前段時間,KAN突然爆火,成為可以替代MLP的一種全新神經網絡架構,200個參數頂30萬參數;而且,GPT-4o的生成速度也是驚艷了一眾大模型愛好者。
大家開始意識到——
大模型的計算效率很重要,提升大模型的tokens生成速度是很關鍵的一環。
而提升大模型的tokens生成速度,除了花錢升級GPU外,更長效的做法是改善Transformer模型架構的計算效率。
今天,筆者發現,終于有團隊對Transformer計算最耗時的核心組件——多頭注意力模塊(MHA)下手了,將Transformer的計算性能提升了有2倍之高。
通俗的講,如果這項工作未來能落地到大模型里面,那么大模型tokens生成速度翻倍式提升的一天就不遠了。

這篇論文已經被今年的機器學習頂會ICML 2024錄用,拿到了7分的高分,而且還開源了。
據透露,今年ICML 2024錄用的paper平均得分在4.25-6.33之間
筆者扒了下,發現這個工作的背后是一家頗具影響力的國內公司——彩云科技,沒錯,就是打造爆火的“彩云小夢”產品的團隊。

不急,先看看這篇論文,如何將Transformer模型計算效率暴漲100%的。
論文標題:
Improving Transformers with Dynamically Composable Multi-Head Attention
論文鏈接:
https://arxiv.org/abs/2405.08553
開源項目地址:
https://github.com/Caiyun-AI/DCFormer
Github上已開源這項工作的代碼、模型和訓練數據集。
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
我們知道,承載Transformer計算量的核心模塊便是多頭注意力(MHA)模塊,位置(position=i)上的每一個注意力頭(attention head)會與全部位置上的注意力頭計算出一個注意力分布矩陣。在這個過程中,位置 i 上的各個注意力頭計算出來的注意力分布矩陣是相互獨立的。
忘了的小伙伴請自行扒拉Transformer論文
論文指出,這種多頭獨立計算的機制會帶來兩大問題:
-
低秩瓶頸(Low-rank Bottleneck): 注意力矩陣的秩較低,模型的表達能力受限
-
頭冗余(Head Redundancy): 不同的注意力頭可能會學習到相似的模式,導致冗余
因此,彩云科技提出了一種叫動態可組合多頭注意力(DCMHA)的機制,DCMHA 通過一個核心的組合函數(Compose function),以輸入依賴的方式轉換注意力得分和權重矩陣,從而動態地組合注意力頭,解決了傳統MHA模塊中存在的上述低秩瓶頸和頭冗余問題。
值得強調的是,DCMHA旨在提高模型的表達能力,同時保持參數和計算效率,它可以作為任何Transformer架構中MHA模塊的即插即用替代品,以獲得相應的DCFormer模型。
論文通過實驗表明,DCFormer在不同的架構和模型規模下,在語言建模方面顯著優于Transformer,與計算量增加1.7倍至2倍的模型性能相匹配。例如,DCPythia-6.9B在預訓練困惑度和下游任務評估方面優于開源的Pythia-12B。
DCMHA原理
DCMHA機制的核心是引入的Compose函數。這個Compose函數可以視為一個可學習的參數,它可以動態地組合不同頭的QK矩陣和VO矩陣,內部通過一系列變換來分解和重構注意力向量。可以近似理解為:經過組合映射后,H個基礎的注意力頭可組合成多至H*H個注意力頭。
你可以簡單理解為,它能根據輸入數據調整頭之間的交互方式,一是打破頭的獨立性,二是可以根據輸入數據動態組合,從而可以增強模型的表達能力。
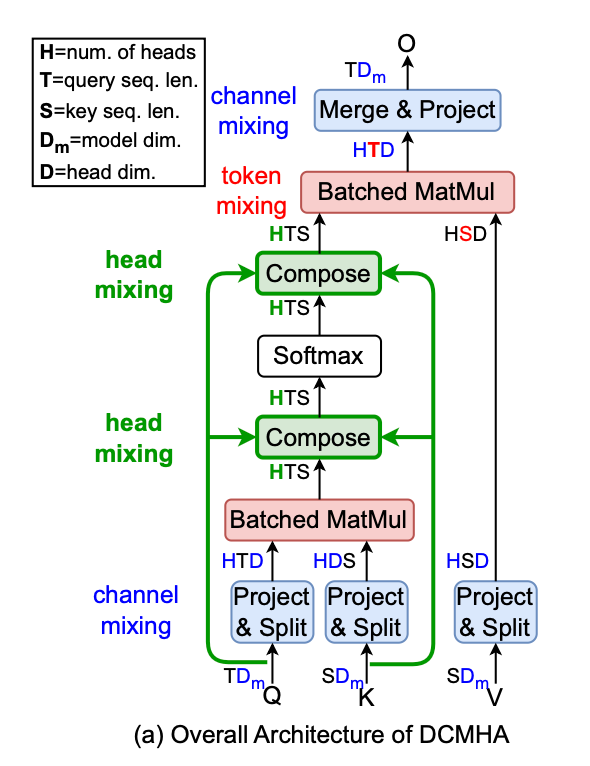
▲動態組合注意力頭機制
利用矩陣分解實現高效的參數計算
盡管引入了動態組合,DCMHA的設計依舊注重參數和計算效率。通過矩陣分解DCMHA能夠以較小的額外參數和計算開銷實現動態組合,同時保持模型性能。
DCFormer可提高70%~100%的模型計算效率
還有很重要的一點是,DCMHA可以作為MHA的直接替代品應用于任何Transformer架構中,升級成DCFormer,實現計算效率的大幅提升,達到1.7倍-2倍的計算效率。
而且,實驗結果表明在眾多NLP下游任務和圖像識別任務上的測評也驗證了DCFormer的有效性。
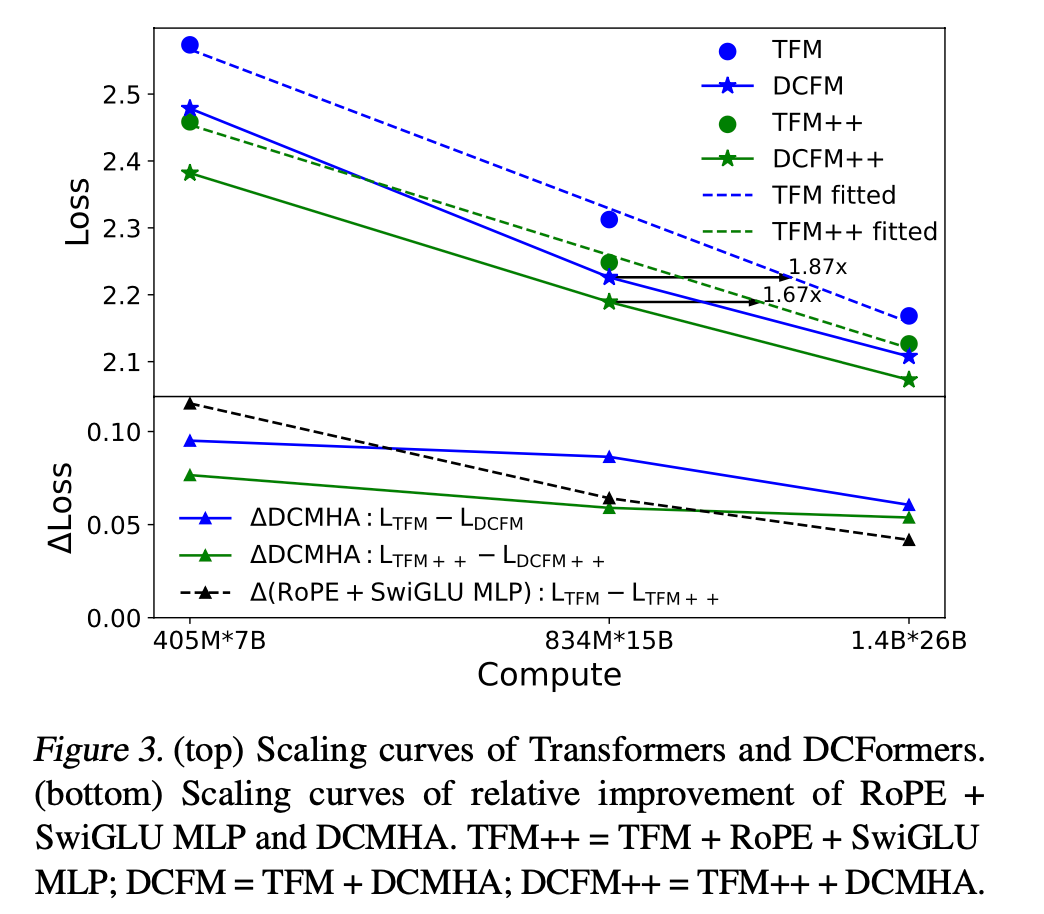
1、DCFormer在不同參數規模下(405M到6.9B參數),對 Transformer 和 Transformer++ 模型的性能提升顯著。
自2017年Transformer誕生至今,旋轉位置編碼RoPE和門控激活函數MLP被證明是最普世有效且廣泛采用的改進,已融入到Transformer++架構,同時也是大名鼎鼎的Llama模型框架。
而DCFormer性能算力比的提升幅度超過這兩項改進的提升幅度之和。
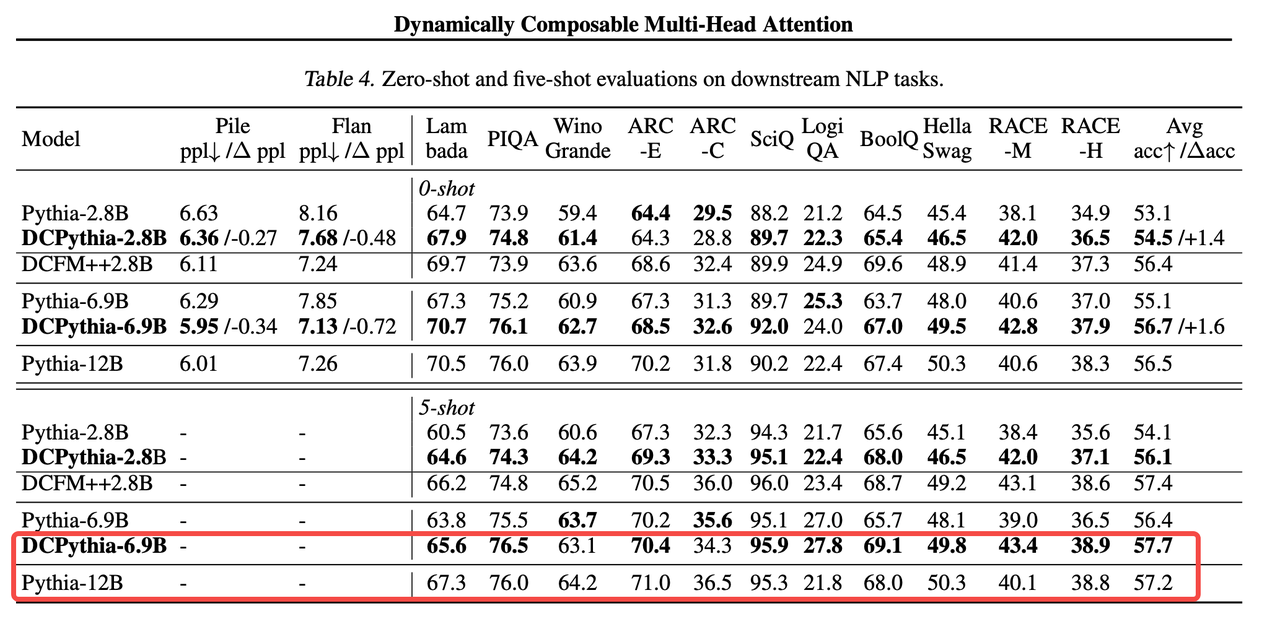
2、DCPythia-6.9B在多個下游任務中的表現優于Pythia-12B。
3、在ImageNet-1K數據集上的實驗驗證了DCMHA在非語言任務中也是有效性的。
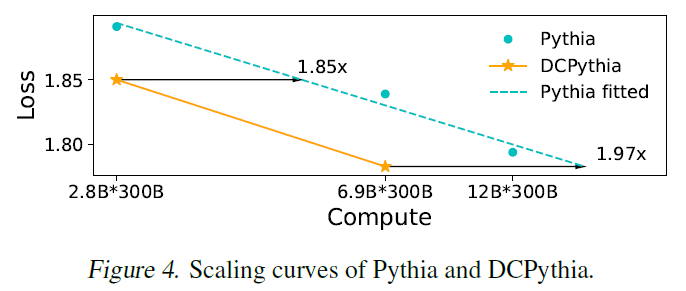
從上圖可以看出,在相同訓練數據和算力下,一個被本文方法改進后69億參數的模型,卻擁有比120億參數傳統模型結構更好的效果。
換句話講:相同的參數量下,使用DCFormer將具備更強的模型表達能力;用更少的參數量,擁有相同的模型表示效果。
DCFormer在不同的架構和模型規模下,在語言建模方面顯著優于Transformer,與計算量增加1.7倍至2倍的模型性能相匹配。
距離大模型“光速”生成tokens不遠了
筆者覺得這個工作還是蠻扎實的,如果能像RoPE一樣在國內外的主流大模型落地,大模型“光速”生成tokens的一天并不遙遠,而且從AI產業對電力能源的利用效率來說,也是一個很有意義的改善。
實話說,在如今這個“資本寒冬”,愿意為前瞻技術研究投入資金、人才支持的公司非常少了,能在ICML這個高含金量機器學習頂會上跑出來高分論文的團隊,背后一定離不開公司層面的支持。
在寫這篇文章的時候,筆者注意到,彩云科技團隊也在進行大模型對齊和測評算法研究員、大模型推理優化、AIGC產品經理、后端工程師、前端工程師、SRE工程師等職位的招聘,這里附上簡歷投遞二維碼:

倘若能進入到發表ICML高分論文的團隊參與AI方向的學術研究和產品落地,屬實是一個非常珍貴的職業經歷,感興趣的小伙伴抓住機會。
筆者在搜彩云科技的時候,還無意間扒出來了意想不到的東西。
筆者發現,有一款服務500+家大客戶的超大型B端產品——彩云天氣竟然也是彩云科技旗下的。

沒準,你手機里的、汽車車載系統里的天氣APP背后走的很可能就是彩云天氣API。
做過ToB業務的都知道,能獲得100家大客戶青睞的B端產品就已經具備相當的B端影響力了,而彩云天氣不僅斬獲了滴滴、小米、vivo、高德、360、小鵬汽車在內的500多家大客戶,其甚至早在2014年就成為了中國氣象局的戰略合作伙伴,曾幫助多個部門和地區避免了自然災害風險。
不夸張的講,彩云天氣已成為了國內事實上的氣象服務基礎設施。
這背后,無疑是彩云科技強悍的AI算法實力和強大的工程能力。

如果你對AI ToB產品覺得陌生,那彩云科技旗下的另一款爆款AI ToC產品請讓我安利下,因為——
它真的太圈粉了!
作為文字工作者,筆者自ChatGPT爆火以來,玩遍了國內外幾乎所有的文字創作類產品,但給筆者留下深刻印象&能持續用起來的產品不多,彩云小夢就是其中一款。
彩云小夢是一款網文輔助寫作工具,也是一個 AI RPG 平臺,用戶可以在里面扮演各種角色,體驗不同的人生。AI 寫作助手具有文風獨特、可以自動續寫、支持自定義開頭等特點和功能。
作為曾經的RPG游戲愛好者(玩過金庸群俠傳、仙劍奇俠傳、武林群俠傳系列的小伙伴請舉手🙋🏻?♀?),筆者甚至用彩云小夢將金庸群俠傳游戲劇情翻寫過小說,因為彩云小夢AI生成的內容太有意思了,貼一段你們自己感受下:

在寫網文這塊,用過彩云小夢后就再也用不回ChatGPT了,體驗差別懸殊。
但最讓我停不下來的,倒不是寫網文。而是你可以扮演網文里面的角色:
這種沉浸式角色的體驗非常神奇,經常玩半天都停不下來:
彩云小夢的產品體驗非常絲滑、穩定,技術出身的筆者,能深刻的在這份絲滑背后的工程能力和產品能力有多強大。
除了彩云天氣和彩云小夢外,彩云科技旗下的彩云小譯也是業界有口皆碑的同聲傳譯軟件,不僅有閱文集團、360和維基百科等廣泛的客戶群基礎,其甚至給《三體》做過翻譯,篇幅原因,這里就不展開講了。
總之,通過進一步深挖彩云科技旗下的產品,筆者深感這是一家集強大的AI算法、工程和產品能力于一身的老牌科技公司,這種低調鉆研技術、打磨產品、做扎實的價值創造的寶藏團隊在國內屬實稀缺。深得筆者喜愛。

最后貼下彩云科技的招聘信息,多個崗位正在火熱招聘中,感興趣的小伙伴抓住機會,招聘崗位詳情請點擊鏈接進一步了解:
http://colorfulclouds.com/jobs/




大學生數學建模挑戰賽 | 園區微電網風光儲協調優化配置 | 數學建模完整代碼解析)










)
:AVL樹)
建模、調優)


)
