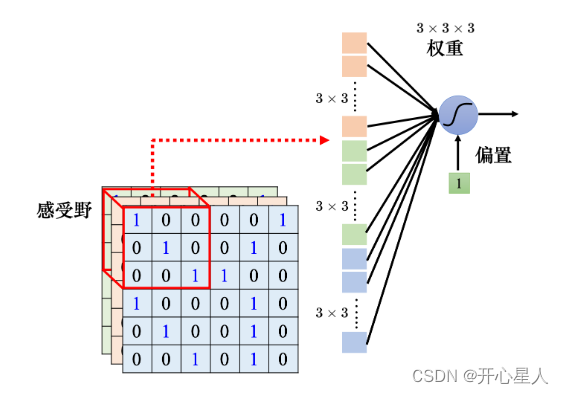
感受野
對一個圖像識別的類神經網絡里面的神經元而言,它要做的就是檢測圖像里面有沒有出現一些特別重要的模式,這些模式是代表了某種物體的。比如有三個神經元分別看到鳥嘴、眼睛、鳥爪 3 個模式,這就代表類神經網絡看到了一只鳥。
卷積神經網絡會設定一個區域,即感受野(receptive field),每個神經元都只關心自己的感受野里面發生的事情,感受野是由我們自己決定的。
卷積核
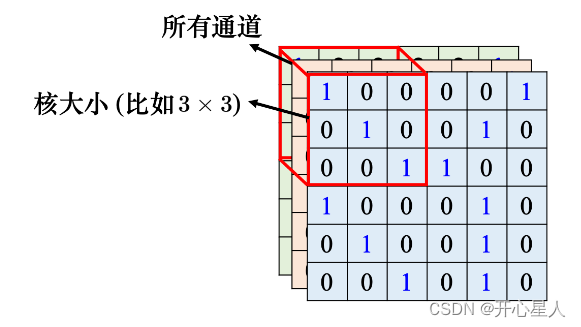
一般同一個感受野會有一組神經元去守備這個范圍,比如 64 個或者是 128 個神經元去守備一個感受野的范圍。圖像里面每個位置都有一群神經元在檢測那個地方,有沒有出現某些模式
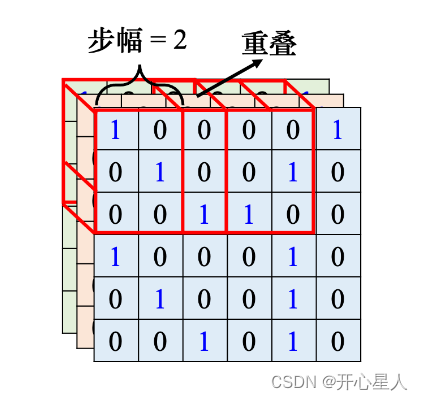
把左上角的感受野往右移一個步幅,就制造出一個新的守備范圍,即新的感受野。移動的量稱為步幅,步幅是一個超參數。因為希望感受野跟感受野之間是有重疊的,所以步幅往往不會設太大,一般設為 1 或 2。
Q: 為什么希望感受野之間是有重疊的呢?
A: 因為假設感受野完全沒有重疊,如果有一個模式正好出現在兩個感受野的交界上面,就沒有任何神經元去檢測它,這個模式可能會丟失,所以希望感受野彼此之間有高度的重疊。如令步幅 = 2,感受野就會重疊。
共享參數
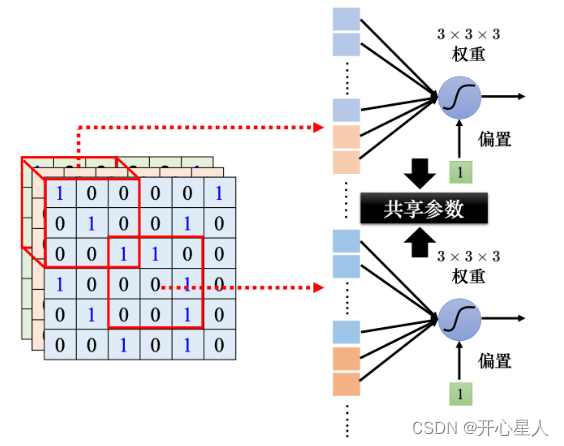
同樣的模式可能會出現在圖像的不同區域。比如檢測鳥嘴的神經元做的事情是一樣的,只是它們守備的范圍不一樣。如果不同的守備范圍都要有一個檢測鳥嘴的神經元,參數量會太多了。
所以可以讓不同感受野的神經元共享參數,也就是做參數共享。所謂參數共享就是兩個神經元的權重完全是一樣的
卷積層
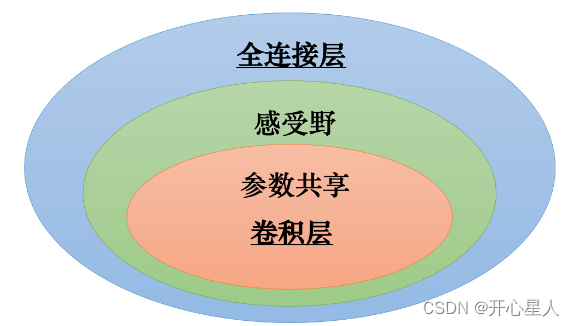
感受野加上參數共享就是卷積層(convolutional layer),用到卷積層的網絡就叫卷積神經網絡。卷積神經網絡的偏差比較大。但模型偏差大不一定是壞事,因為當模型偏差大,模型的靈活性較低時,比較不容易過擬合。
卷積層是專門為圖像設計的,感受野、參數共享都是為圖像設計的
多卷積層
每個感受野都只有一組參數而已,這些參數稱為濾波器。
一個卷積層里面就是有一排的濾波器,每個濾波器都是一個 3 × 3 × 通道,其作用是要去圖像里面檢測某個模式
卷積層是可以疊很多層的,第 2 層的卷積里面也有一堆的濾波器,每個濾波器的大小設成 3 × 3。其高度必須設為 64,因為濾波器的高度就是它要處理的圖像的通道。(這個 64 是前一個卷積層的濾波器數目,前一個卷積層的濾波器數目是 64,輸出以后就是 64 個通道。)
如果濾波器的大小一直設 3 × 3,會不會讓網絡沒有辦法看比較大范圍的模式呢?
A:不會。如圖 4.23 所示,如果在第 2 層卷積層濾波器的大小一樣設 3 × 3,當我們看第 1 個卷積層輸出的特征映射的 3 × 3 的范圍的時候,在原來的圖像上是考慮了一個5 × 5 的范圍。雖然濾波器只有 3 × 3,但它在圖像上考慮的范圍是比較大的是 5 × 5。因此網絡疊得越深,同樣是 3 × 3 的大小的濾波器,它看的范圍就會越來越大。所以網絡夠深,不用怕檢測不到比較大的模式。
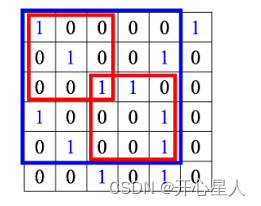
下采樣和匯聚
把一張比較大的圖像做下采樣,把圖像偶數的列都拿掉,奇數的行都拿掉,圖像變成為原來的 1/4,但是不會影響里面是什么東西。
匯聚被用到了圖像識別中。匯聚沒有參數,所以它不是一個層,它里面沒有權重,它沒有要學習的東西,匯聚比較像 Sigmoid、ReLU 等激活函數。
匯聚有很多不同的版本:最大匯聚在每一組里面選一個代表,選的代表就是最大的一個;平均匯聚是取每一組的平均值。
做完卷積以后,往往后面還會搭配匯聚。匯聚就是把圖像變小。做完卷積以后會得到一張圖像,這張圖像里面有很多的通道。做完匯聚以后,這張圖像的通道不變。
一般在實踐上,往往就是卷積跟匯聚交替使用,可能做幾次卷積,做一次匯聚。比如兩次卷積,一次匯聚。不過匯聚對于模型的性能可能會帶來一點傷害。近年來圖像的網絡的設計往往也開始把匯聚丟掉,它會做這種全卷積的神經網絡,整個網絡里面都是卷積,完全都不用匯聚。匯聚最主要的作用是減少運算量,通過下采樣把圖像變小,從而減少運算量。
CNN
經典圖像識別網絡:
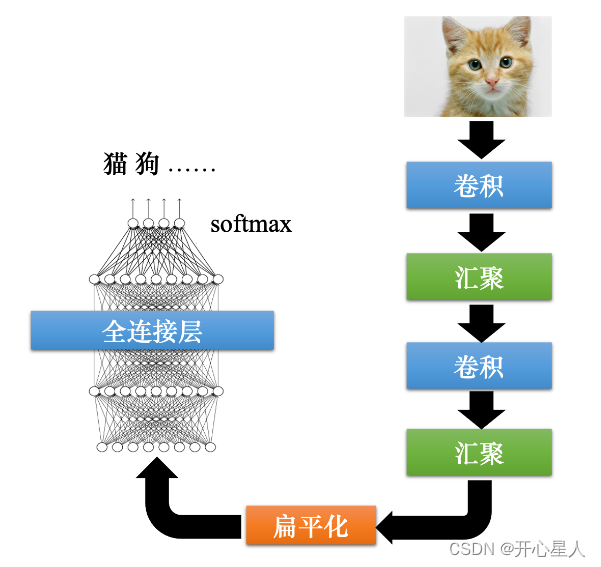
輸入層:輸入圖像等信息
卷積層:用來提取圖像的底層特征
池化層(匯聚):防止過擬合,將數據維度減小
全連接層:匯總卷積層和池化層得到的圖像的底層特征和信息
輸出層:根據全連接層的信息得到概率最大的結果





)



![[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝](http://pic.xiahunao.cn/[CTF]-PWN:mips反匯編工具,ida插件retdec的安裝)








使用)
)