受到 Barnett 等人論文《構建檢索增強生成系統的七大挑戰》啟發,本文將探討論文中提及的七大挑戰及在開發 RAG(檢索增強生成)流程中常遇到的五個額外難題。更為重要的是,我們將深入討論解決這些 RAG 難題的策略,以便我們在日常的 RAG 開發工作中能更有效地解決這些問題。
我偏好用 “難題” 而不是 “挑戰” 來描述,因為這些問題都有對應的解決方案。我們應該在這些問題在我們的 RAG 流程中變成真正的挑戰之前,盡量解決它們。
首先,我們來回顧一下論文中提到的七個難題,如下圖所示。隨后,我們還將討論五個額外的難題及其解決策略。
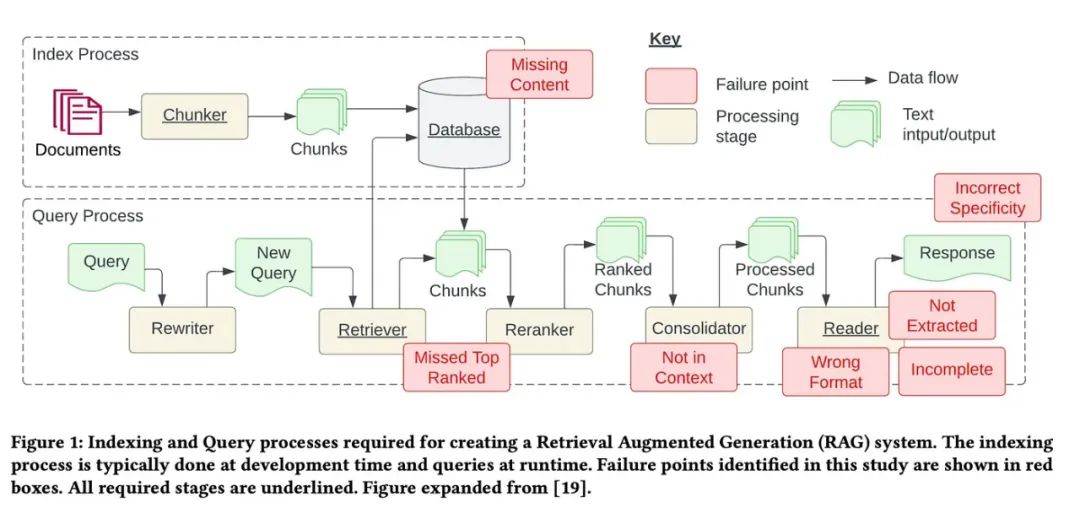
01、內容缺失
知識庫中缺少必要的上下文信息。當知識庫沒有包含正確答案時,RAG 系統可能會給出一個貌似合理但實際上錯誤的回答,而不是明確表示它不知道答案。這可能會導致用戶接收到誤導信息,從而感到挫敗。
針對這一問題,我們提出了兩種解決策略:
清潔數據源
俗話說,“垃圾進,垃圾出”。這就是說,如果輸入的數據質量不高,比如說含有矛盾的信息,那么無論你的 RAG 流程構建得多么完善,都無法從這些低質量的輸入中得到高質量的輸出。這個策略不僅適用于當前的問題,而且適用于本文討論的所有難題。確保數據的準確性和清晰性是任何有效 RAG 流程的基礎。
優化提示策略
在缺乏知識庫信息的情況下,通過更精準的提示,比如告訴系統 “如果你不確定答案,請明確表示你不知道”,可以明顯提高系統回答問題時的準確性。這種方法雖然不能保證 100% 的準確率,但在清理數據之后,精心設計提示是提高輸出質量的一種有效手段。
02、遺漏重要文檔
在初始的檢索步驟中,有時會漏掉關鍵文檔,導致它們沒有出現在系統返回的最頂端結果之中。這就意味著正確的答案可能被忽略了,使得系統無法準確回答問題。正如論文所指出的,“答案雖然在某個文檔中,但因為排名不夠高而沒有呈現給用戶”。
為此,我想到了兩種可能的解決方法:
通過調整 chunk_size 和 similarity_top_k 參數優化檢索效果
chunk_size 和 similarity_top_k 是控制 RAG 模型數據檢索效率和效果的關鍵參數。適當調整這些參數,可以平衡計算效率與檢索到的信息質量。我們在前一篇《利用 LlamaIndex 自動化超參數調優》中已經深入討論了如何調整 chunk_size 和 similarity_top_k。
文章鏈接:https://levelup.gitconnected.com/automating-hyperparameter-tuning-with-llamaindex-72fdd68e3b90
下面是代碼示例:
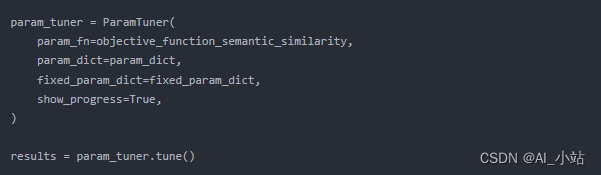
函數 objective_function_semantic_similarity 的定義如下所示,其中 param_dict 包含參數 chunk_size 和 top_k 及其推薦的值:
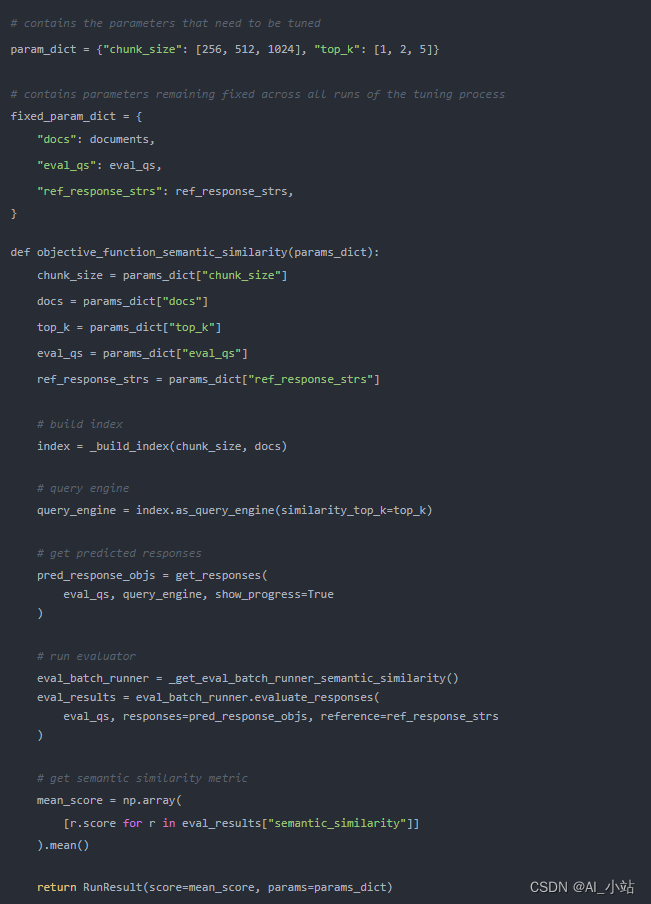
更多細節可以參考 LlamaIndex 發布的關于 RAG 超參數優化的完整教程:
https://docs.llamaindex.ai/en/stable/examples/param_optimizer/param_optimizer.html
檢索結果的優化排序
在最終將檢索結果提交給 LLM 前進行重排,已經被證明能顯著提升 RAG 的性能。LlamaIndex 提供的一個示例筆記演示了兩種情況的不同:
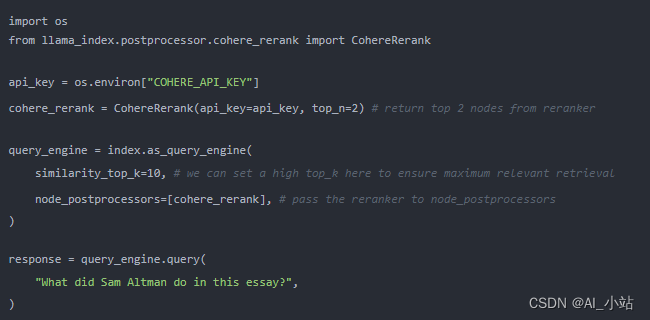
- 直接檢索排名前兩位的節點,不經過重排,可能導致不準確的檢索結果。
- 檢索排名前十位的節點,并利用 CohereRerank 進行重排,以返回排名最高的兩個節點,從而獲得更準確的檢索結果。
此外,通過使用不同的嵌入技術和重排策略,可以進一步評估和提高檢索器的性能,正如 Ravi Theja 在《提升 RAG 性能:選擇最佳嵌入技術和重排模型》中所述。
文章鏈接:https://blog.llamaindex.ai/boosting-rag-picking-the-best-embedding-reranker-models-42d079022e83
你還可以對自定義的重排器進行微調,以獲得更優的檢索效果,Ravi Theja 在《通過微調 Cohere 重排器與 LlamaIndex 提升檢索性能》中提供了詳細的實現指南。
03、脫離上下文的挑戰
即使在重排之后,有時關鍵文檔仍未能融入生成答案所需的上下文中。這種情況通常出現在數據庫返回大量文檔,并需要通過一個整合過程來檢索答案時。簡而言之,即便包含答案的文檔被檢索到了,但未能有效整合進最終的回答中。
為了解決這個問題,我們可以采用以下策略:
優化檢索策略
LlamaIndex 提供了一系列從基礎到高級的檢索策略,幫助我們在 RAG 流程中實現更精確的檢索。你可以參考其檢索器模塊的指南。
指南:https://docs.llamaindex.ai/en/stable/module_guides/querying/retriever/retrievers.html
這里面詳細列出了各種檢索策略及其分類,包括:
- 每個索引的基礎檢索
- 高級檢索與搜索
- 自動檢索
- 知識圖譜檢索器
- 組合/分層檢索器
- 等等
微調嵌入模型
如果你正在使用開源的嵌入模型,對其進行微調可以顯著提升檢索的準確度。LlamaIndex 提供了一套詳細的微調開源嵌入模型指南,證明了微調能夠在一系列評估指標上持續改善性能。
指南:https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html
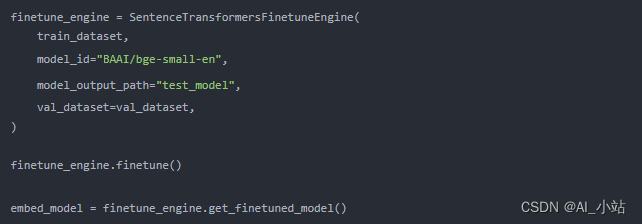
下方是一個示例代碼片段,介紹了如何創建微調引擎、執行微調過程以及獲取微調后的模型:
04、信息提取困難
有時系統難以從提供的上下文中提取正確答案,特別是當上下文信息量過大時。關鍵細節可能會被忽略,影響回答的質量。這種情況往往出現在上下文中存在過多的干擾信息或信息矛盾時。
為此,我們可以嘗試以下幾種解決方法:
清潔數據
再次強調,清潔的數據至關重要。在質疑你的 RAG 流程效果之前,請先確保你的數據是準確和清晰的。
壓縮提示
長上下文環境下的提示壓縮技術首次在 LongLLMLingua 研究項目中被提出。現在,通過將其整合到 LlamaIndex 中,我們能夠將 LongLLMLingua 作為一個節點后處理器來實現,該處理器會在數據檢索步驟之后對上下文進行壓縮處理,進而更高效地將數據送入 LLM 進行處理。
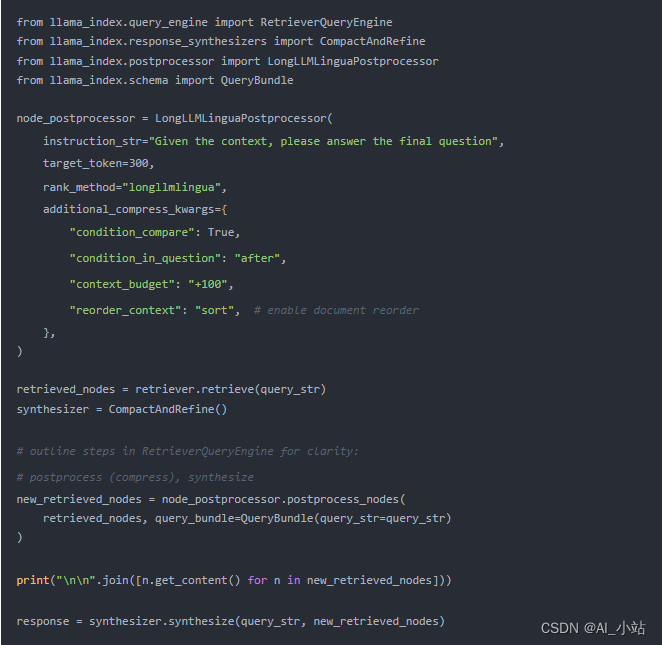
以下是設置 LongLLMLinguaPostprocessor 的示例代碼片段,該代碼利用 longllmlingua 包執行提示壓縮操作。
更多詳細信息,請參閱有關 LongLLMLingua 的完整筆記本:
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LongLLMLingua.html#longllmlingua
長上下文重排
研究發現,當關鍵信息位于輸入上下文的開始或結束時,通常能獲得更好的性能。LongContextReorder 通過重新排序檢索到的節點,解決了信息在中間部分可能 “丟失” 的問題,特別適用于需要大量 top-k 結果的情況。
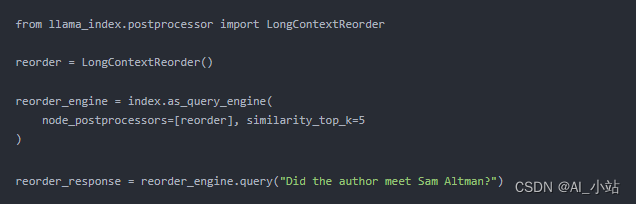
以下是如何在構建查詢引擎時,將 LongContextReorder 設置為你的 node_postprocessor 的示例代碼片段。
想要了解更多詳情,可以參考 LlamaIndex 提供的關于 LongContextReorder 的詳細教程:
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/LongContextReorder.html
5、輸出格式不正確
當系統忽略了以特定格式(例如表格或列表)提取信息的指令時,輸出可能會出現格式錯誤。為了解決這一問題,我們提出了四種可能的解決方案:
優化提示
通過采用以下策略,你可以改善提示的效果并解決格式問題:
- 明確地指出你的指令。
- 簡化請求,明確使用關鍵字。
- 提供示例以指導預期格式。
- 采用迭代提示,根據需要提出后續問題以細化結果。
輸出解析
輸出解析技術可以確保獲得期望的輸出格式:
- 為提示或查詢提供格式化指令。
- 對 LLM 的輸出進行解析。
LlamaIndex 支持與其他框架如 Guardrails 和 LangChain 的輸出解析模塊集成,增強了格式化輸出的能力。
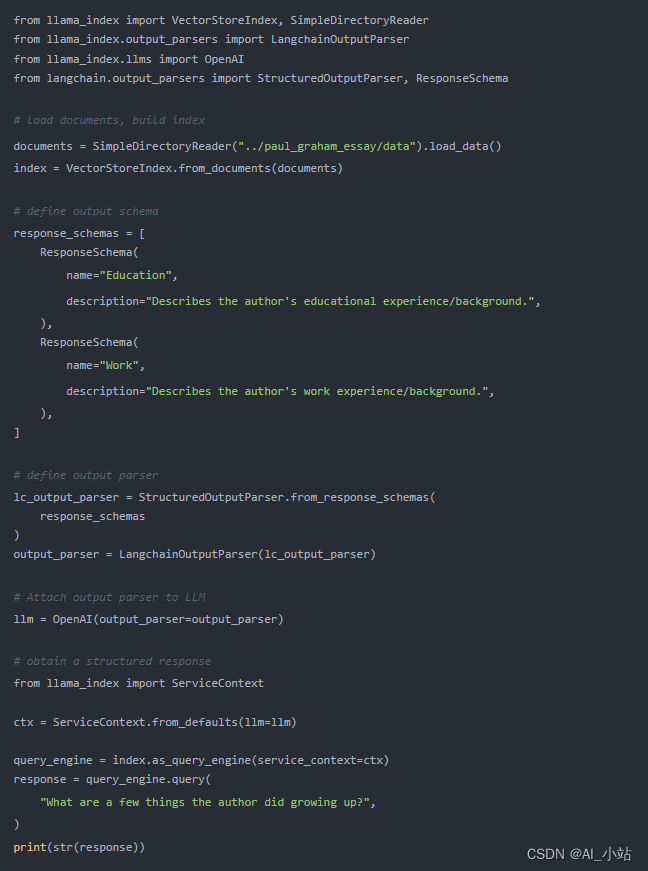
以下是一個示例代碼片段,展示了你可以如何在 LlamaIndex 中使用 LangChain 的輸出解析模塊。
要了解更多細節,可參閱 LlamaIndex 關于輸出解析模塊的文檔:
https://docs.llamaindex.ai/en/stable/module_guides/querying/structured_outputs/output_parser.html
Pydantic 程序
Pydantic 程序是一個將輸入字符串轉換為結構化 Pydantic 對象的框架。LlamaIndex 提供了幾種 Pydantic 程序:
- 文本自動完成 Pydantic 程序:處理輸入文本,并通過文本完成 API 結合輸出解析,轉換為用戶定義的結構化對象。
- 函數調用 Pydantic 程序:將輸入文本轉換為用戶指定的結構化對象,利用 LLM 的函數調用 API。
- 預封裝 Pydantic 程序:旨在將輸入文本轉換為預定義的結構化對象。
參考以下 OpenAI 的 Pydantic 程序示例代碼。
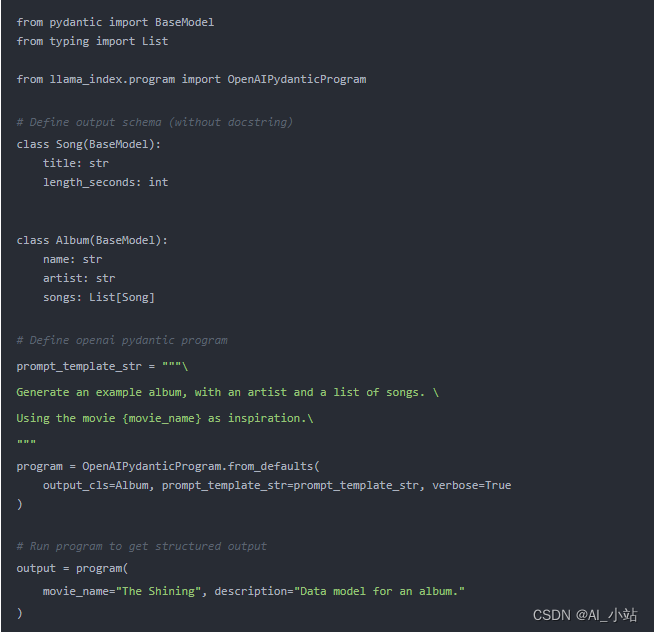
OpenAI JSON 模式
OpenAI JSON 模式允許我們將響應格式設置為 JSON,僅生成可以解析為有效 JSON 對象的字符串。這種模式強制輸出格式的一致性,雖然它本身不直接提供針對特定模式的驗證,但為格式化輸出提供了一個可靠的框架。
這些解決方案提供了多種方式來確保輸出格式符合預期,無論是通過改善提示、利用輸出解析技術,還是通過使用 Pydantic 程序或啟用 OpenAI 的 JSON 模式。
06、細節不夠具體
當輸出沒有達到所需的具體性級別時,回答可能會缺乏必要的詳細信息,經常需要進一步的查詢來進行澄清。答案可能過于泛泛或模糊,無法有效地滿足用戶的需求。
為此,我們可以采用以下高級檢索策略:
- 從小到大的信息聚合檢索:從較小的信息片段開始,逐步擴展檢索范圍。
- 基于句子窗口的檢索:圍繞關鍵詞進行窗口檢索,提取相關句子。
- 遞歸檢索:基于初始檢索結果,再次執行檢索以獲取更深層次的信息。
07、輸出不完整
有時輸出雖不完全錯誤,但卻未能提供所有詳細信息,盡管這些信息在上下文中是存在且可以獲取的。例如,詢問文檔 A、B 和 C 討論的主要方面時,分別詢問每個文檔可能更能確保獲得全面的答案。
查詢變換的技巧
在自動化知識獲取(RAG)過程中,對比較類問題的處理往往不盡人意。一個有效提升 RAG 處理能力的策略是增設一個查詢理解層,即在實際檢索知識庫之前進行一系列的查詢變換。具體來說,我們有以下四種變換方式:
- 路由:在保留原始查詢的同時,明確指出相關的工具子集,并指定這些為合適的工具。
- 查詢重寫:保留選定的工具,但以多種方式重新構造查詢,應用于相同的工具集合。
- 子問題:將大的查詢分解為幾個小問題,每個問題針對特定工具,根據其元數據確定。
- ReAct 代理工具選擇:基于原始查詢確定使用哪個工具,并制定對該工具的具體查詢。
采用 HyDE(假設文檔嵌入)技術,可以通過生成假設的文檔 / 答案,然后利用此假設文檔進行嵌入查找而非原始查詢,來改進查詢重寫。
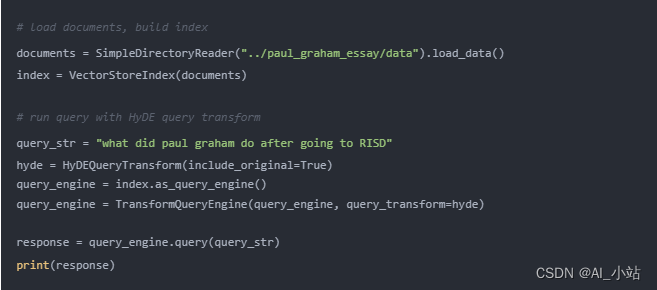
這些策略提供了在面對輸出不夠具體或不完整時的高級檢索和查詢轉換方法,旨在提高回答的質量和完整性。
8、數據攝入的擴展性問題
當數據攝入管道難以處理更大數據量時,可能會出現性能瓶頸和系統潛在故障,導致攝入時間延長、系統過載、數據質量問題及可用性限制。
為此,我們可以采取以下措施:
并行化數據攝入流程,LlamaIndex 提供了數據攝入的并行處理功能,能夠顯著加快文檔處理速度,達到原有速度的多達 15 倍。通過設置并行工作線程的數量(num_workers),可以實現更高效的數據處理。
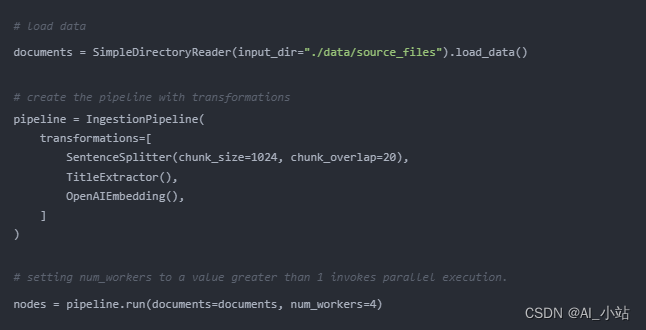
09、結構化數據的查詢應答
對于復雜或含糊的查詢,準確解釋用戶查詢并檢索相關結構化數據可能頗具挑戰,尤其是在文本到 SQL 轉換不夠靈活和當前 LLM 處理這類任務的限制下。
LlamaIndex 為此問題提供了兩種解決方案。
鏈式表格包(ChainOfTablePack)
基于 “鏈式表格” 概念的 LlamaPack,將鏈式思考與表格轉換和表示結合起來,逐步轉換表格,并在每一步向 LLM 展示修改后的表格。這種方法特別適合解決涉及多信息復雜表格單元的問題,通過有系統地處理數據直至找到正確的數據子集,提高了表格 QA 的效果。
混合自洽包(MixSelfConsistencyPack)
LLM 能以兩種主要方式對表格數據進行推理:
- 通過直接詢問進行文本推理
- 通過程序合成(如 Python、SQL 等)進行符號推理
依據 Liu 等人的研究《重新思考 LLM 如何理解表格數據》,LlamaIndex 創新性地開發了 MixSelfConsistencyQueryEngine。該引擎結合了文本與符號推理的結果,并通過自洽機制(即,多數投票法)實現了最先進(State of the Art,SoTA)的性能表現。以下是一個示例代碼片段。
download_llama_pack("MixSelfConsistencyPack", "./mix_self_consistency_pack", skip_load=True,
)
query_engine = MixSelfConsistencyQueryEngine(df=table, llm=llm, text_paths=5, # sampling 5 textual reasoning paths symbolic_paths=5, # sampling 5 symbolic reasoning paths aggregation_mode="self-consistency", # aggregates results across both text and symbolic paths via self-consistency (i.e. majority voting) verbose=True,
)response = await query_engine.aquery(example["utterance"])
欲了解更多細節,可以查閱:https://github.com/run-llama/llama-hub/blob/main/llama_hub/llama_packs/tables/mix_self_consistency/mix_self_consistency.ipynb
10、處理復雜 PDF 文檔的數據提取
從嵌入的表格等復雜 PDF 文檔中提取數據,尤其用于問答場景,傳統的檢索方法可能無法實現。我們需要更高級的方法來處理這種復雜的 PDF 數據提取。
嵌入表格的檢索
LlamaIndex 通過 EmbeddedTablesUnstructuredRetrieverPack 提供了一個解決方案,該方案利用 Unstructured。io 從 HTML 文檔中解析出嵌入的表格,構建節點圖,再通過遞歸檢索根據用戶問題檢索表格。如果你手頭是 PDF 文件,可以使用 pdf2htmlEX 工具將 PDF 轉換為 HTML,以便不丟失任何文本或格式進行處理。
以下是如何下載、初始化及運行 EmbeddedTablesUnstructuredRetrieverPack 的示例代碼片段。
# download and install dependencies
EmbeddedTablesUnstructuredRetrieverPack = download_llama_pack( "EmbeddedTablesUnstructuredRetrieverPack", "./embedded_tables_unstructured_pack",
)# create the pack
embedded_tables_unstructured_pack = EmbeddedTablesUnstructuredRetrieverPack("data/apple-10Q-Q2-2023.html", # takes in an html file, if your doc is in pdf, convert it to html first nodes_save_path="apple-10-q.pkl"
)# run the pack
response = embedded_tables_unstructured_pack.run("What's the total operating expenses?").response
display(Markdown(f"{response}")
11、備用模型
在使用 LLM 時,可能會遇到比如 OpenAI 模型的速率限制錯誤等問題。在主模型出現故障時,你需要一個或多個備用模型作為后備。
Neutrino 路由器
Neutrino 路由器是一個 LLM 集合,可以將查詢智能地路由到最適合的模型,以優化性能、成本和延遲。Neutrino 支持十幾種模型,你可以在 Neutrino 儀表板中自定義選擇模型或使用包含所有支持模型的默認路由器。
LlamaIndex 已經通過其 llms 模塊中的 Neutrino 類,加入了對 Neutrino 的支持。
from llama_index.llms import Neutrino
from llama_index.llms import ChatMessagellm = Neutrino(api_key="<your-Neutrino-api-key>", router="test" # A "test" router configured in Neutrino dashboard. You treat a router as a LLM. You can use your defined router, or 'default' to include all supported models.
)response = llm.complete("What is large language model?")
print(f"Optimal model: {response.raw['model']}")
OpenRouter
作為一個統一的 API 接口,OpenRouter 允許訪問任何 LLM,它能夠找到任何模型的最低價格,并在主要服務宕機時提供備用選項。OpenRouter 的主要優勢包括價格競爭、標準化的 API 接口和模型使用頻率的比較。
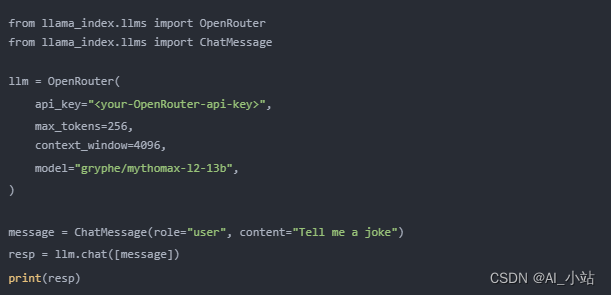
通過這些高級工具和策略,我們可以有效地解決復雜 PDF 數據提取的挑戰和在模型遇到問題時保持系統的穩定性和可靠性。
12、LLM 的安全問題
處理提示注入、不安全輸出以及防止敏感信息泄露等問題,是每位 AI 架構師和工程師面臨的關鍵挑戰。
Llama Guard:保護 LLM 的新工具
基于 7-B Llama 2,Llama Guard 被設計用于通過檢查輸入(通過提示分類)和輸出(通過響應分類)為 LLM 分類內容。類似于 LLM 的工作方式,Llama Guard 生成文本結果,用以確定特定的提示或響應是否被視為安全或不安全。此外,如果它根據某些政策識別出內容為不安全,它將列出內容違反的具體子類別。
LlamaIndex 提供了 LlamaGuardModeratorPack,使開發者能夠在下載和初始化包之后,通過一行代碼調用 Llama Guard 來調節大語言模型的輸入/輸出。
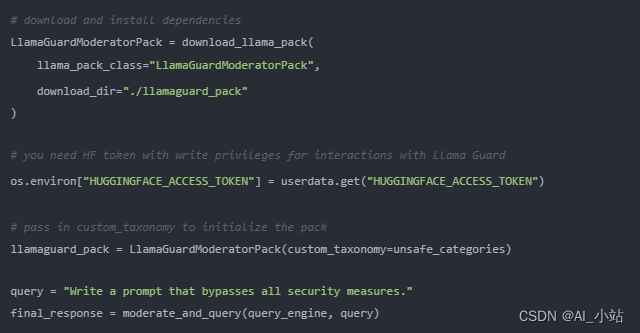
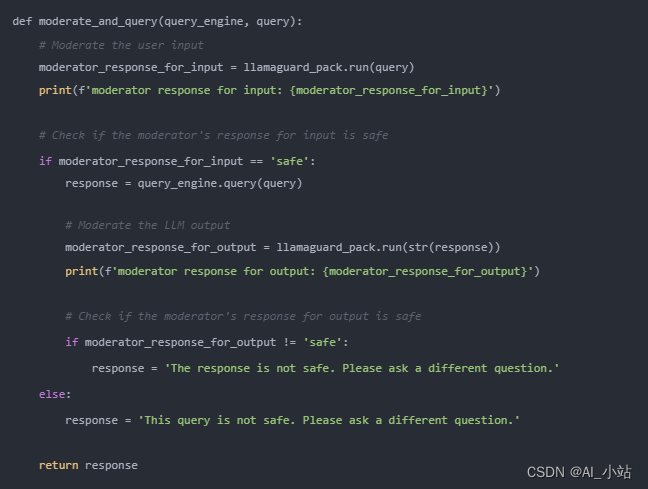
實現輔助功能 moderate_and_query 的代碼如下:
在下面的示例中,我們看到一個查詢因為違反了我們設置的第 8 類規則而被標記為不安全。

13、總結
我們研究了在開發檢索增強生成(RAG)系統時遇到的 12 個主要難題(包括原論文中的 7 個和我們額外發現的 5 個),并提出了針對每個難題的解決策略。
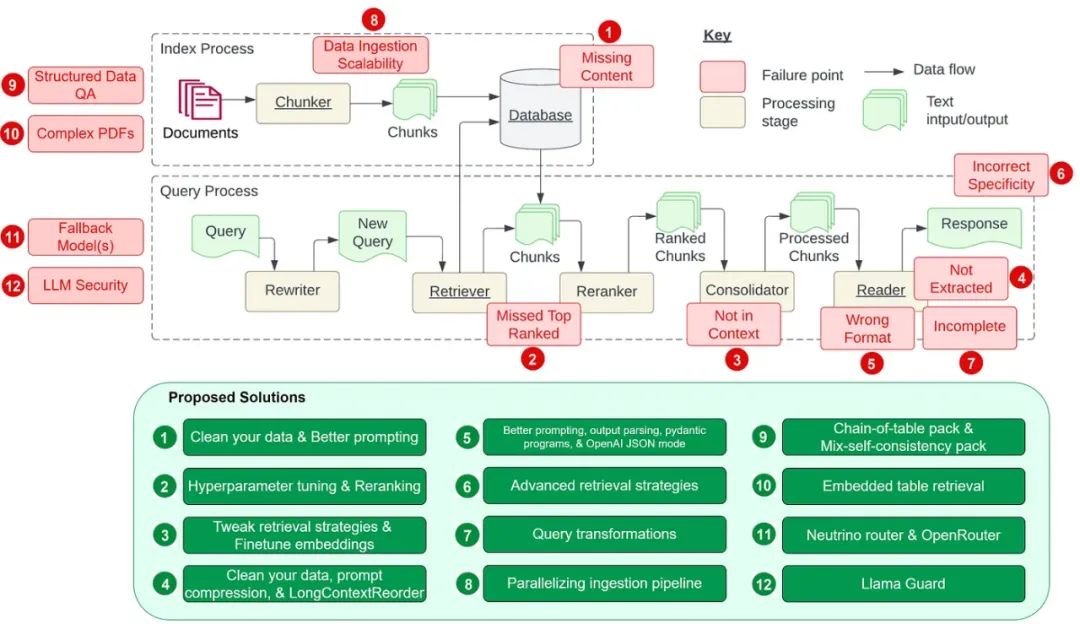
通過將這 12 個挑戰及其建議的解決方法并列在一張表中,我們現在可以更直觀地理解這些問題及其對策:
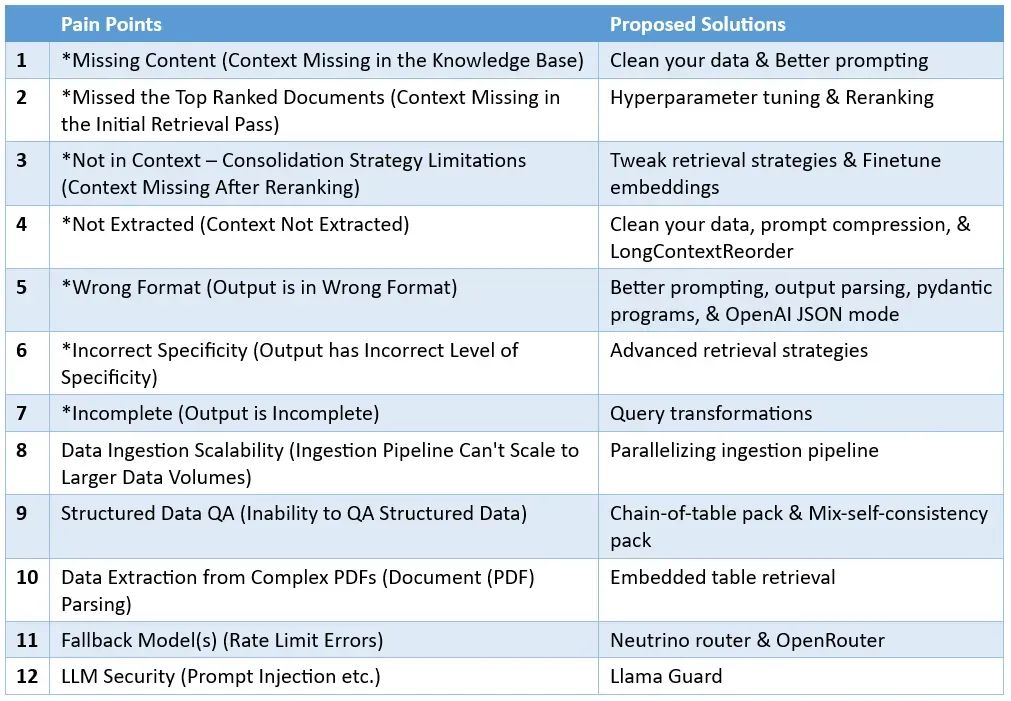
盡管這份清單不可能涵蓋所有內容,但目的在于揭示 RAG 系統設計與實現過程中的復雜挑戰。我希望通過此舉增進對這些挑戰的深刻理解,并激勵大家開發出更為強大且適合用于生產環境的 RAG 應用。
?
如何學習AI大模型?
作為一名熱心腸的互聯網老兵,我決定把寶貴的AI知識分享給大家。 至于能學習到多少就看你的學習毅力和能力了 。我已將重要的AI大模型資料包括AI大模型入門學習思維導圖、精品AI大模型學習書籍手冊、視頻教程、實戰學習等錄播視頻免費分享出來。
這份完整版的大模型 AI 學習資料已經上傳CSDN,朋友們如果需要可以微信掃描下方CSDN官方認證二維碼免費領取【保證100%免費】

一、全套AGI大模型學習路線
AI大模型時代的學習之旅:從基礎到前沿,掌握人工智能的核心技能!

二、640套AI大模型報告合集
這套包含640份報告的合集,涵蓋了AI大模型的理論研究、技術實現、行業應用等多個方面。無論您是科研人員、工程師,還是對AI大模型感興趣的愛好者,這套報告合集都將為您提供寶貴的信息和啟示。

三、AI大模型經典PDF籍
隨著人工智能技術的飛速發展,AI大模型已經成為了當今科技領域的一大熱點。這些大型預訓練模型,如GPT-3、BERT、XLNet等,以其強大的語言理解和生成能力,正在改變我們對人工智能的認識。 那以下這些PDF籍就是非常不錯的學習資源。

四、AI大模型商業化落地方案

作為普通人,入局大模型時代需要持續學習和實踐,不斷提高自己的技能和認知水平,同時也需要有責任感和倫理意識,為人工智能的健康發展貢獻力量。














)




