DeepFlow 實戰:eBPF 技術如何提升故障排查效率
目錄
DeepFlow 實戰:eBPF 技術如何提升故障排查效率
微服務架構系統中各個服務、組件及其相互關系的全景
零侵擾分布式追蹤(Distributed Tracing)的架構和工作流程
關于零侵擾持續性能剖析(Continuous Profiling)的報告
關于前端404錯誤處理的會議內容
業務異常 - 一分鐘解決前端404錯誤
業務異常中偶現的503異常問題,旨在實現分鐘級定位并快速解決。
業務異常中偶現的503異常問題,旨在實現分鐘級定位并快速解決。
圍繞隱藏Bug的識別和消除,以及新版本上線后CPU飆升問題的處理展開
服務超時問題的深入分析和解決策略,特別是針對新功能上線后日志中頻繁出現的第三方服務API調用超時問題
探討了eBPF(Extended Berkeley Packet Filter)技術在提升故障排障效率方面的應用。


會議中剖析了云原生應用架構的演進過程及其帶來的復雜性和挑戰。圖表通過路徑和節點的方式,清晰地展示了從業務代碼、框架代碼到微服務、容器和虛擬機等不同層次的技術和服務。隨著技術的演進,路徑逐漸增多,基礎設施的復雜性也急劇增長。
我們可以看到業務代碼和框架代碼作為應用的核心,通過應用進程、代理進程等組件與微服務、容器和虛擬機等基礎設施進行交互。這種架構的演進使得服務發布更加快速,單個服務更加簡單,同時通用邏輯逐漸被卸載至基礎設施,為開發語言和框架提供了更大的自由度。
然而,這種演進也帶來了諸多挑戰。插樁困難、追蹤盲點、標簽不足、容量焦慮以及資源消耗過多等問題,都是云原生應用架構在演進過程中需要面對和解決的難題。
為了解決這些問題,使用Prometheus、OpenTelemetry、fluentd、Kafka、Redis、Kubernetes等一系列云原生技術和工具,它們為全棧可觀測性提供了支持,幫助開發者更好地監控、追蹤和管理云原生應用。
會議中不僅展示云原生應用架構的演進過程,還揭示了其帶來的復雜性和挑戰,以及可能的解決方案。
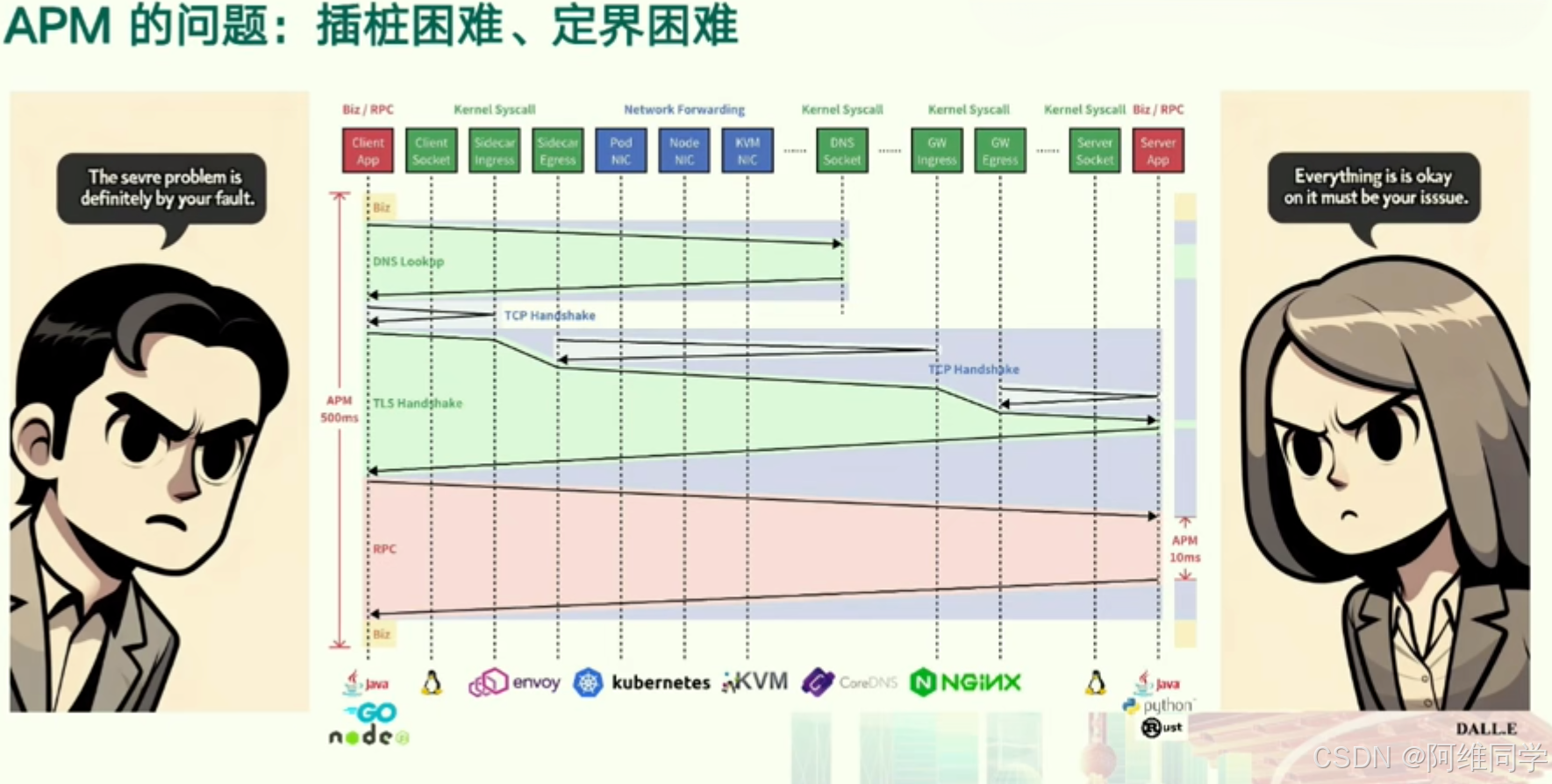
其中深入剖析了微服務架構中應用程序性能監控(APM)所面臨的兩大核心挑戰:
插樁困難和定界困難。
- 插樁困難主要體現在微服務架構中服務數量的龐大上。由于每個服務都需要進行插樁以收集性能數據,這導致了巨大的工作量。同時,插樁過程可能會引入額外的延遲,從而對服務的性能產生負面影響。
- 定界困難則源于微服務架構中服務間復雜的依賴關系。一個服務的問題可能會波及到其他服務,使得跨服務追蹤和日志管理變得異常復雜,難以迅速準確地定位問題所在。
- 一方堅信問題源于對方的故障,而另一方則堅稱一切運行正常。這種情境凸顯了在微服務架構中,APM在快速定位和解決性能問題方面的重要性。
- 此外,微服務架構中的關鍵組件,如客戶端、服務、網關、緩存、數據庫等,以及它們之間的調用關系。通過APM工具(如Zipkin、Jaeger等)來追蹤和監控這些調用,可以幫助我們更好地識別性能瓶頸和問題所在。
- 會議中強調了微服務架構中APM的重要性,還揭示了插樁和定界兩大挑戰。為了有效地管理和監控微服務架構的性能,我們需要借助先進的APM工具和方法,以應對這些挑戰。
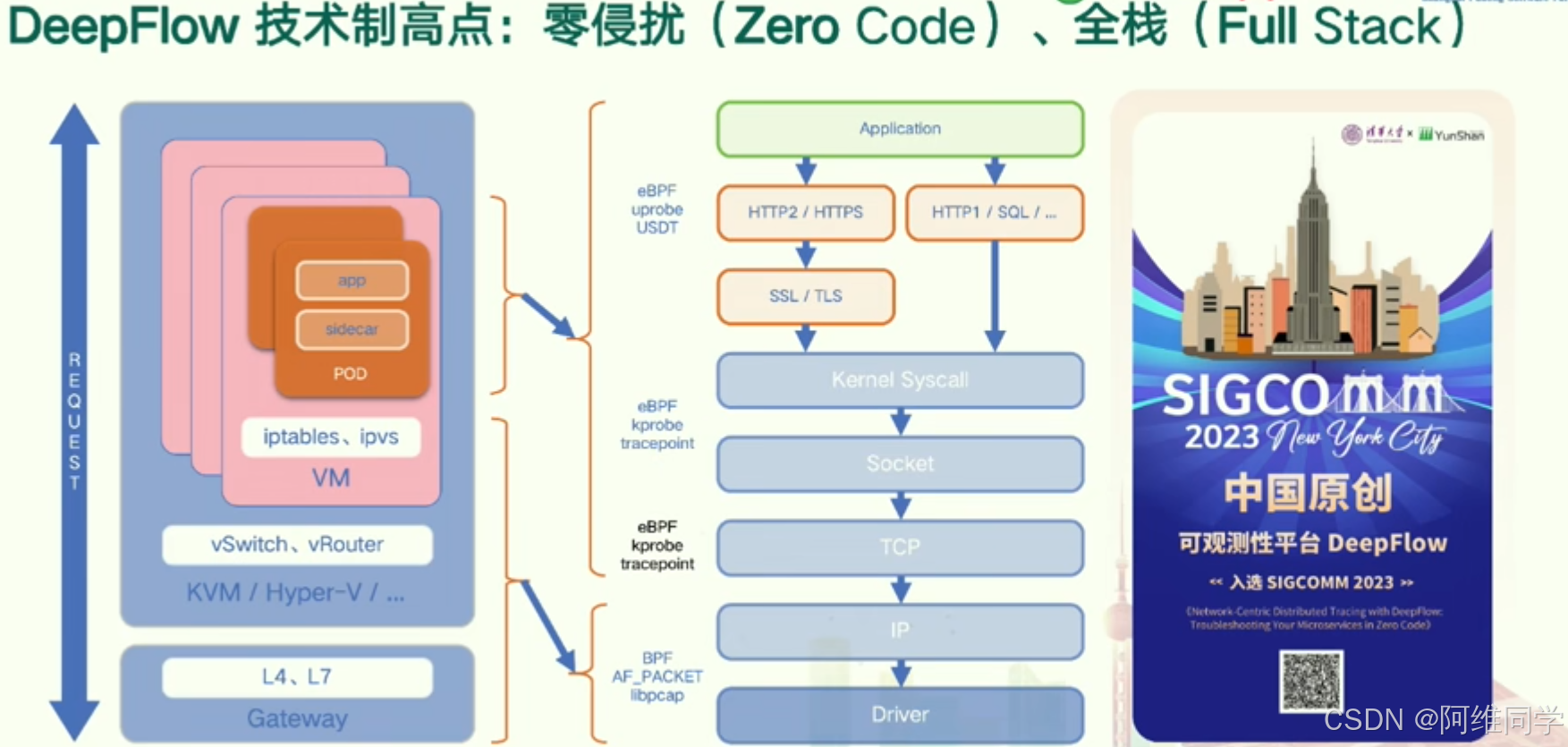
DeepFlow技術框架以其全棧(Full Stack)和零侵入(Zero Code)的特性,展示了其技術制高點。該框架支持多種網絡協議,如HTTP2/HTTPS、HTTP1/SQL、SSL/TLS等,并兼容多種編程語言或框架,如Go、Java、Rust、K8s、C++、Node.js等,確保應用的廣泛適用性和靈活性。
DeepFlow通過eBPF(Extended Berkeley Packet Filter)技術,在內核級別實現功能,如Kprobe和Tracepoint,支持Socket、TCP、IP等網絡協議,為系統提供深入的網絡觀測能力。同時,該框架也支持虛擬機(VM)中的iptables、ipvs等網絡功能,以及L4、L7層網關,確保在虛擬化環境中的高效網絡管理。
DeepFlow還包含vSwitch和vRouter組件,支持KVM/Hyper-V等虛擬化技術,為網絡流量提供靈活的路由和交換功能。在驅動程序層面,它支持BPF(Berkeley Packet Filter)和AF_PACKET接口,確保網絡數據的高效處理和傳輸。
用戶空間方面,DeepFlow框架集成了POD、側車(Sidecar)等組件,為用戶提供豐富的網絡服務和應用支持。整個框架通過eBPF技術實現全棧和零侵入的特點,能夠無縫集成到現有的系統中,無需修改現有代碼,提供高效和靈活的網絡觀測和分析能力。
在SIGCOMM 2023紐約城市會議上,DeepFlow框架被選為觀測性平臺,展示了其在中國原創技術領域的領先地位和可靠性。通過這張技術架構圖,我們可以清晰地看到DeepFlow框架的組成和優勢,以及它在網絡觀測和分析領域的廣泛應用前景。
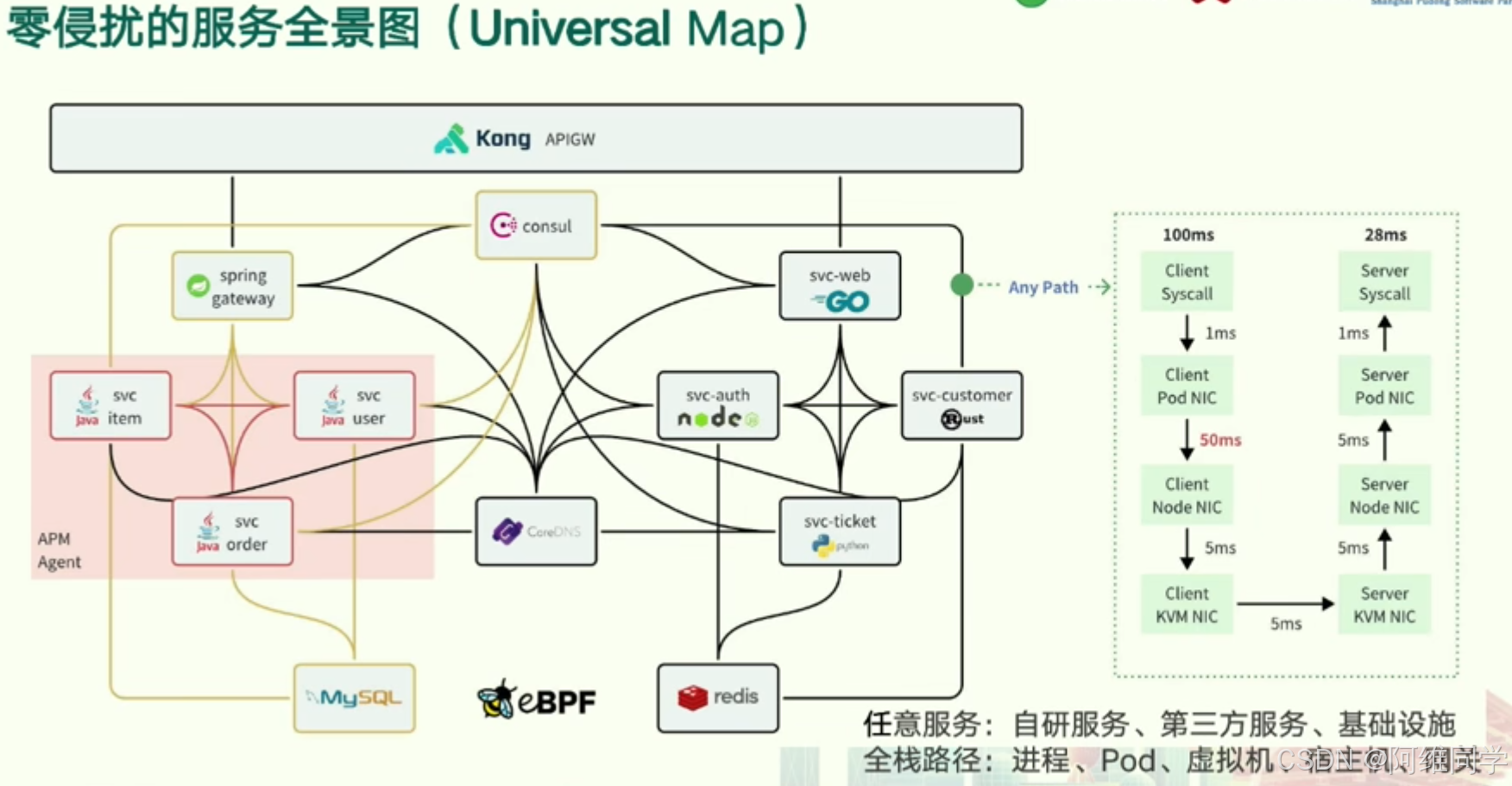
微服務架構系統中各個服務、組件及其相互關系的全景
- 核心組件:
- Kong API Gateway:作為系統的入口點,負責接收并處理來自客戶端的HTTP/S請求。
- Spring Gateway:在微服務架構內部,用于請求路由和轉發。
- Consul:提供服務發現、配置管理和服務協調功能。
- 微服務:如svc-web、svc-item、svc-user、svc-order、svc-customer等,各自負責不同的業務邏輯。
- 數據庫:MySQL作為關系型數據庫,Redis作為緩存數據庫,為微服務提供數據存儲和查詢服務。
- eBPF:擴展Berkeley Packet Filter,用于網絡數據包過濾,確保數據的安全性。
- 服務間通信:
- 客戶端請求首先通過Kong API Gateway,隨后被轉發至Spring Gateway或相應的微服務。
- 微服務之間通過REST API進行通信,實現業務邏輯的解耦和協同。
- 部署環境:
- 圖中展示了服務可以部署在多種環境中,包括Pod(如Kubernetes Pod)、虛擬機(VM)、宿主機(Host)等,體現了系統的靈活性和可擴展性。
- 性能監控:
- 圖中標注了不同組件之間的時間延遲,如100ms、28ms等,這些指標有助于監控系統的性能瓶頸并進行優化。
- 消息隊列:
- 雖然圖中未明確標出,但根據微服務架構的常見實踐,可以推測系統可能使用了如Kafka等消息隊列系統,用于微服務之間的消息傳遞和異步通信。
- 安全性:
- eBPF的引入,確保了網絡數據包的安全性,只有合法的請求才能到達目標服務。
總結來說,這張全景圖展現了一個微服務架構系統中零侵擾服務的全面視圖,涵蓋了服務發現、請求路由、數據庫交互、消息隊列、網絡過濾等多個方面,為系統的穩定性、可擴展性和安全性提供了有力保障。
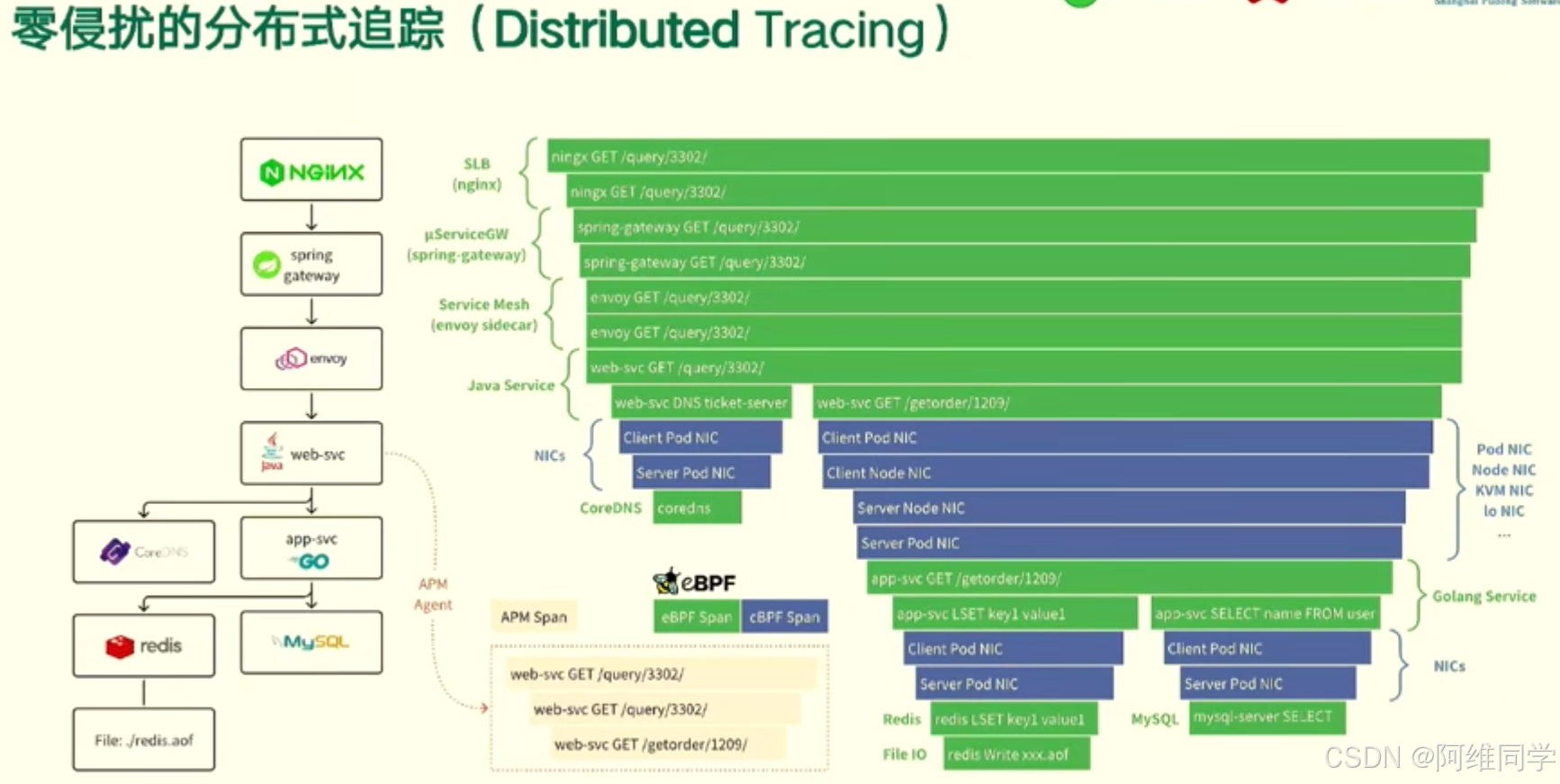
零侵擾分布式追蹤(Distributed Tracing)的架構和工作流程
- 入口與負載均衡:
- NGINX 作為軟件負載均衡器(SLB),負責接收并分發進入系統的請求。
- 請求隨后通過 Spring Gateway,這是一個微服務網關,用于路由、過濾和監控API請求。
- 服務網格:
- Envoy 作為服務網格的代理,負責服務之間的通信,提供流量管理、安全性、可觀察性等功能。
- Java服務:
- Java服務通過web-svc DNS票據服務器進行通信,確保服務之間的可靠連接。
- 使用Nacos作為服務注冊中心,實現服務的自動注冊與發現。
- Redis作為緩存層,用于存儲常用數據,提高系統響應速度。
- MySQL作為關系型數據庫,存儲系統核心數據。
- 應用性能管理(APM):
- SkyWalking作為APM工具,用于收集、分析和聚合系統性能數據。
- 利用eBPF(擴展Berkeley Packet Filter)技術,對網絡數據包進行深度過濾和分析,以提供更精細的性能監控。
- 客戶端與服務器通信:
- 客戶端通過web-svc發起GET請求,獲取所需數據。
- 客戶端和服務器之間的通信可能采用gRPC協議,確保高效、可靠的數據傳輸。
- 客戶端和服務器同樣使用Nacos進行服務注冊與發現,確保服務的動態可用性。
- Redis和MySQL在客戶端和服務器之間共享,確保數據的一致性和高效訪問。
- 文件存儲:
- 使用/redis.aof文件作為Redis的持久化存儲,確保數據在重啟或故障后不會丟失。
整個圖表清晰地展示了從入口到后端服務,再到數據庫和緩存的整個分布式追蹤架構,以及各組件之間的交互關系和數據流動。這為系統運維和性能優化提供了有力的支持。
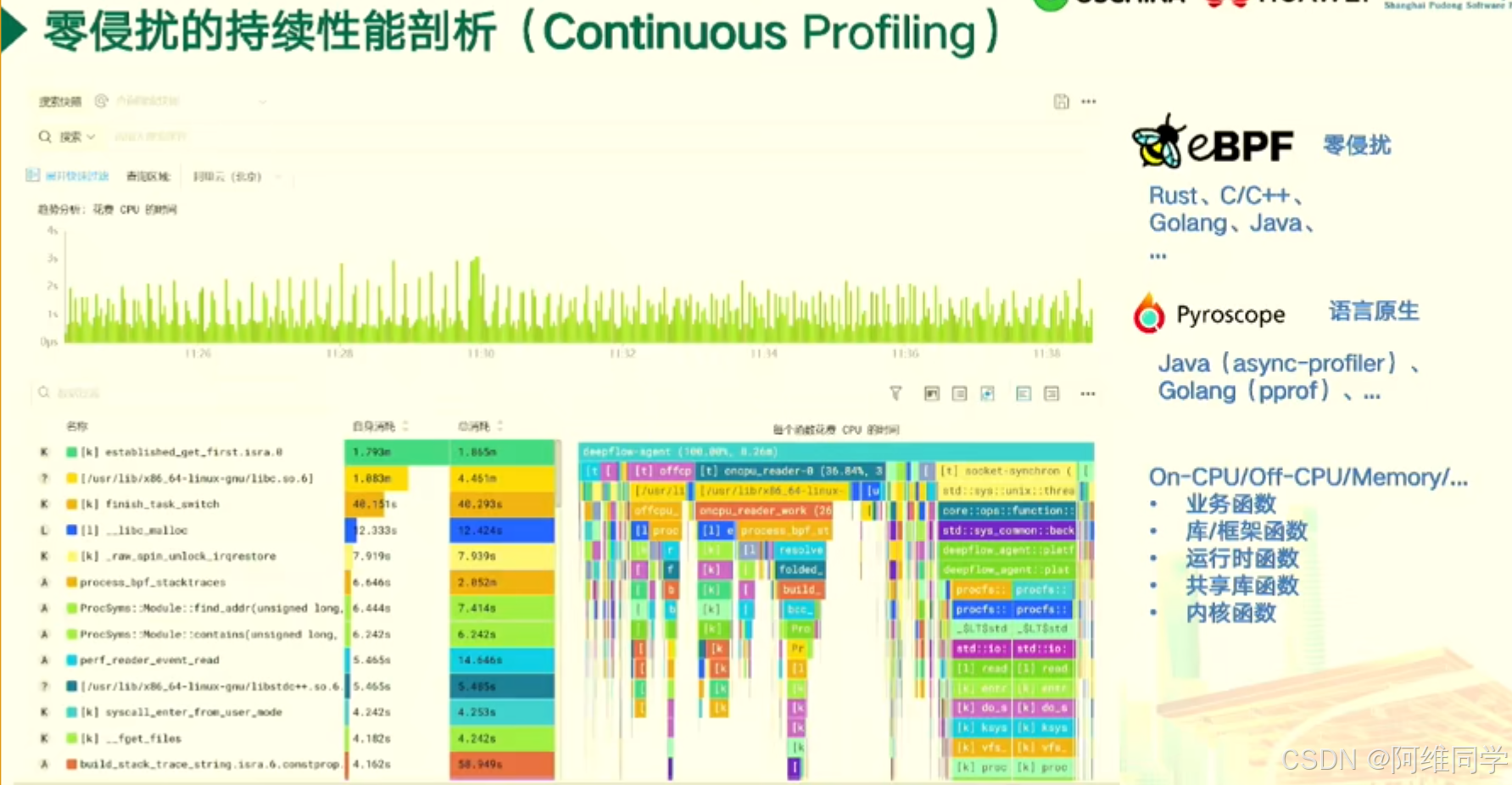
關于零侵擾持續性能剖析(Continuous Profiling)的報告
幫助開發者深入了解應用程序在不同編程語言下的性能表現。報告涵蓋了從11:26到11:58的時間段,并提供了豐富的數據分析和圖表展示。
報告的主要內容包括:
時間范圍與關鍵數據:報告詳細記錄了在此時間段內,應用程序的多個性能指標,如建立的連接數、完成的任務數、內存分配與釋放次數、進程創建與銷毀次數等,為開發者提供了全面的性能概覽。
技術棧與工具:報告基于eBPF(擴展Berkeley Packet Filter)技術,結合Rust、C/C++、Golang和Java等編程語言,利用Pyroscope等工具進行語言原生剖析,確保了對應用程序性能的深入洞察。
圖表分析:報告中的圖表直觀地展示了不同時間段內CPU的使用情況,以及各個函數的調用次數、平均時間和總時間。這些圖表為開發者提供了快速定位性能瓶頸和優化點的依據。
函數統計:報告詳細列出了業務函數、庫函數、運行時函數、共享庫函數和內核函數的統計信息,包括調用次數、平均時間和總時間,幫助開發者了解應用程序中各個部分的性能表現。
性能剖析:通過這份報告,開發者可以清晰地看到應用程序在不同編程語言下的性能差異,以及各個函數對性能的影響。這有助于開發者優化代碼,提高應用程序的性能和效率。

關于前端404錯誤處理的會議內容
- 首先聚焦于前端頁面出現404錯誤的情況,這被識別為業務異常的一種。當用戶在前端遇到空白頁面,且API返回404錯誤時,需要迅速定位并追蹤返回錯誤的服務。
- 在排查步驟上,首先回顧了傳統的排查方法:尋找URL對應的后端服務,分析后端服務的日志,并在日志無訪問記錄時,通過多節點抓包來確認請求走向。接著,會議介紹了引入DeepFlow后的新體驗,通過輸入URL,快速查詢調用日志,并在5分鐘內完成上述步驟,顯著提高了排查效率。
- 會議還強調了錯誤類型的分析,包括通過HTTP調用日志確認返回錯誤的IP地址,以及通過DNS調用日志確認域名解析無異常。這些分析有助于更準確地定位問題所在。
經過深入討論,會議確定了導致訪問異常的根本原因是設置代理不當。這一發現為后續的解決方案提供了重要依據。
最后,展示了排查流程的時間對比,突出了引入DeepFlow后排查時間從數小時縮短到5分鐘的顯著變化。這不僅提高了工作效率,也體現了團隊在應對業務異常時的快速響應能力。

業務異常 - 一分鐘解決前端404錯誤
問題描述:在前端頁面出現空白,同時API返回了404錯誤,這通常意味著服務器無法找到請求的資源。
解決步驟:
- 定位問題:首先,我們查找了與問題URL對應的后端服務,并分析了該服務的日志。由于日志中沒有訪問記錄,我們進一步通過多節點抓包來確認請求的走向。
- 確認錯誤源:接著,我們根據HTTP調用日志確認了返回404錯誤的IP地址或服務器。
- 檢查域名解析:為了確保問題不是由域名解析引起的,我們還檢查了DNS調用日志,確認域名解析無異常。
排障體驗對比:
- 以往:在沒有引入DeepFlow之前,排查此類問題通常需要數小時的時間。
- 現在:通過引入DeepFlow工具,我們能夠在5分鐘內迅速定位并解決404錯誤,大大提高了排障效率。
根本原因:經過深入調查,我們發現問題的根本原因是設置代理導致的訪問異常。
展示了如何通過引入DeepFlow工具,實現對前端404錯誤的快速定位和解決。這不僅提高了我們的工作效率,也為客戶提供了更加穩定可靠的服務體驗。

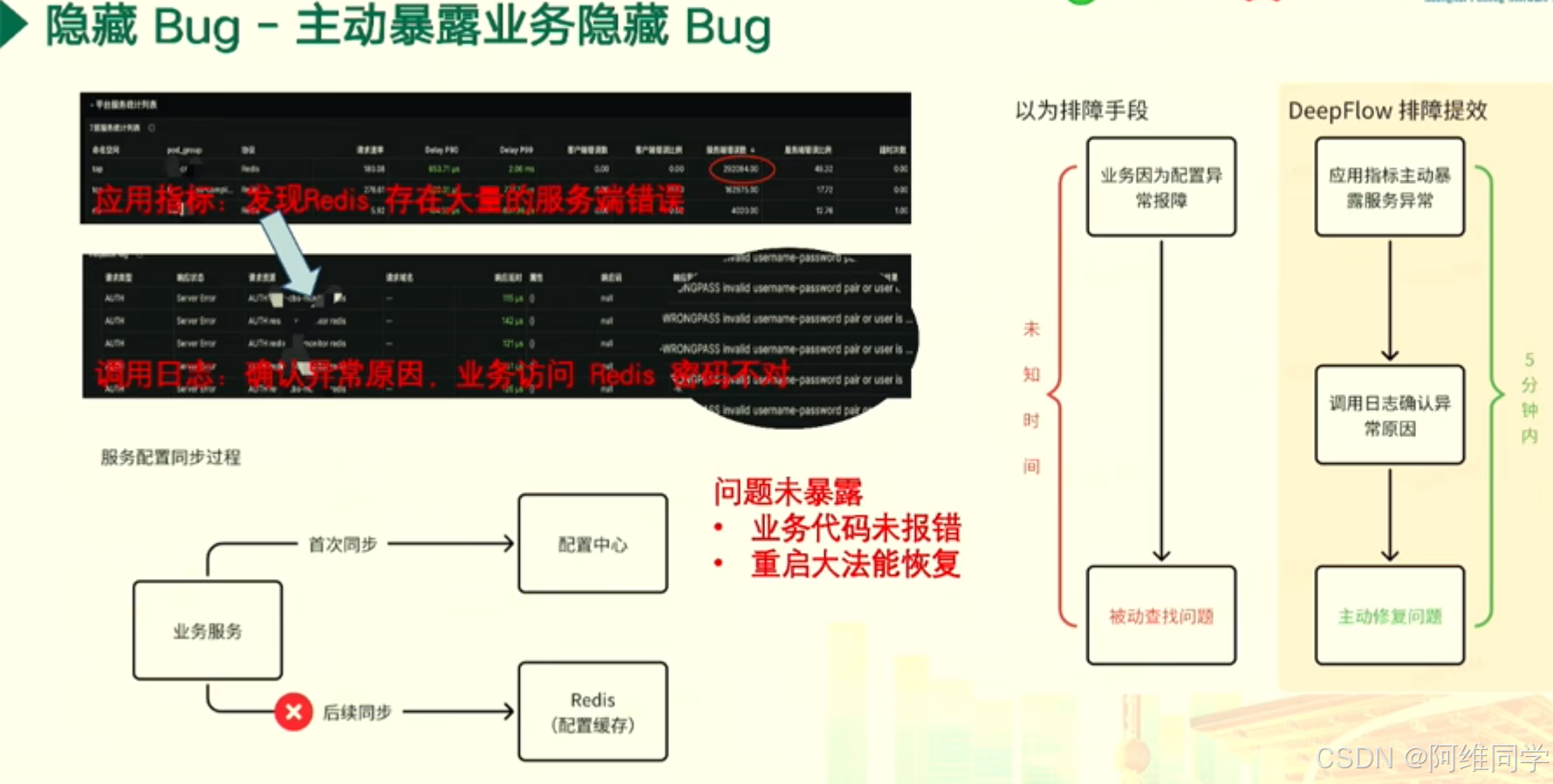
業務異常中偶現的503異常問題,旨在實現分鐘級定位并快速解決。
問題描述:
監控中心偶現訪問異常,具體表現為503 Service Unavailable錯誤。值得注意的是,運維團隊并未主動觸發過503狀態碼,因此需要定位異常原因。分析過程:
- 日志分析:首先,通過快速過濾HTTP調用日志,識別出異常的調用請求。
- 調用鏈追蹤:進一步,利用調用鏈追蹤技術,確認異常服務,并定位問題發生的具體位置。
排查手段:
- 業務梳理:按照研發團隊的指引,梳理業務訪問關系,分析服務日志,以獲取更多關于異常的信息。
- DeepFlow提效:通過輸入503狀態碼,查看詳細的調用日志,并追蹤異常調用的發起和調用鏈,以在五分鐘內迅速確認異常服務。
根本原因分析:
經過深入分析,發現業務高峰期時,服務存在瓶頸,導致資源不足,從而引發503異常。解決方案:
基于上述分析,提出了針對性的解決方案:
- 服務擴容:針對業務高峰期,進行服務擴容,確保資源充足,避免再次出現503異常。
- 持續優化:持續關注業務運行狀況,通過技術優化和流程改進,提升系統的穩定性和可用性。
對偶發503異常問題的快速定位和分析,并提出了有效的解決方案。通過日志分析、調用鏈追蹤和業務梳理等手段,不僅找到了問題的根本原因
業務異常中偶現的503異常問題,旨在實現分鐘級定位并快速解決。
問題描述:
監控中心偶現訪問異常,具體表現為503 Service Unavailable錯誤。值得注意的是,運維團隊并未主動觸發過503狀態碼,因此需要定位異常原因。分析過程:日志分析:首先,通過快速過濾HTTP調用日志,識別出異常的調用請求。調用鏈追蹤:進一步,利用調用鏈追蹤技術,確認異常服務,并定位問題發生的具體位置。
排查手段:
- 業務梳理:按照研發團隊的指引,梳理業務訪問關系,分析服務日志,以獲取更多關于異常的信息。
- DeepFlow提效:通過輸入503狀態碼,查看詳細的調用日志,并追蹤異常調用的發起和調用鏈,以在五分鐘內迅速確認異常服務。
根本原因分析:
經過深入分析,發現業務高峰期時,服務存在瓶頸,導致資源不足,從而引發503異常。解決方案:
基于上述分析,提出了針對性的解決方案:
- 服務擴容:針對業務高峰期,進行服務擴容,確保資源充足,避免再次出現503異常。
- 持續優化:持續關注業務運行狀況,通過技術優化和流程改進,提升系統的穩定性和可用性。
成功實現了對偶發503異常問題的快速定位和分析,并提出了有效的解決方案。通過日志分析、調用鏈追蹤和業務梳理等手段,不僅找到了問題的根本原因,還提出了針對性的改進措施
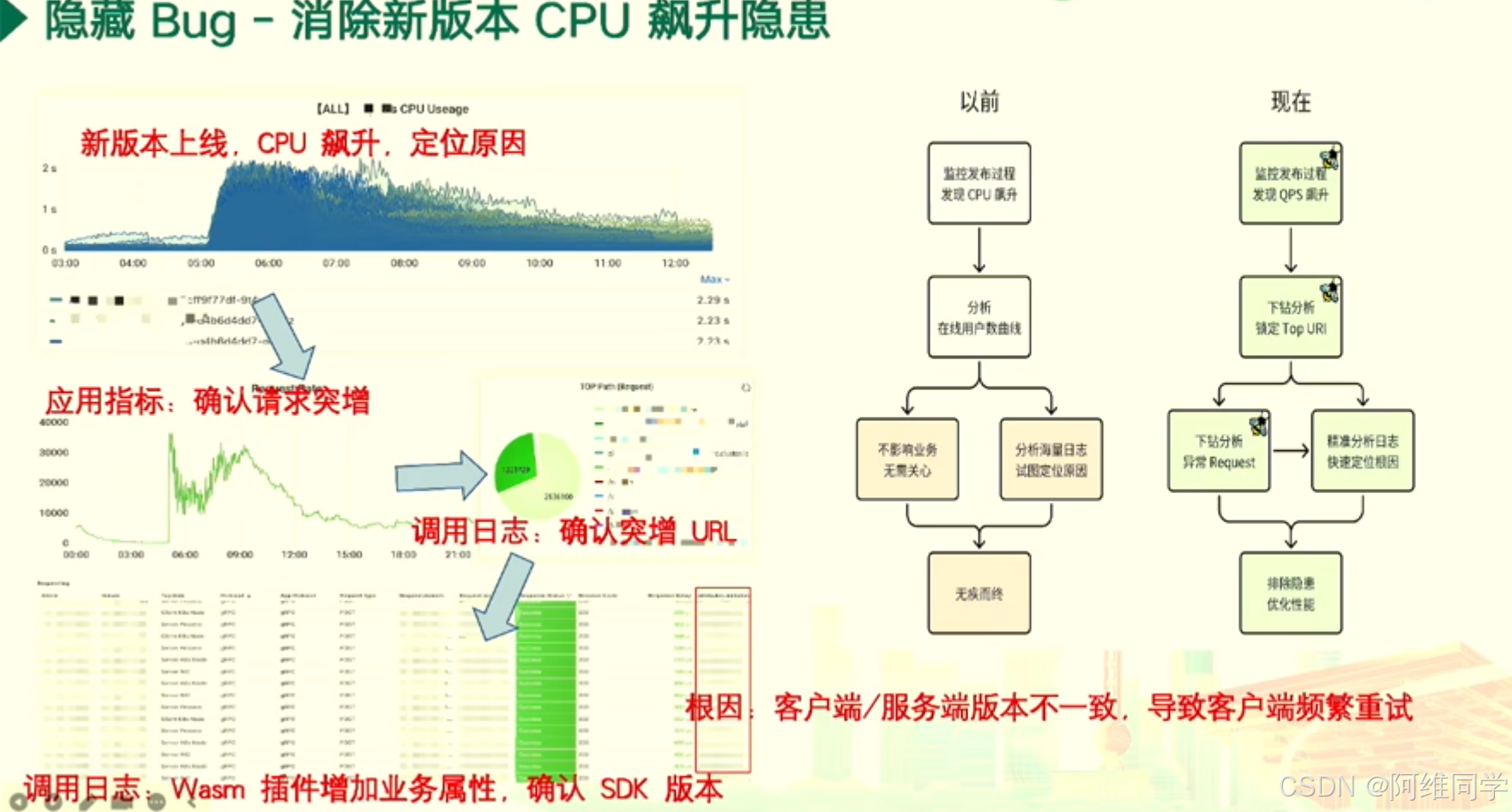
圍繞隱藏Bug的識別和消除,以及新版本上線后CPU飆升問題的處理展開
- 首先,會議通過CPU使用率的圖表,對比了新版本上線前后CPU使用率的顯著變化,并指出了CPU飆升的問題。隨后,通過監控發布過程,發現CPU和QPS(每秒查詢率)的上升,這提示了可能存在性能瓶頸或異常請求。
- 接下來,會議通過下鉆分析,鎖定了Top URI(統一資源標識符),并確認了請求突增的情況。通過進一步分析海量日志,會議團隊快速定位了問題的根因,即客戶端與服務端版本不一致導致的客戶端頻繁重試。
- 為了消除這一隱患并優化性能,會議提出了多項措施。首先,通過調用日志和Wasm插件增加業務屬性,確認了SDK版本,從而解決了版本不一致的問題。此外,還討論了其他調優技術,如調整參數和優化代碼,以進一步提升系統性能。
通過收集數據、分析數據、確定問題原因,并最終解決問題。

服務超時問題的深入分析和解決策略,特別是針對新功能上線后日志中頻繁出現的第三方服務API調用超時問題
如何精準界定這類超時問題是由網絡因素還是第三方服務本身所導致。
- 會議回顧了錯誤日志的詳細情況,其中包含了
ResourceAccessException異常,這明確指出了在嘗試通過GET請求獲取數據時發生了I/O錯誤,具體表現為讀取超時。通過RestTemplate的調用棧,我們能夠追蹤到問題發生在RestTemplate.doExecute方法中,這進一步指向了網絡層面的潛在問題。- 會議對現有的網絡指標進行了深入分析。通過監控TCP連接狀態、流量、丟包率等關鍵指標,發現存在網絡抖動和重傳比例高等異常情況。這些指標為提供了網絡層面可能存在問題的線索。
- 為了更精確地定位問題根源,會議引入了DeepFlow工具來分析網絡流量和抖動情況。通過這一工具,確定了服務端重置是導致調用超時的主要原因,這進一步指向了第三方服務異常的可能性。
- 基于以上分析,提出了針對性的解決方案。如果問題源于網絡抖動,將優化網絡連接以確保穩定性;如果問題確實由第三方服務引起,將與第三方服務提供方緊密溝通,共同尋求解決方案。
會議不僅深入探討了服務超時問題的排查方法,還通過日志分析、網絡監控和異常處理等手段,精準界定了問題的根本原因,并制定了相應的解決策略。這為我們未來處理類似問題提供了寶貴的經驗和參考。
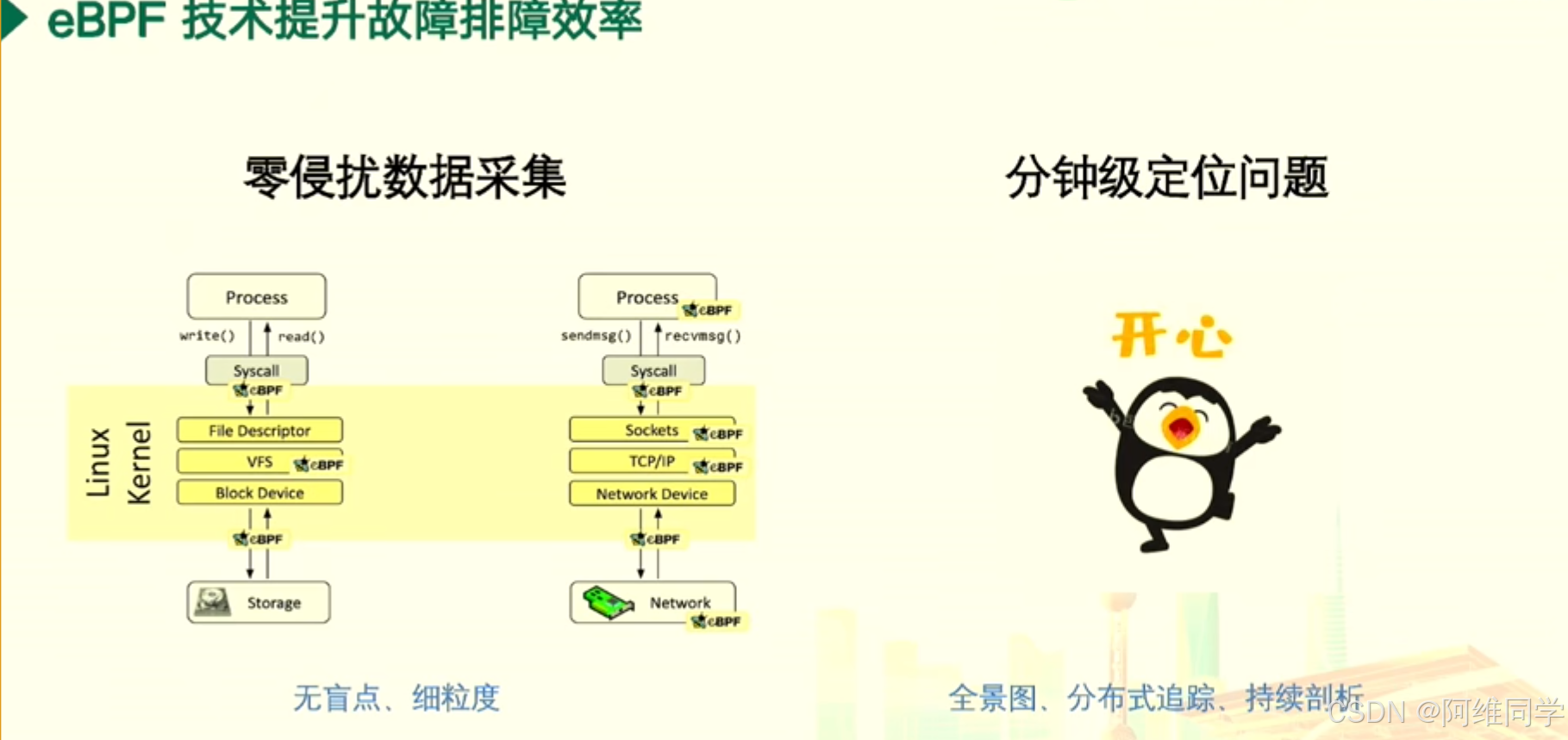
探討了eBPF(Extended Berkeley Packet Filter)技術在提升故障排障效率方面的應用。
- 強調了eBPF技術能夠實現零侵擾數據采集,這意味著在不影響系統正常運行的情況下,該技術能夠捕獲從內核到用戶空間的關鍵數據流動,包括Process、write()、read()、sendmsg()、recvmsg()等系統調用,以及socket、TCP/IP、Block Device、Network Device等網絡和設備相關組件的交互信息。
- eBPF技術如何幫助實現分鐘級的問題定位。通過將eBPF程序加載到Linux內核,系統管理員可以實時收集和分析系統數據,從而迅速發現故障點,極大地提高了故障排查的效率。
- 此外,提到了eBPF技術的其他優勢,如“無盲點、細粒度”的數據收集能力,以及“全景圖、分布式追蹤、持續剖析”的監控策略。這些特點使得eBPF技術能夠提供一個全面、細致且持續的系統監控和故障排查方案。








)






![Detailed Steps for Troubleshooting ORA-00600 [kdsgrp1] (文檔 ID 1492150.1)](http://pic.xiahunao.cn/Detailed Steps for Troubleshooting ORA-00600 [kdsgrp1] (文檔 ID 1492150.1))



)