目錄
一.關系型數據庫與非關系型數據庫
1.關系型數據庫
2.非關系型數據庫
3.二者區別
4.非關系型數據庫產生背景
5.NoSQL與SQL數據記錄對比
關系型數據庫
非關系型數據庫
二.Redis相關概述
1.簡介
2.五大數據類型
3.優缺點
3.1.優點
3.2.缺點
4.使用場景
5.采用單線程的原因
6.哪些數據適合放入緩存中
7.運行速度快的原因
8.與memcached比較
三.Redis的安裝配置
1.源碼編譯安裝
2.redis服務管理
五.Redis的命令工具
1.redis-cli 命令行工具
2.redis-benchmark 測試工具
2.1.并發連接
2.2.數據包的存取的性能測試
2.3.鍵值對的創建速度測試
六.Redis 數據庫常用命令
1.redis鍵值對的存取?
2.redis鍵值列表的獲取
2.1.獲取全部列表
2.2.獲取以某字符為開頭任意長度的鍵
2.3.獲取以某字符為開頭,后面為指定長度的鍵
3.判斷鍵是否存在?
4.刪除鍵
5.查看鍵存儲的數據類型
6.rename?重命名
7.renamenx 重命名
8.dbsize查看鍵數目?
9.設置和清空密碼
設置和查看密碼
清空密碼
七.Redis 多數據庫操作
1.多數據庫間切換select
2.多數據庫間移動數據
3.清除數據庫內數據(慎用)
八.Redis 常見錯誤與解決方案
1.常見運維故障
2.故障排查
一.關系型數據庫與非關系型數據庫
1.關系型數據庫

2.非關系型數據庫

3.二者區別
| SQL | NoSQL | |
| 存儲結構 | 二維表格結構 | 不是二維表格結構,不同的NoSQL采用不同的存儲方式(比如鍵對值、文檔、索引、圖形結構、時間序列等) |
| 擴展方式 | 縱向擴展(提升單機的硬件性能) | 橫向擴展(增加服務器節點數量) |
| 事務典型 | 基于ACID原則,對事務控制更穩定,細粒度更高 | 基于BASE原則,對事務控制的穩定性和細粒度不如SQL |
| 典型代表 |

4.非關系型數據庫產生背景
可用于應對Web2.0純動態網站類型的三高問題
- High performance —— 對數據庫高并發讀寫需求
- Hugestorage——對海量數據高效存儲與訪問需求
- HighScalability&&HighAvailability——對數據庫高可擴展性與高可用性需求
關系型數據庫和非關系型數據庫都有各自的特點與應用場景,兩者的緊密結合將會給Web2.0的數
據庫發展帶來新的思路。讓關系型數據庫關注在關系上和對數據的一致性保障,非關系型數據庫關
注在存儲和高效率上。例如,在讀寫分離的MySQL數據庫環境中,可以把經常訪問的數據存儲在
非關系型數據庫中,提升訪問速度
5.NoSQL與SQL數據記錄對比
關系型數據庫
- 實例-->數據庫-->表(table)-->記錄行(row)、數據字段(column)
非關系型數據庫
- 實例-->數據庫-->集合(collection)-->鍵值對(key-value)
- 非關系型數據庫不需要手動建數據庫和集合(表)
二.Redis相關概述
1.簡介


2.五大數據類型
基礎數據類型包括:string(字符串)、list(列表,雙向鏈表)、hash(散列,鍵值對集合)、set(集合,不重復)和sorted set也可以稱為Zset(有序集合)
| 結構類型 | 結構存儲的值 | 結構的讀寫能力 |
| String | 可以是字符串、整數、浮點數 | 對整個字符串或者字符串的其中一部分進行操作,對整數和浮點數執行自增或者自減操作 |
| list | 一個鏈表,鏈表上每個節點都包含了一個字符串 | 從鏈表的兩端推入或者彈出元素:根據偏移量對鏈表進行修剪:讀取單個或多個元素,根據值查找或者移除元素 |
| set | 包含字符串的無序收集器,并且被包含的每個字符串都是獨一無二各不相同的 | 添加、獲取、移除單個元素,檢查一個元素是否存在與集合中,計算交集、并集、差集,從集合里面隨機獲取元素 |
| hash | 包含鍵值對的無序散列表 | 添加、獲取、移除單個鍵值對,獲取所有鍵值對 |
| zset | 字符串成員與浮點數分值之間的有序映射,元素的排列順序由分值的大小決定 | 添加、獲取、刪除單個元素,根據分值范圍或者成員來獲取元素 |
3.優缺點
3.1.優點

3.2.缺點
- 緩存和數據庫雙寫一致性問題
- 緩存雪崩問題
- 緩存擊穿問題
- 緩存的并發競爭問題
4.使用場景
- Redis作為基于內存運行的數據庫,是一個高性能的緩存,一般應用在Session緩存、隊列、排行榜、計數器、最近最熱文章、最近最熱評論、發布訂閱等
- Redis 適用于數據實時性要求高、數據存儲有過期和淘汰特征的、不需要持久化或者只需要保證弱一致性、邏輯簡單的場景
- 通常會將部分數據放入緩存中,來提高訪問速度,然后數據庫承擔存儲的工作
5.采用單線程的原因
首先要明確的是Redis單線程指的是網絡IO和鍵值對讀寫是由一個線程來完成的,但Redis持久
化、集群數據等是由額外的線程執行的。了解Redis使用單線程之前可以先了解一下多線程的開
銷
通常情況下,使用多線程可以增加系統吞吐率或者可以增加系統擴展性,但多線程通常會存在同時
訪問某些共享資源,為了保證訪問共享資源的正確性,就需要有額外的機制進行保證,這個機制首
先會帶來一定的開銷。其實對于多線程并發訪問的控制一直是一個難點問題,如果沒有精細的設
計,比如說,只是簡單地采用一個粗粒度互斥鎖,就會出現不理想的結果。即使增加了線程,大部
分線程也在等待獲取訪問共享資源的互斥鎖,并行變串行,系統吞吐率并沒有隨著線程的增加而增
加
此外
值得注意的是在Redis6.0中引入了多線程。在Redis6.0之前,從網絡IO處理到實際的讀寫命令處理
都是由單個線程完成的,但隨著網絡硬件的性能提升,Redis的性能瓶頸有可能會出現在網絡IO的
處理上,也就是說單個主線程處理網絡請求的速度跟不上底層網絡硬件的速度。針對此問題,
Redis采用多個IO線程來處理網絡請求,提高網絡請求處理的并行度,但多IO線程只用于處理網絡
請求,對于讀寫命令,Redis仍然使用單線程處理!
6.哪些數據適合放入緩存中
- 即時性? ?例如查詢最新的物流狀態信息。
- 數據一致性要求不高? ?例如門店信息,修改后,數據庫中已經改了,五分鐘后緩存中才是最新的,但不影響功能使用。
- 訪問量大且更新頻率不高? ?例如網站首頁的廣告信息,訪問量大,但是不會經常變化。
?
7.運行速度快的原因
- Redis是基于內存運行,數據的讀寫都是在內存中完成的
- 數據結構簡單,可以直接使用 鍵值對 的方式存儲數據
- 數據讀寫采用單線程模型,避免了多線程切換帶來的CPU性能損耗,同時也不用考慮各種鎖的影響
- 采用IO多路復用模型,非阻塞IO可以使網絡線程處理更多的網絡連接請求,提高了網絡并發能力
8.與memcached比較

三.Redis的安裝配置
1.源碼編譯安裝
---------------------- Redis 安裝部署 ----------------------------------------
//環境準備
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config#修改內核參數
vim /etc/sysctl.conf
vm.overcommit_memory = 1
net.core.somaxconn = 2048sysctl -p//安裝redis
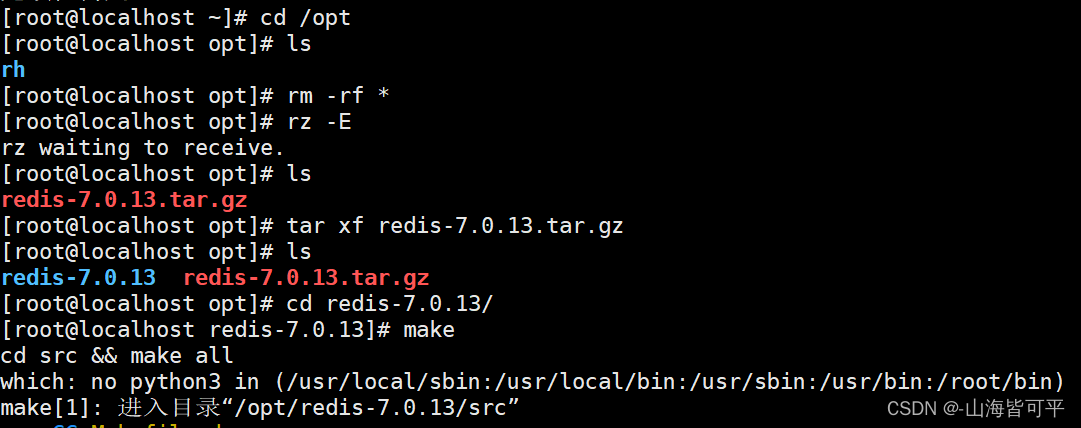
yum install -y gcc gcc-c++ makecd /opt/tar xf redis-7.0.13.tar.gz
cd /redis-7.0.13
make
make PREFIX=/usr/local/redis install
#由于Redis源碼包中直接提供了 Makefile 文件,所以在解壓完軟件包后,不用先執行 ./configure 進行配置,可直接執行 make 與 make install 命令進行安裝。#創建redis工作目錄
mkdir /usr/local/redis/{conf,log,data}cp /opt/redis-7.0.13/redis.conf /usr/local/redis/conf/useradd -M -s /sbin/nologin redis
chown -R redis.redis /usr/local/redis/#環境變量
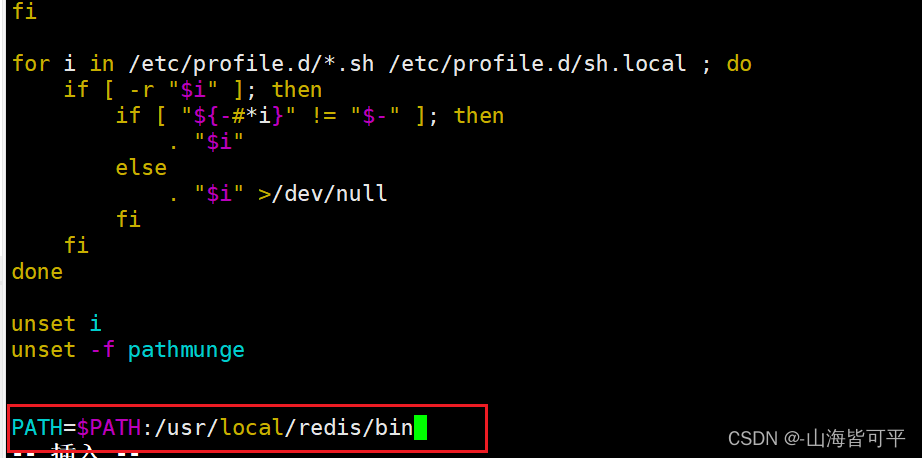
vim /etc/profile
PATH=$PATH:/usr/local/redis/bin #增加一行source /etc/profile//修改配置文件
vim /usr/local/redis/conf/redis.conf
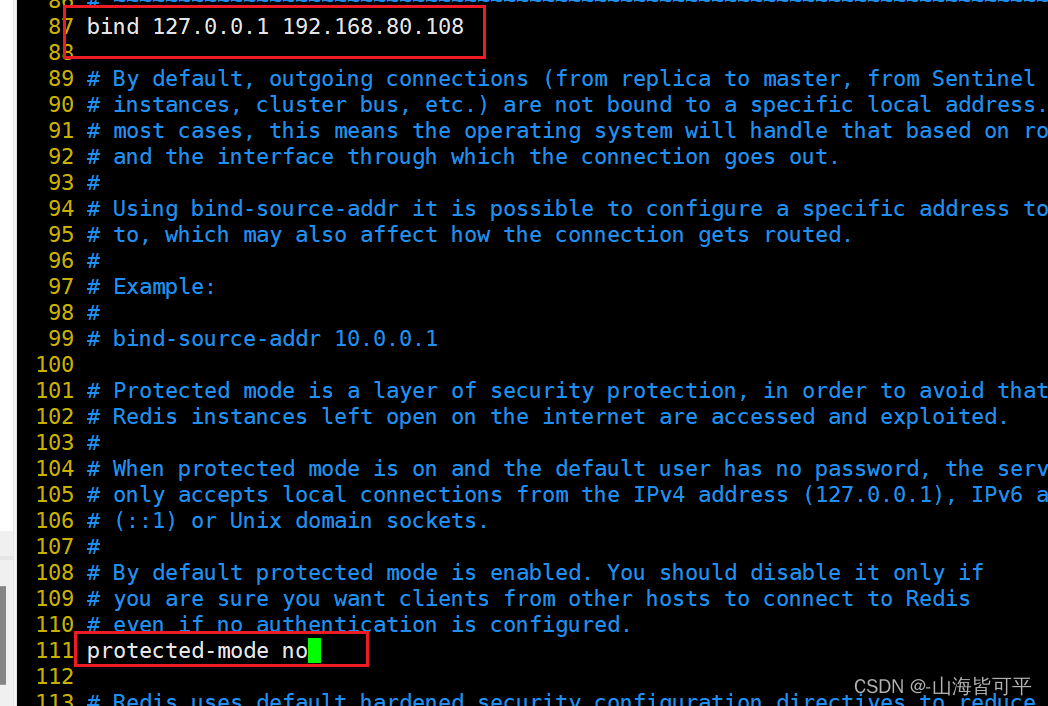
bind 127.0.0.1 192.168.80.108 #87行,添加 監聽的主機地址
protected-mode no #111行,將本機訪問保護模式設置no。如果開啟了,那么在沒有設定bind ip且沒有設密碼的情況下,Redis只允許接受本機的響應
port 6379 #138行,Redis默認的監聽6379端口
daemonize yes #309行,設置為守護進程,后臺啟動
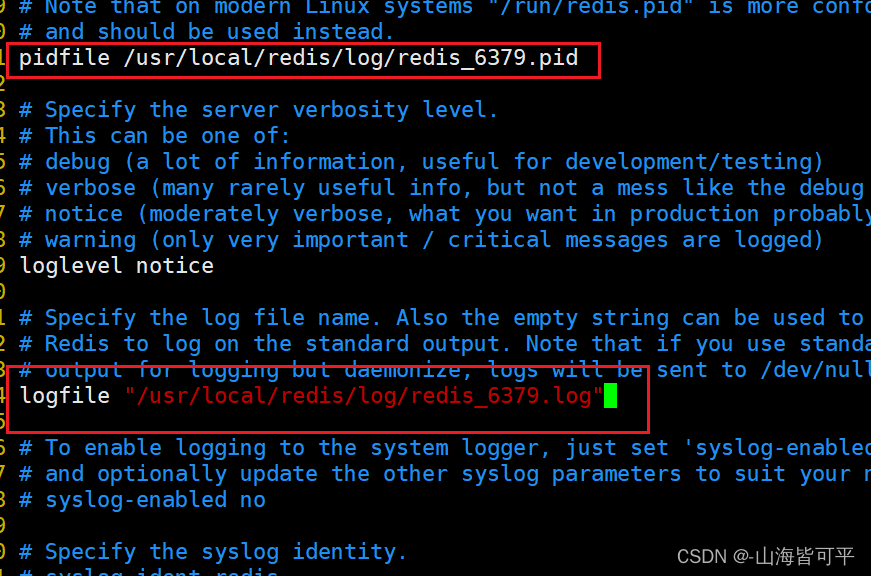
pidfile /usr/local/redis/log/redis_6379.pid #341行,指定 PID 文件
logfile "/usr/local/redis/log/redis_6379.log" #354行,指定日志文件
dir /usr/local/redis/data #504行,指定持久化文件所在目錄
requirepass abc123 #1037行,增加一行,設置redis密碼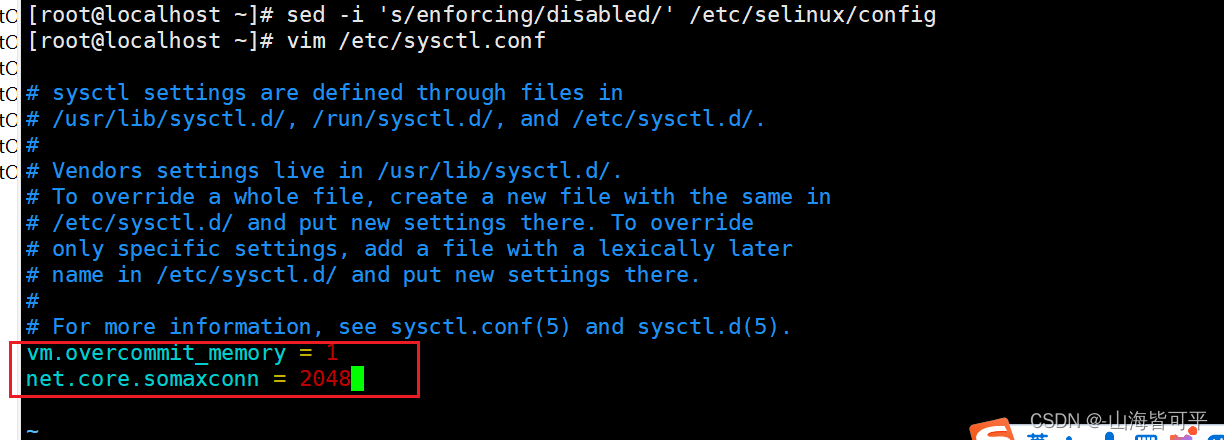





2.redis服務管理
//定義systemd服務管理腳本
vim /usr/lib/systemd/system/redis-server.service
[Unit]
Description=Redis Server
After=network.target[Service]
User=redis
Group=redis
Type=forking
TimeoutSec=0
PIDFile=/usr/local/redis/log/redis_6379.pid
ExecStart=/usr/local/redis/bin/redis-server /usr/local/redis/conf/redis.conf
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true[Install]
WantedBy=multi-user.target#啟動服務
systemctl start redis-server
systemctl enable redis-servernetstat -lntp | grep 6379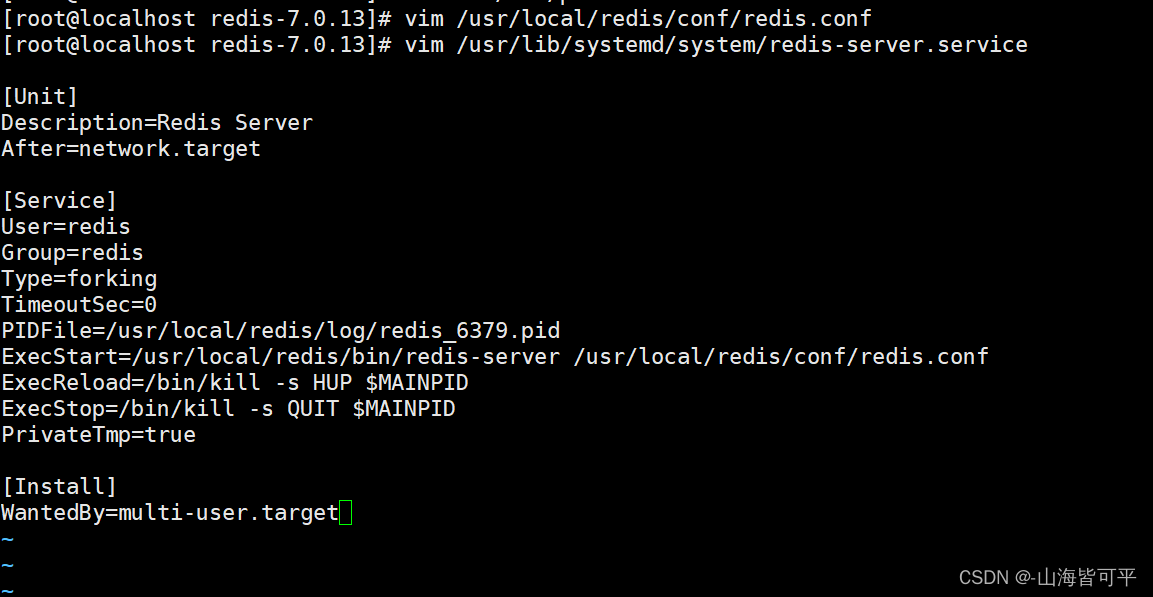

五.Redis的命令工具

| redis-server | 用于啟動redis的工具 |
| redis-benchmark | 用于檢測redis在本機的運行效率 |
| redis-check-aof | 修復AOF持久化文件 |
| redis-check-rdb | 修復RDB持久化文件 |
| redis-cli | redis命令行工具 |
| redis-sentinel | Redis 哨兵集群使用 |
1.redis-cli 命令行工具
語法:redis-cli -h host -p port [-a password]
-h :指定遠程主機
-p :指定 Redis 服務的端口號
-a :指定密碼,未設置數據庫密碼可以省略-a 選項
若不添加任何選項表示,則使用 127.0.0.1:6379 連接本機上的 Redis 數據庫redis-cli -h 192.168.80.108 -p 6379 -a 'abc123'

2.redis-benchmark 測試工具
redis-benchmark 是官方自帶的 Redis 性能測試工具,可以有效的測試 Redis 服務的性能
基本的測試語法:redis-benchmark [選項] [選項值]
-h :指定服務器主機名
-p :指定服務器端口
-s :指定服務器 socket
-c :指定并發連接數
-n :指定請求數
-d :以字節的形式指定 SET/GET 值的數據大小
-k :1=keep alive 0=reconnect
-r :SET/GET/INCR 使用隨機 key, SADD 使用隨機值
-P :通過管道傳輸<numreq>請求
-q :強制退出 redis。僅顯示 query/sec 值
--csv :以 CSV 格式輸出
-l :生成循環,永久執行測試
-t :僅運行以逗號分隔的測試命令列表
-I :Idle 模式。僅打開 N 個 idle 連接并等待
2.1.并發連接
redis-benchmark -h 192.168.80.108 -p 6379 -a 'abc123' -c 100 -n 100000
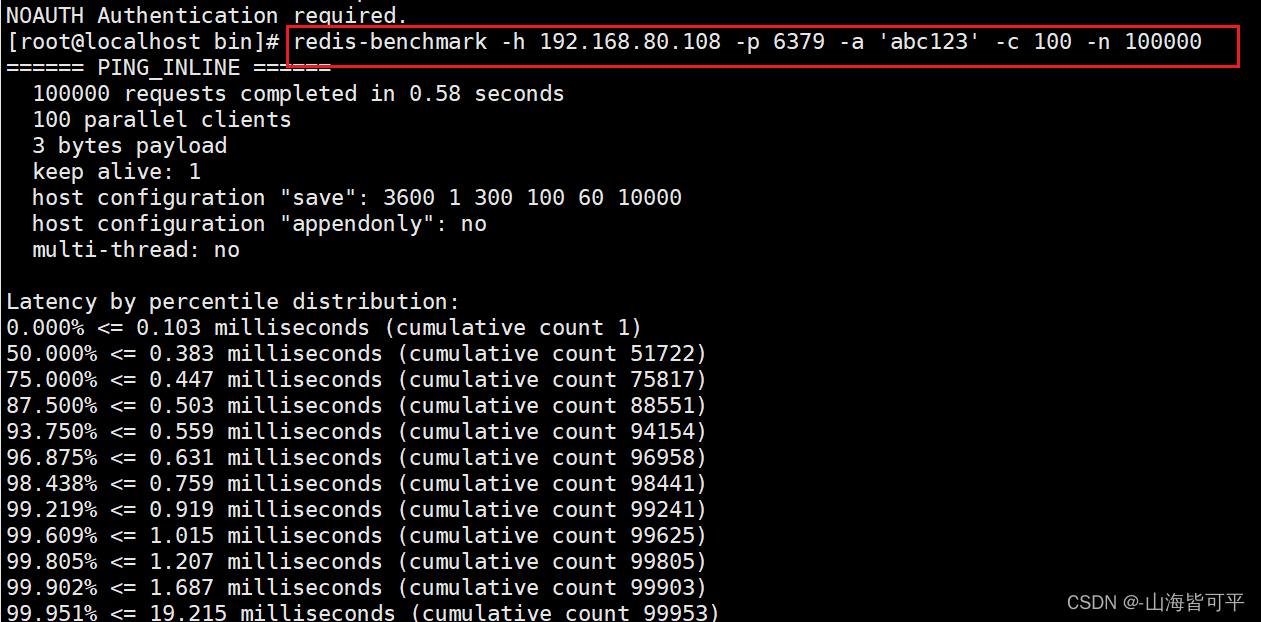
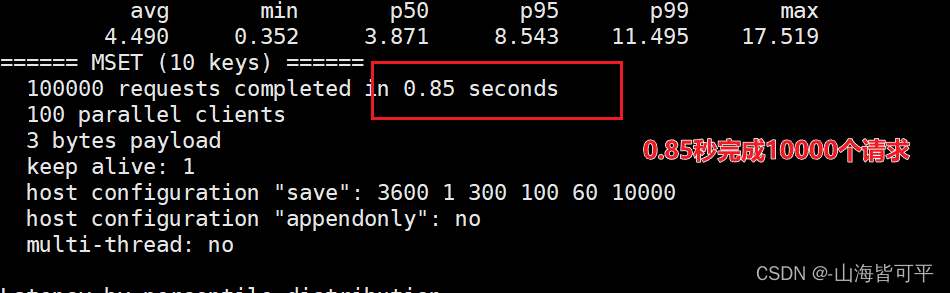
2.2.數據包的存取的性能測試
redis-benchmark -h 192.168.80.108 -p 6379 -a 'abc123' -q -d 100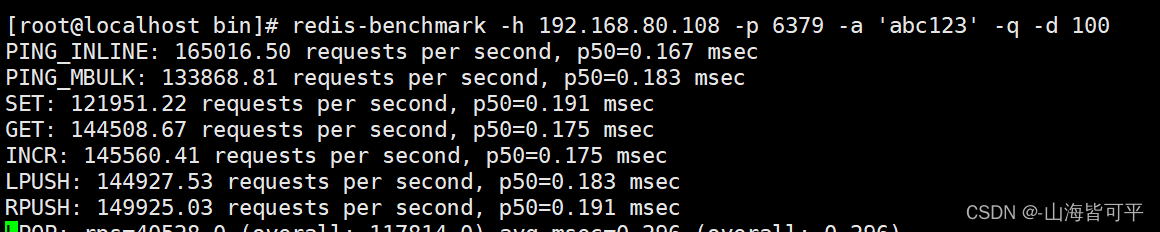
2.3.鍵值對的創建速度測試
redis-benchmark -t set,lpush -a 'abc123' -n 100000 -q

六.Redis 數據庫常用命令
| set | 存放數據 |
| get | 獲取數據 |
| keys * | 查看所有的key |
| keys k? | 查看k開頭后面任意一位的數據 |
| exists | 判斷鍵是否存在(存在1,不存在0) |
| del | 刪除鍵 |
| type | 查看鍵對應的value值類型 |
| rename key1 key2 | 改名,不管key2是否存在都會改名成功。如果存在,key1的值會覆蓋key2得值 |
| renamenx key1 key2 | 改名,若key2不存在,可以改名成功。若key2存在則不進行改名 |
| dbsize | 查看當前數據庫中key的數目 |
1.redis鍵值對的存取?
set:存放數據,命令格式為 set key valueget:獲取數據,命令格式為 get key
2.redis鍵值列表的獲取
設置鍵值
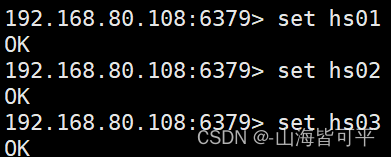
2.1.獲取全部列表
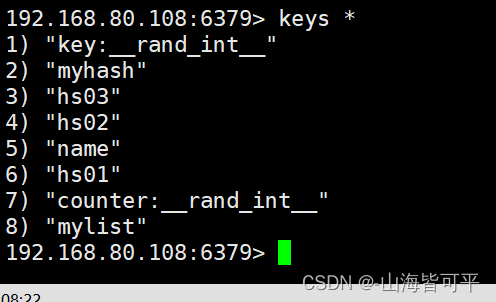
2.2.獲取以某字符為開頭任意長度的鍵
keys h*

2.3.獲取以某字符為開頭,后面為指定長度的鍵
添加測試數據
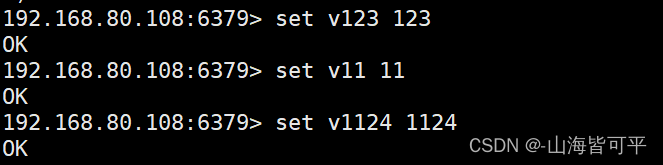
keys v??
keys v???
keys v????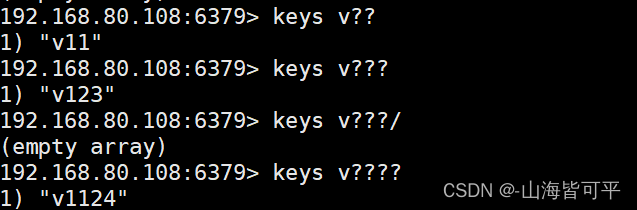
3.判斷鍵是否存在?
exists 鍵 #返回結果 為0 則為不存在,返回為1即為存在
4.刪除鍵
del 鍵
5.查看鍵存儲的數據類型
type 鍵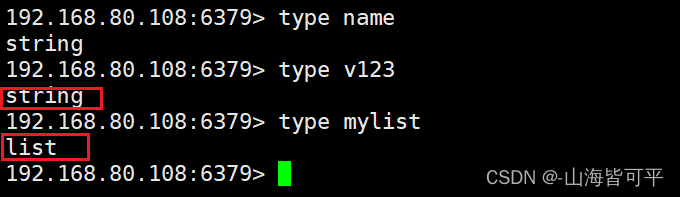
6.rename?重命名
- 使用rename命令進行重命名時,無論目標key是否存在都會進行重命名,且源key的值會覆蓋目標key的值
- 在實際使用過程中,建議先用exists命令查看目標key 是否存在,然后再決定是否執行rename 命令,以避免覆蓋重要數據
命令格式: rename 源key 目標key7.renamenx 重命名
- 是對已有 key 進行重命名,并檢測新名是否存在,如果目標 key 存在則不進行重命名。(不覆蓋)
命令格式:renamenx 源key 目標key8.dbsize查看鍵數目?
dbsize
9.設置和清空密碼
設置和查看密碼
#設置redis的登錄密碼
config set requirepass 123123
#查看redis的密碼
config get requirepass 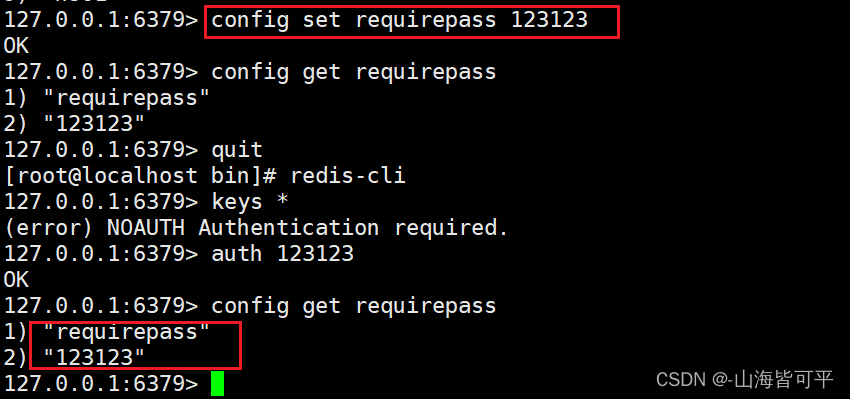
清空密碼
#清空密碼config set requirepass '' 
七.Redis 多數據庫操作
- Redis 支持多數據庫,Redis默認情況下包含16個數據庫,數據庫名稱是用數字0-15來依次命名的
- 使用redis-cli連接Redis數據庫后,默認使用的是序號為0的數據庫
- 多數據庫相互獨立,互不干擾
1.多數據庫間切換select
命令格式:select 序號?#使用redis-cli連接Redis數據庫后,默認使用的是序號為0的數據庫。127.0.0.1:6379>select 10 #切換至序號為10的數據庫?127.0.0.1:6379[10]>select 15 #切換至序號為15的數據庫?127.0.0.1:6379[15]>select 0 #切換至序號為0的數據庫?127.0.0.1:6379[0]>
2.多數據庫間移動數據
move 鍵值 序號(庫的序號)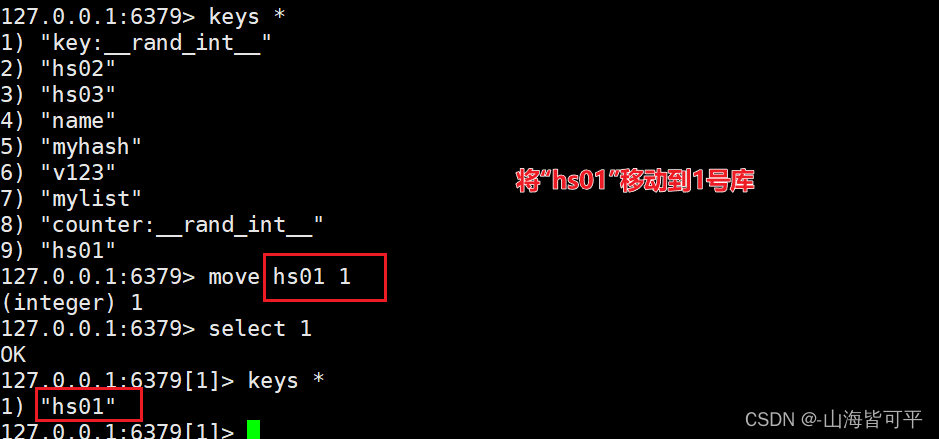
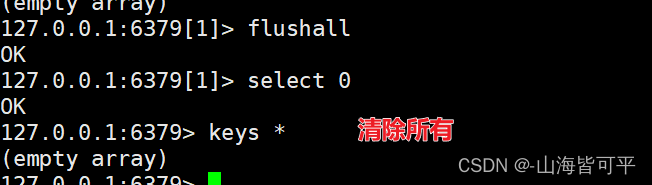
3.清除數據庫內數據(慎用)
FLUSHDB:清空當前數據庫數據FLUSHALL:清空所有數據庫的數據,
八.Redis 常見錯誤與解決方案
1.常見運維故障
- 使用 keys* 把庫堵死。——建議使用別名把這個命令改名
- 超過內存使用后,部分數據被刪除。——這個有刪除策略的,選擇適合自己的即可
- 沒開持久化,卻重啟了實例,數據全掉。——記得非緩存的信息需要打開持久化
- RDB的持久化需要 Vm.overcommit_memory=1 ,否則會持久化失敗
- 沒有持久化情況下,主從,主重啟太快,從還沒認為主掛的情況下,從會清空自己的數據,人為重啟主節點前,先關閉從節點的同步
2.故障排查
- 結合Redis 監控查看QPS、緩存命中率、內存使用率等信息
- 確認機器層面的資源是否有異常
- 故障時及時上機,使用 redis-cli monitor 打印出操作日志,然后分析(事后分析此條失效)
- 和研發溝通,確認是否有大Key在堵塞(大Key也可以在日常的巡檢中獲得) 和組內同事溝通,確實是否有誤操作
- 和運維同事、研發一起排查流量是否正常,是否存在被刷的情況

)














![[Python]根據文件路徑獲取文件所在目錄、文件名和后綴名](http://pic.xiahunao.cn/[Python]根據文件路徑獲取文件所在目錄、文件名和后綴名)


