在 AI 技術從“實驗性”走向“企業級落地”的關鍵階段,數據工程作為底層支撐的重要性愈發凸顯。近日,DZone 發布的《2025 數據工程趨勢報告》(Scaling Intelligence with the Modern Data Stack)通過對全球 123 位 IT 專業人士的調研,揭示了當前數據工程領域的核心趨勢、技術選型偏好與實踐痛點。本文將梳理報告的核心發現,并解讀其對數據工程師、架構師及技術管理者的實踐價值。

一、報告概覽:調研背景與核心基調
DZone 本次調研覆蓋了全球范圍內的開發者、架構師等 IT 從業者,樣本呈現三大特征:
- 角色集中:32%為“開發者/工程師”,10%為“開發團隊負責人”,核心受訪者均深度參與數據系統構建;
- 技術棧成熟:80%企業使用 Python 生態,50%從業者以 Python 為主要工作語言,Java(22%)位居第二;
- 經驗豐富:受訪者平均 IT 從業經驗達 14.65 年,中位數 13 年,反饋具備較強實踐參考性。
報告核心基調明確:企業數據能力正從“技術堆砌”轉向“整合優化”——不再盲目追逐新工具,而是聚焦成本控制、性能監控與流程編排,以適配 AI 原生架構、實時分析等新需求。
二、核心發現:數據工程的三大“轉向”
1. 存儲架構:從“混合分散”轉向“云原生主導”
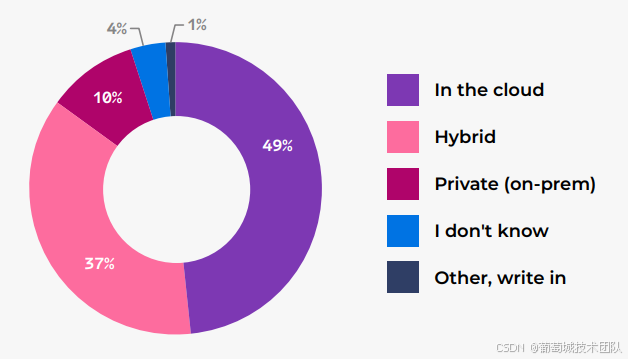
數據存儲是本次調研的重點領域,結果顯示“云原生”已成為不可逆趨勢:
- 云存儲占比大幅提升:49%企業主要采用“純云存儲”,較 2024 年的 30%增長 19 個百分點;而混合存儲(37%,-11%)、本地私有存儲(10%,-10%)占比顯著下降;
- 遷移動機務實化:“維持高可用性”(44%)、“降低成本”(39%)、“提升數據可訪問性”(34%)是云遷移的三大核心訴求,其中大企業更傾向通過云遷移實現“現代化改造”與“AI 分析支撐”;
- 存儲架構分層明顯:55%企業使用數據倉庫,47%使用數據湖,27%使用湖倉一體(Lakehouse);大企業(1000+員工)是“湖倉一體”的主要實踐者(38%),小企業(<100 人)因規模限制,數據倉庫使用率僅 37%(低于整體 55%)。
2. 數據安全:從“工具堆砌”轉向“體系化落地”
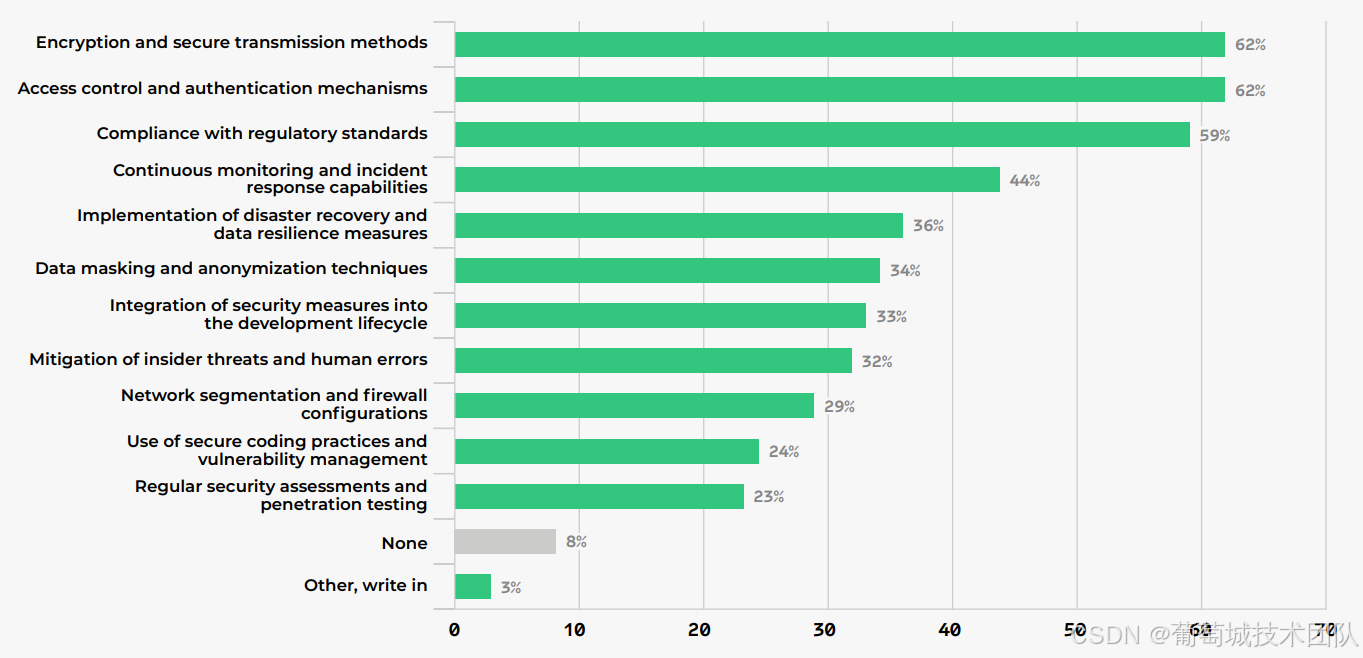
盡管數據安全的重要性達成共識,但實踐呈現“認知與落地脫節”的特點:
- 核心策略集中:62%企業依賴“加密與安全傳輸”“訪問控制與認證”,59%關注“合規性標準”,三者構成安全實踐的“鐵三角”;
- 實踐 Adoption 下降:與 2024 年相比,“災難恢復”(-22%)、“數據脫敏”(-21%)、“安全編碼”(-22%)等實踐的使用率顯著下滑,推測與“依賴云廠商默認安全能力”“成本壓縮”有關;
- 威脅感知聚焦:60%企業最擔憂“數據泄露”,50%關注“認證與訪問控制失效”,43%警惕“不安全數據處理”,中小企業對“弱加密”的擔憂更突出(40%,高于大企業 17%)。
3. 數據管道:從“批量離線”轉向“實時 AI 適配”
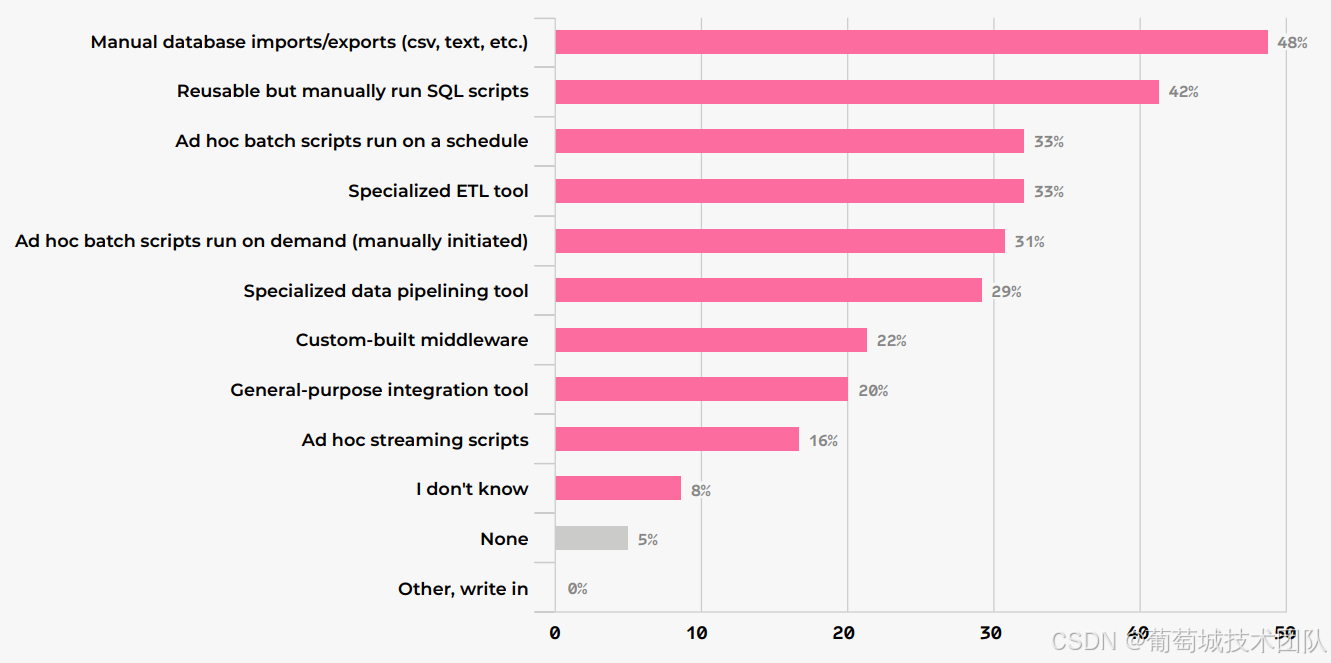
數據管道是支撐 AI 落地的核心環節,調研顯示其正在向“實時化、AI 原生”轉型:
- ETL 工作量高企:從業者平均 30%工作時間用于 ETL/ELT,大企業(35%)與小企業(33%)耗時更高,中型企業(20%)因流程成熟度居中;
- 工具選型分化:48%企業仍依賴“手動數據庫導入/導出”,33%使用“專業 ETL 工具”(較 2024 年下降 11%);大企業更偏好專業工具(40%),小企業則依賴“臨時批處理腳本”(43%);
- AI 數據準備待加強:僅 18%從業者“非常自信”于 AI/ML 數據準備最佳實踐,39%通過“API 實時供數”支撐生成式 AI,36%使用向量數據庫實現 RAG(檢索增強生成),但小企業的數據質量實踐覆蓋率顯著低于大企業。
三、專家洞見:來自行業一線的實踐指南
報告收錄了微軟、Netflix、Factorial 等企業專家的深度解讀,核心聚焦三大方向:
1. 數據架構的“融合與開放”:湖倉一體+開放表格式
Factorial 工程 VP Miguel Garcia Lorenzo 指出,傳統數據湖、倉庫的邊界正在消失,基于開放表格式(如 Apache Iceberg)的湖倉一體成為主流:
- Iceberg 憑借“引擎中立性”“隱藏分區”“元數據管理”優勢,成為多引擎(Trino、Flink、DuckDB)共享數據的統一層;
- 現代架構采用“多引擎策略”:DuckDB 用于嵌入式邊緣分析,Trino 用于跨源聯邦查詢,ClickHouse 用于實時 OLAP,實現“存儲與計算解耦”。
2. AI 原生架構的“底層重構”
微軟產品經理 Abhishek Gupta 強調,AI 原生架構與傳統架構存在本質差異(如下表),需從“數據類型、處理模式、存儲選型”全鏈路重構:
| 維度 | 傳統架構 | AI 原生架構 |
|---|---|---|
| 數據類型 | 結構化數據 | 文本、圖像等多模態數據 |
| 處理模式 | 批量 ETL | 實時流+批量混合 |
| 延遲要求 | 小時級-天級 | 毫秒級-秒級 |
| 存儲核心 | 數據倉庫(星型模型) | 數據湖+向量庫+特征庫 |
| 查詢模式 | SQL 分析 | 向量相似性搜索+傳統查詢 |
3. 實時系統的“DataOps 落地”
Netflix 高級工程師 Tulika Bhatt 分享了實時數據系統的 DataOps 實踐:
- schema 版本化:通過 Avro/Protobuf 定義 schema,結合 Apicurio Schema Registry 實現兼容性校驗;
- CI/CD 全自動化:將 Flink 作業、配置文件納入 Git 管理,通過 GitHub Actions 實現“構建-測試-灰度部署”;
- 可觀測性體系:聚焦 Kafka 消費延遲、Flink checkpoint 時長等核心指標,通過 Prometheus+Grafana 建立業務告警。
四、報告價值:為不同角色提供行動指南
1. 數據工程師:明確工具與技能優先級
- 工具選型:優先掌握 Python 生態、Apache Iceberg、Kafka/Pulsar 流處理,以及 Prometheus/Grafana 可觀測性工具;
- 技能升級:補充向量數據庫(Pinecone、Weaviate)、RAG 數據準備、DataOps 自動化等 AI 相關能力。
2. 架構師:把握技術選型的“平衡術”
- 存儲層:中小企業可從“云存儲+數據倉庫”起步,大企業推進“湖倉一體+開放表格式”;
- 安全層:避免“工具堆砌”,聚焦“加密+訪問控制+合規”核心,借力云廠商安全能力降低成本;
- 管道層:根據規模選擇“專業 ETL 工具(大企業)”或“腳本+輕量工具(中小企業)”,逐步推進自動化。
3. 技術管理者:平衡“創新與成本”
- 資源傾斜:向“實時數據管道”“AI 數據質量”等核心環節傾斜預算,優先解決“數據可用性”問題;
- 團隊協同:建立“數據工程師+數據科學家+ML 工程師”跨職能團隊,通過 Feature Store、數據目錄實現協作效率提升。
五、總結:數據工程的未來三大關鍵詞
- 云原生深化:純云存儲將持續替代混合/本地存儲,云廠商的“Serverless+托管服務”成為中小企業首選;
- AI 驅動重構:向量數據庫、實時流處理、開放表格式成為 AI 原生架構的“基礎設施”,數據工程與 AI 工程的邊界進一步模糊;
- DataOps 常態化:實時系統的“自動化部署、可觀測性、版本控制”將成為標配,推動數據工程從“手工運維”轉向“工程化交付”。
如需深入探索,可參考報告附錄的“解決方案目錄”——涵蓋 DataStax Astra DB(AI 原生 NoSQL)、Langflow(LLM 可視化構建)、Apache Kafka(流處理)等 100+工具的選型指南,為實踐落地提供直接參考。
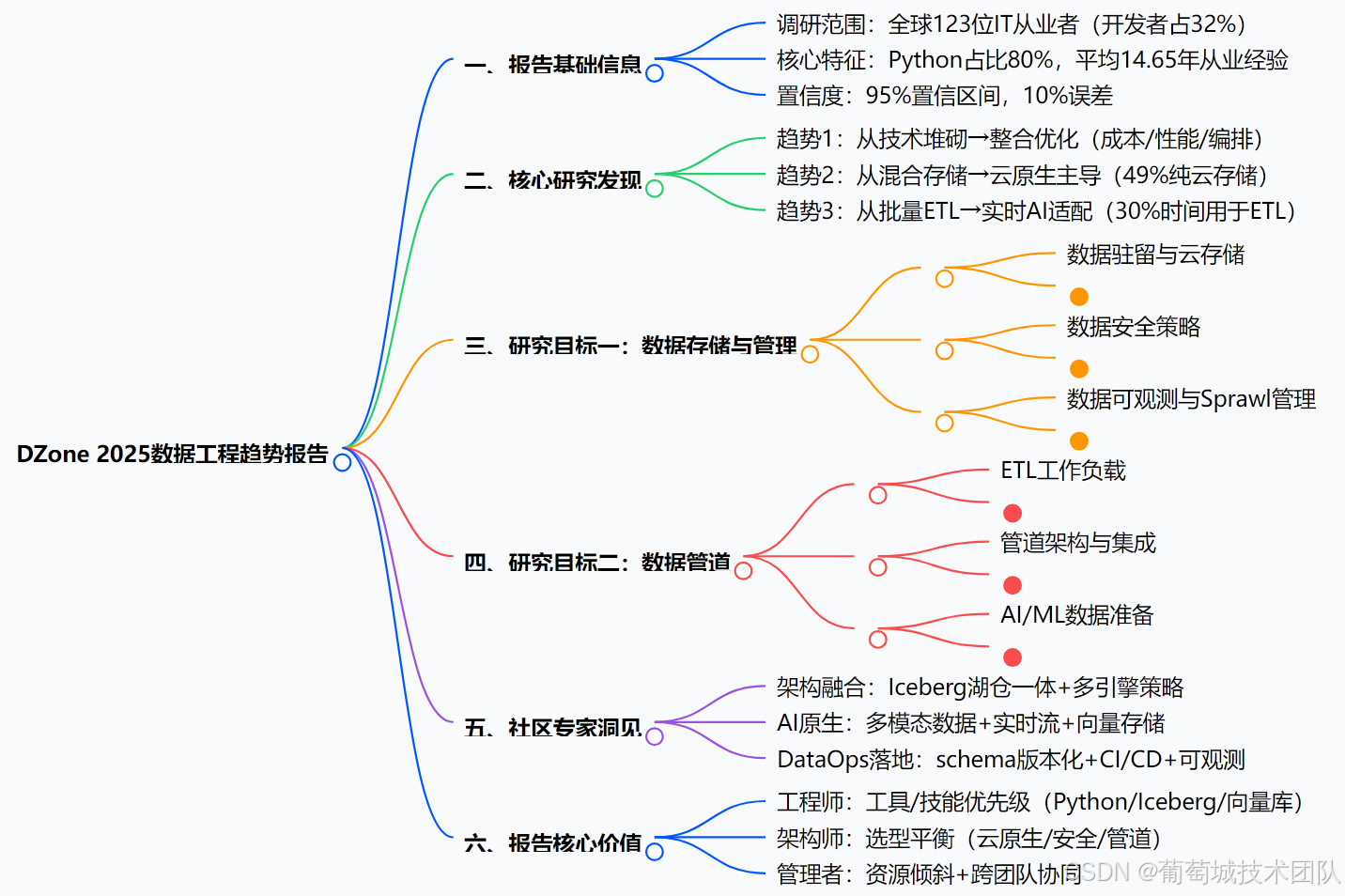
附:報告核心內容腦圖大綱
下載地址














)




