文章目錄
- 前言
- 一、IP協議
- IP報頭解析
- 4位版本
- 4位首部長度
- 16位總長度
- 8位生存時間
- 8位協議
- 16位首部校驗和
- 32位源IP地址和32位目標IP地址
- 網段劃分
- 子網-局域網
- 子網掩碼
- 特殊的IP地址
- 公網IP地址與私網IP地址
- 運營商
- 路由
- 路由表
- 數據鏈路層
- MAC幀格式
- 局域網通信原理
- 局域網數據碰撞
- MTU
- 分片(網絡層IP協議)
- ARP協議
- ARP協議的作用
- ARP數據報的格式
- 環境模擬
- RARP請求/應答
- DNS(Domain Name System)
- ICMP協議
- traceroute命令
- NAT技術
- NAT技術的缺陷
前言
上一章我們已經學習了傳輸層的TCP協議和UDP協議,本章我們來講傳輸層的下一層,網絡層IP協議。
一、IP協議
對于IP,我們之前也有過一些簡單的表述,我們說要在全網中找到唯一一臺主機就需要目標IP地址。
這次我們主要對IP進行一個更加深入的認識。
IP報頭解析
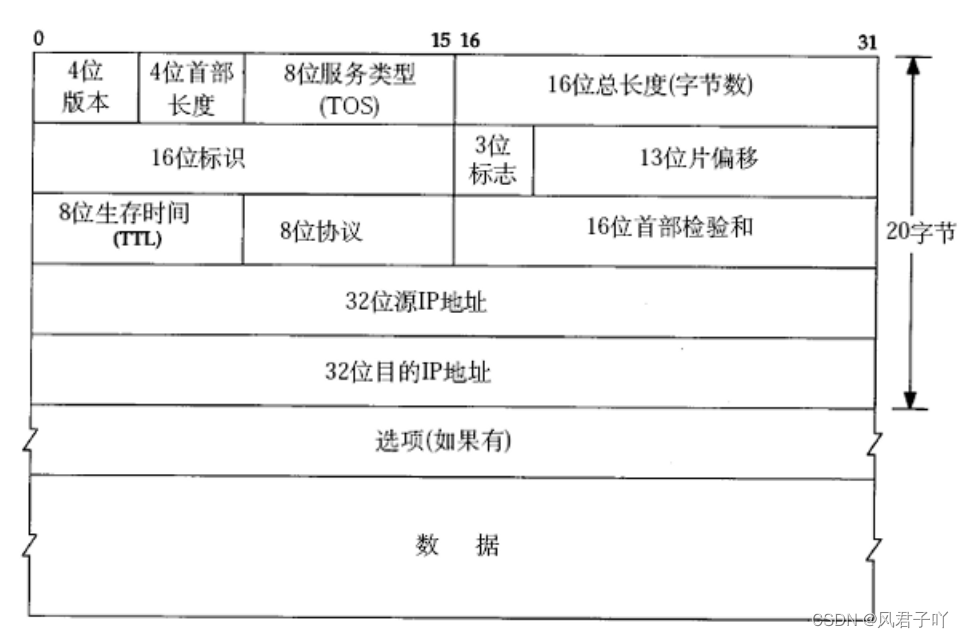
IP報文與TCP報文格式有點相似,他們的報頭都是固定20字節+選項長度,最后都是它們自己的有效載荷。
4位版本
對于IPv4而言,它的版本就是4,所以這里的四位版本就是4。
那么IPv6呢? IPv6可以說基本與IPv4在結構上完全不相干,所以這里的4位版本與IPv6沒有任何關系。
4位首部長度
與TCP的4位首部長度一樣,TCP報頭與IP報頭都是20字節+選項字節長度,所以這里也是一樣,4個bit位能代表0 - 15 ,加上以4字節為單位的話,就是0 - 60字節。
16位總長度
16位總長度代表的就是整個報文的長度,16位bit可以代表2^16 - 1 = 65535個字節。 所以剛好,通過16位總長度 - 4位首部長度就可以得到有效數據載荷的長度。
8位生存時間
TTL(Time To Live)代表一個IP報文最多可以經過多少次路由器的傳遞,TTL剛發出時一般為64,之后每經過一個路由器,TTL - 1, 如果等TTL減到0還未到達目標主機,該報文則被舍棄。
這樣設計的原因是因為我們在查找目標主機的時候,并不是每次都能找到目標主機的,有時候會因為網絡或者對方主機出現問題,導致報文一直在各個路由器流竄,如果不進行一定時間內的銷毀,那么這些流竄的報文將會持續存在,且耗費資源。所以就有了TTL來控制報文的生存時間。
8位協議
這8位協議存儲的是上層協議的類型,目標主機在拿到IP報文時,就可以通過報頭中的8位協議找到解包之后的有效載荷應該交給哪個協議,是交給UDP協議還是TCP協議。
當然,在封裝的時候也是一樣,會根據上層的哪個協議交付給IP協議來填寫8位協議。
16位首部校驗和
用來校驗首部數據是否有問題,這里不做細講。
32位源IP地址和32位目標IP地址
這個已經很明顯了,不做過多解釋了。
我們的32位IP地址換算下來一共可以有42億多的IP地址。相當于說全網可以代表42億個入網設備,但是現如今已經不同于20多年前,如今的入網設備已經不止42億臺設備了,所以現如今就需要有解決方案,IPv6也是一種解決方案。
網段劃分
不過我們先來講講網段劃分的概念,IP地址分為兩個部分, 網絡號和主機號。
子網-局域網
以我們的路由器為例,我們連接我們路由器的網絡,其實就是連接上了路由器創建的一個子網,我們也稱這個子網為局域網。
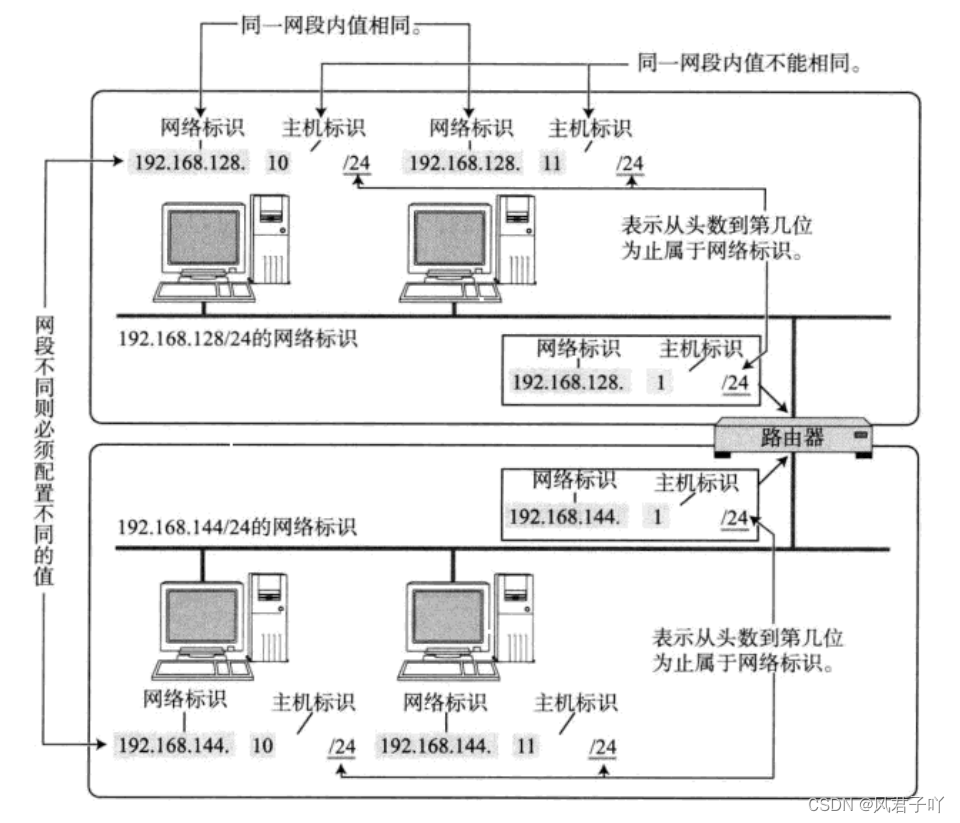
以上圖為例,192.168.128這里就可以被理解為網絡號 ,一臺主機的主機號為10,所以它的IP地址就是192.168.128.10,另一臺主機的主機號為11,那么它的IP地址就是192.168.128.11。
不同的子網其實就是把網絡號相同的主機放到一起。
過去曾經提出一種劃分網絡號和主機號的方案, 把所有IP地址分為五類, 如下圖所示(該圖出自[TCPIP])。
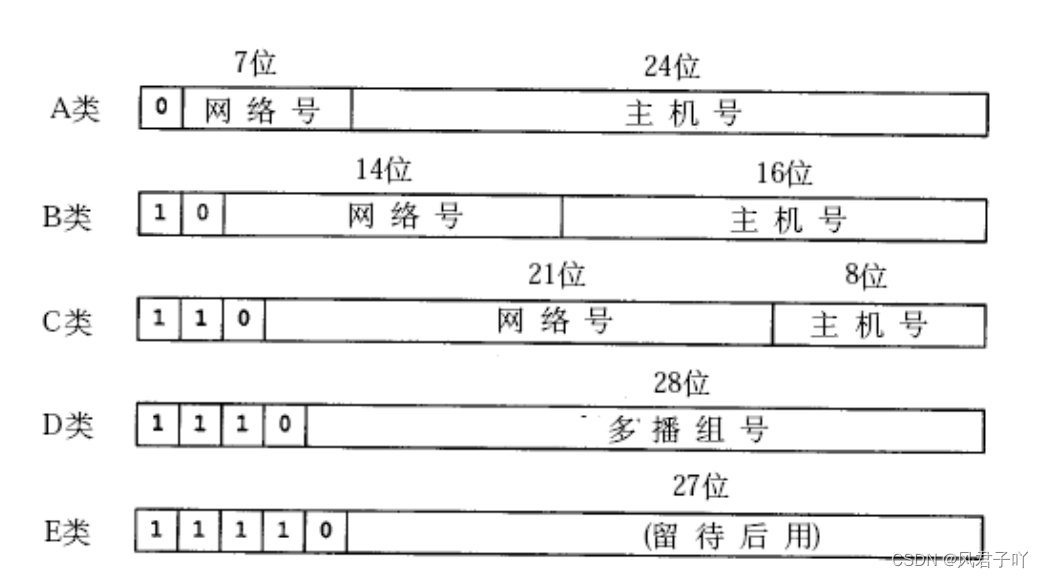
。
-
A類 0.0.0.0到127.255.255.255
-
B類 128.0.0.0到191.255.255.255
-
C類 192.0.0.0到223.255.255.255
-
D類 224.0.0.0到239.255.255.255
-
E類 240.0.0.0到247.255.255.255
比如說A類, 如果你可以申請一個1.開頭的網絡IP地址,那么你申請的這個網絡理論上就可以連接2^24臺主機。
所以缺點很明顯,申請這樣一個A類或者B類的網絡,即使是一個組織,企業,想要讓一個子網連接這么多臺主機是很難的(就需要有網絡運營商)。
所以這就勢必會造成許多IP地址是荒廢的。 更何況現在的如今互聯網時代,42億個IP地址對應每一臺入網設備的話,都根本不夠分,你竟然還浪費。
所以針對這一問題,我們就提出了新的劃分方案,稱為CIDR(Classless Interdomain Routing)。
引入一個額外的子網掩碼(subnet mask)來區分網絡號和主機號。
子網掩碼
子網掩碼也是一個32位的正整數. 通常用一串 “0” 來結尾,將IP地址和子網掩碼進行 “按位與” 操作, 得到的結果就是網絡號。
由子網掩碼按位與出來的網絡號和主機號的劃分與這個IP地址是A類、B類還是C類無關。
IP 地址 & 子網掩碼就能得出網絡號,所以只要子網掩碼的 1 更少,網絡范圍就更大, 子網能連接的設備就越多。
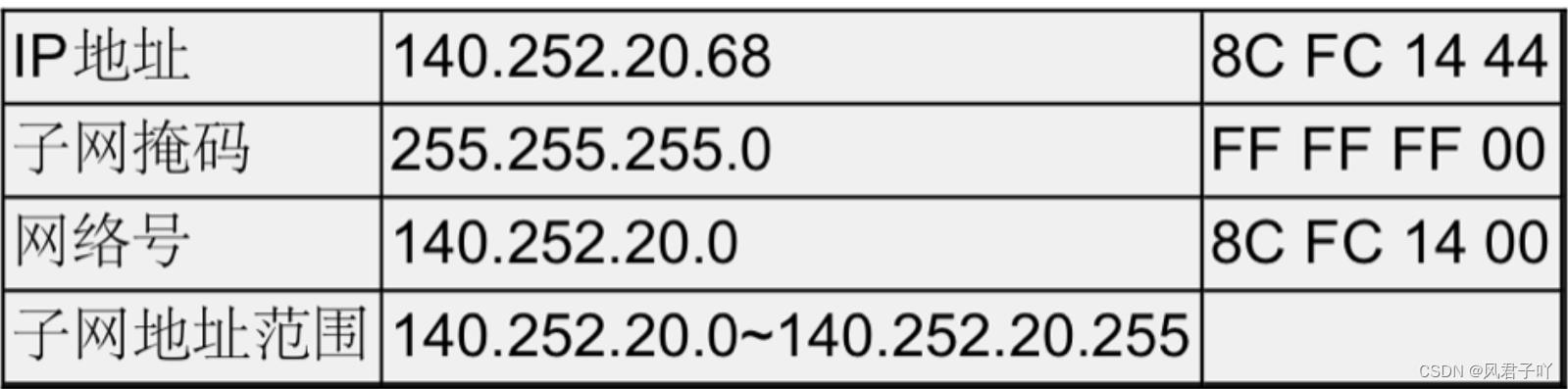
再比如說我現在電腦的IP地址
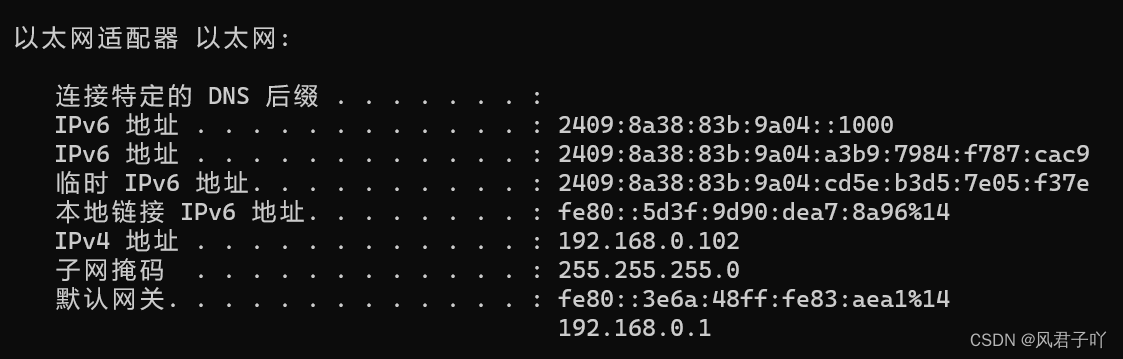
其中網絡號就是192.168.0 , 主機號是102.
連入我這一子網的主機的IP范圍就是192.168.0 ~ 192.168.255。
這僅僅是我這個路由器的子網掩碼,而我路由器需要連接的是運營商的路由器,所以我的路由器也存在于運營商路由器的子網當中,它的子網地址范圍一定會比我大很多,因為肯定不止連接我家一個路由器,需要連接到萬戶的路由器。
所以運營商的路由器的子網掩碼的全1bit位就會更少,我們的設備包括私人路由器也是處于運營商路由器的子網范圍當中。
引入子網掩碼以后,就可以將網絡號劃分地更細,更好的利用我們的IP地址。
特殊的IP地址
將IP地址中的主機地址全部設為0, 就成為了網絡號, 代表這個局域網。
將IP地址中的主機地址全部設為1, 就成為了廣播地址, 用于給同一個鏈路中相互連接的所有主機發送數據包。
127.*的IP地址用于本機環回(loop back)測試,通常是127.0.0.1。
公網IP地址與私網IP地址
如果一個組織內部組建局域網,IP地址只用于局域網內的通信,而不直接連到Internet上,理論上 使用任意的IP地址都可以,但是RFC 1918規定了用于組建局域網的私有IP地址。
- 10.*,前8位是網絡號,共16,777,216個地址
- 172.16.到172.31.,前12位是網絡號,共1,048,576個地址
- 192.168.*,前16位是網絡號,共65,536個地址
包含在這個范圍中的, 都成為私有IP, 其余的則稱為全局IP(或公網IP);
意思就是私網IP地址是無法直接連上Internet的。 而我們最常見使用的最多的192.168.x.x,就是私網IP地址!
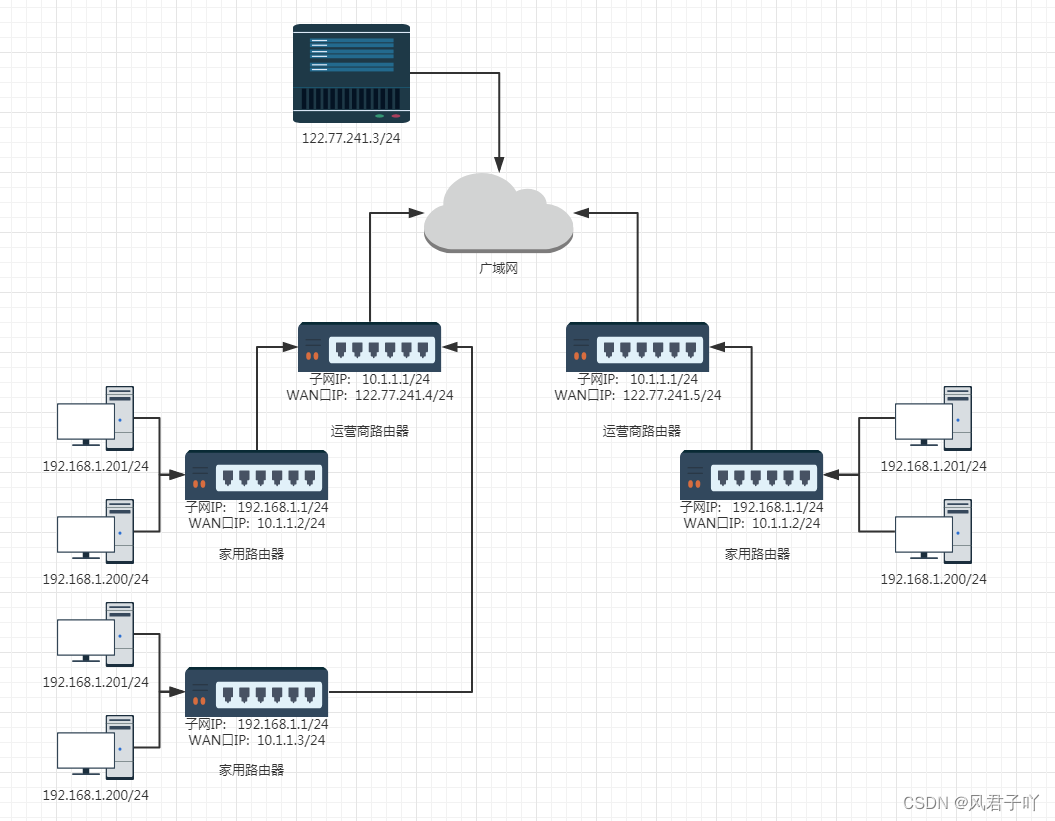
且我們這些私網IP地址,在不同的局域網子網之下,是可以重復的!這也大大提高了IP地址的利用率。
那我們這些私網無法直接連入公網,我們是怎么訪問別人服務器資源的呢? 答案是通過運營商!
運營商
我們雖然經常會吐槽運營商這不好那不好,但是實際上運營商對于我國的互聯網發展是起到了十分重要的作用的。
因為想要維護我國這樣如此龐大的網絡,是需要許多網絡服務器的,這些服務器成本是十分巨大的,而且想要讓家家戶戶都連上你的網絡,需要不少的時間。 所以沒有企業能夠負擔,這就需要國企來承擔這一責任,于是就有了我們國內的運營商! 是這些運營商在我們需要聯網裝路由器的時候來派基層人員來給我們安裝寬帶、網絡,當然這也是要收費的。
我們的數據先通過自家路由器,然后通過調制調節器(光貓)將數字信號轉化為光纖信號到運營商的路由器,再由運營商的路由器連接到公網上,再將報文從公網上一步一步轉發給目標主機。
這個轉發的過程,我們稱為路由。
路由
路由這里需要涉及到網絡層和數據鏈路層,我們先來講講網絡層上是怎樣運作的。
要將報文數據進行轉發,首先要判斷這個報文數據的目的主機是不是在報文當前所在主機所連接的子網內,這是通過路由表來判斷的。
路由表
需要注意的是,路由表可不僅僅只是在路由器才有的,我們的電腦、手機、云服務器上也有路由表。
在Linux的命令行中輸入 route
可以查看當前主機的路由表

-
Destination是目標網絡地址,一般是這臺主機所連接的子網網絡地址,可以看到有個default,這是默認路由地址,我們等會會講。
-
Gateway是下一跳地址。 Iface是發送接口,因為我的這個服務器只處于一個路由器的內網當中,所以也就只有一個發送接口。
-
Genmask就是子網掩碼。
-
Flags中的U標志表示此條目有效(可以禁用某些 條目),G標志表示此條目的下一跳地址是某個路由器的地址,沒有G標志的條目表示目的網絡地址是與本機接口直接相連的網絡,不必經路由器轉發。
假設有一個目標IP為42.1.1.1的報文數據到了我這臺主機,我首先要判斷它的目標IP地址是不是處于我的這個子網內,判斷方法就是將 (目標IP地址 & 子網掩碼) == Destination

(42.1.1.1 & 255.255.252.0 = 42.1.0.0) != 10.0.4.0
所以這個報文就不是發給網絡號為10.0.4.0的子網,接著就繼續找這臺主機連接的另一個子網是否匹配。
如果沒有找遍了路由表還是沒找到,這個時候default 默認路由地址就有作用了,default一般代表該網段的另一臺主機,它就會走default路線將這個報文通過eth0這個接口發給另外一臺主機,另外一臺主機再重復上面的這個操作,從一個路由器跳到另一臺相連的路由器,這就會越來越接近目標IP主機。
又需要注意的是,路由表只是用來判斷該報文目標IP是否處在當前主機所連接的子網,至于下面跳轉路由器的過程,涉及到MAC幀,MAC幀我們緊接著會講!

重復若干上面查找路由表的操作和跳路由器的動作之后,當這個報文終于找到了目標IP所在的網段,又應該怎樣進行下一步呢?而且這個跳的過程又是怎樣進行的呢?
這就又需要涉及到數據鏈路層和MAC幀。
數據鏈路層
所謂的數據鏈路層,也就是我們的網卡驅動,物理層,之前我們最初學習網絡基礎的時候也微微提到過。 MAC地址是用于在局域網中通信的,當上面的那個千里迢迢才找到目標IP所在的子網的報文數據,最后到達了這個子網后,就是需要在局域網中轉發這個數據!
局域網間主機的通信就是靠MAC地址來查找目標主機的。
MAC幀格式
我們以以太網為例,數據鏈路層不同協議的MAC幀格式都差不多。
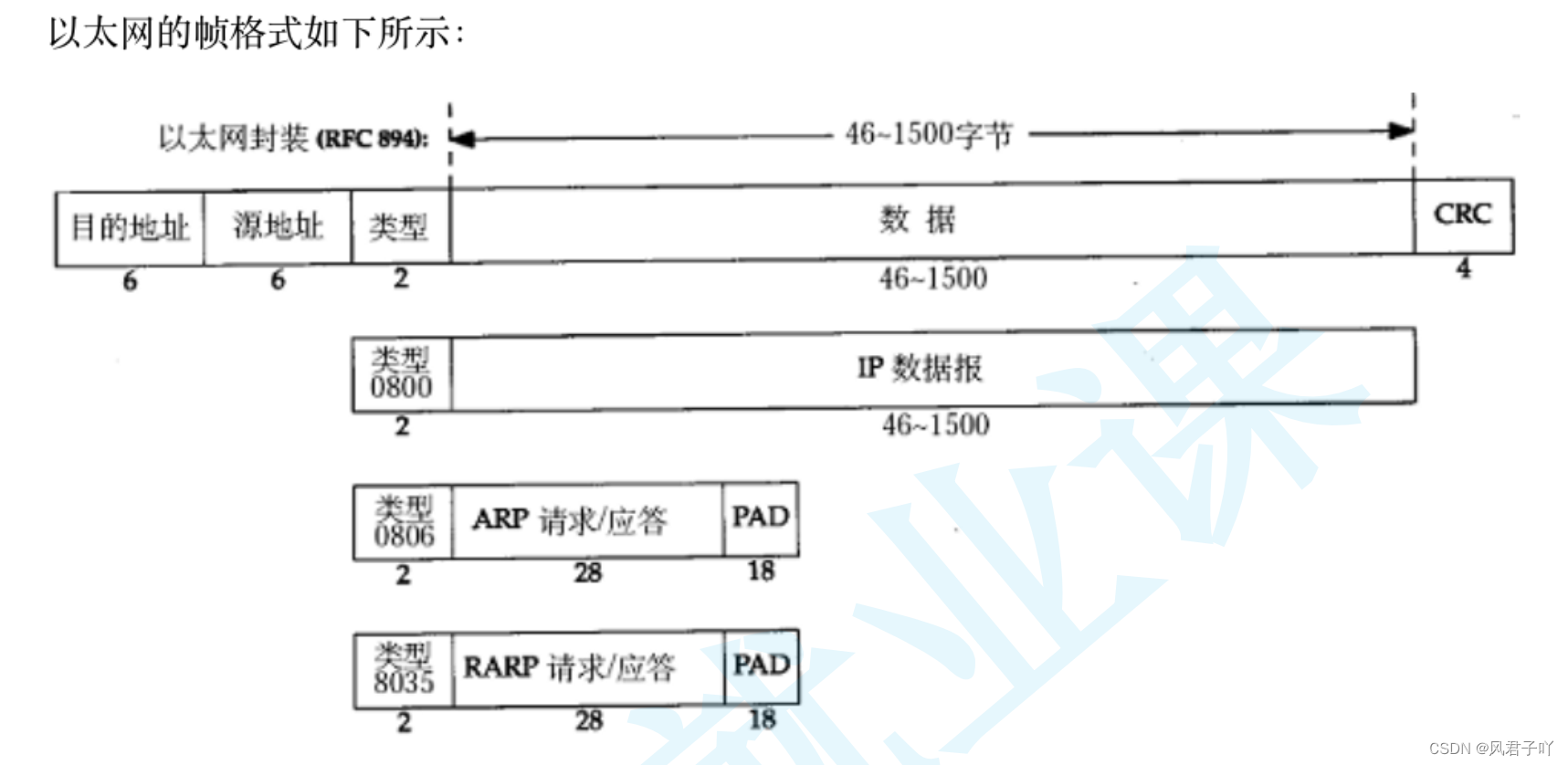
- 6字節目的地址就是 目標主機的MAC地址。
- 6字節源地址就是 發送主機的MAC地址。
- 2字節類型就是分辨該報文MAC幀報文數據類型,有可能會是攜帶了IP數據報頭的數據,也有可能是APR請求/應答、也有可能是RARP請求/應答。
對于ARP和RARP我們等會還會詳細講解。 - CRC是CRC校驗碼,用于保證數據幀的完整性。
局域網通信原理
當局域網的一臺主機想向另一臺處在同一局域網的主機發送數據,首先要從應用層不斷將數據向下經過傳輸層,網絡層,數據鏈路層的封裝,其中在數據鏈路層會封裝MAC幀報頭。然后經過數據鏈路層的網卡設備向局域網發送報文數據,這個報文數據是會被所有處于局域網的主機都接收的,不過所有主機的鏈路層會根據MAC幀報頭中的目的MAC地址來判斷是否是發給它的報文數據,如果不是則丟棄。 是的話則一路經由網絡協議棧向上交付解包。
局域網數據碰撞
原則上,局域網同一時間只能同時存在一個報文數據,如果同一時間存在多個報文數據,則會造成數據碰撞,導致數據出現問題,最后數據會被所有主機舍棄,為了減少數據碰撞,就需要設計防碰撞算法來盡量減少數據碰撞的發生概率。
不過光靠防碰撞算法也是不夠的,在一臺子網連接的主機數量達到一定程度時,數據碰撞還是會經常發生,例如說學校的校園網,當其他宿舍同學去上課時,你的網絡就很好,他們下課時就會很卡,這不僅僅是網絡帶寬的問題,也有可能是同一子網內連接的主機太多發生了數據碰撞。
還有一種設備——交換機,也能減少數據碰撞的發生概率,叫交換機可以分割碰撞域,可以將過多的主機的局域網分割開來。
MTU
MTU(Maximum Transmission Unit)是不同的數據鏈路對應的物理層所能發到局域網中最大的有效載荷長度, 報文長度 = MAC幀報頭長度 + 有效載荷/IP數據報長度(不能超過MTU)
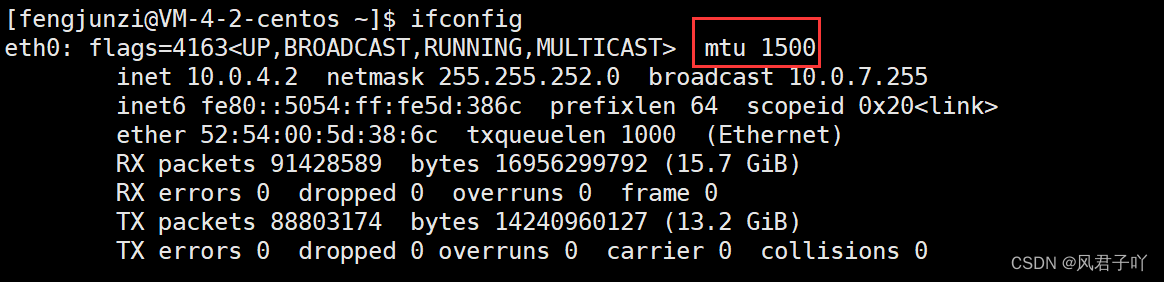
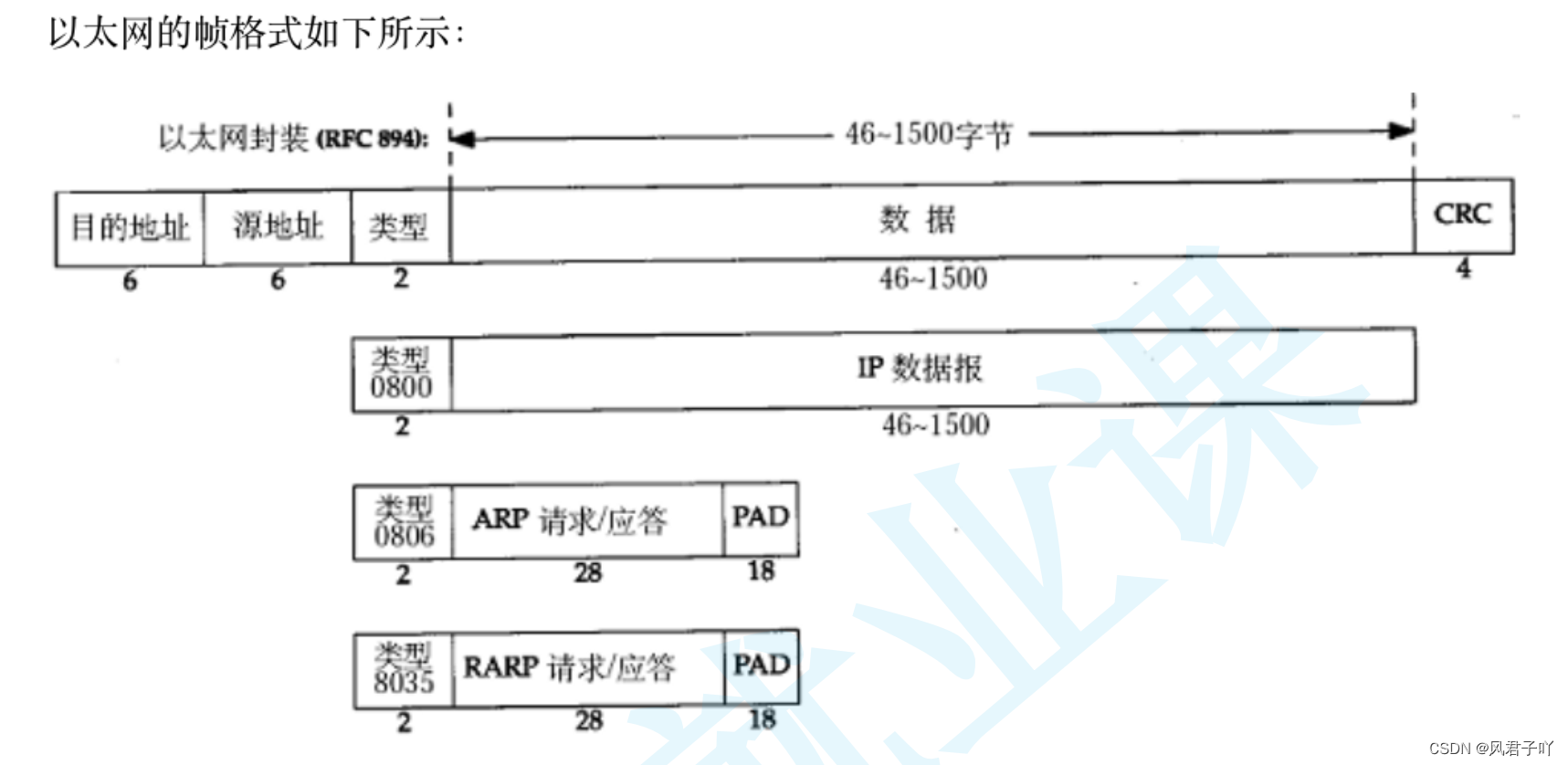
- 以太網幀中的數據長度規定最小46字節,最大1500字節,ARP數據包的長度不夠46字節,要在后面補填充位;
- 最大值1500稱為以太網的最大傳輸單元(MTU),不同的網絡類型有不同的MTU;
- 如果一個數據包從以太網路由到撥號鏈路上,數據包長度大于撥號鏈路的MTU了,則需要對數據包進行分片(fragmentation);
- 不同的數據鏈路層標準的MTU是不同的;
分片(網絡層IP協議)
以以太網為例,
因為我們的數據鏈路層以太網幀中的數據長度最多只能攜帶1500字節,那么網絡層給數據鏈路層傳的報文就不能超過1500字節,可是網絡層也是從傳輸層拿的數據,傳輸層像UDP協議他就是硬塞給網絡層一個特別長的報文數據,那么網絡層IP協議就要考慮到數據鏈路層的MTU,就必須要做到分片,將過長報文分成多個部分。
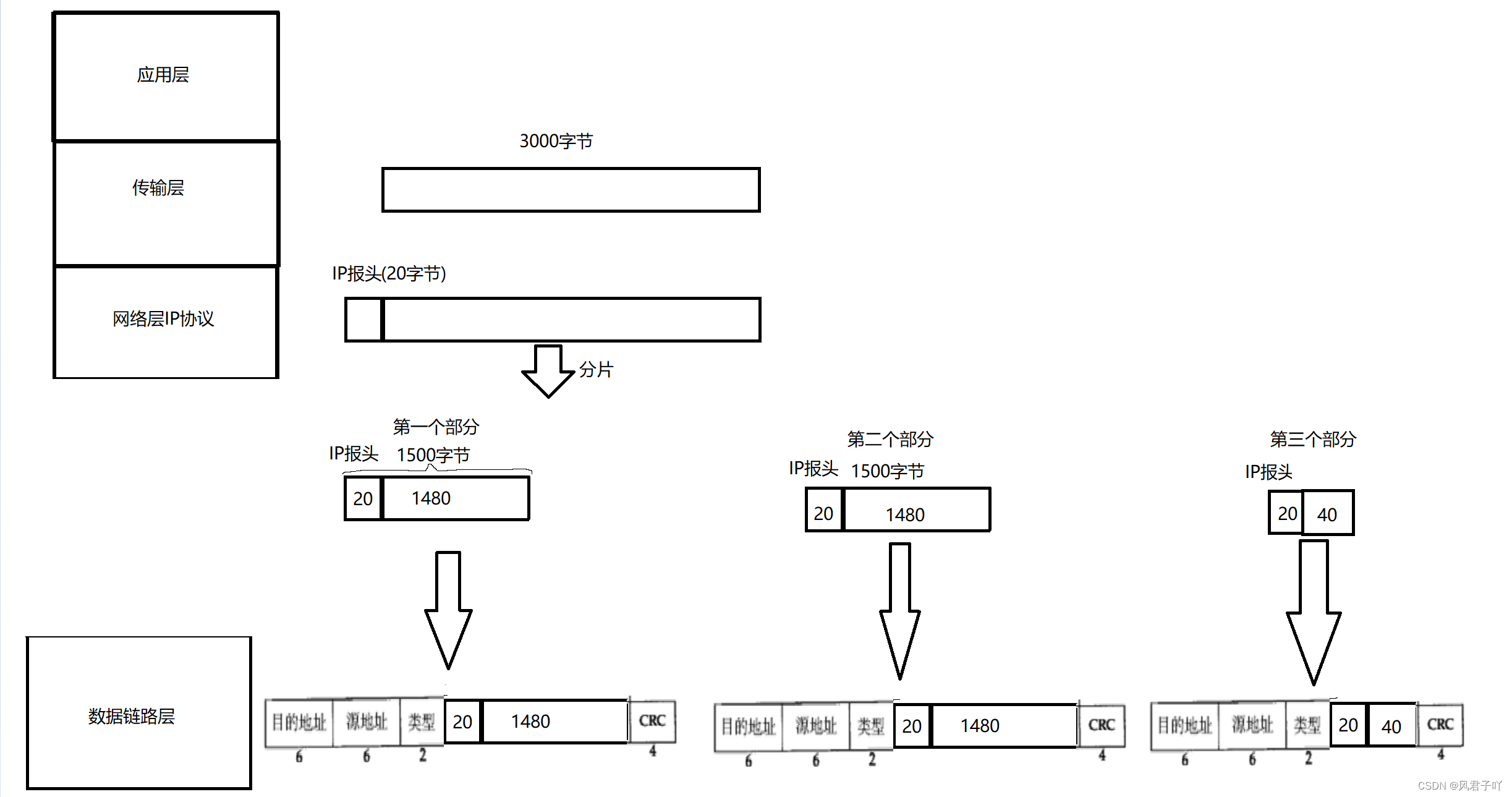
現在講了將過長的IP報文分片的過程,那么怎么將這些被分片的IP報文拼裝起來呢?
因為這些報文都攜帶了MAC幀,所以也就能找到目標主機,目標主機也需要在網絡層將這些分片的報文拼裝起來,但是這些拼裝的報文,誰是頭誰是尾,該如何分辨?
可別忘了我們我們的IP協議報頭還有一行沒講呢。

16位標識(id): 唯一的標識主機發送的報文。如果IP報文在數據鏈路層被分片了,那么每一個片里面的這個id都是相同的。
3位標志字段: 第一位保留(保留的意思是現在不用,但是還沒想好說不定以后要用到). 第二位置為1表示禁止分片, 這時候如果報文長度超過MTU, IP模塊就會丟棄報文。第三位表示"更多分片", 如果分片了的話,最后一個分片置為1, 其他是0。類似于一個結束標記。
所以根據標志字段的最后一位我們可以知道該分片報文是不是最后一個分片。
13位分片偏移(framegament offset): 是分片相對于原始IP報文開始處的偏移。其實就是在表示當前分片在原報文中處在哪個位置。
我們再以上面那個被分片的IP報文為例

雖然網絡層有了分片可以保證我們的數據鏈路層能夠發送MTU的數據,但是我們還是要避免分片,因為分太多片勢必也會提高局域網中數據碰撞的概率,造成的直接后果就是分片的數據丟失。就又需要數據鏈路層進行超時重傳,是的,數據鏈路層也有超時重傳機制。
但是IP層和數據鏈路層都沒有辦法控制報文數據有效載荷的大小,我們就只能依靠傳輸層來進一步約束它的報文數據長度。
再聯系TCP協議的滑動窗口,為什么我們的滑動窗口當時在寫的時候里面是一個部分一個部分,這就是因為它也要考慮到MTU,而滑動窗口里那一個部分一個部分的長度,我們稱之為MSS(Maximum Segment Size)最大報文長度。
如果說我們這里的數據鏈路層的物理層的MTU是1500,那么我們的MSS可以這樣計算 MSS = 1500 - IP報頭(20字節) = 1480
又由于我們通信的兩臺主機的MTU可能是不一樣的,所以我們在TCP協議的三次握手時也會同時互相發送各自的MSS長度(選項當中),再協商使用兩臺主機的最小MSS來制定雙方的滑動窗口的MSS。
可是,上面還有一個十分重要的部分我們沒講,那就是這個報文數據是如何在兩個主機之間“跳”的,這個報文數據到達了目標IP地址所在的入口路由器,我們又怎么從局域網中找到該目標主機?局域網是通過MAC地址來通信的,而我們的報文數據只有IP地址。
所以又有IP地址轉MAC地址,這種轉換方式又是基于ARP協議。
ARP協議
ARP不僅僅是一個數據鏈路層協議,它是位于以太網/令牌環協議之上,網絡層IP協議之下,是一個介于數據鏈路層和網絡層之間的協議;
ARP協議的作用
它建立了一個ARP協議建立了主機 IP地址 和 MAC地址 的映射關系。
所以,兩臺主機想要進行局域網通信,就首先要獲取一方的MAC地址,就需要先發送ARP報文。
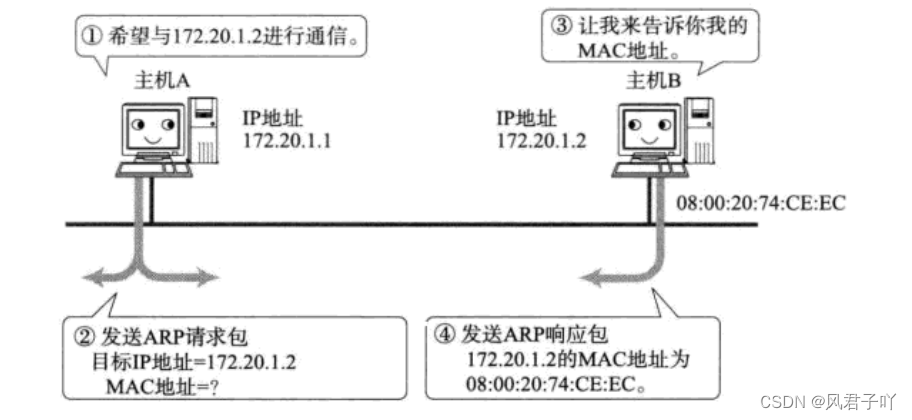
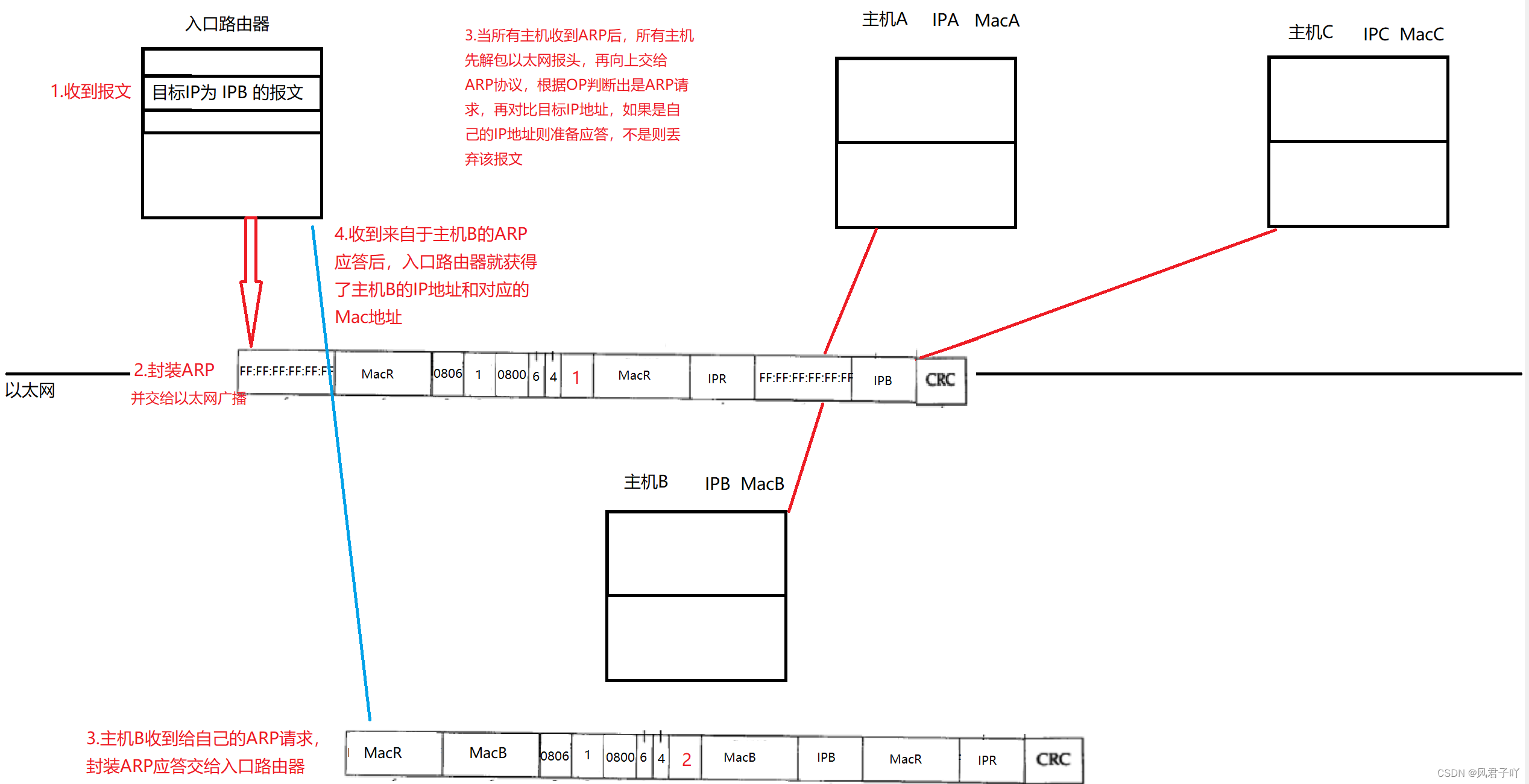
- 源主機發出ARP請求,詢問“IP地址是192.168.0.1的主機的硬件地址是多少”, 并將這個請求廣播到本地網段(以太網幀首部的目的以太網地址填FF:FF:FF:FF:FF:FF表示廣播);
- 目的主機接收到廣播的ARP請求,發現其中的IP地址與本機相符,則發送一個ARP應答數據包給源主機,將自己的硬件地址填寫在應答包中。 如果非目標主機收到這個廣播的ARP請求,則直接在ARP協議層解析并丟棄。
- 每臺主機都維護一個ARP緩存表,可以用arp -a命令查看。緩存表中的表項有過期時間(一般為20分鐘),如果20分鐘內沒有再次使用某個表項,則該表項失效,下次還要發ARP請求來獲得目的主機的硬件地址
ARP數據報的格式

以太網首部我們就不再重復了,需要注意的是以太網首部的幀類型會因為封裝的數據是ARP數據,這里的幀類型是0806。
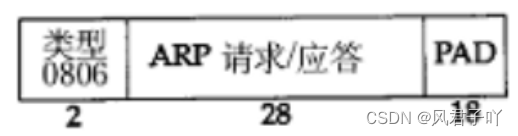
- 硬件類型指鏈路層網絡類型,1為以太網。
- 協議類型指你的網絡層協議地址類型,0x0800為IP地址。
- 硬件地址長度對于以太網地址為6字節。
- 協議地址長度對于和IP地址為4字節。
- op比較重要,用于分辨是ARP請求還是應答。請求為1,應答為2。
- 剩下的發送端以太網地址、發送端IP地址、目的以太網地址、目的IP地址無需多談。
環境模擬
現在我們來模擬一下ARP請求應答的環境來讓我們更好的認識ARP請求與應答的過程。
RARP請求/應答
RARP與ARP相反,ARP是用IP地址來找詢問對應主機的MAC地址,RARP是通過MAC地址來詢問對應主機的IP地址。 這里對RARP不做細講。
DNS(Domain Name System)
域名解析系統
例如我們輸入www.baidu,com 或者baidu.com的時候,其實本質也是通過訪問IP地址的方式來訪問百度服務器的資源,但是這里如何將域名轉化為IP地址,就需要訪問DNS系統,將域名交給DNS服務器,再由DNS服務器給我們返回對應的IP地址。
如果本地由對應的DNS緩存就不必訪問訪問DNS系統了。
ICMP協議
ICMP協議是一個 網絡層協議。 ICMP是位于IP協議之下,網絡層之內的一個協議。
一個新搭建好的網絡, 往往需要先進行一個簡單的測試, 來驗證網絡是否暢通; 但是IP協議并不提供可靠傳輸. 如果丟包了, IP協議并不能通知傳輸層是否丟包以及丟包的原因。
ICMP正是提供這種功能的協議,ICMP主要功能包括:
- 確認IP包是否成功到達目標地址。
- 通知在發送過程中IP包被丟棄的原因。
- ICMP也是基于IP協議工作的. 但是它并不是傳輸層的功能, 因此人們仍然把它歸結為網絡層協議。
- ICMP只能搭配IPv4使用. 如果是IPv6的情況下, 需要是用ICMPv6。
例如我們的ping命令
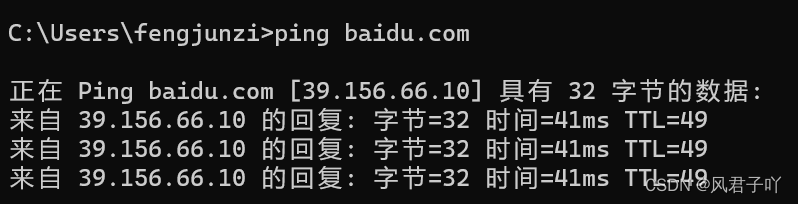
ping命令基于ICMP, 是在網絡層. 而端口號, 是傳輸層的內容. 在ICMP中根本就不關注端口號這樣的信息。
所以以后面試問到ping是什么端口不要掉坑里去了。
traceroute命令
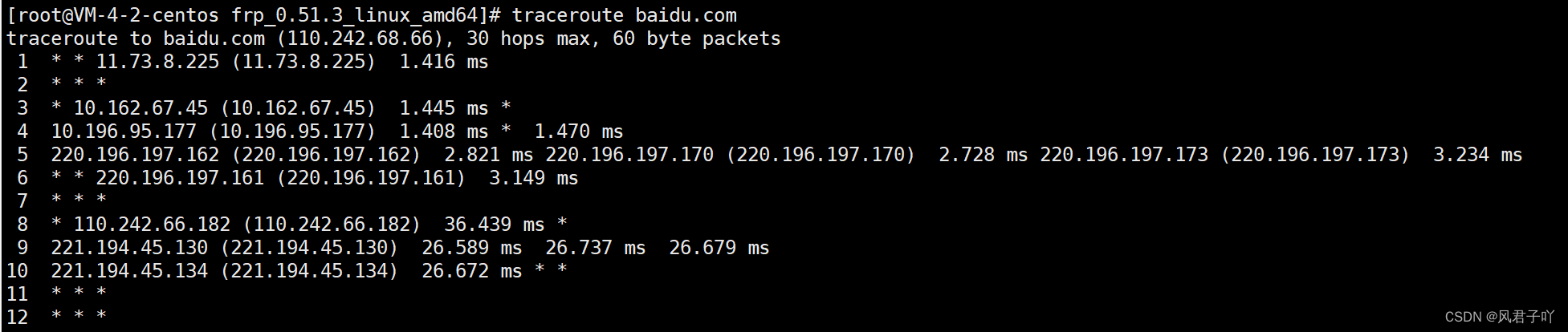
traceroute命令也是基于ICMP協議,它其實就是通過改變IP報頭中的TTL來追蹤我們訪問一個目標IP所需要經過的路由地址。 因為我們的路由在因TTL為0時丟棄報文的同時也會給我們返回一個ICMP報文回來。
NAT技術
以上的內容,我們都清楚的講解了一個處于內網中的主機向一個處于公網中的服務器發送數據請求的整個過程。 可是,既然收到了一個請求,我們的公網服務器就需要作出對應的應答,我們的公網服務器又如何做到回去找到處于內網的主機呢?
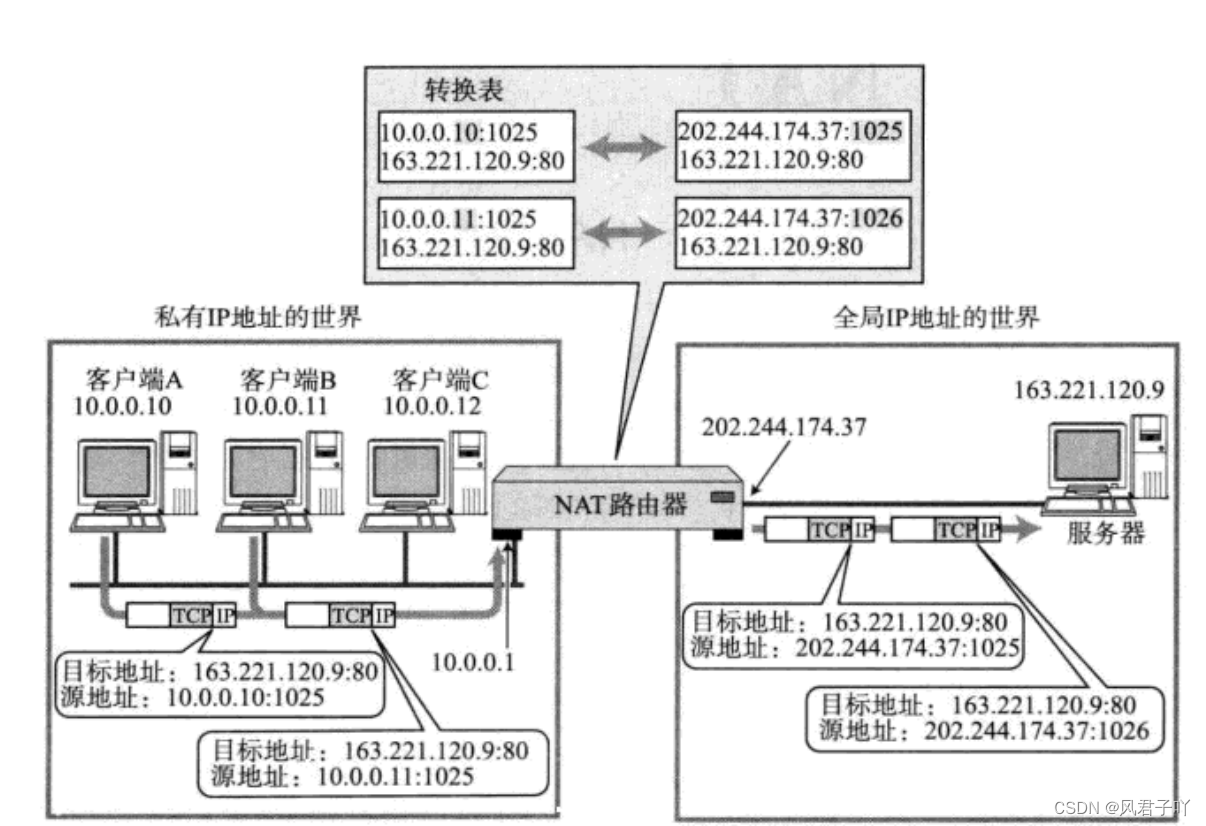
在內網向公網發出的數據每經過一個仍處于內網的子網的路由器時,這個路由器都需要有對應的NAT轉換表,并在這個轉換表插入對應的私網IP地址端口號的映射,并將IP報頭中的源內網IP地址換成新的WAN口IP地址。TCP/UDP報頭中的源端口號換成新的不與其他轉換表中重復的端口號。
所以當公網的應答回到該路由器時,它會查找NAT轉換表,并通過轉換表將IP報頭的目標IP地址和TCP/UDP報頭的目標端口號重新換成轉換表中對應的內網IP地址和端口號。 這樣就實現了公網的應答傳到內網中。
像我國的網絡環境,我們家里一個家用路由器,然后家用路由器還要連接到運營商的路由器,而且這個運營商的路由器還不一定直接是連到公網,可能還得又經過一個運營商路由器。 所以我們用電腦向公網發起請求,這個請求報文是會有多個NAT轉換表的映射的,會有多個替換源IP和端口號的過程。
通過NAT技術,可以有效緩解目前IP地址不足的問題。
NAT技術的缺陷
由于NAT依賴這個轉換表, 所以有諸多限制:
無法從NAT外部向內部服務器建立連接;
轉換表的生成和銷毀都需要額外開銷;
通信過程中一旦NAT設備異常, 即使存在熱備, 所有的TCP連接也都會斷開;




半決賽(華中賽區)Pwn題解)







)






—— 實時AI換臉項目)