AI應用開發相關目錄
本專欄包括AI應用開發相關內容分享,包括不限于AI算法部署實施細節、AI應用后端分析服務相關概念及開發技巧、AI應用后端應用服務相關概念及開發技巧、AI應用前端實現路徑及開發技巧
適用于具備一定算法及Python使用基礎的人群
- AI應用開發流程概述
- Visual Studio Code及Remote Development插件遠程開發
- git開源項目的一些問題及鏡像解決辦法
- python實現UDP報文通信
- python實現日志生成及定期清理
- Linux終端命令Screen常見用法
- python實現redis數據存儲
- python字符串轉字典
- python實現文本向量化及文本相似度計算
- python對MySQL數據的常見使用
- 一文總結python的異常數據處理示例
- 基于selenium和bs4的通用數據采集技術(附代碼)
- 基于python的知識圖譜技術
- 一文理清python學習路徑
- Linux、Git、Docker常用指令
- linux和windows系統下的python環境遷移
- linux下python服務定時(自)啟動
- windows下基于python語言的TTS開發
- python opencv實現圖像分割
- python使用API實現word文檔翻譯
- yolo-world:”目標檢測屆大模型“
- 爬蟲進階:多線程爬蟲
- python使用modbustcp協議與PLC進行簡單通信
- ChatTTS:開源語音合成項目
- sqlite性能考量及使用(附可視化操作軟件)
- 拓撲數據的關鍵點識別算法
- python腳本將視頻抽幀為圖像數據集
- 圖文RAG組件:360LayoutAnalysis中文論文及研報圖像分析
- Ubuntu服務器的GitLab部署
- 無痛接入圖像生成風格遷移能力:GAN生成對抗網絡
- 一文理清OCR的前世今生
- labelme使用筆記
- HAC-TextRank算法進行關鍵語句提取
34.Segment any Text:優質文本分割是高質量RAG的必由之路
文章目錄
- AI應用開發相關目錄
文本自動切句是個很有趣且很重要的場景,傳統的句子分割方法依賴于基于規則或統計的方法,這些方法通常需要依賴于標點符號等詞匯特征,例如早期方法使用決策樹來確定文本中的每個標點符號是否表示句子邊界,這基于標點周圍的語言特征。然而,這些方法在面對缺少標點、新領域適應性差、效率不高等問題時表現不佳。
huggingface:https://huggingface.co/segment-any-text
這是一種用于改善自然語言處理(NLP)系統中文本句子分割的方法,據Segment any Text名稱看,這是一個能夠分割任意段落自然語言文本的工作。
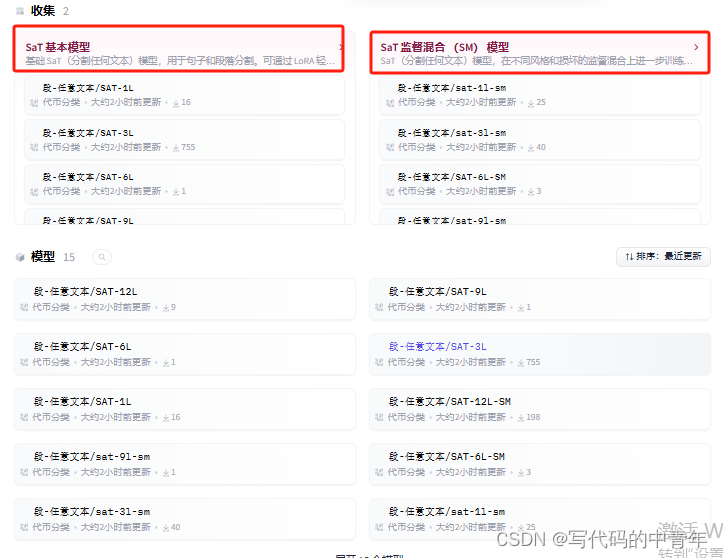
其算法主要分類基礎模型和監督混合模型(SM)兩類。基礎 SaT(分割任何文本)模型,用于句子和段落分割。可通過 LoRA 輕松適應;SM則在不同風格和損壞的監督混合數據上進一步訓練。
每種模型后邊的數字表示幾個transfomer層:

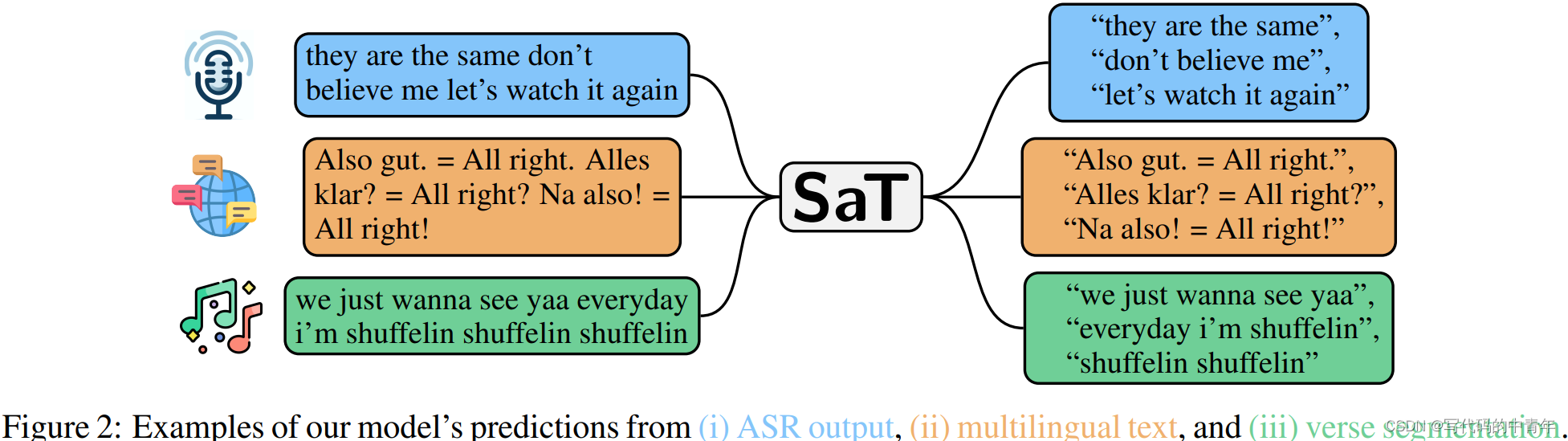
通過示例可以發現,其各種文本,是包括了無標點無格式文本、符號混亂無格式文本、語義混亂無格式文本。
可推測模型具備在文本分割需求下的語言理解能力,該工作大大增強了文本分割的適用面。
但缺陷是:
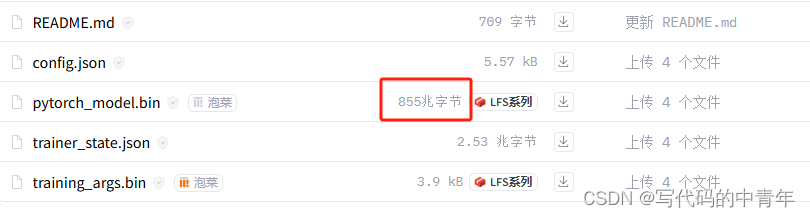
模型不小。
此次分享,各位按需使用。


)

辦理全面講解)
)













