目錄
寫在前面
一、使用ChatTTS
二、優點
三、局限
寫在前面
????????最像人聲的AI來了!語音開源天花板ChatTTS火速出圈,3天就斬獲9k個star。截至發稿前,已經25.9k個star了。這是專門為對話場景設計的語音生成模型,用于LLM助手對話任務、對話語音、視頻介紹等,僅支持中英文。硬件要求低,甚至不需要GPU,一臺普通PC就能運行。
????????主模型使用了 100,000+ 小時的中文和英文音頻數據進行訓練。開源的版本是4 萬小時基礎模型。
? ? ? ? 項目地址:https://github.com/jianchang512/ChatTTS-ui,這是原項目ChatTTS的地址,不用下,我們要使用的是ChatTTS-ui,是給ChatTTS增加了UI,并打好了包,開包即用。
一、使用ChatTTS
? ? ? ? 廢話不多少,先玩起來。
????????1.下載ChatTTS-ui:https://github.com/jianchang512/chatTTS-ui/releases
????????2.解壓縮并運行app.exe
????????3.等一會會自動打開默認瀏覽器,就可以開始生成音頻啦!!
???????? ? ? ? ?????????
? ? ? ?????????
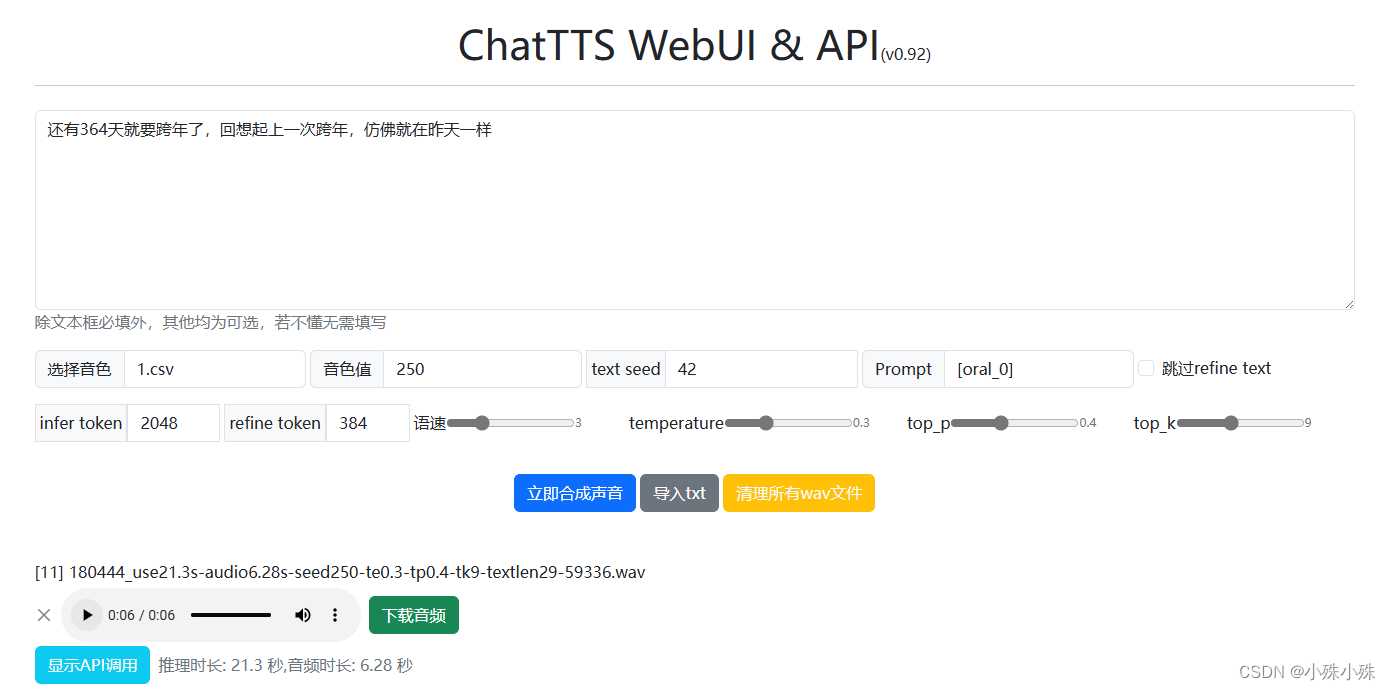
????????使用也很簡單,輸入文字點擊立即合成,等待一會下方就會出現結果,下面介紹一下參數:
? ? ? ? (1)文本:如果哪里斷句不好,可以加一個[break_1];如果想調整口語程度可以加[oral_0],數字越大,越口語化;如果想加笑聲可以加[laugh_1],但經我測試,加了laugh廢話變多了。
????????(2)選擇音色:一共10000個音色,每個音色有一個csv的特征文件,這里下載全部10000個音色。
? ? ? ? (3)音色值:如果懶得下載10000個音色文件,也可以在這里輸入1-10000的數字,值得注意的是,一旦這里輸入,前面的csv就沒用了。音色試聽在這里。
? ? ? ? (4)text seed:擴散模型嘛,肯定要有一個控制噪聲的隨機種子。
? ? ? ? (5)Prompt:現在支持三個值,是全局的,oral控制口語程度數字越大,越口語化,例如[oral_0]就接近朗讀的口氣;langh會使說話過程中插入笑聲,經我測試數越大,與文本無關的廢話越多;break控制斷句,數越大,斷句越干脆。
? ? ? ? (6)跳過refine text:如果正文中加入了[uv_break]二效果不好,可以勾上試試。
? ? ? ? (7)infer token:推理最大token數,默認就行。
? ? ? ? (8)refine token:預處理的時候,會對文本進行優化,使之更適合口語,這個是調整的token數量,也不用動。
? ? ? ? (9)語速:數越大,語速越快,但是變化并不是太明顯。
? ? ? ? ? (10)temperature:數越大語氣、音色、聲調等隨機性越大。
? ? ? ? (11)top_p:控制生成多樣性的參數,數越小,多樣性越強。比如0.3,那下一個預測token的概率只要大于0.3就有可能被選中,當然也要配合下面的top_k使用。
? ? ? ? (12)top_k:同樣控制生成多樣性的參數,數越大,多樣性越強。比如9,那下一個預測token的會選前9個概率最大的,當然也要配合上面的top_p使用。
二、優點
????????1.ChatTTS針對基于對話的任務進行了優化,實現了自然而富有表現力的語音合成,很接近人聲。
????????2.模型可以加入韻律特征,包括笑聲、停頓和嘆詞。
????????3.硬件要求低,雖然是擴散模型,但是在CPU上也能流暢使用
三、局限
????????1.音色文件的提取方式作者沒有開源,所以現在不能定制自己的聲音。
????????2.使用擴散模型,仍然需要抽卡,尤其對于長文本,不好控制,商用會有問題。
????????ChatTTS的使用就簡單介紹到這里,關注不迷路(*^▽^*)
關注訂閱號了解更多精品文章

交流探討、商務合作請加微信


)




)



 unplugin-vue-router 實用教程)



)




