InnoDB 引擎,每一個數據表有兩個文件 .frm和.ibd,分別為表結構,數據和索引,數據掛在主索引的葉子節點上,此主索引稱為聚簇索引。
MyISAM 引擎,每一個數據表有三個文件.frm和.MYI和.MYD,分別為表結構,索引,數據;也就是說其索引和數據是分開的,索引的葉子節點存儲的不是數據而是磁盤地址,稱為非聚簇索引。
下面只分析 InnoDB 引擎。
一、為什么是 B+Tree 而不是 B-Tree
B-Tree
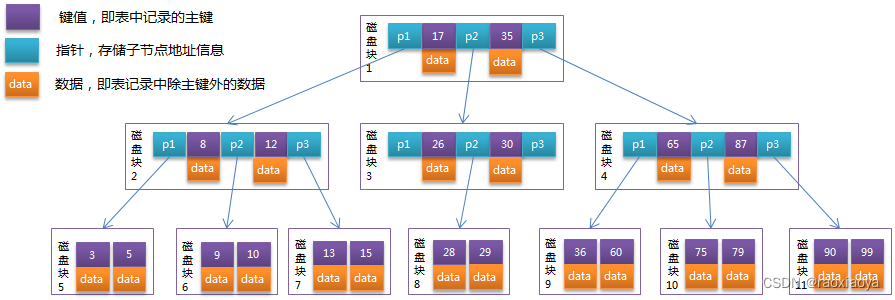
B+Tree
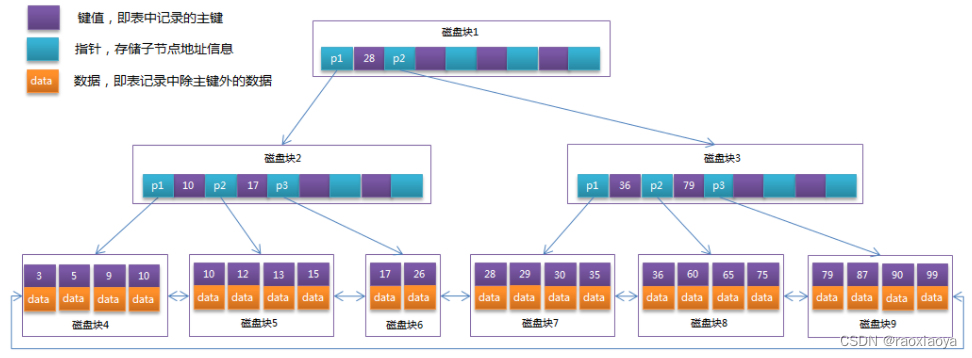
他兩最大的區別就是 B+Tree 將data部分下沉到了最后一級,即葉子節點。
對于基于磁盤的存儲,一般使用對磁盤的IO次數來評判索引結構的優劣,假設操作系統對磁盤的每次IO能讀取 4K 數據(塊),假設索引結構的每一個節點有16K的固定空間,這個16K稱為頁,索引以頁作為最基本的管理單位,所以每一次讀取要4次IO,從節省IO次數的角度講,如果每個節點上如果能存儲更多的key就能減少IO的次數,而B+Tree是將所有的data下放到葉子節點,其他節點全部用來存儲key和指針,顯然IO效率更高。
一般在數據庫系統或文件系統中使用的B+Tree結構都在經典B+Tree的基礎上進行了優化,增加了順序訪問指針。在B+Tree的每個葉子節點增加一個指向相鄰葉子節點的指針,做這個優化的目的是為了提高區間訪問的性能。也就是說,通過這個指針你可以訪問到已經排序好的key的列表。
二、InnoDB 引擎讀寫磁盤的過程
我們經常聽人說Mysql對磁盤的寫操作是隨機尋址的,所以需要WAL組件。但是為什么Mysql對磁盤的寫操作是隨機尋址的呢?這就需要了解它讀寫磁盤的過程。
就以InnoDB引擎為例,其索引結構和源數據都存在.ibd文件里,文件是一塊大的連續的磁盤空間,收到查詢請求后引擎就去讀取此文件的主索引,以頁(16K)為單位讀取,從B+Tree的根節點開始,當然有時候一個節點不止一頁,如果沒有找到這個key就要接著讀,直到找到了data。
從根節點指向一級節點的時候,那么一級節點存在文件中的哪個位置呢,或者說即便你知道了它在文件中的位置,你要怎么讀到它呢,我們可以使用相對于文件起始位置的偏移量來讀取那一塊的數據,或者計算出其在磁盤上的地址,然后直接讀取磁盤,所以指向子節點使用的是指針,整個的讀取過程是跳躍的隨機的。
同樣的,在寫入的時候,要寫入的目標磁盤塊的位置也是跳躍的,所以說寫操作是隨機的尋址,它不是append模式。有時候在寫入后現有節點還要調整。
說到底這些節點都還是存在于文件中,文件是一塊大的連續的磁盤空間,所以這里的指針應該是相對于文件起始地址的相對地址,而不能是磁盤的絕對地址,否則你一移動文件那豈不都失效了。
在機械硬盤上面,這種隨機尋址會嚴重影響磁盤的IO性能。
三、需要 WAL (Write-Ahead Logging)
既然直接落盤性能堪憂,那就改成異步落盤。基本上所有的數據庫都使用WAL模式來解決這個問題,實現方式可能各有不同,但大致思路都是一樣的。
一個修寫入請求,先寫入日志文件,成功之后才寫入緩存,然后有后臺程序將日志文件的內容落盤。
在寫日志文件的時候,使用 append模式,這就是順序寫,要比隨機寫好很多。
redo log:保證數據一致性。如果Mysql宕機了,重啟的時候可以將日志文件中未落盤的數據落盤。
undo log:保證事務的原子性,實現多版本并發控制(MVCC)。它相當于在修改之前做一下備份。
組提交機制:將多個小的事務合并成一組再執行落盤,可以大幅度降低磁盤的 IOPS 消耗。







半決賽(華中賽區)Pwn題解)







)



