前言:
有點項目經驗的朋友都知道緩存的重要性是不言而喻的,不僅僅我們在開發項目業務功能的時候使用了各種緩存,框架在設計的時候也有框架層面的緩存,尤其在查詢多的場景下,緩存可以大大的減少數據庫訪問,提升系統效率,Mybatis 也提供了緩存,分別為一級緩存和二級緩存,默認的情況下,Mybatis 只開啟一級緩存。
Mybatis 相關知識傳送門
初識 MyBatis 【MyBatis 核心概念】
MyBatis 源碼分析–SqlSessionFactory
MyBatis 源碼分析–獲取SqlSession
MyBatis 源碼分析-- getMapper(獲取Mapper)
MyBatis 源碼分析-- SQL請求執行流程( Mapper 接口方法的執行的過程)
MyBatis 源碼分析-- 插件(攔截器)原理
MyBatis 插件(攔截器)實戰(自定義實現攔截器)
一級緩存
什么是一級緩存?
一級緩存是 SqlSession 級別的緩存,在操作數據庫時需要構造 SqlSession 對象,在對象中有一個 Map(HashMap)用于存儲緩存數據,不同的 SqlSession 之間的緩存是互相不影響的,即同一個 SqlSession 對象, 在參數和 SQL 完全一樣的情況下,多次查詢只執行一次 SQL 語句,因為第一次查詢后,MyBatis 會將其放在緩存中,后面再次查詢的時候,如果沒有聲明需要刷新,且緩存沒有超時的情況下,SqlSession 會取出當前緩存的數據,不會再次發送 SQL 到數據庫進行查詢,這就是一級緩存。
一級緩存編碼驗證:
代碼示例:
@Transactional(rollbackFor = Exception.class)
@Override
public void queryById(Long id) {selectById(id);log.info("第一次查詢");selectById(id);log.info("第二次查詢");
}
演示結果:
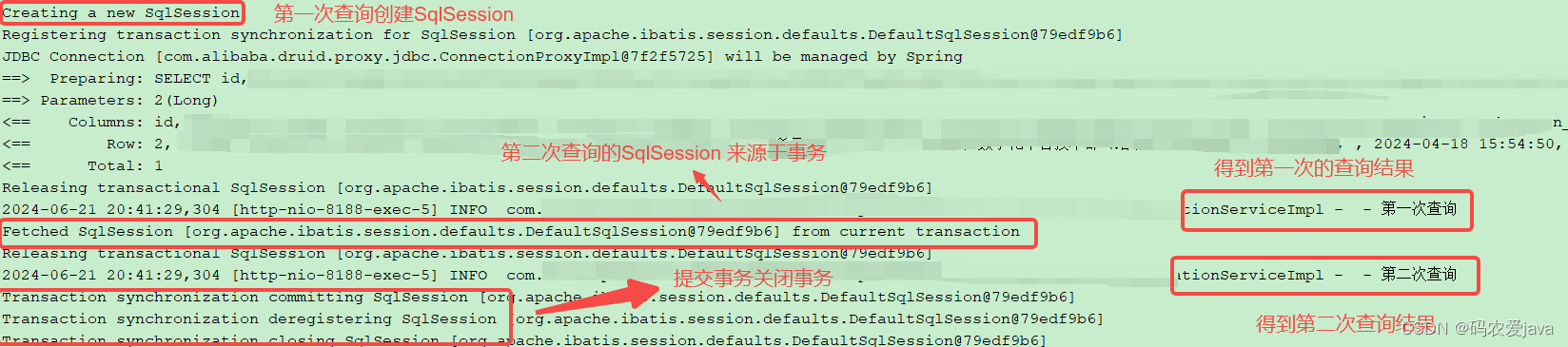
通過輸出日志可以知道,兩次查詢只執行了一次查詢數據庫的操作,表名一級緩存生效了(Mybatis 默認開啟一級緩存)。
注意:如果想要使用 Mybatis 的一級緩存,需要保證是在同一個事務中,只有在同一個事務中,才能獲取到同一個 SqlSession。
一級緩存失效的場景:
- 使用不同的 SqlSession。
- 兩次查詢的查詢條件不一致。
- 兩次查詢之間有增刪改操作。
- 兩次查詢之間手動清除了一級緩存。
一級緩存源碼分析
一級緩存的原理其實在前文分支 SQL 的執行過程的時候已經分析過了,這里我們在回憶一下,在 BaseExecutor#query 方法中會判斷一級緩存中是否有數據,有就返回,沒有才會去查詢數據庫。
//org.apache.ibatis.executor.BaseExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler, org.apache.ibatis.cache.CacheKey, org.apache.ibatis.mapping.BoundSql)
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {//錯誤上下文ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());//執行器關閉 拋出異常if (this.closed) {throw new ExecutorException("Executor was closed.");} else {//queryStack 查詢堆棧 防止遞歸查詢重復處理緩存 是否刷新緩存 flushCacheRequired 是 true 清除一級緩存if (this.queryStack == 0 && ms.isFlushCacheRequired()) {//清除一級緩存this.clearLocalCache();}List list;try {//查詢堆棧 +1++this.queryStack;//從一級緩存中獲取數據list = resultHandler == null ? (List)this.localCache.getObject(key) : null;if (list != null) {//從一級緩存中獲取數據this.handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);} else {//從數據庫查詢數據list = this.queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);}} finally {//查詢堆棧-1--this.queryStack;}if (this.queryStack == 0) {Iterator i$ = this.deferredLoads.iterator();while(i$.hasNext()) {BaseExecutor.DeferredLoad deferredLoad = (BaseExecutor.DeferredLoad)i$.next();deferredLoad.load();}this.deferredLoads.clear();if (this.configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {this.clearLocalCache();}}return list;}
}
一級緩存的存入時機就是每次查詢數據庫的時候,只要查詢了數據庫,結果都會緩存到一級緩存中,這也就是一級緩存默認打開的原因。
//org.apache.ibatis.executor.BaseExecutor#queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {//一級緩存 存儲一個占位符this.localCache.putObject(key, ExecutionPlaceholder.EXECUTION_PLACEHOLDER);List list;try {//執行數據庫查詢list = this.doQuery(ms, parameter, rowBounds, resultHandler, boundSql);} finally {//清除占位符緩存this.localCache.removeObject(key);}//存入一級緩存this.localCache.putObject(key, list);if (ms.getStatementType() == StatementType.CALLABLE) {this.localOutputParameterCache.putObject(key, parameter);}return list;
}
我們知道 Mybatis 的 INSERT、UPDATE、DELETE 最終執行的都是 update 方法,在 update 方法中我們看到了清除一級緩存的代碼,這就是為什么兩次查詢之間有 INSERT、UPDATE、DELETE 操作時候,就無法使用一級緩存的原因。
//org.apache.ibatis.executor.BaseExecutor#update
public int update(MappedStatement ms, Object parameter) throws SQLException {ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());if (this.closed) {throw new ExecutorException("Executor was closed.");} else {//清除一級緩存this.clearLocalCache();return this.doUpdate(ms, parameter);}
}
一級緩存源碼結構
一級緩存的源碼結構很簡單,就是一個簡單的 Map 結構,提供了一些常用的 put、get、remove、clear 方法,本質就是內存中的一個 Map。
public class PerpetualCache implements Cache {private final String id;private final Map<Object, Object> cache = new HashMap();public PerpetualCache(String id) {this.id = id;}public String getId() {return this.id;}public int getSize() {return this.cache.size();}public void putObject(Object key, Object value) {this.cache.put(key, value);}public Object getObject(Object key) {return this.cache.get(key);}public Object removeObject(Object key) {return this.cache.remove(key);}public void clear() {this.cache.clear();}public boolean equals(Object o) {if (this.getId() == null) {throw new CacheException("Cache instances require an ID.");} else if (this == o) {return true;} else if (!(o instanceof Cache)) {return false;} else {Cache otherCache = (Cache)o;return this.getId().equals(otherCache.getId());}}public int hashCode() {if (this.getId() == null) {throw new CacheException("Cache instances require an ID.");} else {return this.getId().hashCode();}}
}
緩存 key 的生成方法 createCacheKey 源碼分析
從源碼中我們可以知道 cacheKey 是根據 MappedStatement id + RowBounds offset + RowBounds limit + SQL + Parameter值 + Environment id 來確定唯一性的。
//org.apache.ibatis.executor.BaseExecutor#createCacheKey
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {//判斷執行器是否關閉if (this.closed) {throw new ExecutorException("Executor was closed.");} else {//創建 緩存key 對象CacheKey cacheKey = new CacheKey();//根據接口的全限定類名+方法名更新 cacheKeycacheKey.update(ms.getId());//根據查詢數據的偏移量更新 cacheKeycacheKey.update(rowBounds.getOffset());//根據查詢數據的條數更新 cacheKeycacheKey.update(rowBounds.getLimit());//根據sql 語句更新 cacheKeycacheKey.update(boundSql.getSql());//其實是從查詢 sql 占位符中解析出的參數元數據信息 然后進行遍歷 獲取每個參數名 并從查詢接口傳入的參數中獲取相應的參數值List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();//獲取類型處理器注冊表TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();//循環遍歷入參 for(int i = 0; i < parameterMappings.size(); ++i) {//獲取參數映射ParameterMapping parameterMapping = (ParameterMapping)parameterMappings.get(i);//參數類型判斷判斷if (parameterMapping.getMode() != ParameterMode.OUT) {//獲取參數屬性名稱String propertyName = parameterMapping.getProperty();//參數值Object value;//是否有附加參數if (boundSql.hasAdditionalParameter(propertyName)) {//根據參數名稱獲取參數值value = boundSql.getAdditionalParameter(propertyName);} else if (parameterObject == null) {//參數為空value = null;} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {//參數類型注冊表中有參數類型 value = parameterObject;} else {//MetaObject提供了一些便捷的方法 可以根據 parameterObject 類型 獲取相應 propertyName 值的方法 不需要直接使用反射操作MetaObject metaObject = this.configuration.newMetaObject(parameterObject);//使用 metaObject 獲取參數值value = metaObject.getValue(propertyName);}//根據環境id更新 cacheKeyif (this.configuration.getEnvironment() != null) {cacheKey.update(this.configuration.getEnvironment().getId());}//根據環境 value 更新 cacheKeycacheKey.update(value);}}return cacheKey;}
}
CacheKey#update 方法源碼分析
CacheKey#update 會把生產的唯一 CacheKey 進行 HashCode,并更新到 updateList 中,判斷兩個 CacheKey 對象相等的充分必要條件是兩個對象代表的組合序列中的每個元素必須都相等,為了避免每次比較都要進行一次循環(遍歷組合List),CacheKey 采用 hashCode–>checksum–>count–>updateList 的順序比較,只要有一個不相等,則視為兩個 CacheKey 對象不相等。
//org.apache.ibatis.cache.CacheKey#update
public void update(Object object) {//如果 object 為空 hashcode 就為1 不為 null 就獲取 hashcodeint baseHashCode = object == null ? 1 : ArrayUtil.hashCode(object);//count ++++this.count;//checksum 等于 checksum +object的 hashcodethis.checksum += (long)baseHashCode;//baseHashCode 等于 baseHashCode 乘以 countbaseHashCode *= this.count;//重新計算 hashcodethis.hashcode = this.multiplier * this.hashcode + baseHashCode;//更新到列表中this.updateList.add(object);
}
二級緩存
什么是二級緩存?
二級緩存是存戶在 SqlSessionFactory 中,二級緩存和名稱空間綁定,也就是說通常所說的二級緩存是 Mapper 級別的緩存,即多個 SqlSession 共享同一個 Mapper 命名空間下的緩存,它的作用是緩存 Mapper 執行的結果,避免頻繁地訪問數據庫,提高系統的性能。
配置二級緩存
Mybatis 二級緩存默認是關閉的,二級緩存有全局開關、局部開關和在某個查詢 SQL 上配置使用緩存,可以根據自己的需求靈活配置。
全局開啟二級緩存:
在 mybatis-config.xml 中如下配置。
<settings><setting name="cacheEnabled" value="true"/>
</settings>
局部開啟二級緩存:
在 Mapper.xml 文件中開啟二級緩存。
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
標簽解釋:
- eviction:清除緩存的策略,FIFO 表示先進先出的策略,默認是 LRU 最近最少使用。
- flushInterval:緩存刷新時間間隔,緩存多長時間刷新一次,默認不清空,設置一個毫秒值。
- size:緩存存放多少個元素。
- readOnly:是否只讀,true 只讀,MyBatis 認為所有從緩存中獲取數據的操作都是只讀操作,不會修改數據。
- type:指定自定義緩存的全類名,自己實現Cache 接口即可。
- blocking:緩存中找不到對應的key,是否會一直 blocking,直到有對應的數據進入緩存。
eviction 緩存回收策略
- FIFO :先進先出,按照緩存進入的順序來移除。
- LRU:最近最少使用,移除最長時間不被使用的對象。
- SOFT:軟引用,移除基于垃圾回收器狀態和軟引用規則的對象。
- WEAK:弱引用,更積極的移除基于垃圾收集器和弱引用規則的對象。
在某個查詢 SQL 上配置使用緩存,如下:
<select id="selectUser" resultType="com.my.study.User" useCache="true" flushCache="true">select * from user where id = #{id}
</select>
二級緩存的創建
二級緩存的創建,其實就是解析 標簽,這個解析動作是在構建 SqlSessionFactory 的過程中做的,前文在分析 SqlSessionFactory 的創建過程中有詳細講解,這里只分析 解析 標簽的源碼,如下:
SqlSession 創建傳送門
//org.apache.ibatis.builder.xml.XMLMapperBuilder#configurationElement
private void configurationElement(XNode context) {try {//獲取 namespaceString namespace = context.getStringAttribute("namespace");if (namespace != null && !namespace.isEmpty()) {//設置 namespacethis.builderAssistant.setCurrentNamespace(namespace);//解析 cache-ref 標簽this.cacheRefElement(context.evalNode("cache-ref"));//解析 cache 標簽this.cacheElement(context.evalNode("cache"));//解析映射參數 parameterMap this.parameterMapElement(context.evalNodes("/mapper/parameterMap"));//解析結果集 resultMapthis.resultMapElements(context.evalNodes("/mapper/resultMap"));//解析 sqlthis.sqlElement(context.evalNodes("/mapper/sql"));//構建 crud 語句 this.buildStatementFromContext(context.evalNodes("select|insert|update|delete"));} else {throw new BuilderException("Mapper's namespace cannot be empty");}} catch (Exception var3) {throw new BuilderException("Error parsing Mapper XML. The XML location is '" + this.resource + "'. Cause: " + var3, var3);}
}
XMLMapperBuilder#cacheElement 源碼分析
XMLMapperBuilder#cacheElement 源碼就很簡單了,其實就是對 Cache 標簽的解析,解析 Cache 標簽的各個屬性,然后構建一個 Cache 對象返回。
//org.apache.ibatis.builder.xml.XMLMapperBuilder#cacheElement
private void cacheElement(XNode context) {if (context != null) {//獲取緩存類名 這里如果我們定義了<cache/>中的 type 就使用自定義的Cache類 否則使用和一級緩存相同的PerpetualCacheString type = context.getStringAttribute("type", "PERPETUAL");//從類型別名注冊表中獲取緩存類名的 classClass<? extends Cache> typeClass = this.typeAliasRegistry.resolveAlias(type);//緩存淘汰策略 默認 LRUString eviction = context.getStringAttribute("eviction", "LRU");//從類型別名注冊表中獲取緩存類名的 classClass<? extends Cache> evictionClass = this.typeAliasRegistry.resolveAlias(eviction);//獲取緩存刷新時間間隔Long flushInterval = context.getLongAttribute("flushInterval");//緩存存放的元素個數Integer size = context.getIntAttribute("size");//只讀屬性 默認 falseboolean readWrite = !context.getBooleanAttribute("readOnly", false);//緩存中找不到對應的key 是否會一直 blocking 直到有對應的數據進入緩存 默認 falseboolean blocking = context.getBooleanAttribute("blocking", false);Properties props = context.getChildrenAsProperties();//構建一個新的二級緩存對象this.builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);}}//org.apache.ibatis.builder.MapperBuilderAssistant#useNewCache
public Cache useNewCache(Class<? extends Cache> typeClass, Class<? extends Cache> evictionClass, Long flushInterval, Integer size, boolean readWrite, boolean blocking, Properties props) {//創建 cache 對象Cache cache = (new CacheBuilder(this.currentNamespace)).implementation((Class)this.valueOrDefault(typeClass, PerpetualCache.class)).addDecorator((Class)this.valueOrDefault(evictionClass, LruCache.class)).clearInterval(flushInterval).size(size).readWrite(readWrite).blocking(blocking).properties(props).build();//添加到 configuration 中this.configuration.addCache(cache);//將 cache 賦值給 MapperBuilderAssistant.currentCachethis.currentCache = cache;return cache;
}
二級緩存在查詢過程中的使用源碼分析
二級緩存的使用再 CachingExecutor#query 方法中有體現,如下:
//CachingExecutor#query 方法會從 MappedStatement 中獲取 SQL 信息,創建緩存 key 并執行查詢,Configuration 中 cacheEnabled 屬性值默認為 true,因此會執行 CachingExecutor 的 query方法。
//org.apache.ibatis.executor.CachingExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler)
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {//獲取 SQL 基本信息BoundSql boundSql = ms.getBoundSql(parameterObject);//創建緩存 keyCacheKey key = this.createCacheKey(ms, parameterObject, rowBounds, boundSql);//執行查詢return this.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}//CachingExecutor#query 會判斷是否使用了緩存,如果允許使用緩存會先從二級緩存查詢,二級緩存中查詢不到才會去查詢一級緩存或者數據庫,如果二級緩存為空或者不允許使用緩存就會直接去查詢一級緩存或者數據庫。
//org.apache.ibatis.executor.CachingExecutor#query(org.apache.ibatis.mapping.MappedStatement, java.lang.Object, org.apache.ibatis.session.RowBounds, org.apache.ibatis.session.ResultHandler, org.apache.ibatis.cache.CacheKey, org.apache.ibatis.mapping.BoundSql)
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {//獲取 二級緩存Cache cache = ms.getCache();//為空判斷if (cache != null) {//是否刷新緩存//select 時候 flushCacheRequired 默認是false 不清除二級緩存 //insert update delete 時候 flushCacheRequired 是 true 會清除二級緩存this.flushCacheIfRequired(ms);//如果使用了緩存 ResultHandler 不為空 if (ms.isUseCache() && resultHandler == null) {//對存儲過程的處理 確保沒有存儲過程 如果有存儲過程 就報錯this.ensureNoOutParams(ms, parameterObject, boundSql);//從二級緩存中查詢數據 TransactionalCacheManagerList<E> list = (List)this.tcm.getObject(cache, key);//結果為空 判斷if (list == null) {//為空 BaseExexutor 執行查詢數據庫list = this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);//加入二級緩存this.tcm.putObject(cache, key, list);}return list;}}//緩存為空 BaseExexutor 直接查詢數據庫return this.delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
TransactionalCacheManager 源碼分析
二級緩存 Cache 對象是從 MappedStatement 中獲取的,一個 Mapper 對應一個 MapperStatment,MappedStatement(SQL語句信息) 對象是存在全局配置中,多個 CachingExecutor 多可以獲取到,這樣就可以在多個線程之間共用了,會存在線程安全問題,同樣多個 SqlSession 使用同一個 Cache 也會出現數據臟讀問題,因此使用了事務緩存管理器 TransactionalCacheManager 來管理二級緩存,TransactionalCacheManager 使用一個 Map 維護了 Cache 和 TransactionalCache 的關系,并提供了管理緩存的方法,但真正管理緩存的時候 TransactionalCache。
package org.apache.ibatis.cache;import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.ibatis.cache.decorators.TransactionalCache;public class TransactionalCacheManager {//維護 Cache ransactionalCache 之間的關系private final Map<Cache, TransactionalCache> transactionalCaches = new HashMap();public TransactionalCacheManager() {}//清除緩存public void clear(Cache cache) {this.getTransactionalCache(cache).clear();}//獲取緩存public Object getObject(Cache cache, CacheKey key) {return this.getTransactionalCache(cache).getObject(key);}//存入緩存public void putObject(Cache cache, CacheKey key, Object value) {this.getTransactionalCache(cache).putObject(key, value);}public void commit() {Iterator var1 = this.transactionalCaches.values().iterator();while(var1.hasNext()) {TransactionalCache txCache = (TransactionalCache)var1.next();txCache.commit();}}public void rollback() {Iterator var1 = this.transactionalCaches.values().iterator();while(var1.hasNext()) {TransactionalCache txCache = (TransactionalCache)var1.next();txCache.rollback();}}//獲取 TransactionalCacheprivate TransactionalCache getTransactionalCache(Cache cache) {return (TransactionalCache)this.transactionalCaches.computeIfAbsent(cache, TransactionalCache::new);}
}
TransactionalCache 源碼分析
TransactionalCache 是事務緩存裝飾器,可以為 Cache 增加事務功能,真正操作緩存的方法都在 TransactionalCache 中,TransactionalCache 中真正的二級緩存存在在 delegate 中,讀取緩存從 delegate 中讀取,存入緩存的時候會先存入到 entriesToAddOnCommit 中,只有正真提交事務的時候,才會把緩存加入到 delegate 真正的二級緩存中。
package org.apache.ibatis.cache.decorators;import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.Map.Entry;
import org.apache.ibatis.cache.Cache;
import org.apache.ibatis.logging.Log;
import org.apache.ibatis.logging.LogFactory;public class TransactionalCache implements Cache {private static final Log log = LogFactory.getLog(TransactionalCache.class);//二級緩存對象private final Cache delegate;//在commit的時候是否清除數據 標記位private boolean clearOnCommit;//存放緩存中沒有的對象 只有在 commit 的時候 才會真正加入到緩存中private final Map<Object, Object> entriesToAddOnCommit;//事務提交前 在二級緩存中沒有找到這個對象就加入 entriesMissedInCacheprivate final Set<Object> entriesMissedInCache;//構造方法public TransactionalCache(Cache delegate) {this.delegate = delegate;this.clearOnCommit = false;this.entriesToAddOnCommit = new HashMap();this.entriesMissedInCache = new HashSet();}public String getId() {return this.delegate.getId();}public int getSize() {return this.delegate.getSize();}//獲取緩存public Object getObject(Object key) {//從二級緩存中獲取對象Object object = this.delegate.getObject(key);//為空if (object == null) {//key 加入到 entriesMissedInCachethis.entriesMissedInCache.add(key);}//更新二級緩存的時候 不會直接清除二級緩存 而是會將 clearOnCommit 改為true//clearOnCommit 為true 返回 null 否則返回查詢到的緩存對象return this.clearOnCommit ? null : object;}//存入緩存public void putObject(Object key, Object object) {//這里只是加入到 entriesToAddOnCommit 中this.entriesToAddOnCommit.put(key, object);}public Object removeObject(Object key) {return null;}public void clear() {this.clearOnCommit = true;this.entriesToAddOnCommit.clear();}//提交事務public void commit() {if (this.clearOnCommit) {//如果提交時候清除緩存 就執行清空操作this.delegate.clear();}//將 entriesToAddOnCommit 加入二級緩存this.flushPendingEntries();//加入完成之后 執行重置操作 重置 entriesToAddOnCommit entriesMissedInCache this.reset();}//回滾public void rollback() {//清除二級緩存this.unlockMissedEntries();//重置操作 重置 entriesToAddOnCommit entriesMissedInCache this.reset();}//重置操作private void reset() {this.clearOnCommit = false;this.entriesToAddOnCommit.clear();this.entriesMissedInCache.clear();}//刷新待處理的數據 其實就是加入二級緩存private void flushPendingEntries() {//迭代遍歷 entriesToAddOnCommit Iterator var1 = this.entriesToAddOnCommit.entrySet().iterator();while(var1.hasNext()) {Entry<Object, Object> entry = (Entry)var1.next();//加入二級緩存this.delegate.putObject(entry.getKey(), entry.getValue());}//迭代遍歷 entriesMissedInCachevar1 = this.entriesMissedInCache.iterator();while(var1.hasNext()) {Object entry = var1.next();if (!this.entriesToAddOnCommit.containsKey(entry)) {//entriesToAddOnCommit 中不存在 則加入二級緩存 value 為 nullthis.delegate.putObject(entry, (Object)null);}}}//如果回滾就執行該防范private void unlockMissedEntries() {//迭代遍歷 entriesMissedInCacheIterator var1 = this.entriesMissedInCache.iterator();while(var1.hasNext()) {Object entry = var1.next();try {//從二級緩存中移出對象this.delegate.removeObject(entry);} catch (Exception var4) {log.warn("Unexpected exception while notifiying a rollback to the cache adapter. Consider upgrading your cache adapter to the latest version. Cause: " + var4);}}}
}
二級緩存生效的時機
我們根據 DefaultSqlSession#commit 方法的源碼跟進去,發現最后調用了 TransactionalCache#commit 方法,也就是二級緩存的生效時機是在 SqlSession 提交之后,這樣就避免了單機情況下的臟讀問題。
//org.apache.ibatis.session.defaults.DefaultSqlSession#commit()
public void commit() {this.commit(false);
}//org.apache.ibatis.session.defaults.DefaultSqlSession#commit(boolean)
public void commit(boolean force) {try {this.executor.commit(this.isCommitOrRollbackRequired(force));this.dirty = false;} catch (Exception var6) {throw ExceptionFactory.wrapException("Error committing transaction. Cause: " + var6, var6);} finally {ErrorContext.instance().reset();}}//org.apache.ibatis.executor.CachingExecutor#commit
public void commit(boolean required) throws SQLException {this.delegate.commit(required);this.tcm.commit();
}//org.apache.ibatis.cache.TransactionalCacheManager#commit
public void commit() {Iterator var1 = this.transactionalCaches.values().iterator();while(var1.hasNext()) {TransactionalCache txCache = (TransactionalCache)var1.next();txCache.commit();}}//org.apache.ibatis.cache.decorators.TransactionalCache#commit
public void commit() {if (this.clearOnCommit) {this.delegate.clear();}this.flushPendingEntries();this.reset();
}
二級緩存更新時機
同樣從 DefaultSqlSession#update 方法入手分析,發現最終調用了 TransactionalCache#clear 方法,TransactionalCache#clear 方法并沒有正在的更新或者清除二級緩存,而是將 clearOnCommit 提交事務時候是否清除緩存改為 true(默認是false),事務提交時候會進行判斷,如果 clearOnCommit 為 true,就會清除二級緩存,同樣在查詢二級緩存的時候也會判斷 clearOnCommit 屬性,如果 clearOnCommit 為 true,則直接返回 null,來保證數據的準確性。
//org.apache.ibatis.session.defaults.DefaultSqlSession#update(java.lang.String)
public int update(String statement) {return this.update(statement, (Object)null);
}//org.apache.ibatis.session.defaults.DefaultSqlSession#update(java.lang.String, java.lang.Object)
public int update(String statement, Object parameter) {int var4;try {this.dirty = true;MappedStatement ms = this.configuration.getMappedStatement(statement);var4 = this.executor.update(ms, this.wrapCollection(parameter));} catch (Exception var8) {throw ExceptionFactory.wrapException("Error updating database. Cause: " + var8, var8);} finally {ErrorContext.instance().reset();}return var4;
}//org.apache.ibatis.executor.CachingExecutor#update
public int update(MappedStatement ms, Object parameterObject) throws SQLException {this.flushCacheIfRequired(ms);return this.delegate.update(ms, parameterObject);
}//org.apache.ibatis.executor.CachingExecutor#flushCacheIfRequired
private void flushCacheIfRequired(MappedStatement ms) {Cache cache = ms.getCache();if (cache != null && ms.isFlushCacheRequired()) {this.tcm.clear(cache);}}//org.apache.ibatis.cache.TransactionalCacheManager#clear
public void clear(Cache cache) {this.getTransactionalCache(cache).clear();
}//org.apache.ibatis.cache.decorators.TransactionalCache#clear
public void clear() {this.clearOnCommit = true;this.entriesToAddOnCommit.clear();
}
總結:二級緩存實現了 Sqlsession 之間的緩存數據共享,屬于 namespace/Mapper 級別的緩存,具有豐富的緩存淘汰策略,二級緩存使用 TransactionalCache 來解決臟讀的問題,只有事務提交的時候,對應的數據才會放入到二級緩存中,來避免臟讀問題,同時需要注意的是默認的情況下,Mybatis將一二級緩存都存儲到本地緩存中,因此在分布式情況下,二級緩存還是會出現臟讀問題,分布式情況下不建議使用二級緩存。
歡迎提出建議及對錯誤的地方指出糾正。





)









SpringBoot 整合多個kafka數據源-支持億級消息生產者)



