論文鏈接:Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
代碼鏈接:https://github.com/junjie18/CMT
作者:Junjie Yan, Yingfei Liu, Jianjian Sun, Fan Jia, Shuailin Li, Tiancai Wang, Xiangyu Zhang
發表單位:曠視科技
會議/期刊:ICCV2023
一、研究背景
多傳感器融合在自動駕駛系統中展示了其巨大優勢。不同的傳感器通常能提供互補的信息。例如,攝像頭以透視視角捕捉信息,圖像中包含豐富的語義特征,而點云則提供更多的定位和幾何信息。充分利用不同傳感器有助于減少不確定性,從而進行準確和魯棒的預測。
然而,由于不同模態的傳感器數據在分布上的巨大差異,融合這些多模態數據一直是個挑戰。當前的主流方法通常通過構建統一的鳥瞰圖(BEV)表示來進行多模態特征融合,或通過查詢令牌(Transformer架構)來實現多模態融合。
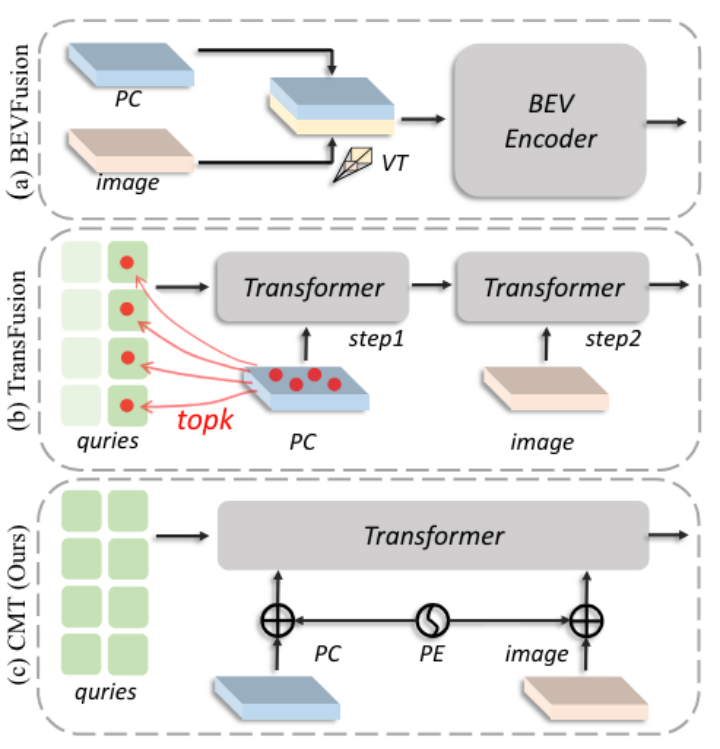
BEVFusion、TransFusion 和所提出的 CMT 之間的比較
上圖, (a) 在 BEVFusion 中,通過視圖變換將相機特征變換到 BEV 空間。兩個模態特征在BEV空間中級聯,并采用BEV編碼器進行融合。 “VT”是從圖像到3D空間的視圖變換。(b) TransFusion 首先從 LiDAR 特征的高響應區域生成查詢。之后,對象查詢分別與點云特征和圖像特征交互。 (c) 在 CMT 中,對象查詢直接同時與多模態特征交互。將位置編碼(PE)添加到多模態特征中以進行對齊。
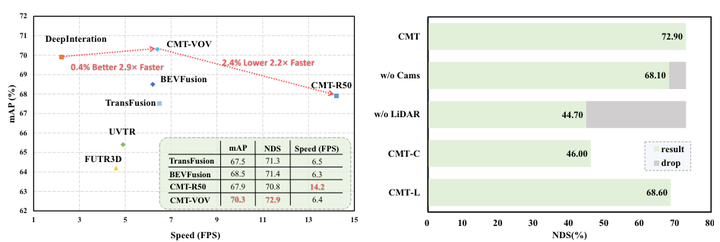
性能對比以及傳感器缺失情況性能評估
左:CMT 與現有方法之間的性能比較。所有速度統計數據均使用官方存儲庫的最佳模型在單個 Tesla A100 GPU 上測量。 (所有方法都使用spconv repo中相同的Voxelization模塊。此外,BevFusion的TranFusion head也配備了CMT repo中相同的FlashAttn。CMT和BEVFusion都沒有采用預計算)。
右:傳感器缺失情況下 CMT 的性能評估。在推理過程中,CMT 在 LiDAR 缺失的情況下實現了基于視覺的性能,表現出很強的魯棒性。
本文受 DETR 的啟發,目標是為 3D 對象檢測中的多模態融合構建一個優雅的端到端管道。
在 DETR 中,對象查詢通過 Transformer 解碼器中的交叉注意力直接與圖像標記交互。對于 3D 對象檢測,一種直觀的方法是將圖像和點云標記連接在一起,以便與對象查詢進一步交互。然而,連接的標記是無序的并且不知道它們在 3D 空間中的相應位置。因此,有必要為多模態標記和對象查詢提供位置先驗。
在本文,提出了 Cross-Modal Transformer (CMT),這是一種簡單但有效的端到端管道,用于魯棒3D 對象檢測。
首先,提出了坐標編碼模塊(CEM),它通過將 3D 點集隱式編碼為多模態標記來生成位置感知特征。具體來說,對于相機圖像,從視錐體空間采樣的 3D 點用于指示每個像素的 3D 位置的概率。而對于 LiDAR,BEV 坐標只是簡單地編碼到點云標記中。接下來,使用位置引導查詢。每個查詢都按照 PETR初始化為 3D 參考點。將參考點的 3D 坐標變換到圖像和 LiDAR 空間,以在每個空間中執行相對坐標編碼。
與現有方法相比,所提出的 CMT 框架具有許多優點。
首先,該方法是一個簡單的端到端管道,可以輕松擴展。 3D 位置被隱式編碼到多模態特征中,這避免了引入顯式跨視圖特征對齊引起的偏差。
其次,方法僅包含基本操作,沒有對多模態特征進行特征采樣或復雜的 2D 到 3D 視圖轉換。它實現了最先進的性能,并且與現有方法相比顯示出明顯的優越性。
第三,CMT的魯棒性比其他現有方法強得多。極端的是,在 LiDAR 未命中的情況下,與那些基于視覺的 3D 物體檢測器相比,僅使用圖像標記的 CMT 可以實現相似的性能。
本文貢獻:
(1)提出了一種快速且強大的3D 檢測器,這是一個真正的端到端框架,無需任何后處理。它克服了傳感器丟失的問題。
(2)3D 位置被編碼到多模式標記中,無需任何復雜的操作,例如網格采樣和體素池化(cue了BEVFusion)。
(3)CMT 在nuScenes 數據集上實現了最先進的3D 檢測性能。它為未來的研究提供了一個簡單的基線。
二、整體框架

Cross-Modal Transformer (CMT) 范例的架構
多視圖圖像和點云被輸入到兩個骨干網絡以提取特征tokens。在坐標編碼模塊中,相機光線和BEV位置的坐標(3D 坐標)分別轉換為圖像位置編碼(Im PE)和點云位置編碼(PC PE)。查詢由位置引導查詢生成器生成。在查詢生成器中,3D 錨點被投影到不同的模態,并且相對坐標被編碼(參見右側部分)。多模態tokens進一步與轉換器解碼器中的查詢交互。更新后的查詢進一步用于預測 3D 邊界框。整個框架以完全端到端的方式學習,LiDAR 主干從頭開始訓練,無需預訓練。
(1)特征提取:從多視角圖像和LiDAR點云中提取特征。
(2)位置編碼:使用CEM對圖像和點云特征進行位置編碼,生成位置嵌入。
(3)初始化查詢:
-
使用PQG在3D空間中初始化錨點,并通過CEM對這些錨點進行位置編碼。
-
將位置嵌入與查詢內容嵌入相結合,生成初始位置引導查詢。
(4)查詢更新:在跨模態Transformer解碼器中,位置引導查詢與多模態特征進行交互和更新,最終生成3D目標檢測結果。
三、核心方法
3.1 Coordinates Encoding Module
CEM的主要目的是通過將3D點的位置信息編碼到多模態令牌(圖像和LiDAR)中,提供具有位置感知的特征。這種編碼使模型能夠隱式理解3D空間中的空間關系,這對于準確的3D目標檢測至關重要。
假設P(u,v)是不同模態特征圖F(u,v)的3D點集,這里的(u,v)表示特征圖中的坐標。具體來說,F是相機的圖像特征或者LiDAR的BEV特征。假設CEM的輸出位置嵌入為Γ?(u,v),其計算公式為:
其中 𝜑 是多層感知 (MLP) 層。
CE for Images:對于攝像頭圖像,編碼涉及從攝像頭的截錐體空間中采樣3D點,因此圖像中的每個像素可以看作在3D空間中表示一條線(極線)。對于每個圖像,從相機視錐體空間中的一組點進行編碼以執行坐標編碼,對于給定的圖像特征F im,每個像素都可以表示為相機平截頭體坐標中的一系列點:
其中,u和v代表像素坐標,d是沿深度軸采樣的點的數量。
特別說明這里的dk是怎么得到的,類似LSS中的方法:
(1)預定義的深度范圍:通常,攝像頭的視錐體會有一個預定義的深度范圍,比如從最小深度(通常接近0)到最大深度(通常是攝像頭的遠裁剪面距離)。
(2)均勻采樣:在這個預定義的深度范圍內,均勻采樣dk個點。這些點可以是等間距的,也可以按照特定的策略(如對數分布)進行采樣,以便更好地捕捉近距離或遠距離的細節。例如,如果預定義的深度范圍是從0.1米到100米,可以均勻地在這個范圍內采樣d個點。
(3)深度值集合:得到的d個深度值{d1,d2,...,dk,...,d}}就代表了沿深度軸采樣的點。這些點用于生成相機平截頭體坐標中的點集。
采樣后得到的點通過相機內外參變化矩陣進行變化,最終投影到3D空間:
其中, 是從第i個相機坐標到LiDAR坐標的變換矩陣,
是第i個相機的內在矩陣。也就是說,這些點通過T從攝像頭坐標系變到LiDAR坐標系,然后由攝像頭內參矩陣K變到LiDAR空間。
圖像中每個像素的位置信息編碼計算為:
一樣是用MLP進行位置編碼。
CE for Point Clouds:使用VoxelNet或PointPillar作為主干網絡編碼點云Tokens,稱為F pc。點集沿Z軸(高度)采樣。假設(u,v)是BEV特征圖的坐標,那么采樣得到的點集是:
其中,hk代表第k個點的高度,h0=0是默認值。BEV特征圖對應的3D點就可以通過下面公式計算:
其中,(ud,vd)是每個BEV特征網格的大小,為了簡化,只沿高度軸采樣一個點,相當于BEV空間中的2D坐標編碼。那么點云的position embedding(位置信息編碼)可以計算:
3.2 Position-guided Query Generator
首先,位置引導的查詢生成器根據Anchor-DETR和PETR的方法,初始化一組錨點。這些錨點是從均勻分布中采樣的n個點,表示為:
其中,每個錨點的坐標在[0, 1]范圍內均勻分布。
接下來,這些錨點通過線性變換映射到3D世界空間中,具體公式如下:
其中,[xmin?,ymin?,zmin?,xmax?,ymax?,zmax?]是3D世界空間的感興趣區域(RoI)。
3D世界空間的感興趣區域(Region of Interest, RoI)是預定義的一個空間范圍,用于在該范圍內進行3D目標檢測。這個RoI的確定通常基于具體的應用場景和傳感器的覆蓋范圍。RoI通常通過一組邊界坐標來定義,通常是一個長方體或立方體,包含了目標可能出現的所有區域。定義RoI的邊界坐標通常包括最小和最大值。
這些坐標分別表示RoI在X、Y、Z三個軸上的最小和最大范圍。例如:
-
xmin? 和 xmax? 表示RoI在X軸(通常是車輛前后方向)的范圍。
-
ymin? 和 ymax? 表示RoI在Y軸(通常是車輛左右方向)的范圍。
-
zmin? 和 ?zmax? 表示RoI在Z軸(通常是高度方向)的范圍。
這種定義確保了RoI覆蓋了車輛周圍的所有重要區域,從而能夠有效地檢測和處理這些區域內的目標。
在將錨點轉換到3D世界空間后,這些錨點被投影到不同的模態(如圖像和平面視圖)中,并通過坐標編碼模塊(CEM)編碼對應的點集。這樣可以生成對象查詢的位置信息嵌入Γq可以通過以下方式生成:
其中,Apc和Aim分別是投影到BEV平面和圖像平面的點集,位置嵌入Γq進一步與查詢內容嵌入相加,以生成初始位置引導查詢Q0。
3.3 Decoder and Loss
對于解碼器,遵循 DETR 中原始的 Transformer 解碼器并使用解碼器L層。
每個解碼器層,位置引導查詢與多模式令牌交互并更新其表示。兩個前饋網絡 (FFN) 用于使用更新的查詢來預測 3D 邊界框和類別。將每個解碼器層的預測過程表述如下:
其中Ψreg和Ψcls分別表示回歸和分類的FFN。Qi是第i解碼器層的更新的對象查詢。
對于集合預測,二分匹配應用于預測和真實值之間的一對一分配。采用Focal Loss進行分類,采用L1 損失進行 3D 邊界框回歸:
w1和w2是平衡兩個損失項的超參數。對于查詢去噪中的正查詢和負查詢,損失的計算方式相同。
3.4 Masked-Modal Training for Robustness
安全性是自動駕駛系統最重要的問題。理想的系統需要可靠的性能,即使其中一部分失敗,并且不依賴于任何特定模式的輸入。BEVFusion 探索了 LiDAR 傳感器故障的魯棒性。然而,探索僅限于有限的掃描范圍,并且模型需要重新訓練。在本文中,嘗試了更多的極端故障,包括單攝像頭缺失、攝像頭缺失和激光雷達缺失,如下圖所示。與實際場景一致,保證了自動駕駛的安全。
為了提高模型的魯棒性,提出了一種訓練策略,稱為masked-模態訓練。在訓練過程中,隨機使用單一模態進行訓練,例如相機或激光雷達,其比例為x1和x2。該策略確保模型經過單模態和多模態的充分訓練。然后可以使用單模態或多模態測試模型,而無需修改模型權重。實驗結果表明,掩模模態訓練不會影響融合模型的性能。即使LiDAR損壞,與基于SoTA視覺的3D探測器相比,它仍然可以實現相似的性能。
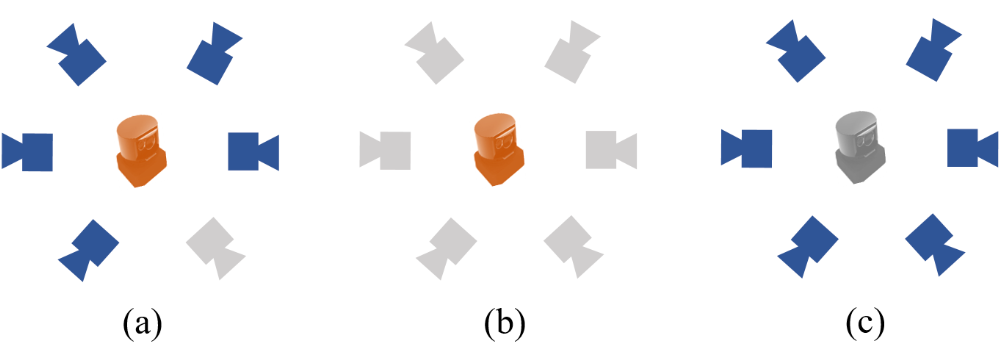
圖 4:在測試期間分析了 CMT 在三種模擬傳感器誤差下的系統魯棒性:(a) 單攝像頭未命中、(b) 所有攝像頭未命中和 (c) LiDAR 未命中。
CMT 在端到端建模方面與 FUTR3D 有著相似的動機。然而,兩者的方法和效果卻完全不同。 FUTR3D 重復采樣每個模態的相應特征,然后執行跨模態融合。 CMT對多視點圖像和點云都進行位置編碼,簡單地添加相應的模態標記,消除了重復的投影和采樣過程。它在原有的DETR框架中保留了更多端到端的精神。此外,與 FUTR3D 相比,CMT 取得了更好的性能,顯示出其卓越的有效性。可以認為 CMT 為多模態目標檢測提供了更好的端到端解決方案。
四、實驗結果
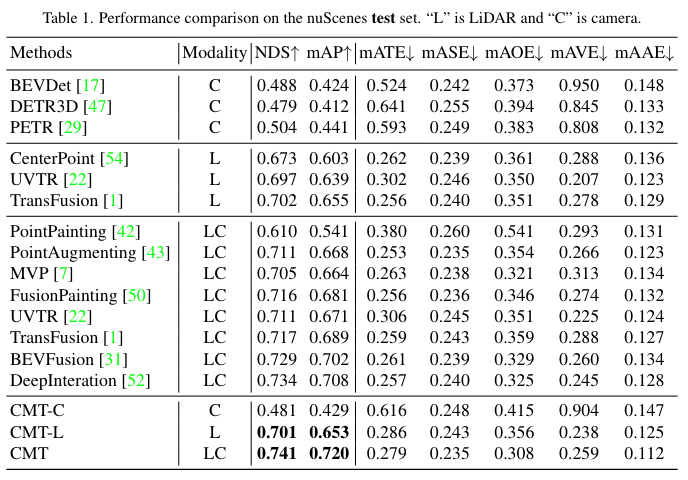
nuScenes 測試集上的性能比較
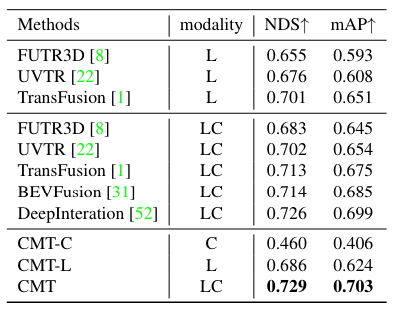
nuScenes 驗證集的性能比較

使用 LiDAR 或相機未命中的 nuScenes val 的定量結果。通過掩模模態訓練, CMT 的效率和魯棒性得到了顯著提高,特別是在缺少 LiDAR 或相機的情況下。
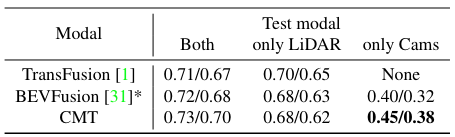
nuScenes val 與傳感器缺失的 NDS/mAP 比較。 BEVFusion 使用掩模模態策略進行訓練。 * 表示作者復現的結果。
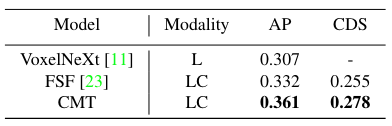
Argoverse2 驗證集上的 CDS/AP 比較。 “L”是激光雷達,“C”是相機。CDS和NDS有點相似,但是只考慮了平均平移誤差、平均尺度誤差和平均角度誤差。

CDS的公式

nuScenes 測試集中周圍視圖和 BEV 空間的一些定性檢測結果。不同顏色的邊界框代表車輛、行人、公共汽車和卡車。

多視圖圖像上注意力圖的可視化。藍點是初始錨點,而紅點是框預測的中心。它表明注意力圖的高響應區域主要集中在靠近錨點的前景物體上。
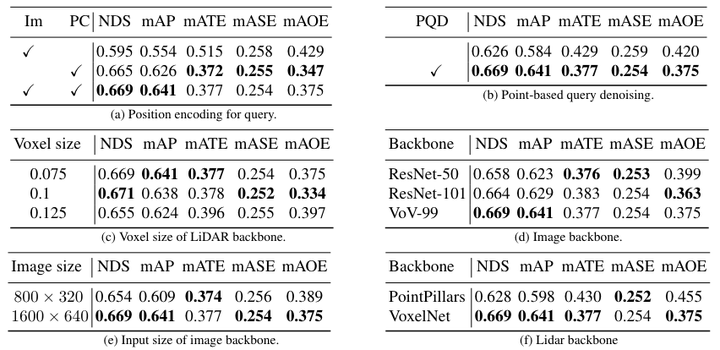
CMT 中不同組件的消融研究



)












大學生數學建模挑戰賽 | 園區微電網風光儲協調優化配置 | 數學建模完整代碼解析)


