Spark的最簡安裝
1. 下載并解壓 Spark
首先,我們需要下載 Spark 安裝包。您可以選擇以下方式之一:
方式一:從官網下載(推薦)
# 在 hadoop01 節點上執行
cd /home/hadoop/app
wget https://archive.apache.org/dist/spark/spark-2.3.1/spark-2.3.1-bin-hadoop2.7.tgz
方式二:如果已有安裝包,直接解壓
cd /home/hadoop/app
# 如果已經有安裝包,直接解壓
tar -zxvf spark-2.3.1-bin-hadoop2.7.tgz
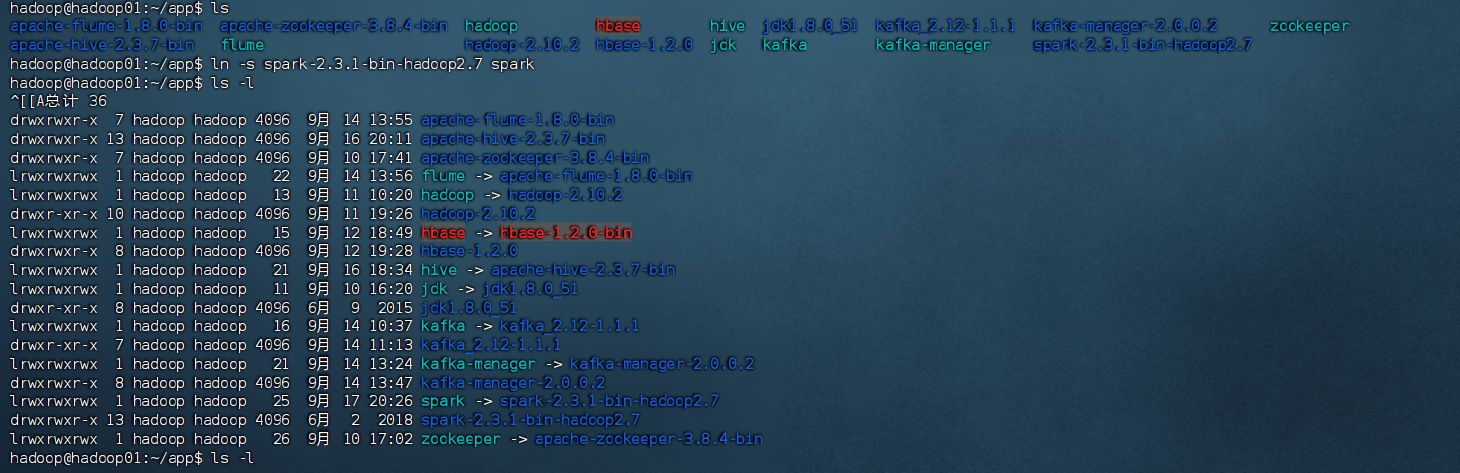
# 創建軟鏈接
ln -s spark-2.3.1-bin-hadoop2.7 spark
2. 測試運行 Spark
(1) 準備測試數據集
cd /home/hadoop/app/spark
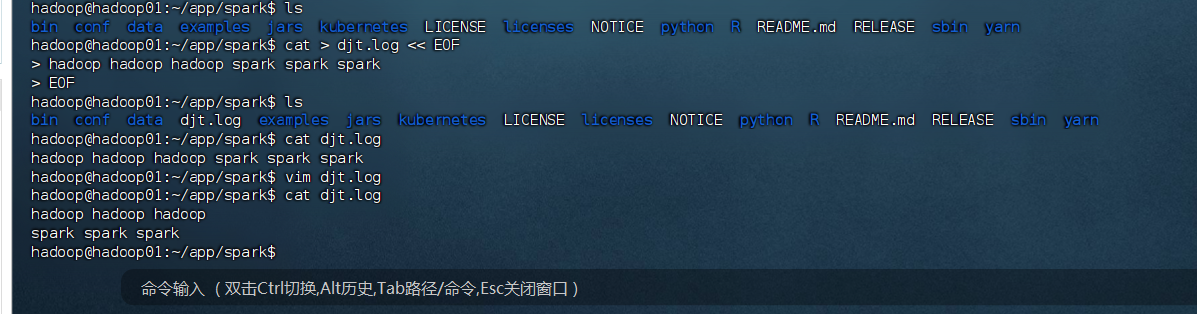
# 創建測試文件
cat > djt.log << EOF
hadoop hadoop hadoop spark spark spark
EOF# 查看文件內容
cat djt.log
(2) Spark shell 測試運行單詞詞頻統計
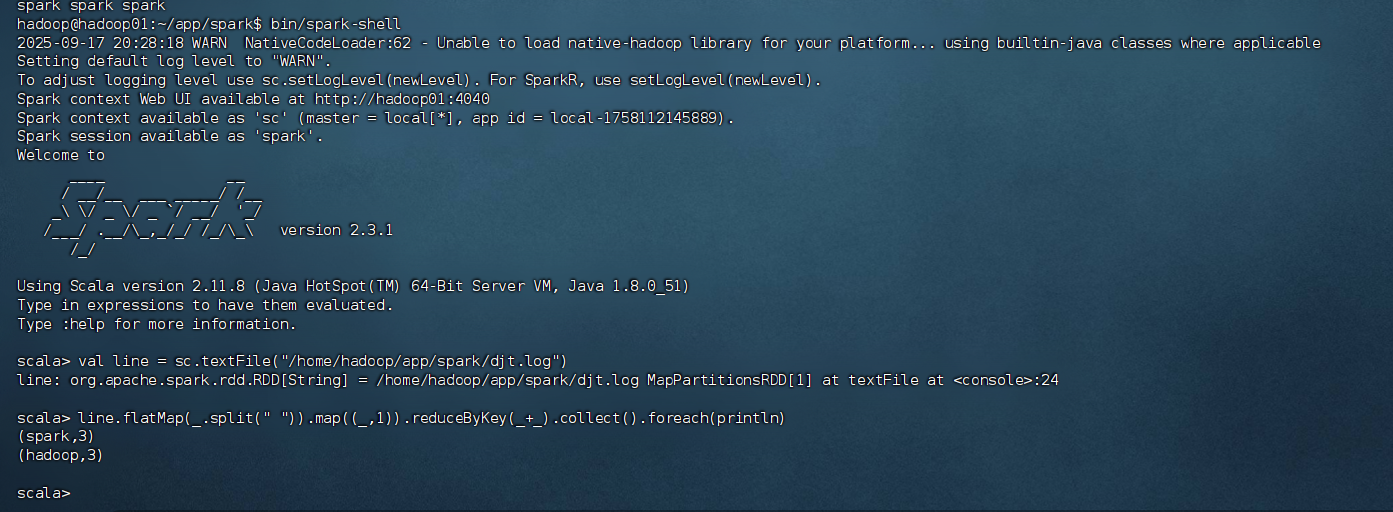
# 啟動 Spark shell
bin/spark-shell# 等待 Spark shell 啟動完成,看到 scala> 提示符后,依次輸入以下命令:
在 Spark shell 中輸入以下命令:
// 讀取本地文件
val line = sc.textFile("/home/hadoop/app/spark/djt.log")// WordCount 統計并打印
line.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
預期輸出:
(spark,3)
(hadoop,3)
3. Spark 實現 WordCount(Scala 程序)
步驟1:下載 Hadoop 及 winutils.exe
1.1 下載 Hadoop 2.7.1 安裝包
鏈接參考https://blog.csdn.net/qq_39900031/article/details/121080109
好的,我把 Windows 下 Hadoop 環境配置的 完整詳細過程整理給你(以 Hadoop 2.7.1 + JDK1.8 為例):
一、準備工作
-
安裝 JDK1.8
-
下載 JDK1.8 并安裝,推薦路徑如:
C:\Java\jdk1.8.0_221。 -
配置環境變量:
JAVA_HOME=C:\Java\jdk1.8.0_221PATH中添加:%JAVA_HOME%\bin- 新建
CLASSPATH=.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar
-
-
下載 Hadoop 2.7.1
- 地址:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.1/
- 解壓到:
C:\hadoop-2.7.1
-
下載 HadoopOnWindows 適配包
- GitHub 或 CSDN 提供的
hadooponwindows-master.zip - 解壓后,把里面的 bin 和 etc 文件夾 覆蓋到
C:\hadoop-2.7.1目錄下。
- GitHub 或 CSDN 提供的
二、配置 Hadoop 環境變量
在 系統環境變量中新建:
HADOOP_HOME=C:\hadoop-2.7.1PATH添加:%HADOOP_HOME%\bin;%HADOOP_HOME%\sbin
三、修改配置文件
進入 C:\hadoop-2.7.1\etc\hadoop 目錄:
-
hadoop-env.cmd
set JAVA_HOME=C:\Java\jdk1.8.0_221 -
core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property><property><name>hadoop.tmp.dir</name><value>C:/hadoop-2.7.1/tmp</value>


)


)




)

)






