transformer
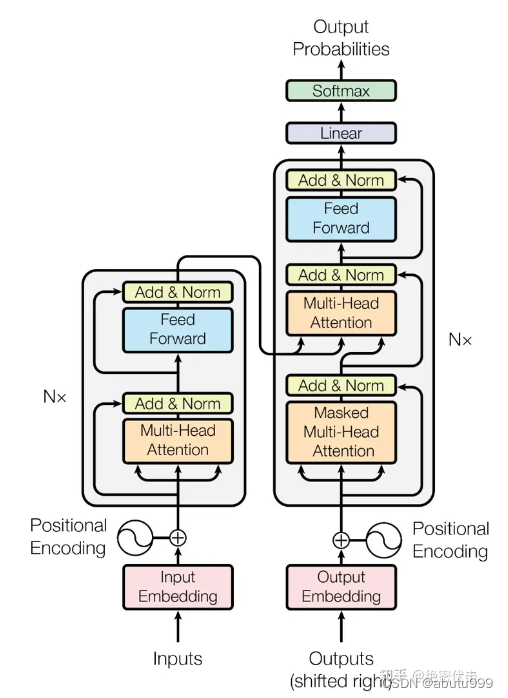
ENCODER
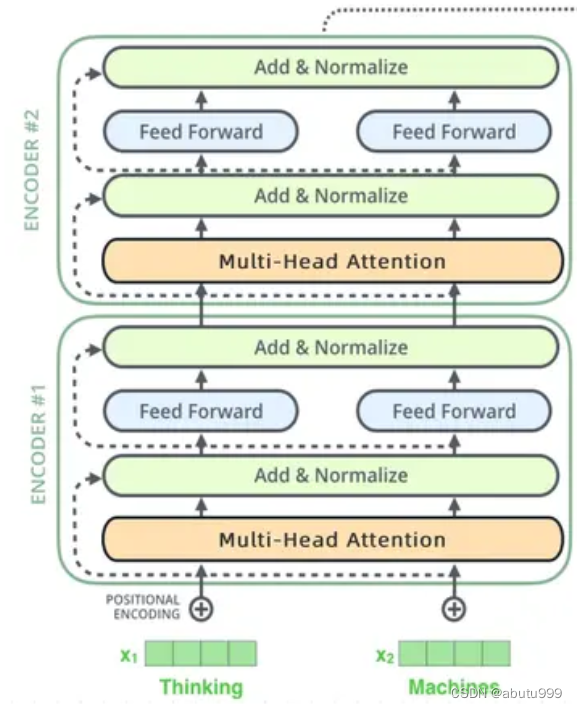
輸入部分
對拆分后的語句x = [batch_size, seq_len]進行以下操作
- Embedding
將離散的輸入(如單詞索引或其他類別特征)轉換為稠密的實數向量,以便可以在神經網絡中使用。 - 位置編碼
與RNN相比,RNN是一個字一個字的輸入,自然每個字的順序關系信息就會保留下來。但在Encoder中,一個句子的每一個字(詞)是并行計算的(下一節解釋),所以我們在輸入的時候需要提前引入位置信息。
位置信息由: pos(一句話中的第幾個字) 和 i (這個字編碼成向量后的第i維) 來確定
下面是Positional Encoding的公式:
i為 偶 數 時 , P E p o s , i = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos, i}= sin( pos/ 10000^{2i/ d_{model}}) PEpos,i?=sin(pos/100002i/dmodel?)
i為 奇 數 時 , P E p o s , i = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{pos, i}= cos( pos/ 10000^{2i/ d_{model}}) PEpos,i?=cos(pos/100002i/dmodel?)
d m o d e l d_{model} dmodel?指想用多長的 vector 來表達一個詞(embedding_dim)
通過輸入部分
x: [batch_size, seq_len, embedding_dim]
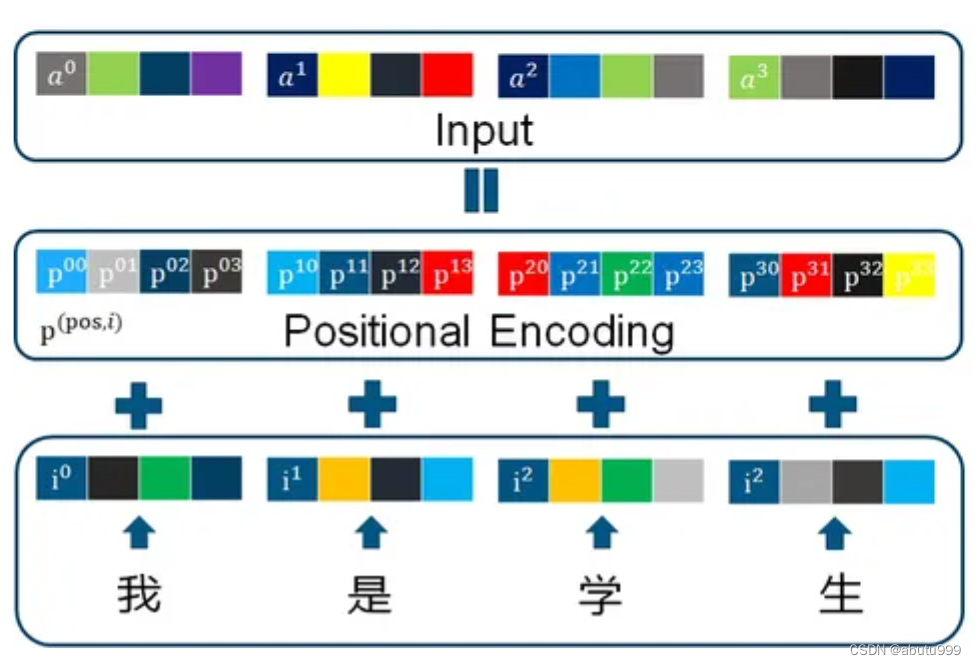
多頭注意力機制
- 單頭注意力機制
對一句話中第i個字的字向量 a i a_i ai?,產生三個矩陣Q, K ,V
Q,K,V的維度都為[batch_size, seq_len, embedding_dim]
將 a i a_i ai?分別與上面三個矩陣相乘,得到三個向量 q i , k i , v i q_i, k_i, v_i qi?,ki?,vi?
如果要計算第1個字向量與句子中所有字向量的注意力:
將查詢向量 q 1 q_1 q1?與 所有的字向量的鍵向量 k i k_i ki?相乘得到 a l p h a 10 , a l p h a 11 , . . . , a l p h a 1 , s e q l e n alpha_{10}, alpha_{11},...,alpha_{1,seqlen} alpha10?,alpha11?,...,alpha1,seqlen?
將這寫數值進行softmax處理后, 分別與 v i v_i vi?相乘再合加得到最終結果 b 1 b_1 b1?
- 多頭注意力機制
把 Q , K , V Q,K,V Q,K,V三個大矩陣變成n個小矩陣(seq_len, embedding_dim/n) n=8
用上節相同的方式計算8個矩陣,然后把每一個head-Attention計算出來的b矩陣拼在一起,作為輸出
Add&LN
Add是用了殘差神經網絡的思想,也就是把Multi-Head Attention的輸入的a矩陣直接加上Multi-Head Attention的輸出b矩陣(好處是可以讓網絡訓練的更深)得到的和 b ˉ \bar{b} bˉ矩陣
再在經過Layer normalization(歸一化,作用加快訓練速度,加速收斂)把
每一行(也就是每個句子)做歸一為標準正態分布,最后得到 b ^ \hat{b} b^
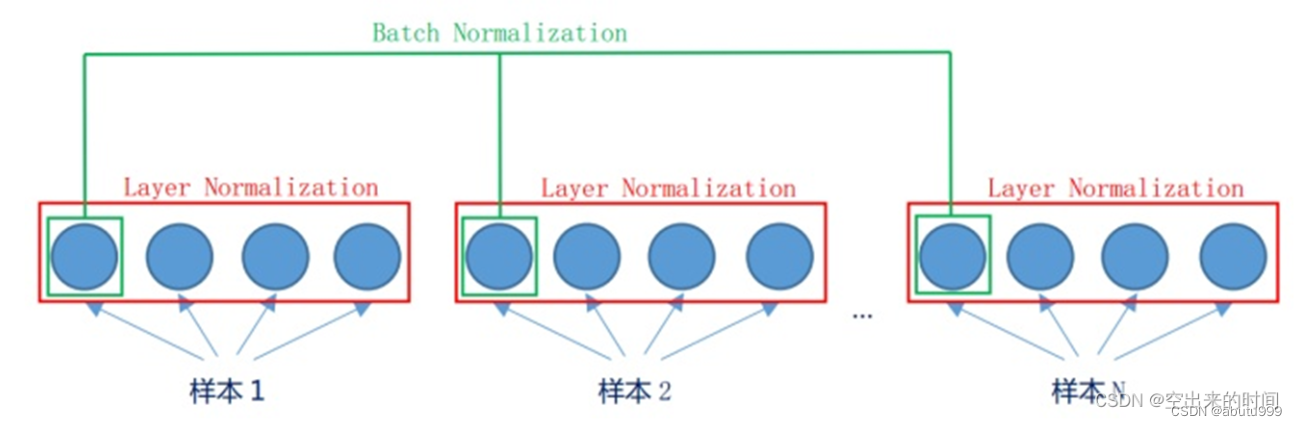
BN 和 LN:
- LN: 在一個樣本內做歸一化 適于RNN,transformer
- BN: 對batch_size里面的樣本按對應的特征做歸一化 適于CNN
Feed_forward前饋神經網絡
把Add & Layer normalization輸出 b ^ \hat{b} b^,經過兩個全連接層,再經過Add & Layer normalization得到最后輸出 o 矩陣
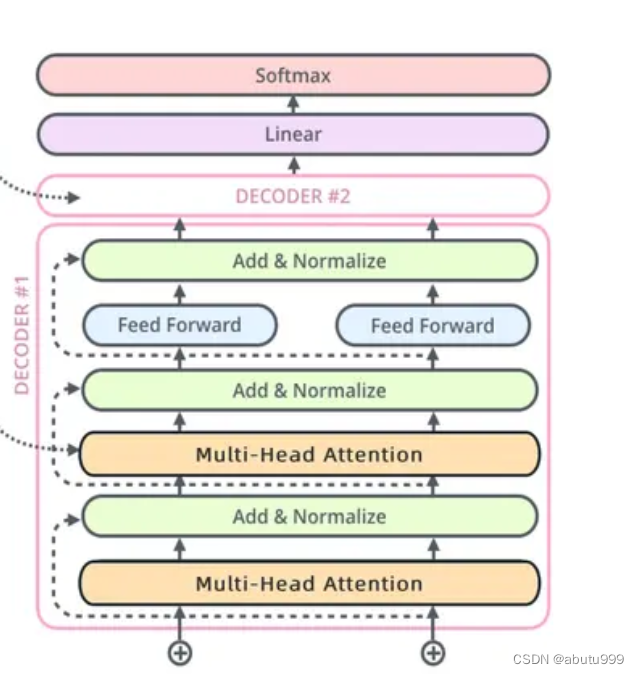
DECODER
masked_多頭注意力機制
比如我們在中英文翻譯時候,會先把"我是學生"整個句子輸入到Encoder中,得到最后一層的輸出后,才會在Decoder輸入"S I am a student"(s表示開始),但是"S I am a student"這個句子我們不會一起輸入,而是在T0時刻先輸入"S"預測,預測第一個詞"I";在下一個T1時刻,同時輸入"S"和"I"到Decoder預測下一個單詞"am";然后在T2時刻把"S,I,am"同時輸入到Decoder預測下一個單詞"a",依次把整個句子輸入到Decoder,預測出"I am a student E"
多頭注意力機制
Decoder 的 Multi-Head Attention 的輸入來自兩部分,
K,V 矩陣來自Encoder的輸出,
Q 矩陣來自 Masked Multi-Head Attention 的輸出

)





)
)
![BUUCTF靶場[MISC]wireshark、被嗅探的流量、神秘龍卷風、另一個世界](http://pic.xiahunao.cn/BUUCTF靶場[MISC]wireshark、被嗅探的流量、神秘龍卷風、另一個世界)









】)