原創文章第570篇,專注“AI量化投資、世界運行的規律、個人成長與財富自由"。
研報復現繼續:【研報復現】年化27.1%,人工智能多因子大類資產配置策略之benchmark
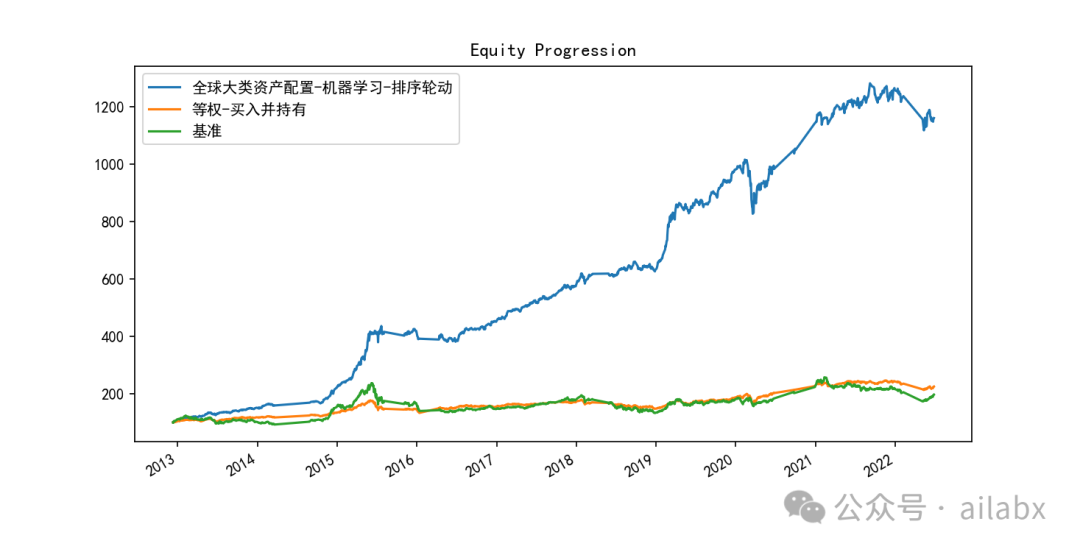
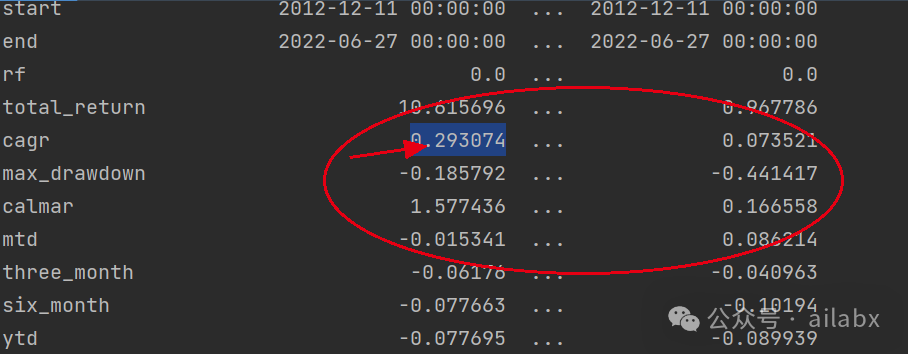
昨天調了一版參數,主要是lambda_l1, lambda_l2,防止過擬合的,有明顯的效果:年化29.3%,最大回撤18.5%,還有繼續優化的空間。
def train(df_train, df_val, feature_cols, label_col='label'):model = LGBMRegressor(boosting='gbdt', # gbdt \ dartn_estimators=600, # 迭代次數learning_rate=0.1, # 步長max_depth=10, # 樹的最大深度seed=42, # 指定隨機種子,為了復現結果num_leaves=250,# min_split_gain=0.01,lambda_l1=2,lambda_l2=2000)
目前使用的是GridCV網格參數搜索:
ef adj_params(X_train, y_train):"""模型調參"""params = {# 'n_estimators': [100, 200, 300, 400,500,600,700,800],# 'learning_rate': [0.01, 0.03, 0.05, 0.1],'max_depth': range(10, 64, 2),# 'lambda_l1': range(0,3),# 'lambda_l2':[200,400,800,1000,1200,1400,1600,2000]}other_params = {'learning_rate': 0.1, 'seed': 42, 'lambda_l1': 2, 'lambda_l2': 2000}model_adj = LGBMRegressor(**other_params)# sklearn提供的調參工具,訓練集k折交叉驗證(消除數據切分產生數據分布不均勻的影響)optimized_param = GridSearchCV(estimator=model_adj, param_grid=params, scoring='r2', cv=5, verbose=1)# 模型訓練optimized_param.fit(X_train, y_train)# 對應參數的k折交叉驗證平均得分means = optimized_param.cv_results_['mean_test_score']params = optimized_param.cv_results_['params']for mean, param in zip(means, params):print("mean_score: %f, params: %r" % (mean, param))# 最佳模型參數print('參數的最佳取值:{0}'.format(optimized_param.best_params_))# 最佳參數模型得分print('最佳模型得分:{0}'.format(optimized_param.best_score_))
后續考慮使用hyperopt以及gluon來調參:
ModelTrainer:基于AutoGluon的多因子合成AI量化通用流程
代碼與數據均在星球更新:
AI量化實驗室——2024量化投資的星辰大海
吾日三省吾身
昨天有同學留言說,現在這后半段有點雞湯了。
我向來反感和警惕雞湯,因此,我仔細反思了一下。
當下的大環境,大家越發渴望確定性,希望快速成功,賺錢,獲得安全感。
但如果想聽真話的話——這個世界沒有“速成”之說。
成功也沒有秘籍——沒有武俠小說里,那種猴子肚子里掏出一本書,然后幾天內達到別人30年的功力,然后年紀輕輕就獨步天下——沒有。
所謂心得,其實都是顯學。
理財——多多儲蓄,堅持長期投資,保持耐心。——沒有了。
無論你想不想慢慢變富,你都會慢慢變老。區別在于,你是又老且富,還是又老且窮。
你說有沒有財富自由快車道,——有,也是按3-7年往前看的。
有誰見過,花1000塊錢不到,買一個策略或系統,然后賺1000萬的?——誰這么跟你說,一定對你別有所圖。
美好的東西都是需要時間這個變量來孵化。
它可能很慢,尤其在前期,慢到很多人沒有耐心等到它發生。量化過程很慢,但越到后期才指數級復利加速。
如何度過這個孵化期——信念、系統。
種一棵樹,最好的時間是十年前,其次是現在。
歷史文章:
lightGBM全球大類資產多因子量化之重要因子篩選
【研報復現】年化27.1%,人工智能多因子大類資產配置策略之benchmark
AI量化實驗室——2024量化投資的星辰大海















target(SNAT、DNAT、MASQUERADE、REDIRECT))


)
