
本文字數:1684;估計閱讀時間:5分鐘
審校:莊曉東(魏莊)
本文在公眾號【ClickHouseInc】首發

介紹
在?ClickHouse,我們熱衷于基準測試和性能優化。所以當我第一次看到?Hacker News?上那篇“查詢大型 JSON 文件的最快工具是用 Python 編寫的”帖子時,我的第一個想法是——“但 clickhouse-local 不是用 Python 編寫的”。讓我們來看一下這個基準測試,證明 clickhouse-local 實際上是查詢大型 JSON 文件的最快工具。
clickhouse-local
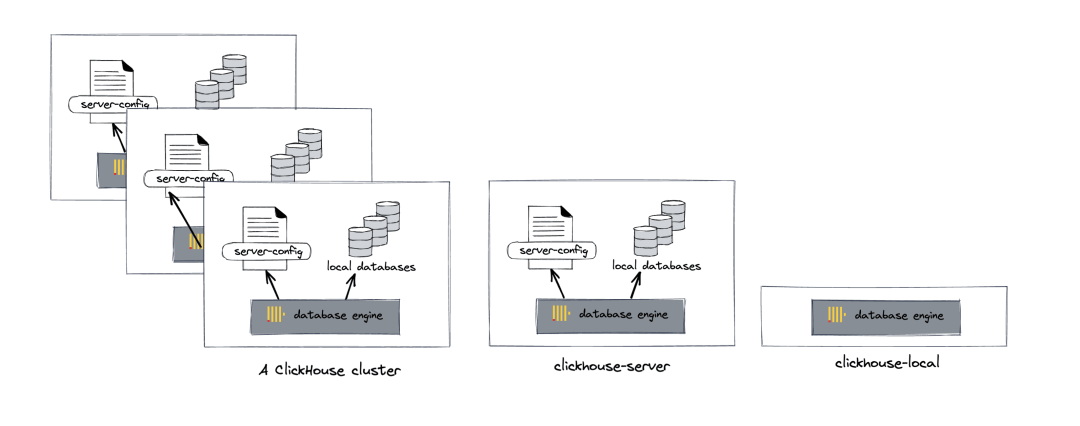
clickhouse-local 是一個單一的二進制文件,允許你使用 SQL 快速處理本地和遠程文件,提供了無數據庫的數據庫功能。除了支持 ClickHouse 的所有功能外,它還支持多種文件格式,包括 JSON。下面我們嘗試可視化 ClickHouse 集群、單個 ClickHouse 實例和 clickhouse-local 之間的區別:
性能基準測試
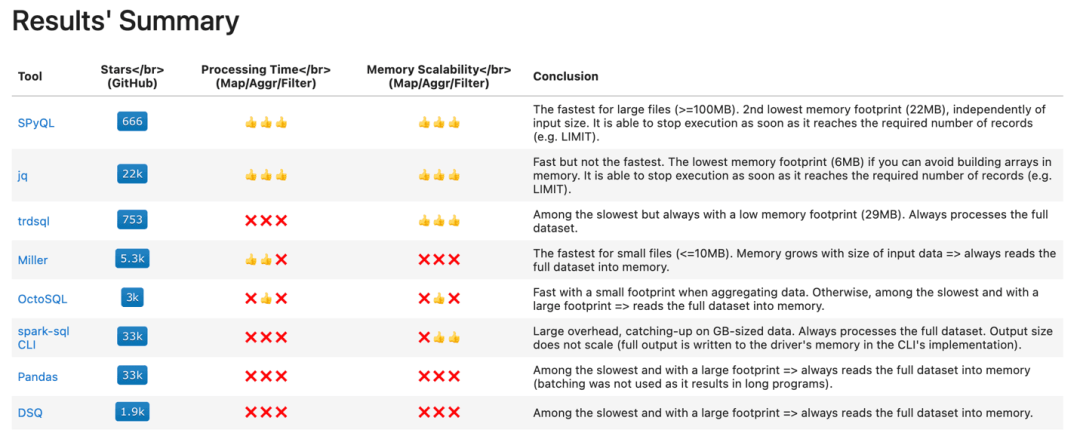
SPySQL 的創建者 Daniel Moura 發布了一項作為 SPySQL 項目一部分的基準測試。該基準測試比較了幾種命令行工具,重點是查詢可以存儲在標準機器磁盤上但可能無法完全放入內存的大文件。測試數據集使用了亞馬遜書評數據集的 10GB 子集。基準測試中使用的工具包括 SPySQL、jq、trdsql、Miller、OctoSQL、spark-sql、Pandas 和 DSQ。基準測試主要包含 3 個挑戰:
-
Map:
為所有行計算一個新列(批量輸入和輸出都很大)。
這代表了一種常見的 ETL 類任務,涉及數據清洗和豐富。
-
Aggregation/Reduce:
計算一列所有行的平均值(只有輸入很大)。
適用于需要快速分析結果且想避免將數據加載到如 ClickHouse 這樣的數據存儲中的用戶。
-
Subset/Filter:
返回符合過濾條件的列的前 100 個值(只需要處理部分輸入)。
此測試評估工具快速采樣文件的能力,代表用戶在迭代查詢前常執行的任務。
初步測試結果顯示 SPySQL 是查詢大型 JSON 文件的最快工具:
但 Daniel 并不知道 clickhouse-local。為此,ClickHouse 最近引入了兩個新功能,使處理 JSON 文件和復現此基準測試變得更加簡單:支持半結構化數據存儲和自動模式推斷。后者允許 ClickHouse 從數據中推斷列類型,因此用戶無需指定 JSON 文件的結構和每個字段的類型,從而簡化了語法并加速了入門體驗。
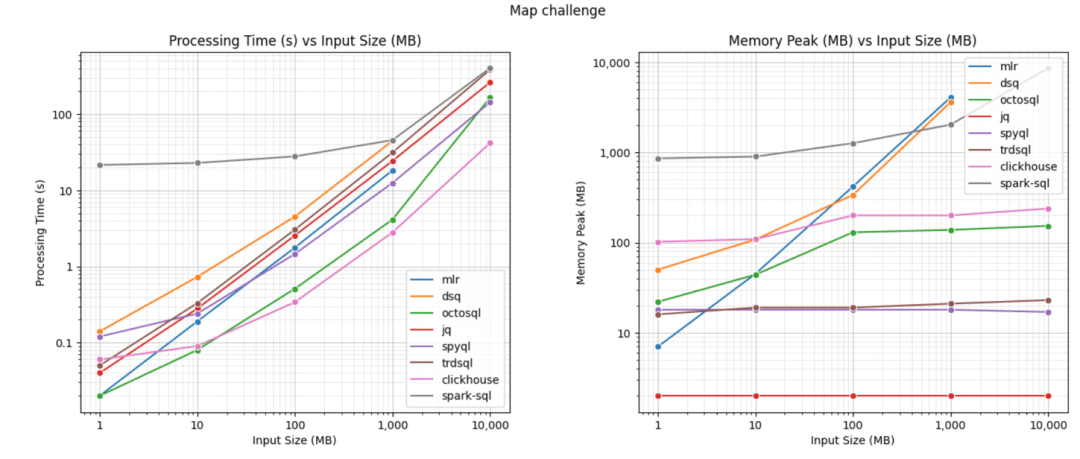
在聯系 Daniel 后,他迅速將 clickhouse-local 添加到他的基準測試中并更新了結果。令人驚訝的是,clickhouse-local 比之前的所有工具都快。OctoSQL 的一位開發人員(用 Go 編寫)也要求根據最新改進更新基準測試,并取得了不錯的結果。下圖展示了更新后的基準測試結果。
Map 測試
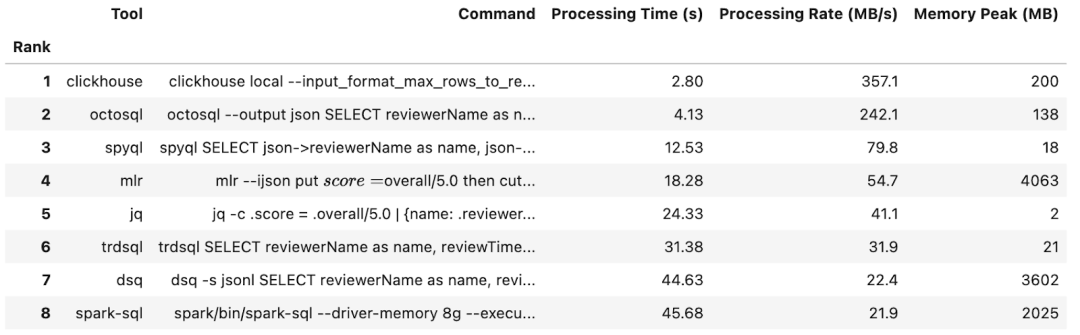
1GB 數據的測試結果
聚合(reduce)測試
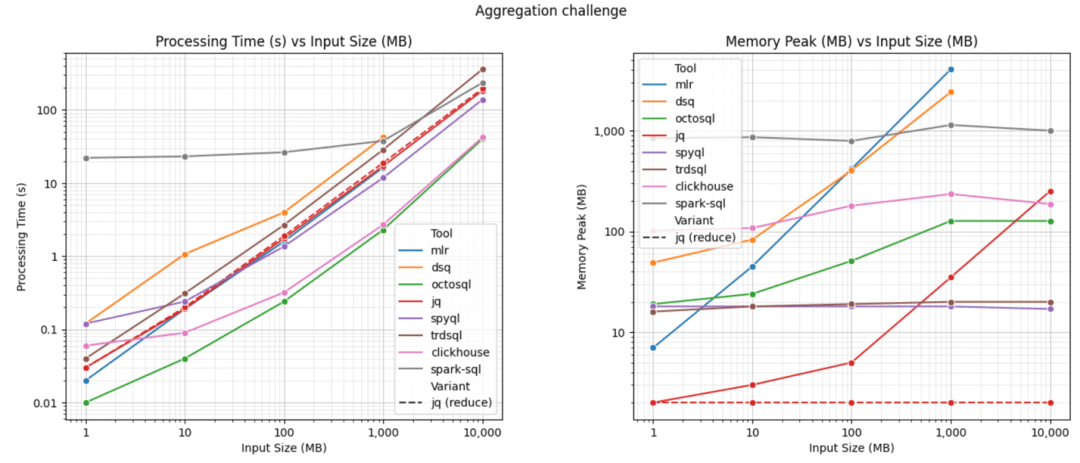
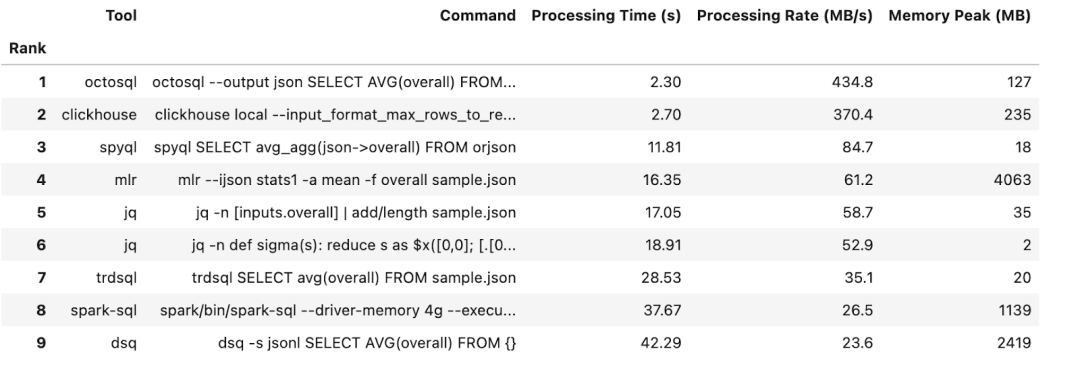
1GB 數據的測試結果
過濾(subset)測試
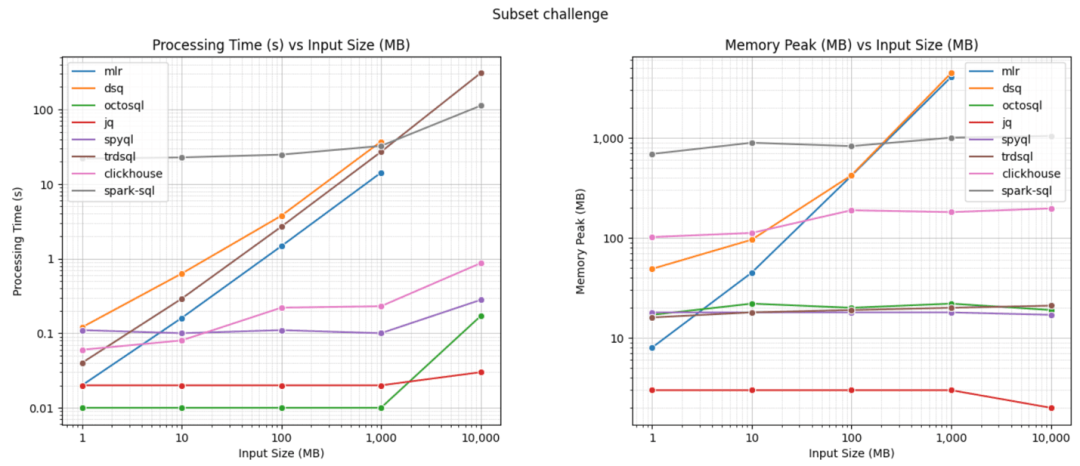
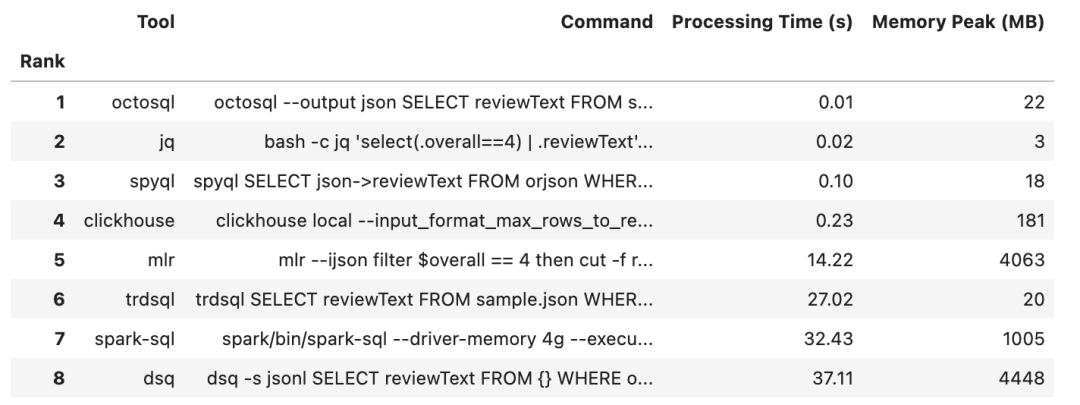
1GB 數據的測試結果
結果總結
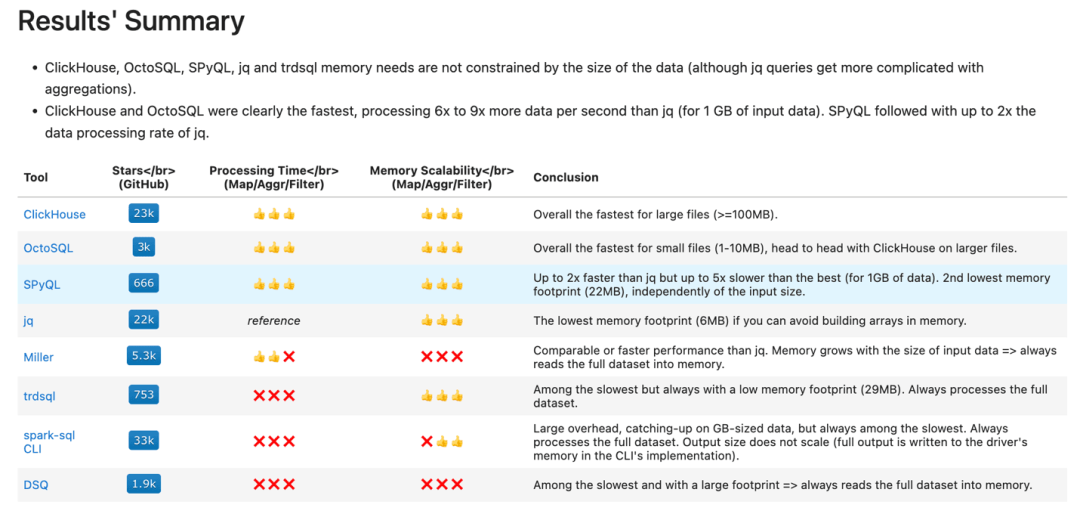
更新的結果已經發布在此。可以看到,clickhouse-local 在查詢大型 JSON 文件時速度遠超大多數其他工具,而 OctoSQL 在處理較小文件時表現優異。
這個基準測試并不完美。每個查詢只運行一次,因此可能會有波動,用戶在本地硬件上重現結果時可能會發現運行之間的明顯差異。結果也可能由于硬件和操作系統的差異而有所不同。最后,Daniel 在過濾查詢中故意沒有使用 ORDER BY 子句。雖然這可能導致不同工具之間的結果不同,因為 SQL 并不強制默認順序,但基準測試的目標是評估用戶希望盡快對文件進行采樣以及工具避免完全掃描的能力。這個測試對那些在滿足 LIMIT 后支持早期終止并且不需要將整個文件加載到內存中的工具有利。
所以,下次你需要處理大型 JSON 文件時,就知道該用哪個工具了!
征稿啟示
面向社區長期正文,文章內容包括但不限于關于 ClickHouse 的技術研究、項目實踐和創新做法等。建議行文風格干貨輸出&圖文并茂。質量合格的文章將會發布在本公眾號,優秀者也有機會推薦到 ClickHouse 官網。請將文章稿件的 WORD 版本發郵件至:Tracy.Wang@clickhouse.com

??聯系我們
手機號:13910395701
郵箱:Tracy.Wang@clickhouse.com
滿足您所有的在線分析列式數據庫管理需求
?









)




)



和APB2(高速)上的外設)
