鏈接:https://arxiv.org/pdf/2208.06366
論文:BEIT V2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
Introduction
- Motivation:Masked image modeling (MIM) 任務在自監督表征學習上取得了不錯的成績,但是現有方法大多是基于low-level image pixels,需要探索模型的high-level semantics。
- 創新點:引入了矢量量化知識蒸餾(Vector-Quantized Knowledge Distillation ,VQ-KD)算法來離散語義空間,同時引入一個patch聚合策略(a patch aggregation strategy)鼓勵模型關聯所有patch到[CLS]
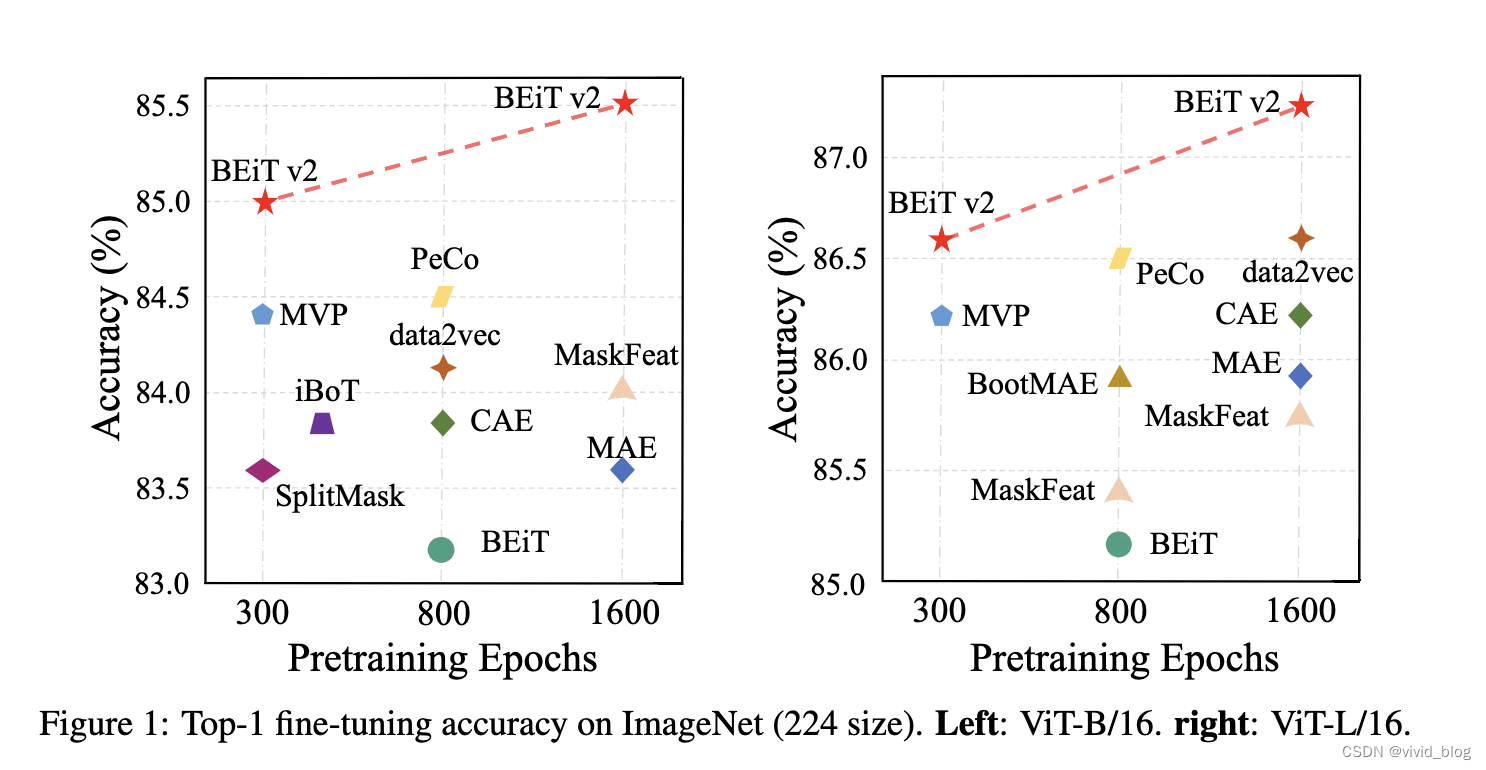
- 實驗效果:
Details
整體架構與BEiT相似,依舊是包含一個visual tokenizer對圖像進行離散表示(visual tokens),訓練目標則是重建相應位置的masked visual tokens。
- Image Representation:依舊使用ViT,將輸入切為patches,flattened and linearly projected to input embeddings,最終輸入transformer。
- Training Visual Tokenizer
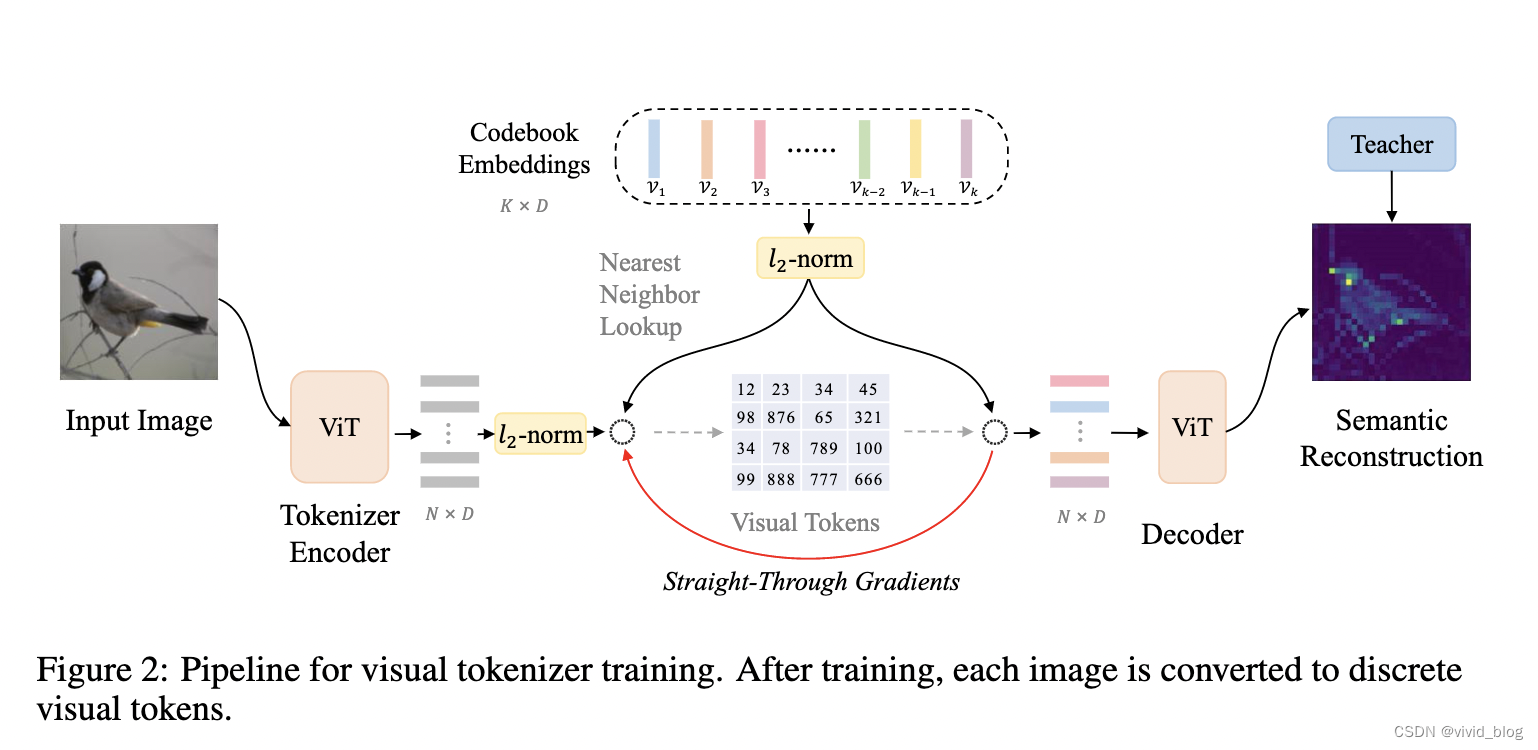
a. 提出vector-quantized knowledge distillation (VQ-KD)方法訓練visual tokenizer, 架構如上圖所示,包括tokenizer和decoder兩部分。
b. tokenizer將輸入圖像映射為一系列visual tokens,進行離散化,與patch數量對應。其包含一個Vision Transformer encoder, and a quantizer。想通過encoder將圖像編碼為向量,然后quantizer查找最近鄰的表示。尋找最近鄰embedding公式如下(quantizer的目的是將向量映射到固定詞表,便于在后續mask任務中預測):
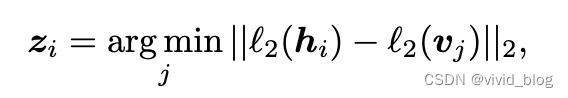
先對向量進行l2正則,使用余弦相似度計算。
c. 向量量化后,過l2正則輸入decoder,decoder模型為多層Transformer,其目標是重建Teacher模型的語義特征(Teacher模型可以為DINO或者CLIP)。再最大化decoder的輸出和teacher模型的輸出的余弦相似度。
d. 由于量化過程不可微,直接使用梯度拷貝(從decoder的輸入到encoder的輸出),直觀上,量化器為encoder輸出查找最近的編碼,所以該codebook embeddings的提督對encoder的優化方向有效。

第一項為decoder輸出與teacher輸出的余弦相似度損失,sg表示stop-gradient,前向傳遞過程中為恒等式,同時在反向傳播期間具有零梯度。第二項和第三項分別代表前向和反向。 - Improving codebook utilization.
向量量化訓練期間很容易遇到codebook的坍縮,只有一小部分的codes可以使用,
a. 量化過程將碼本嵌入空間的維數減少到32-d, 在被送入解碼器之前被映射回高維空間
b. 指數移動平均可以使VQ-KD的訓練穩定。 - Pretraining BEIT V2
a. 給定輸入圖像x,大約40%的patches會被block-wisely masked,masked position會被標記,masked patch會被一個shared learnable embedding取代。
b. prepend a learnable [CLS] token,在預測時對應位置加一個全連接層。
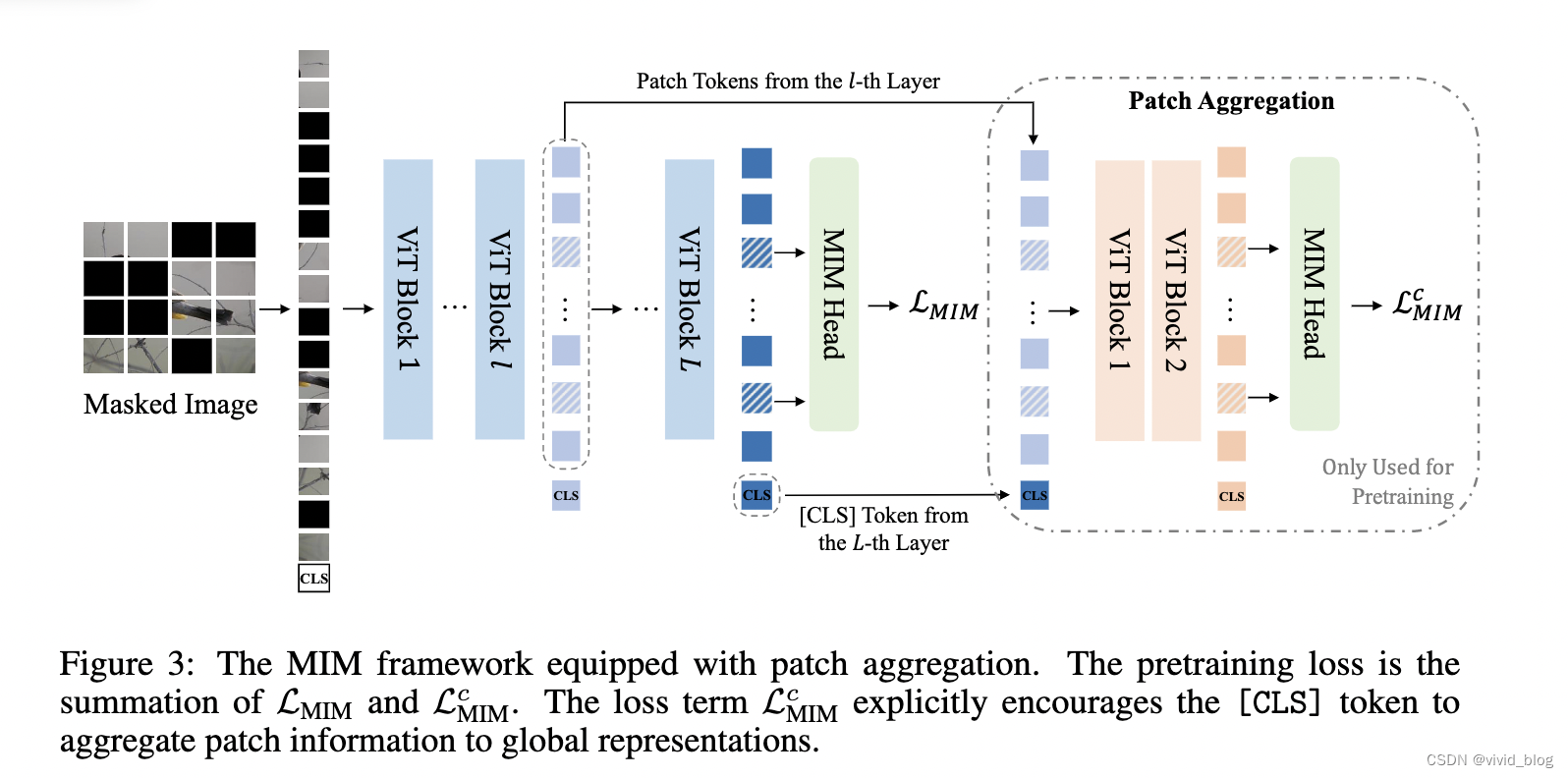
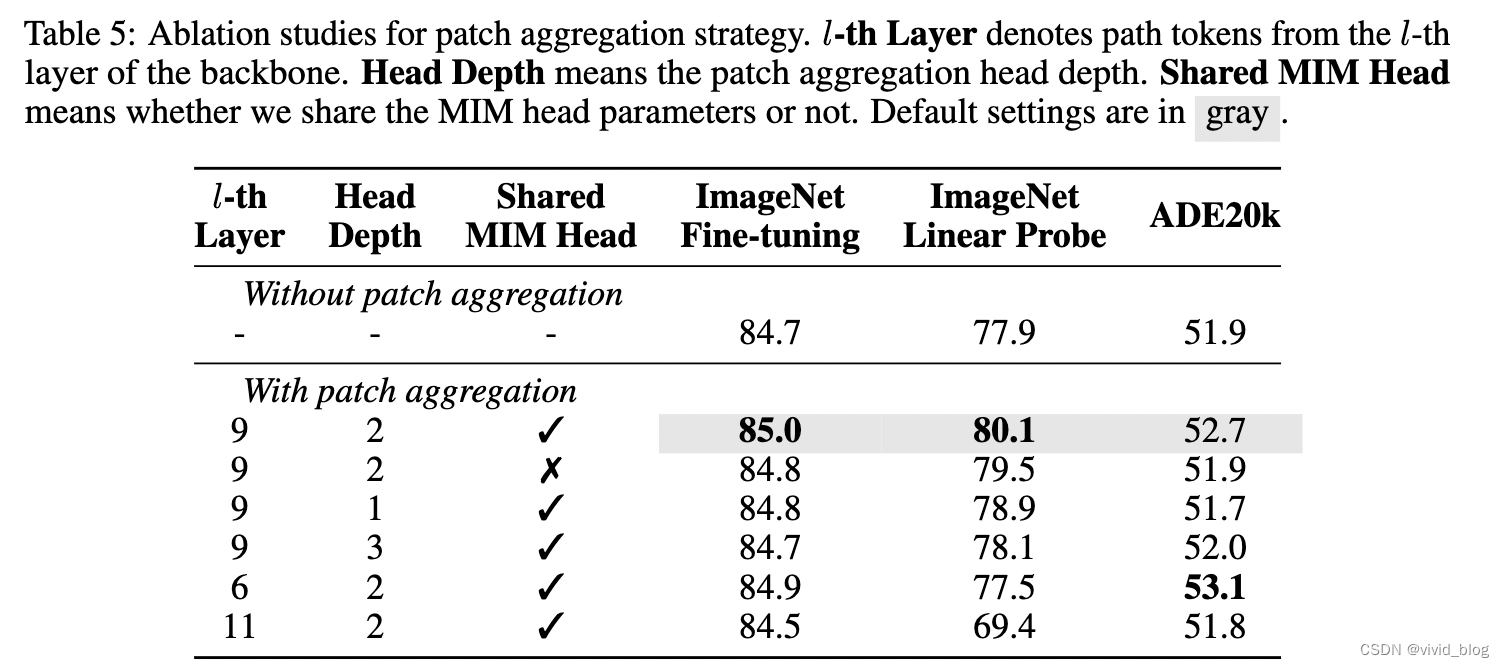
c. Pretraining global representation:為了使CLS更好地進行全局圖像特征表示,消除patch-level的預訓練對image-level的表示差異,選取最后L層的CLS表示,以及encoder第l層的patch表示,拼接作為一個淺層(2-layer)Transformer的輸入,進行掩碼預測。MIM Head的參數共享,兩個loss相加(原始MIM loss和過完淺層transformer的loss)。直觀上,這樣做的好處在于由于使用訓練不充分的中間表示,導致CLS更好地涵蓋全局信息,使MIM loss更低。該新增的兩層transformer僅輔助訓練,inference會被丟棄。
實驗
- 兩階段訓練參數
a. Visual tokenizer training
ViT-B/16,decoder為三層Transformer,和encoder頭數與維度都相同,Teacher使用CLIP-B/16 train VQ-KD on ImageNet-1k with 224×224 resolution。code size K is set as 8192,code dimension D as 32。
b. Masked image modeling
ImageNet-1K,set l = 9 for ViT-B/16, l = 21 for ViT-L/16,40% mask
pre-train的vit encoder和modeling階段不是同一個 - 對比實驗
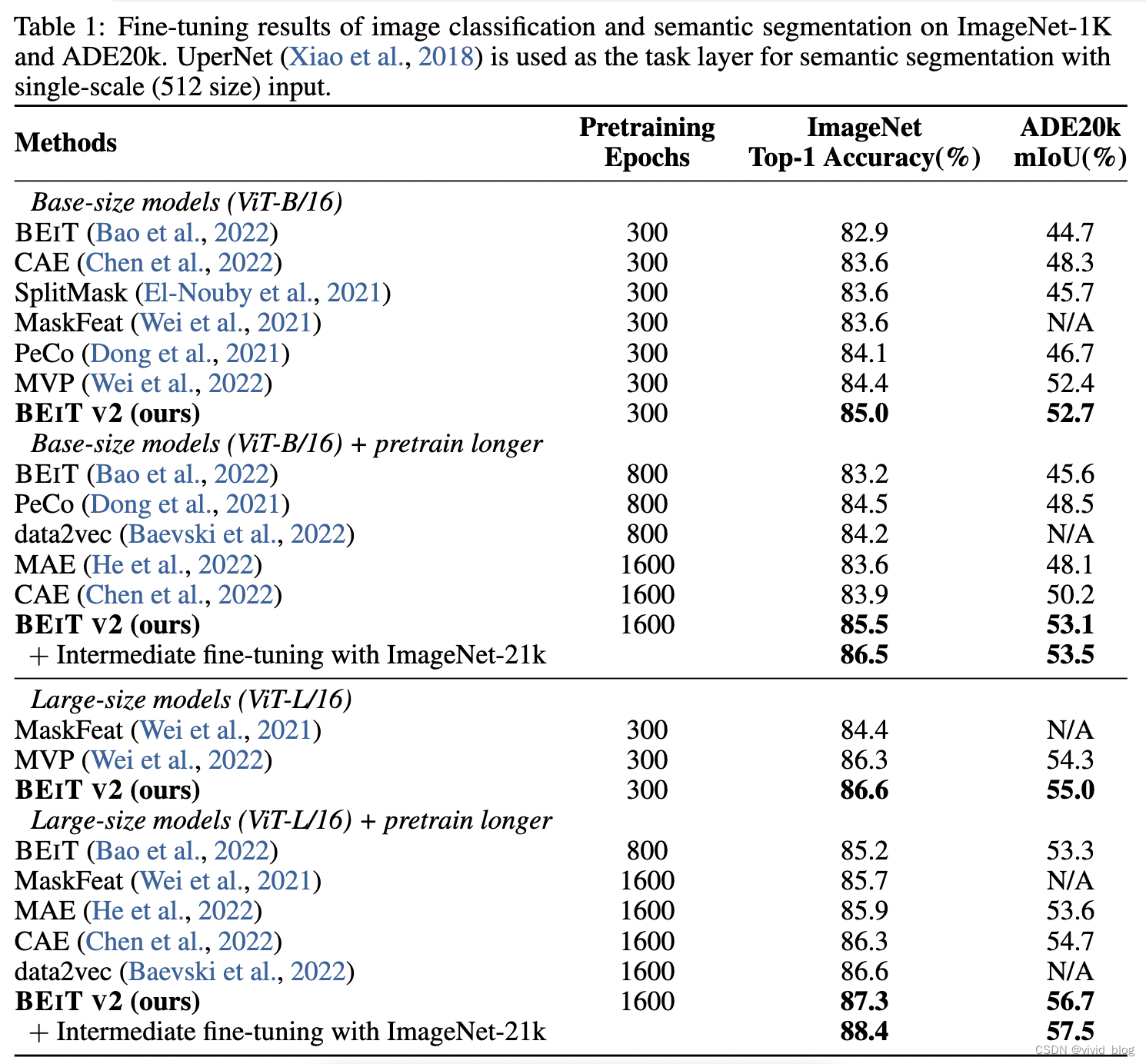
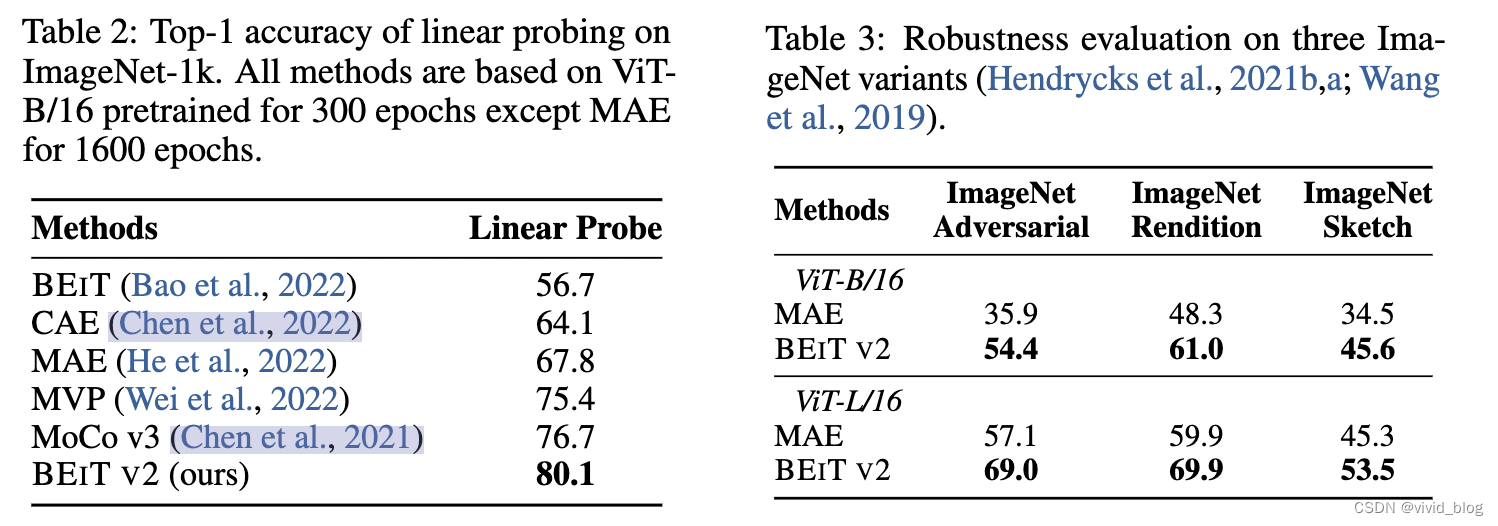
- 消融實驗
a. VQ-KD的消融
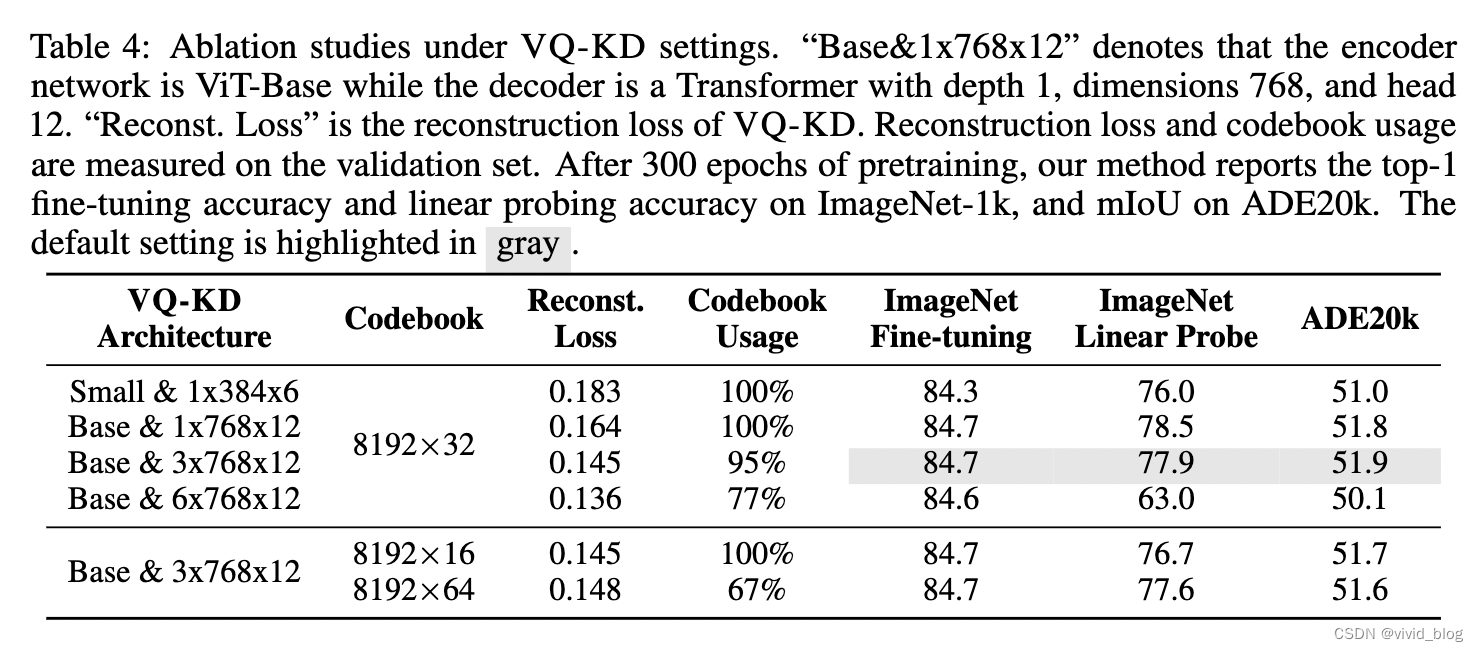
b. Patch aggregation消融
c. VQ-KD targets
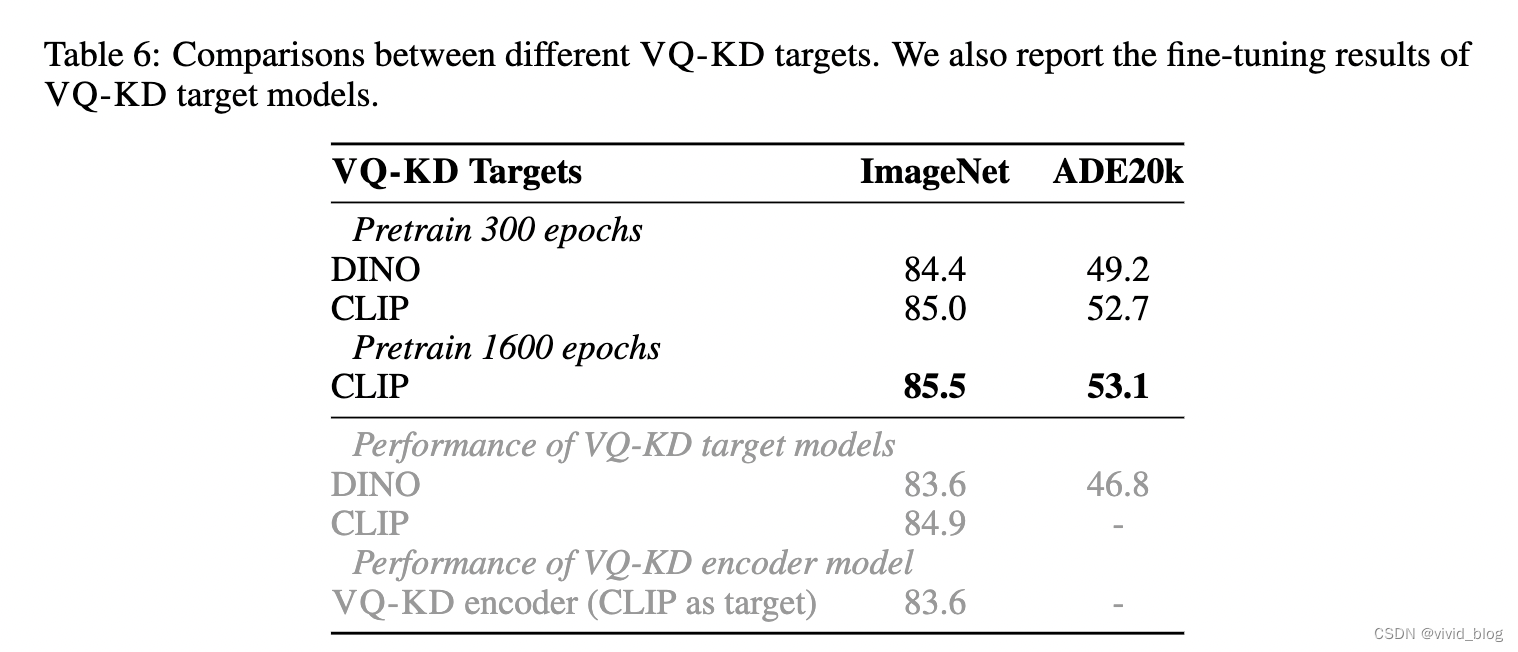
- 可視化實驗







)

辦理全面講解)
)









