:::
大家好!今天我分享的文章是來自威斯康星大學麥迪遜分校和亞馬遜AWS AI實驗室的最新工作,文章所屬領域是推薦系統和因果推理,作者針對跨域推薦中的偏差問題提出了一種基于因果去偏的預訓練推薦系統框架PreRec。
:::

原文:Pre-trained Recommender Systems: A Causal Debiasing Perspective
地址:https://arxiv.org/abs/2310.19251
代碼:https://github.com/myhakureimu/PreRec
出版:WSDM '24
機構: 威斯康星大學麥迪遜分校、亞馬遜
1 研究問題
本文研究的核心問題是: 如何設計一個通用的預訓練推薦系統框架,能夠有效處理跨域推薦中的偏差問題。
::: block-1
假設我們有一個電商平臺,想要為不同國家的用戶推薦商品。每個國家的用戶行為和商品特征都有所不同,直接將一個國家的推薦模型應用到另一個國家往往效果不佳。我們希望能夠設計一個通用的推薦框架,可以在多個國家的數據上預訓練,然后快速適應到新的國家市場,同時還能處理不同國家之間的偏差問題。
:::
本文研究問題的特點和現有方法面臨的挑戰主要體現在以下幾個方面:
- 跨域推薦中存在域內偏差和跨域偏差,這些偏差會影響模型的泛化能力。例如,不同國家的商品流行度分布不同(域內偏差),以及不同國家的用戶行為模式差異(跨域偏差)。
- 現有的預訓練推薦方法(如ZESRec和UniSRec)沒有考慮這些偏差,可能會導致模型過擬合源域數據。
- 如何在保留通用知識的同時,有效地消除這些偏差是一個挑戰。
針對這些挑戰,本文提出了一種基于因果去偏的"PreRec"方法:
::: block-1
PreRec的核心思想是將推薦過程建模為一個概率圖模型,并引入因果推理的思想來處理偏差。它就像一個精明的導購,不僅了解每個國家的商品和用戶特點,還能識別出哪些是真正的用戶偏好,哪些只是由于某個國家特定的促銷活動或文化差異造成的偏差。具體來說,PreRec使用一個分層貝葉斯深度學習模型來捕獲用戶興趣、商品特征、域特征和流行度等因素。在預訓練階段,它通過顯式建模域內偏差(如商品流行度)和跨域偏差(如域特征),將這些偏差與通用知識分離。在推斷階段,它使用因果干預的方法來消除這些偏差的影響,只保留真正的用戶-商品匹配信息。這就像PreRec在每個國家都派了一個"特工",這些特工不僅收集各自國家的數據,還能識別出哪些是該國特有的"噪音"。在給新國家的用戶推薦時,PreRec就能拋開這些"噪音",專注于真正通用的推薦知識。
:::
2 研究方法
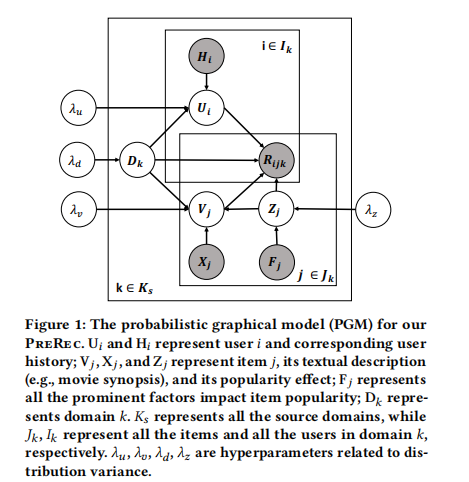
2.1 PreRec模型結構
PreRec是一種新型的預訓練推薦系統,采用層次化貝葉斯深度學習框架。它的核心目標是解決多域預訓練中的偏差問題,提高模型在新域上的泛化能力。PreRec的整體架構包括以下幾個關鍵組件:
- 用戶通用嵌入網絡(User Universal Embedding Network):這個網絡用于生成用戶的通用嵌入表示。它接收用戶的歷史交互序列作為輸入,通過一個序列模型(如Transformer)來聚合這些交互信息,最終輸出用戶的嵌入向量。
- 物品通用嵌入網絡(Item Universal Embedding Network):這個網絡用于生成物品的通用嵌入表示。它以物品的文本描述為輸入,通過預訓練的語言模型(如BERT)和一個單層神經網絡來提取物品的語義特征,最終輸出物品的嵌入向量。
- 域屬性嵌入(Domain Embedding):這是一個可學習的向量,用于捕捉每個域的特有屬性,如用戶群體特征、促銷活動等。
- 流行度嵌入(Popularity Embedding):這個組件用于建模物品在特定域內的流行度偏差。它基于物品的交互次數、流量和時間等因素計算得出。
舉個例子,假設我們在構建一個跨國的電商推薦系統。對于一個來自美國的用戶,用戶通用嵌入網絡會分析他過去購買的商品序列(如手機、耳機、充電器等),生成一個能夠反映他整體興趣的嵌入向量。對于一個新上架的手機,物品通用嵌入網絡會分析其產品描述,生成一個反映手機特征的嵌入向量。同時,我們還會有一個代表"美國市場"的域屬性嵌入,以及反映這款手機在美國市場受歡迎程度的流行度嵌入。
PreRec的創新之處在于,它明確地將這些不同來源的信息(用戶興趣、物品特征、域屬性、流行度)分開建模,這為后續的去偏和遷移學習奠定了基礎。
2.2 多域預訓練
在多域預訓練階段,PreRec的目標是從多個源域中提取通用知識,同時顯式建模和處理不同類型的偏差。這個過程主要包括以下幾個步驟:
- 數據收集:從多個源域(例如不同國家的電商平臺)收集用戶-物品交互數據、物品描述文本以及相關的元數據。
- 通用表示學習:使用物品通用嵌入網絡和用戶通用嵌入網絡,分別學習物品和用戶的通用表示。這些表示應該能夠捕捉到跨域的共性特征。
- 域內偏差建模:PreRec顯式地建模了域內的流行度偏差。具體來說,它引入了一個流行度嵌入 Z j Z_j Zj?,用于捕捉物品 j j j 在特定域內的流行度效應。這個流行度嵌入是基于物品的交互次數、總流量和時間等因素計算得出的。
- 跨域偏差建模:PreRec引入了一個域屬性嵌入 D k D_k Dk?,用于捕捉每個域 k k k 的特有屬性。這個嵌入可以理解為域的隱藏表示,它影響著該域內的用戶興趣、物品屬性和用戶行為模式。
- 聯合優化:PreRec通過最小化負對數似然來聯合優化所有這些組件。優化目標函數如下:
L = ∑ ? l o g ( f s o f t m a x ( U i T V j + D k W d + Z j W z ) ) + λ z / 2 ∑ ∣ ∣ Z j ? f p o p ( F j ) ∣ ∣ 2 + λ v / 2 ∑ ∣ ∣ V j ? f e ( D k , Z j ) ∣ ∣ 2 + λ u / 2 ∑ ∣ ∣ U i ? f s e q ( D k , H i ) ∣ ∣ 2 + λ d / 2 ∑ ∣ ∣ D k ∣ ∣ 2 L = ∑ -log(f_softmax(U_i^T V_j + D_k W_d + Z_j W_z)) + λ_z/2 ∑ ||Z_j - f_pop(F_j)||^2 + λ_v/2 ∑ ||V_j - f_e(D_k, Z_j)||^2 + λ_u/2 ∑ ||U_i - f_seq(D_k, H_i)||^2 + λ_d/2 ∑ ||D_k||^2 L=∑?log(fs?oftmax(UiT?Vj?+Dk?Wd?+Zj?Wz?))+λz?/2∑∣∣Zj??fp?op(Fj?)∣∣2+λv?/2∑∣∣Vj??fe?(Dk?,Zj?)∣∣2+λu?/2∑∣∣Ui??fs?eq(Dk?,Hi?)∣∣2+λd?/2∑∣∣Dk?∣∣2
這里, U i U_i Ui? 是用戶嵌入, V j V_j Vj? 是物品嵌入, D k D_k Dk? 是域屬性嵌入, Z j Z_j Zj? 是流行度嵌入, H i H_i Hi? 是用戶歷史, F j F_j Fj? 是流行度因子。
舉個具體的例子,假設我們在美國、英國和加拿大的電商平臺上預訓練PreRec。對于一個在美國平臺上很受歡迎的iPhone手機,它的表示會包含幾個部分:
- 通用物品嵌入:反映iPhone的基本特征,如智能手機、iOS系統等。
- 流行度嵌入:反映這款iPhone在美國市場的高人氣。
- 域屬性嵌入:可能捕捉到美國用戶偏好高端科技產品的特點。
通過這種方式,PreRec能夠區分出哪些特征是iPhone的固有屬性,哪些是由于美國市場的特殊性造成的,從而為后續的跨域推薦打下基礎。
2.3 零樣本推薦
零樣本推薦是PreRec的一個關鍵能力,它允許模型在沒有見過任何目標域數據的情況下,直接在新域上進行推薦。PreRec通過巧妙的因果干預機制來實現這一點。具體步驟如下:
- 消除跨域偏差:在進行零樣本推薦時,PreRec首先將域屬性嵌入 D k D_k Dk? 設置為0。這相當于執行了一個do-操作: d o ( D k = 0 ) do(D_k = 0) do(Dk?=0)。直覺上,這就好比我們在問:“如果沒有任何特定域的影響,用戶會如何與物品交互?”
- 保留域內偏差:雖然消除了跨域偏差,但PreRec保留了流行度嵌入 Z j Z_j Zj?。這是因為流行度信息通常在不同域之間具有一定的可遷移性。
- 計算推薦分數:PreRec使用因果干預后的用戶嵌入和物品嵌入來計算最終的推薦分數:
P ( R i j k ∣ d o ( U i , V j , Z j ) ) = f s o f t m a x ( U i T V j + Z j W z ) P(R_ijk|do(U_i, V_j, Z_j)) = f_softmax(U_i^T V_j + Z_j W_z) P(Ri?jk∣do(Ui?,Vj?,Zj?))=fs?oftmax(UiT?Vj?+Zj?Wz?)
這里, R i j k R_ijk Ri?jk 表示用戶 i i i 與物品 j j j 在域 k k k 中的交互。
舉個例子,假設我們要將預訓練好的PreRec應用到澳大利亞的電商平臺上。對于一個從未在澳大利亞市場出現過的新用戶,PreRec會這樣工作:
- 基于用戶的歷史行為(可能來自其他國家的平臺)生成用戶嵌入。
- 對于澳大利亞市場的每個商品,生成其通用物品嵌入。
- 計算每個商品在澳大利亞市場的流行度嵌入。
- 將域屬性嵌入設為0,相當于"假設沒有澳大利亞市場的特殊影響"。
- 基于以上信息計算推薦分數,并向用戶推薦得分最高的商品。
這種方法的優勢在于,它能夠利用從其他市場學到的通用知識,同時考慮商品在新市場的受歡迎程度,但不會被源域的特殊偏好所影響。
2.4 目標域微調
隨著在新域(如澳大利亞市場)積累了一定量的交互數據,PreRec可以通過微調來進一步提升推薦性能。微調過程包括以下步驟:
- 重新估計隱變量:PreRec會重新估計目標域的所有隱變量,包括用戶嵌入 U i U_i Ui?,物品嵌入 V j V_j Vj?,域屬性嵌入 D k D_k Dk?,和流行度嵌入 Z j Z_j Zj?。
- 端到端優化:PreRec在目標域數據上優化與預訓練階段相同的目標函數:
$$
L = ∑ -log(f_softmax(U_i^T V_j + D_k W_d + Z_j W_z))- λ_z/2 ∑ ||Z_j - f_pop(F_j)||^2
- λ_v/2 ∑ ||V_j - f_e(D_k, Z_j)||^2
- λ_u/2 ∑ ||U_i - f_seq(D_k, H_i)||^2
- λ_d/2 ∑ ||D_k||^2
$$
- 適應性推斷:微調后的推斷過程會考慮目標域的特性:
P ( R i j k ∣ d o ( U i , V j , D k , Z j ) ) = f s o f t m a x ( U i T V j + D k W d + Z j W z ) P(R_ijk|do(U_i, V_j, D_k, Z_j)) = f_softmax(U_i^T V_j + D_k W_d + Z_j W_z) P(Ri?jk∣do(Ui?,Vj?,Dk?,Zj?))=fs?oftmax(UiT?Vj?+Dk?Wd?+Zj?Wz?)
這里,我們不再將 D k D_k Dk? 設為0,而是使用學習到的目標域屬性嵌入。
具體來說,假設PreRec在澳大利亞市場運行了一段時間,收集到了一些用戶交互數據。微調過程會:
- 更新用戶嵌入,以更好地反映澳大利亞用戶的偏好。比如,可能會發現澳大利亞用戶特別喜歡戶外運動產品。
- 調整物品嵌入,以適應澳大利亞市
3 實驗
3.1 實驗場景介紹
本論文提出了一個可以跨領域預訓練的推薦系統模型PreRec。實驗主要驗證PreRec在新的目標領域上的推薦性能,包括零樣本場景和微調場景。實驗涉及跨市場(不同國家的Amazon市場)和跨平臺(Amazon與Online Retail)兩種跨域場景。
3.2 實驗設置
- Datasets:
- XMarket數據集:覆蓋18個本地市場(國家)的16個不同產品類別
- Online Retail數據集:來自英國在線零售平臺的數據
- 預訓練數據集:印度、西班牙、加拿大
- 跨市場目標數據集:澳大利亞、墨西哥、德國、日本
- 跨平臺目標數據集:Online Retail
- Baselines:Random, POP, SBERT, GRU4Rec, SASRec, ZESRec, UniSRec, PreRec_n
- Implementation details:
- 所有方法使用256維的物品和用戶嵌入
- 基于GRU的序列模型使用2層GRU
- 基于自注意力的序列模型使用2層多頭注意力
- 使用Adam優化器,學習率為0.0003
- 在驗證集上使用平均r-NDCG@K%進行早停
- Metrics:Recall@K% 和 r-NDCG@K%
- 環境:使用一塊Tesla V100 GPU進行訓練
3.3 實驗結果
實驗1、零樣本推薦實驗

目的:評估PreRec在新的目標域上的零樣本推薦性能
涉及圖表:表1
實驗細節概述:在三個源域(印度、西班牙、加拿大)上預訓練PreRec,然后在五個目標域(澳大利亞、墨西哥、德國、日本、Online Retail)上進行零樣本評估
結果:
- PreRec在幾乎所有情況下都顯著優于所有基線方法
- 在跨市場場景中,PreRec在澳大利亞數據集上獲得最大改進,在日本數據集上改進最小
- 在跨平臺場景(Online Retail)中,PreRec同樣表現出色
實驗2、消融實驗
目的:驗證因果去偏機制的有效性
涉及圖表:表1
實驗細節概述:比較PreRec與其簡化版本PreRec_n(忽略了跨域和域內偏差項)的性能
結果:在幾乎所有情況下,PreRec都優于PreRec_n,證明了因果去偏機制的有效性
實驗3、全量微調實驗
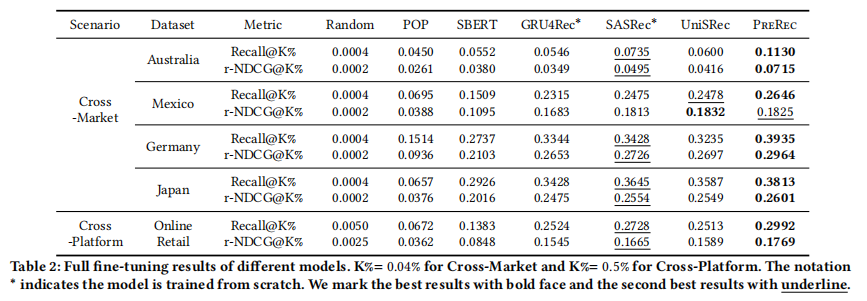
目的:評估在目標域上全量微調后PreRec的性能
涉及圖表:表2
實驗細節概述:在目標域的所有可用訓練數據上微調模型,并與基線方法比較
結果:
- PreRec在微調后仍然在幾乎所有情況下顯著優于所有基線方法
- 這表明PreRec在預訓練階段提取了通用知識,即使在目標域有充足數據的情況下仍具有互補價值
- PreRec能夠快速適應新域,同時不會遺忘預訓練階段學到的知識
實驗4、增量微調實驗
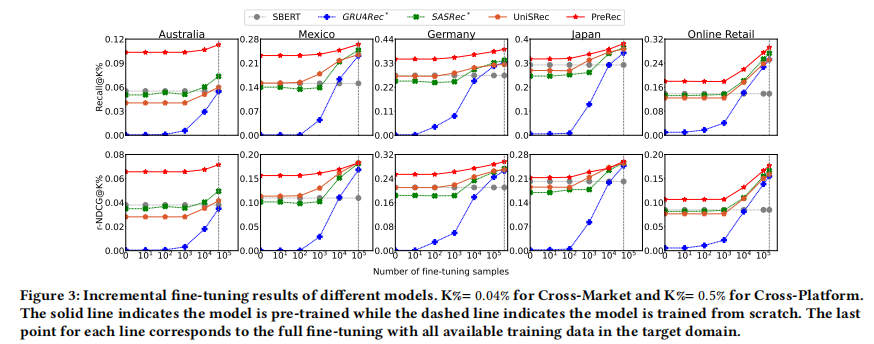
目的:研究目標域微調樣本數量對模型性能的影響
涉及圖表:圖3
實驗細節概述:使用逐漸增加的目標域訓練數據對模型進行微調,觀察性能變化
結果:
- PreRec在所有目標域中都優于基線方法
- 隨著微調樣本數量增加,PreRec的性能穩步提升,表明它在逐步適應目標域
- 即使在有10^4個目標域訓練樣本時,PreRec與基線方法的性能差距仍然顯著
- 這表明PreRec在預訓練階段提取的知識在目標域數據有限的情況下具有重要價值
非常感謝您提供的論文和問題。下面是我根據您的要求對論文進行的總結和分析:
4 總結后記
本論文針對預訓練推薦系統中的域內偏差和跨域偏差問題,提出了一種名為PreRec的因果去偏視角方法。PreRec通過引入顯式和隱式的混雜因子來建模不同類型的偏差,并使用因果干預機制來消除這些偏差的影響。實驗結果表明,PreRec在跨市場和跨平臺的零樣本和微調場景下都顯著優于現有方法,為構建通用的預訓練推薦系統提供了新的思路。
::: block-2
疑惑和想法:
- 論文中提到的顯式和隱式混雜因子是如何具體定義和識別的?是否存在其他類型的混雜因子需要考慮?
- PreRec如何處理動態變化的用戶興趣和項目特征?是否可以引入時間序列建模來捕捉這些變化?
- 在跨語言場景下,PreRec的性能如何?是否需要額外的跨語言對齊機制?
- PreRec能否擴展到處理多模態數據(如圖像、視頻)的推薦任務?這將帶來哪些新的挑戰?
:::
::: block-2
可借鑒的方法點:
- 將因果推斷與深度學習相結合的思路可以推廣到其他存在偏差問題的機器學習任務中,如計算機視覺、自然語言處理等。
- 使用分層貝葉斯模型來捕捉不同層次的特征和偏差的方法值得借鑒,可以應用于其他需要建模復雜層次結構的問題。
- 通過預訓練和微調相結合的方式來提高模型的泛化能力和適應性的思路可以廣泛應用于遷移學習和領域適應等場景。
- 設計新的評估指標(如r-NDCG@K%)來更公平地比較不同域間的性能的做法值得借鑒,可以應用于其他需要跨域評估的任務中。
:::






)












)