1 ShardingSphere-JDBC 內核工作原理
-
當往 ShardingSphere 提交一個邏輯SQL后,ShardingSphere 到底做了哪些事情呢?首先要從 ShardingSphere 官方提供的這張整體架構圖說起:
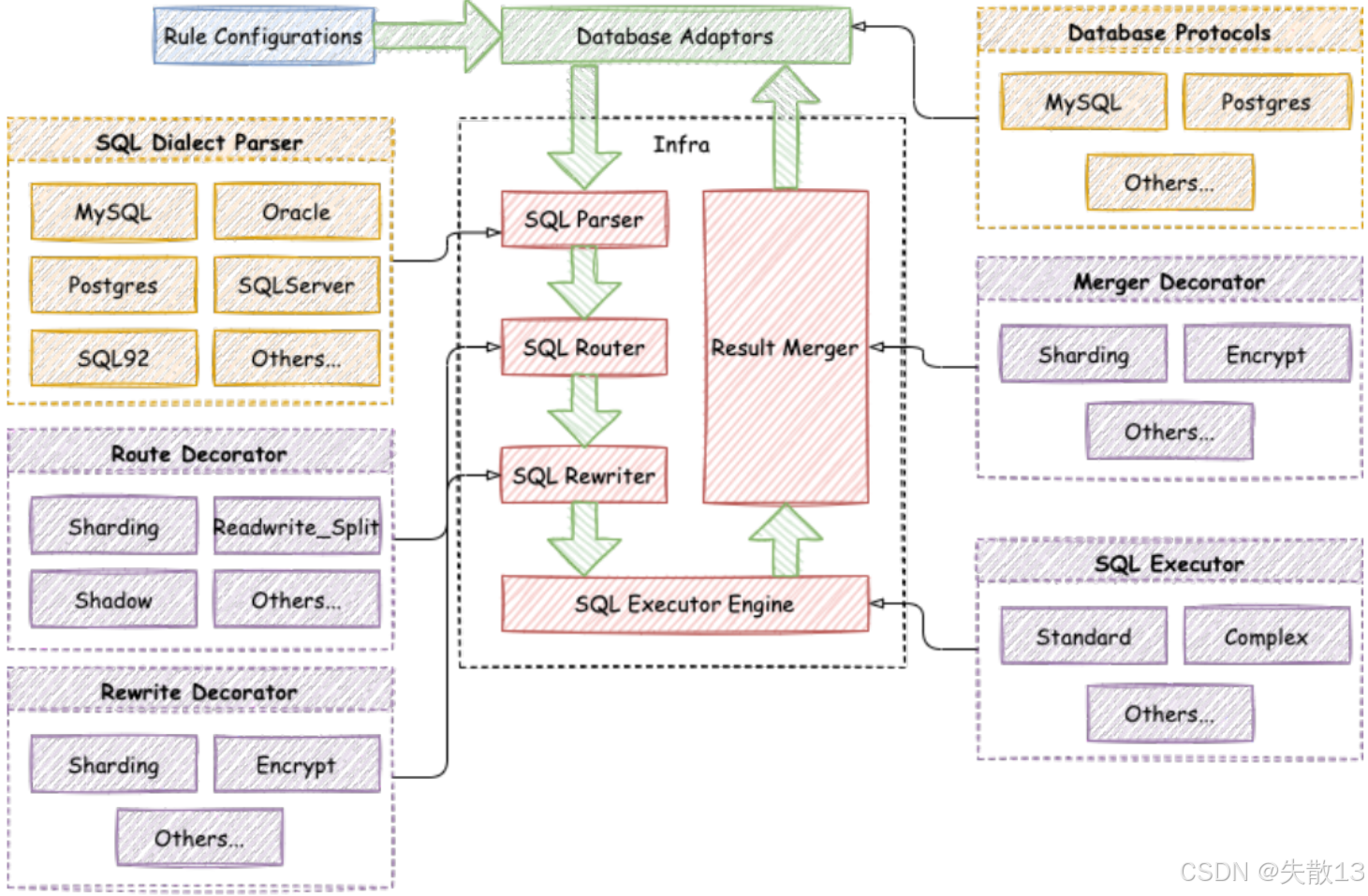
1.1 配置管控
-
在 SQL 進入 ShardingSphere 內核處理(如解析、路由、重寫等)之前,ShardingSphere 會先對應用的配置信息進行處理。這些配置可能涉及:
-
數據庫分片規則(哪些表分片、分片鍵是什么、分片算法如何);
-
讀寫分離規則(讀請求和寫請求路由到哪些庫);
-
數據加密規則(哪些字段需要加密、加密算法是什么)等;
-
-
ShardingSphere 不僅能解析應用本地的配置,還支持將配置信息存儲到 第三方注冊中心(如 Nacos、ZooKeeper 等)。這樣做的價值是:
-
實現應用層的水平擴展:多個應用實例可共享注冊中心的配置,無需每個實例單獨維護配置,集群擴容時更高效;
-
配置集中管理:運維人員能在注冊中心統一修改、下發配置,無需逐個修改應用配置,降低維護成本;
-
-
ShardingSphere-JDBC vs ShardingProxy
-
ShardingSphere-JDBC:作為客戶端側的數據庫中間件(以 Jar 包形式集成到應用中),應用本身可以自己管理配置(比如在應用配置文件里寫規則),或者自行接入 Nacos 等配置中心。因此,配置管控對 ShardingSphere-JDBC 來說,不是特別亮眼的功能(因為應用有其他替代方案);
-
ShardingProxy:作為服務端側的數據庫中間件(對外提供數據庫服務,應用像連普通數據庫一樣連 Proxy),運維人員通過 Proxy 管理多應用的數據庫訪問規則。此時,配置管控(尤其是對接注冊中心實現集中配置)的價值就非常突出——能更高效地管理多應用、多節點的配置。
-
1.2 SQL Parser:SQL解析引擎
-
SQL 解析分為兩步:
-
詞法解析:把 SQL 拆成不可再分的原子符號(Token),并根據不同數據庫方言鎖提供的字典,將其歸類為關鍵字(如
SELECTFROMWHERE)、表達式、字面量(如'ACTIVE'18)、操作符(如=>AND)等; -
語法解析:基于詞法解析的結果,將 SQL 轉換為抽象語法樹(AST,Abstract Syntax Tree)——用“樹結構”表達 SQL 的邏輯結構,例:
SELECT id, name FROM t_user WHERE status = 'ACTIVE' AND age > 18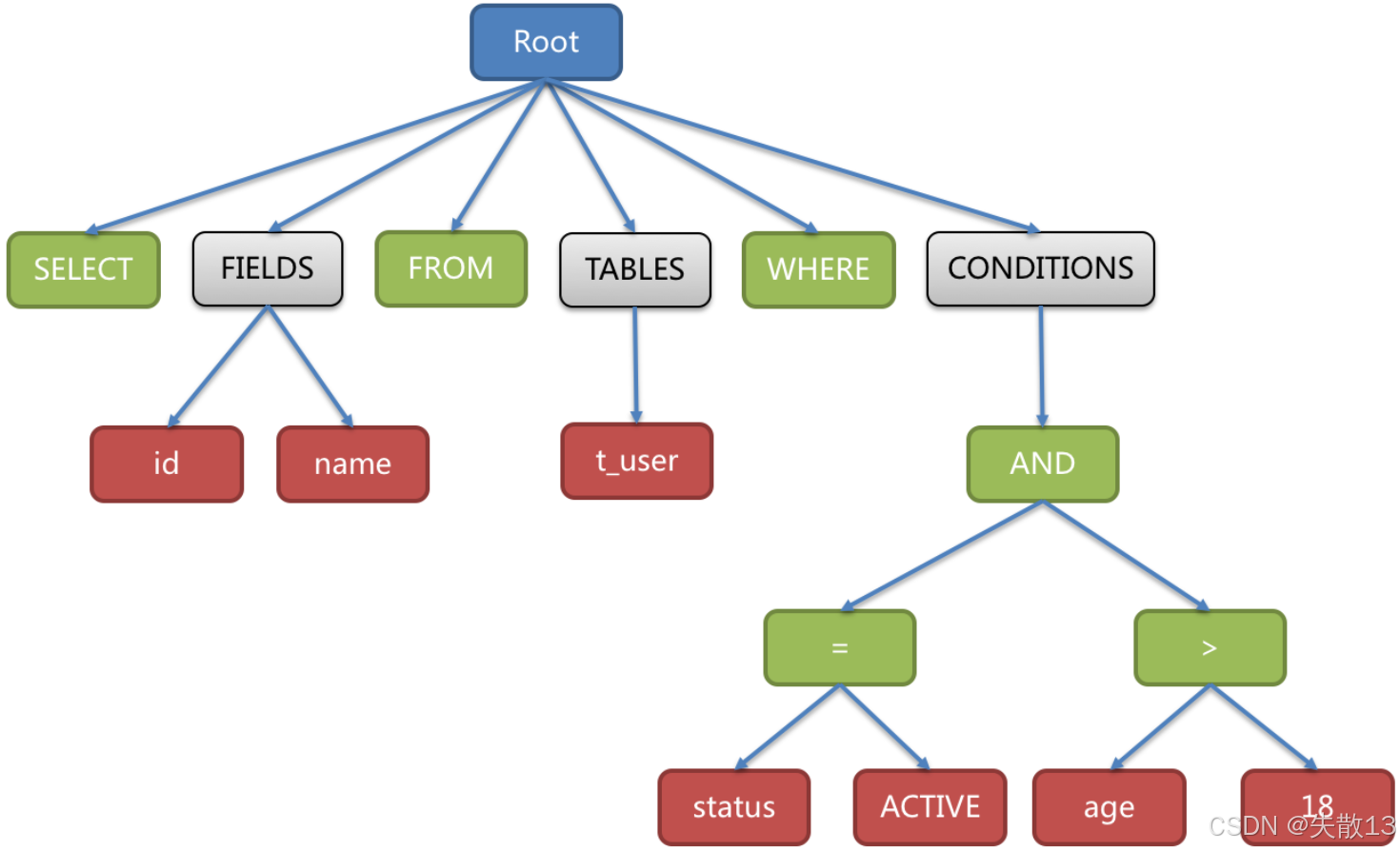
-
-
ShardingSphere 對 SQL 解析引擎的選擇,經歷了多個階段:
-
1.4.x 及之前:用 Druid(性能較快的開源解析引擎);
-
1.5.x 版本:自研解析引擎。針對分庫分表場景,采用對 SQL 半理解的方式,提升解析性能和兼容性(更適配中間件的業務需求);
-
3.0.x 及之后:改用 ANTLR(開源的 SQL 解析引擎)。ANTLR 被很多開源產品采用(如 Druid、Flink、Hive 等),通用性和擴展性更強。
-
1.3 SQL Router:SQL 路由引擎
-
路由引擎的關鍵是分片鍵(決定數據分片的字段):
-
攜帶分片鍵的SQL:走分片路由——根據分片鍵的操作符(如
=單片路由、IN多片路由、BETWEEN范圍路由),匹配數據庫/表的分片策略,生成精準的路由路徑(明確該SQL該訪問哪些分片); -
不攜帶分片鍵的SQL:走廣播路由——因為沒分片鍵,無法精準定位分片,需向所有相關數據庫/表廣播執行(但廣播路由影響大,不利于集群管理,所以實際應盡量用攜帶分片鍵的SQL);
-
-
分片路由又因SQL場景不同,分為多種子路由:
-
直接路由:通過
hint(手動指定路由規則),強制SQL路由到特定分片; -
標準路由:單表或綁定表(關聯時可視為單表的表)的SQL,按分片規則精準路由;
-
笛卡爾路由:多表且無綁定表關系的關聯查詢,需對多表分片做笛卡爾積組合路由(性能較差,應盡量避免);
-
-
不攜帶分片鍵時,不同類型的SQL(如DQL查詢、DML增刪改、DDL建表、DCL權限操作等),廣播路由也細分了多種子路由:
-
全庫表路由:DQL/DML/DDL類語句(如
select * from course),遍歷所有庫的所有表執行; -
全庫路由:設置類DAL/TCL語句(如
set autocommit=0),遍歷所有庫執行; -
全實例路由:DCL語句(如
CREATE USER),每個數據庫實例執行一次; -
單播路由:查詢類DAL語句(如
DESCRIBE course),僅從任意一個庫表獲取元數據; -
阻斷路由:像
USE database這類對虛擬庫的操作,直接阻斷(因為中間件的庫是虛擬的,無需切換真實庫)。
-
1.4 SQL Rewriter: SQL 優化引擎
-
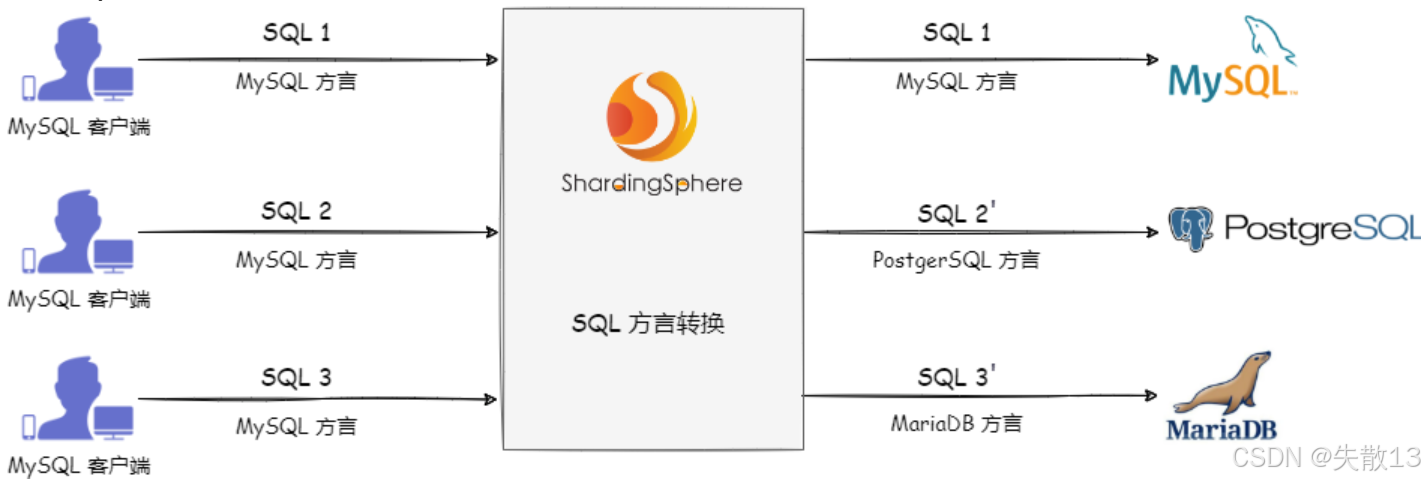
ShardingSphere 能實現不同數據庫方言之間的自動轉換;
- 例如:用 MySQL 客戶端發送 MySQL 方言的 SQL 給 ShardingSphere,ShardingSphere 會識別目標存儲節點類型(比如要訪問 PostgreSQL、MariaDB),自動把 SQL 轉成對應數據庫的方言,再下發執行;
- 這讓用戶可以面向邏輯庫/邏輯表寫 SQL,無需關心底層不同數據庫的語法差異,ShardingSphere 會負責“翻譯”;
-
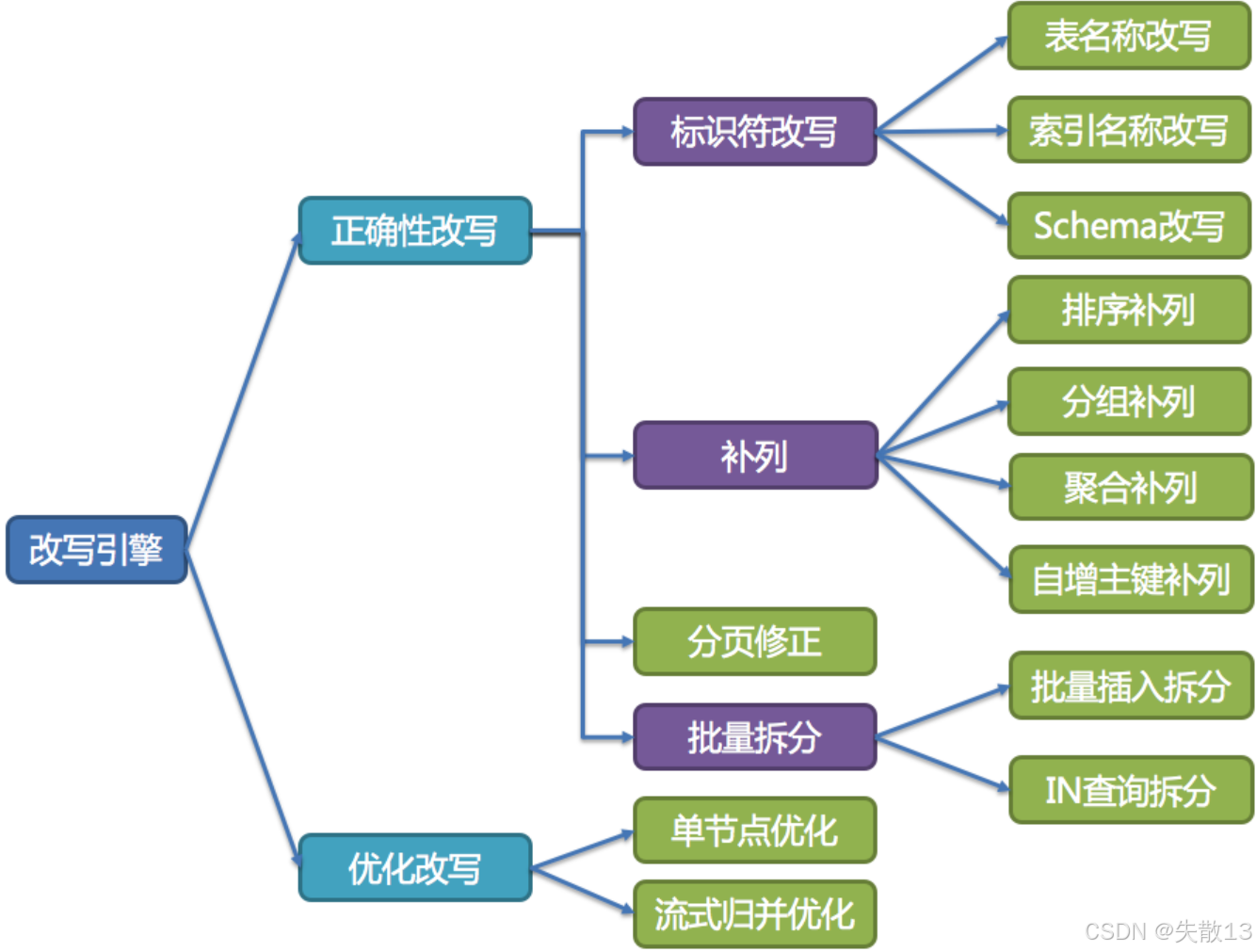
SQL 改寫分為正確性改寫和優化改寫,目的是讓 SQL 能在真實數據庫中正確執行或更高效執行;
-
正確性改寫:讓 SQL 能正確執行。解決邏輯庫表到真實庫表的匹配問題,確保 SQL 語義準確。包含以下能力:
-
標識符改寫:修改表名、索引名、Schema(數據庫名)等標識符。比如分表場景下,把邏輯表名(如
t_order)改寫成真實的分片表名(如t_order_0t_order_1); -
補列:為 SQL 補充必要的列,保證執行邏輯正確。比如:
- 排序補列:若排序依賴分片鍵,補充分片鍵列確保排序邏輯對;
- 分組補列:分組查詢時補充分片鍵列,保證分組正確;
- 聚合補列:聚合(如
COUNTSUM)時補充相關列; - 自增主鍵補列:處理分布式場景下自增主鍵的生成與填充;
-
分頁修正:分庫分表后,分頁邏輯可能跨多個分片,需修正分頁參數,保證結果正確;
-
批量拆分:把批量操作(如批量插入、
IN條件包含大量值)拆分成小批量,避免單條 SQL 過大或觸發數據庫限制;
-
-
優化改寫:讓 SQL 執行更高效。在不影響 SQL 正確性的前提下,提升執行性能。包含:
-
單節點優化:針對單個數據庫節點的 SQL 執行邏輯優化;
-
流式歸并優化:對多分片返回的結果,用流式歸并的方式聚合,減少內存占用、提升響應速度(比如多分片的查詢結果,邊查邊合并,而非等所有分片都查完再合并);
-
1.5 SQL Executor: SQL執行引擎
-
ShardingSphere 采用一套自動化的執行引擎,負責將路由和改寫完成之后的真實 SQL 安全且高效發送到底層數據源執行;
-
ShardingSphere 的執行引擎,不是簡單用 JDBC 直連數據庫發 SQL,也不是直接把請求丟進線程池并發執行。它更關注平衡資源消耗:
-
控制數據庫連接創建的開銷;
-
控制內存占用的消耗;
-
最大化利用并發能力;
-
-
最終實現自動化平衡資源控制與執行效率;
-
-
執行流程:
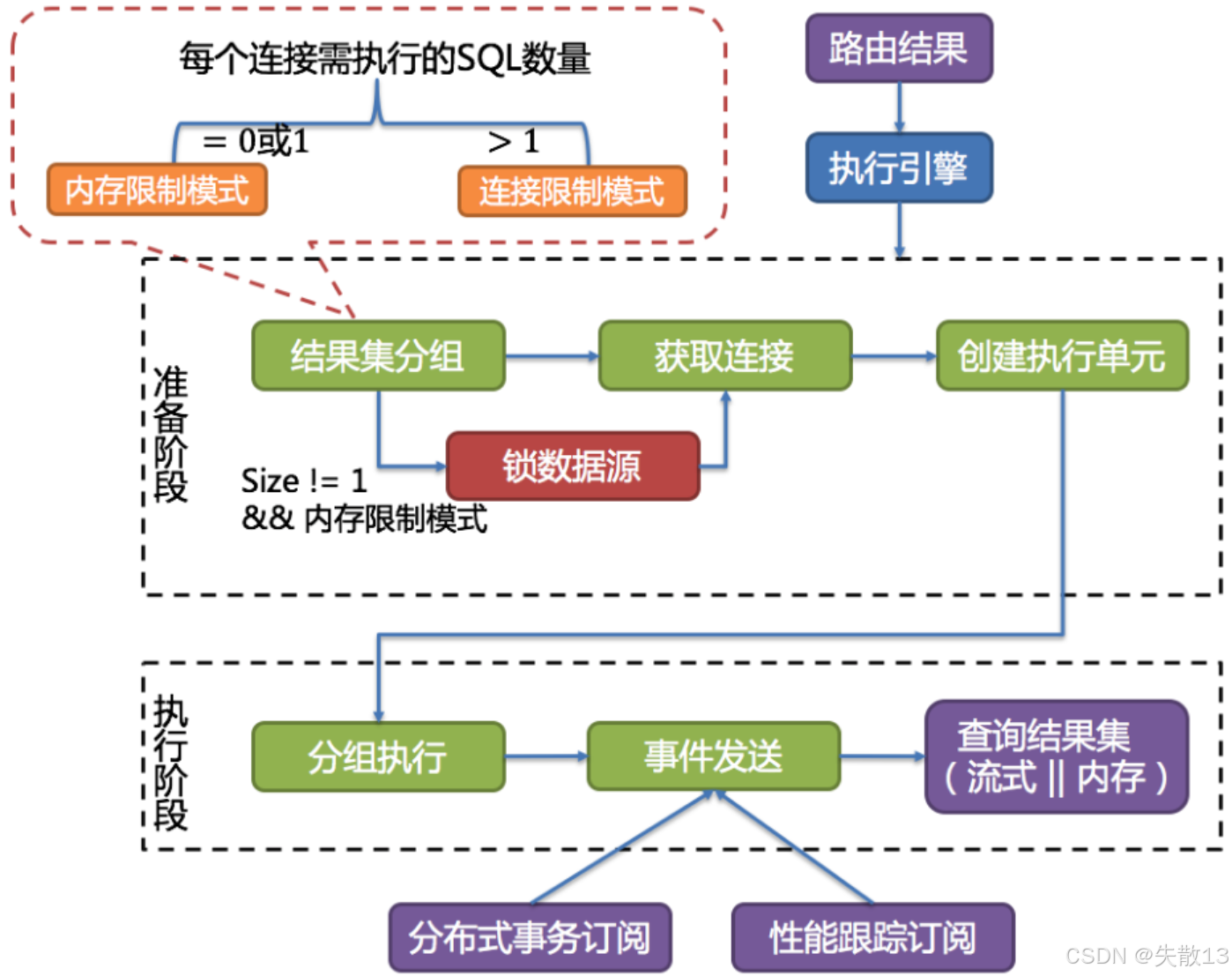
-
準備階段
- 結果集分組:把要執行的 SQL 按目標數據源分組(確定哪些 SQL 要發給哪個數據庫);
- 獲取連接 & 創建執行單元:為每組 SQL 獲取數據庫連接,并封裝成執行單元(包含 SQL、連接等信息);
- 鎖數據源(可選):若滿足“結果集數量≠1 且 內存限制模式”,會鎖定數據源(避免并發沖突);
-
執行階段
- 分組執行:按分組,執行每個執行單元里的 SQL;
- 事件發送:執行過程中,觸發分布式事務訂閱(保證分布式場景下事務一致性)和性能跟蹤訂閱(監控執行性能);
- 查詢結果集:以流式或內存方式獲取結果(流式適合大數據量,減少內存爆倉;內存適合小數據量,提升讀取速度);
-
-
執行模式由每個數據庫連接需執行的 SQL 數量決定,而這個數量的計算公式是:
每個數據庫連接需執行的SQL數量=所有需在該數據庫上執行的SQL數量maxConnectionSizePerQuery \text{每個數據庫連接需執行的SQL數量} = \frac{\text{所有需在該數據庫上執行的SQL數量}}{\text{maxConnectionSizePerQuery}} 每個數據庫連接需執行的SQL數量=maxConnectionSizePerQuery所有需在該數據庫上執行的SQL數量?
所有需在該數據庫上執行的SQL數量是路由至該數據源的路由結果;maxConnectionSizePerQuery是用戶配置項;
-
基于這個數量,分為兩種模式:
-
內存限制模式
-
條件:每個數據庫連接需執行的 SQL 數量 ≤ 1(即
= 0 或 1); -
邏輯:一個 JDBC 連接只執行 1 條 SQL;ShardingSphere 不限制一次操作消耗的數據庫連接總數(比如要執行 10 條 SQL,可能開 10 個連接,每個連執行 1 條);
-
適合場景:SQL 執行耗時短、并發不高,優先減少單連接壓力,用多連接提升并行度;
-
-
連接限制模式
-
條件:每個數據庫連接需執行的 SQL 數量 > 1;
-
邏輯:一個 JDBC 連接要執行多條 SQL;ShardingSphere 嚴格控制一次操作消耗的數據庫連接總數(比如要執行 10 條 SQL,可能只開 2 個連接,每個連接執行 5 條);
-
適合場景:數據庫連接資源寶貴(比如連接池大小有限),優先節省連接數,用單連接執行多 SQL 減少連接開銷。
-
-
1.6 Result Merger:結果歸并
-
當 SQL 涉及多分片(多個數據節點)時,每個分片會返回部分結果。結果歸并就是把這些分散的結果集組合成一個完整的結果集,再返回給客戶端;
-
歸并引擎會根據 SQL 的分頁、分組、排序、聚合等需求,選擇不同的歸并策略:
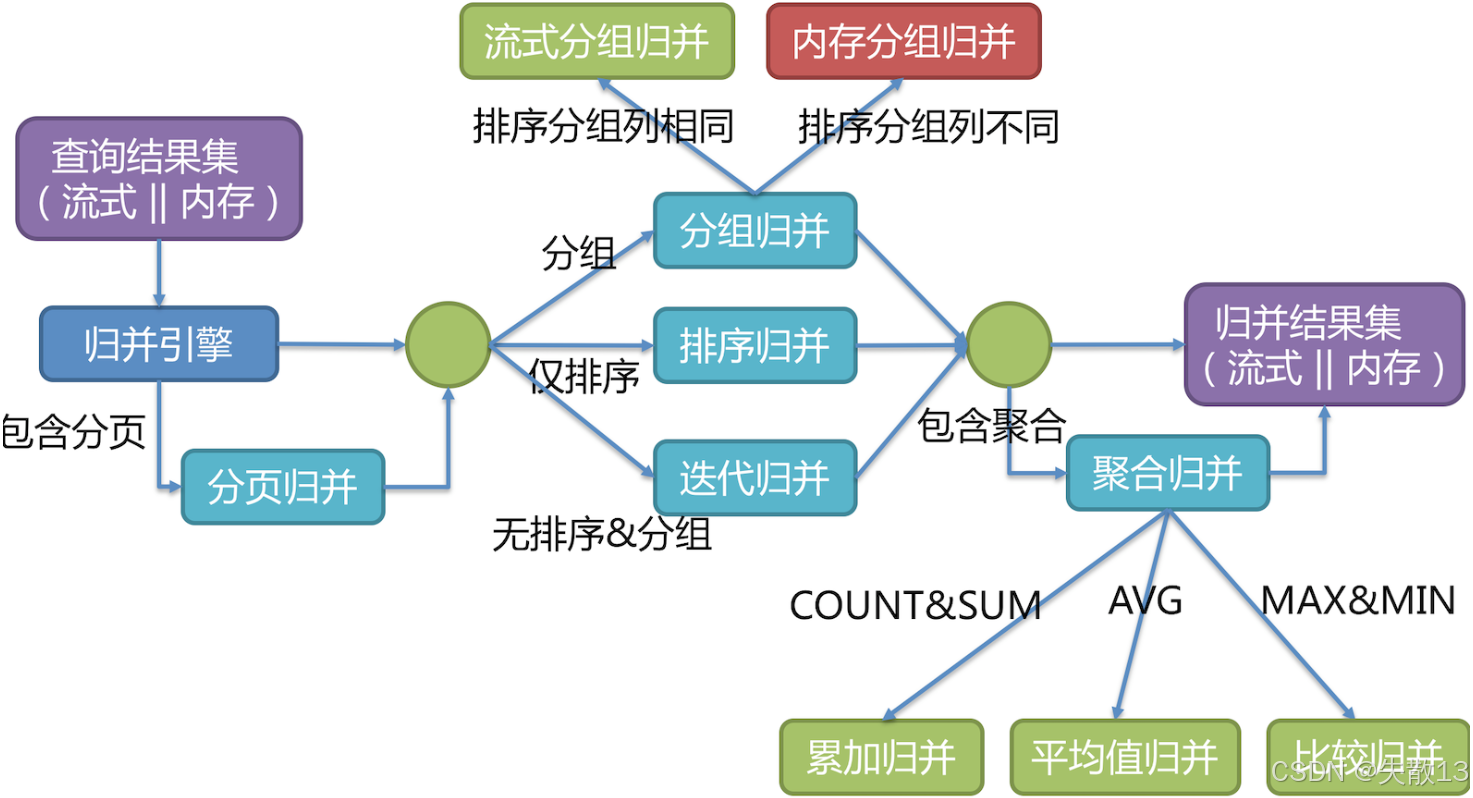
-
帶分頁的場景 → 分頁歸并:處理需要分頁的查詢(如
LIMIT語句),確保最終結果的分頁邏輯正確(比如從多分片結果中,篩選出符合頁碼的記錄); -
分組/排序/無分組排序的場景:
-
分組歸并:若 SQL 有分組(
GROUP BY)需求,對多分片結果按分組規則合并(又分流式分組歸并和內存分組歸并,取決于排序分組列是否相同); -
排序歸并:若 SQL 有排序(
ORDER BY)需求,對多分片結果按排序規則合并; -
迭代歸并:若 SQL 既無分組也無排序,直接迭代合并多分片結果;
-
-
帶聚合的場景 → 聚合歸并:若 SQL 有聚合函數(如
COUNTSUMAVGMAXMIN),對多分片的聚合結果再做一次聚合:-
COUNT/SUM→ 累加歸并(把各分片的計數/求和結果相加); -
AVG→ 平均值歸并(基于各分片的和與計數,計算整體平均值); -
MAX/MIN→ 比較歸并(從各分片的最大/最小值中,再選最大/最小);
-
-
歸并模式的選擇,決定了結果如何存儲、如何返回,適配不同業務場景:
-
流式歸并
-
每次從結果集中取一條數據,逐條返回(和數據庫原生返回結果集的方式一致);
-
無需把所有結果都加載到內存,內存消耗小,適合數據量大、需快速返回首條結果的場景(如 OLTP 在線交易,強調低延遲、高并發);
-
典型場景:遍歷、排序、流式分組歸并等。通常內存限制模式會用流式歸并;
-
-
內存歸并
-
把所有分片的結果全部加載到內存,再統一做分組、排序、聚合,最后封裝成可逐次訪問的結果集返回;
-
需要更多內存,但能支持更復雜的全局分組、排序、聚合邏輯。適合分析型查詢(OLAP)(如報表統計,需處理大量數據做全局計算);
-
典型場景:通常連接限制模式會用內存歸并。
-
-
2 ShardingSphere-JDBC 擴展機制
2.1 ShardingSphereDataSource
-
如何調試 ShardingSphere-JDBC 的源碼呢?這就需要一個比較簡單明了的測試案例來作為調試代碼的入口:
public class ShardingJDBCDemo {public static void main(String[] args) throws SQLException {// 一、配置數據庫連接池:創建兩個物理數據庫的數據源Map<String, DataSource> dataSourceMap = new HashMap<>(2);// 配置第一個數據源,對應數據庫 shardingdb1HikariDataSource dataSource0 = new HikariDataSource();dataSource0.setDriverClassName("com.mysql.cj.jdbc.Driver");dataSource0.setJdbcUrl("jdbc:mysql://192.168.65.212:3306/shardingdb1?serverTimezone=GMT%2B8&useSSL=false");dataSource0.setUsername("root");dataSource0.setPassword("root");dataSourceMap.put("m0", dataSource0); // 數據源標識為 m0// 配置第二個數據源,對應數據庫 shardingdb2HikariDataSource dataSource1 = new HikariDataSource();dataSource1.setDriverClassName("com.mysql.cj.jdbc.Driver");dataSource1.setJdbcUrl("jdbc:mysql://192.168.65.212:3306/shardingdb2?serverTimezone=GMT%2B8&useSSL=false");dataSource1.setUsername("root");dataSource1.setPassword("root");dataSourceMap.put("m1", dataSource1); // 數據源標識為 m1// 二、配置分庫分表規則:定義數據如何分布到不同的庫和表中ShardingRuleConfiguration shardingRuleConfig = createRuleConfig();// 三、配置ShardingSphere屬性:開啟SQL執行日志顯示Properties properties = new Properties();properties.setProperty("sql-show", "true"); // 顯示分片后的真實SQL語句// TEST:創建ShardingSphere數據源,整合所有配置,創建具有分片功能的數據源DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap,Collections.singleton(shardingRuleConfig), properties);// 測試部分ShardingJDBCDemo test = new ShardingJDBCDemo();// 建表操作(需要時取消注釋執行)//test.droptable(dataSource);//test.createtable(dataSource);// 插入測試數據(需要時取消注釋執行)//test.addcourse(dataSource);// TEST(調試的起點):查詢數據,驗證分片查詢功能test.querycourse(dataSource);}/*** 創建分片規則配置* 配置邏輯表course如何映射到物理表(分布在m0和m1兩個庫,每個庫有course_1和course_2兩個表)*/private static ShardingRuleConfiguration createRuleConfig(){ShardingRuleConfiguration result = new ShardingRuleConfiguration();// 配置邏輯表course對應的實際數據節點:m0和m1兩個庫,每個庫有course_1和course_2表ShardingTableRuleConfiguration courseTableRuleConfig = new ShardingTableRuleConfiguration("course","m$->{0..1}.course_$->{1..2}");// 配置分布式ID生成算法(雪花算法)Properties snowflakeprop = new Properties();snowflakeprop.setProperty("worker.id", "123"); // 設置工作節點IDresult.getKeyGenerators().put("alg_snowflake", new AlgorithmConfiguration("SNOWFLAKE", snowflakeprop));// 配置課程表的主鍵生成策略:使用雪花算法為cid字段生成IDcourseTableRuleConfig.setKeyGenerateStrategy(new KeyGenerateStrategyConfiguration("cid","alg_snowflake"));// 配置分庫策略:按照cid字段進行分庫,使用MOD算法(取模)courseTableRuleConfig.setDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("cid","course_db_alg"));Properties modProp = new Properties();modProp.put("sharding-count",2); // 設置分片數量為2(兩個庫)result.getShardingAlgorithms().put("course_db_alg",new AlgorithmConfiguration("MOD",modProp));// 配置分表策略:按照cid字段進行分表,使用INLINE表達式算法courseTableRuleConfig.setTableShardingStrategy(new StandardShardingStrategyConfiguration("cid","course_tbl_alg"));// 分表算法表達式:根據cid計算表名后綴(結果為1或2)Properties inlineProp = new Properties();inlineProp.setProperty("algorithm-expression", "course_$->{((cid+1)%4).intdiv(2)+1}");result.getShardingAlgorithms().put("course_tbl_alg",new AlgorithmConfiguration("INLINE",inlineProp));result.getTables().add(courseTableRuleConfig);return result;}// 添加測試課程數據:插入9條記錄,觀察ID生成和分片效果public void addcourse(DataSource dataSource) throws SQLException {for (int i = 1; i < 10; i++) {long orderId = executeAndGetGeneratedKey(dataSource, "INSERT INTO course (cname, user_id, cstatus) VALUES ('java'," + i + ", '1')");System.out.println("添加課程成功,課程ID:" + orderId);}}// 查詢課程數據:根據特定cid查詢,測試分片查詢功能public void querycourse(DataSource dataSource) throws SQLException {Connection conn = null;try {// 獲取ShardingSphere連接(特殊化的Connection實現)conn = dataSource.getConnection();// 創建ShardingSphere語句對象Statement statement = conn.createStatement();String sql = "SELECT cid,cname,user_id,cstatus from course where cid=851198093910081536";// 執行查詢,獲取分片結果集ResultSet result = statement.executeQuery(sql);while (result.next()) {System.out.println("result:" + result.getLong("cid"));}} catch (SQLException e) {e.printStackTrace();} finally {if (null != conn) {conn.close();}}}// 通用SQL執行方法private void execute(final DataSource dataSource, final String sql) throws SQLException {try (Connection conn = dataSource.getConnection();Statement statement = conn.createStatement()) {statement.execute(sql);}}// 執行SQL并返回生成的主鍵(用于獲取雪花算法生成的ID)private long executeAndGetGeneratedKey(final DataSource dataSource, final String sql) throws SQLException {long result = -1;try (Connection conn = dataSource.getConnection();Statement statement = conn.createStatement()) {statement.executeUpdate(sql, Statement.RETURN_GENERATED_KEYS);ResultSet resultSet = statement.getGeneratedKeys();if (resultSet.next()) {result = resultSet.getLong(1); // 獲取生成的主鍵值}}return result;}/*** 表初始化操作*/public void droptable(DataSource dataSource) throws SQLException {execute(dataSource, "DROP TABLE IF EXISTS course_1");execute(dataSource, "DROP TABLE IF EXISTS course_2");}public void createtable(DataSource dataSource) throws SQLException {execute(dataSource, "CREATE TABLE course_1 (cid BIGINT(20) PRIMARY KEY,cname VARCHAR(50) NOT NULL,user_id BIGINT(20) NOT NULL,cstatus varchar(10) NOT NULL);");execute(dataSource, "CREATE TABLE course_2 (cid BIGINT(20) PRIMARY KEY,cname VARCHAR(50) NOT NULL,user_id BIGINT(20) NOT NULL,cstatus varchar(10) NOT NULL);");} } -
代碼中最關鍵的是
ShardingSphereDataSource(標記為TEST處),它是整個分庫分表功能的中樞:- 它實現了 JDBC 的
DataSource接口,因此可以像普通數據源(如 Druid、Hikari)一樣,與 Spring Data、MyBatis 等框架無縫集成(符合 JDBC 規范,無需修改上層代碼); - 當通過它獲取連接(
getConnection())、執行 SQL 時,ShardingSphere 會在底層自動完成:- SQL 解析(理解 SQL 要操作什么);
- 路由(根據分庫分表規則,確定該訪問哪些真實庫表);
- SQL 改寫(將邏輯表名改為真實表名等);
- 執行(在目標庫表上執行 SQL);
- 結果歸并(將多庫表的結果合并為一個)。
- 它實現了 JDBC 的
2.2 基于 ShardingSphereDataSource 的工作方式
-
實際上,ShardingSphereDataSource 除了擁有分庫分表的功能外,還實現了很多自己的擴展功能。其中最常用的,是他能自己解析配置文件。因此, ShardingSphere-JDBC 其實完全可以脫離 SpringBoot 等框架,以通過標準 JDBC 方式獨立運行。例:
在上一章節
10.2 ShardingSphere-JDBC分庫分表實戰與講解的案例,實際上是通過基于 SpringBoot 的第三方拓展,來實現解析配置文件、創建數據源等功能;public class ShardingJDBCDriverTest {@Testpublic void test() throws ClassNotFoundException, SQLException {String jdbcDriver = "org.apache.shardingsphere.driver.ShardingSphereDriver";String jdbcUrl = "jdbc:shardingsphere:classpath:config.yaml";String sql = "select * from sharding_db.course";// 用 Class.forName 加載 ShardingSphereDriverClass.forName(jdbcDriver);// 通過 DriverManager.getConnection 連接,URL 指向配置文件 config.yamltry(Connection connection = DriverManager.getConnection(jdbcUrl);) {// 后續執行 SQL 的流程(createStatement、executeQuery 等)和標準 JDBC 完全一致Statement statement = connection.createStatement();ResultSet resultSet = statement.executeQuery(sql);while (resultSet.next()){System.out.println("course cid= "+resultSet.getLong("cid"));}}} }- 這說明 ShardingSphere 本身是 JDBC 規范的實現,只要提供正確的驅動和配置,就能獨立完成分庫分表等工作;
-
config.yaml是 ShardingSphere 的核心配置載體,用 YAML 格式定義分庫分表、數據源、全局屬性等規則,和之前用 Java 代碼配置的邏輯是等價的,只是形式不同。配置文件主要包含以下模塊:rules:定義各類規則(如SHARDING分庫分表規則、TRANSACTION事務規則、SQL_PARSERSQL 解析規則等)。以SHARDING為例,復刻上一章節對course表進行分庫分表的功能:- 真實表映射(
actualDataNodes: m${0..1}.course_${1..2},對應m0/m1庫的course_1/course_2表); - 分庫策略(按
cid取模,路由到m0或m1); - 分表策略(按
cid計算,路由到course_1或course_2); - 主鍵生成(雪花算法生成
cid);
- 真實表映射(
props:全局屬性(如連接池大小、SQL 日志開關、執行器線程數等);databaseName:邏輯數據庫名;dataSources:配置真實數據源(如m0、m1對應的數據庫連接信息);
# 權限規則配置:定義用戶權限 rules:- !AUTHORITY # 權限規則標識users:- root@%:root # 用戶root,可從任何主機訪問,密碼root- sharding@:sharding # 用戶sharding,無主機限制,密碼shardingprovider:type: ALL_PERMITTED # 權限提供者類型:所有用戶擁有所有權限- !TRANSACTION # 事務規則配置defaultType: XA # 默認事務類型:XA分布式事務providerType: Atomikos # 事務管理器提供者:Atomikos- !SQL_PARSER # SQL解析器配置sqlCommentParseEnabled: true # 啟用SQL注釋解析sqlStatementCache: # SQL語句緩存配置initialCapacity: 2000 # 初始容量2000條maximumSize: 65535 # 最大容量65535條parseTreeCache: # 解析樹緩存配置initialCapacity: 128 # 初始容量128個maximumSize: 1024 # 最大容量1024個- !SHARDING # 分片規則配置(核心配置)tables:course: # 邏輯表course的配置actualDataNodes: m${0..1}.course_${1..2} # 實際數據節點:兩個數據庫(m0,m1),每個庫兩個表(course_1,course_2)databaseStrategy: # 分庫策略standard:shardingColumn: cid # 分庫字段:cidshardingAlgorithmName: course_db_alg # 分庫算法名稱tableStrategy: # 分表策略standard:shardingColumn: cid # 分表字段:cidshardingAlgorithmName: course_tbl_alg # 分表算法名稱keyGenerateStrategy: # 主鍵生成策略column: cid # 主鍵列名keyGeneratorName: alg_snowflake # 主鍵生成器名稱# 分片算法定義shardingAlgorithms:course_db_alg: # 分庫算法type: MOD # 取模算法props:sharding-count: 2 # 分片數量:2個庫course_tbl_alg: # 分表算法type: INLINE # 內聯表達式算法props:algorithm-expression: course_$->{cid%2+1} # 表名計算表達式:cid對2取模后加1# 主鍵生成器定義keyGenerators:alg_snowflake:type: SNOWFLAKE # 使用雪花算法生成分布式ID# 系統屬性配置 props:max-connections-size-per-query: 1 # 每個查詢的最大連接數kernel-executor-size: 16 # 內核線程池大小,默認無限proxy-frontend-flush-threshold: 128 # 代理前端刷新閾值,默認128proxy-hint-enabled: false # 是否啟用hint強制路由sql-show: false # 是否顯示實際執行的SQL語句check-table-metadata-enabled: false # 是否檢查表元數據一致性proxy-backend-query-fetch-size: -1 # 代理后端查詢獲取大小,-1表示使用JDBC驅動最小值proxy-frontend-executor-size: 0 # 代理前端執行器大小,0由Netty決定proxy-backend-executor-suitable: OLAP # 代理后端執行器適用類型:OLAP(聯機分析處理)proxy-frontend-max-connections: 0 # 代理前端最大連接數,0表示無限制sql-federation-type: NONE # SQL聯邦查詢類型:不啟用proxy-backend-driver-type: JDBC # 代理后端驅動類型:JDBCproxy-mysql-default-version: 8.0.20 # MySQL默認版本proxy-default-port: 3307 # 代理服務器默認端口proxy-netty-backlog: 1024 # Netty backlog參數# 邏輯數據庫名稱(客戶端連接時使用的數據庫名) databaseName: sharding_db# 數據源配置:定義物理數據庫連接 dataSources:m0: # 第一個數據源標識dataSourceClassName: com.zaxxer.hikari.HikariDataSource # 使用HikariCP連接池url: jdbc:mysql://192.168.65.212:3306/shardingdb1?serverTimezone=UTC&useSSL=false # 數據庫連接URLusername: root # 數據庫用戶名password: root # 數據庫密碼connectionTimeoutMilliseconds: 30000 # 連接超時時間30秒idleTimeoutMilliseconds: 60000 # 空閑連接超時時間60秒maxLifetimeMilliseconds: 1800000 # 連接最大生命周期30分鐘maxPoolSize: 50 # 最大連接池大小50minPoolSize: 1 # 最小連接池大小1m1: # 第二個數據源標識dataSourceClassName: com.zaxxer.hikari.HikariDataSourceurl: jdbc:mysql://192.168.65.212:3306/shardingdb2?serverTimezone=UTC&useSSL=falseusername: rootpassword: rootconnectionTimeoutMilliseconds: 30000idleTimeoutMilliseconds: 60000maxLifetimeMilliseconds: 1800000maxPoolSize: 50minPoolSize: 1 -
那么為什么上一章不直接用這個 YAML 配置文件呢?因為 IDEA 沒有提示;
-
最后,這個配置文件,其實是和 ShardingSphere-Proxy 通用的;
3 ShardingSphere 的 SPI 擴展機制
3.1 從主鍵生成策略入手
-
SPI(Service Provider Interface)是 Java 提供的服務發現機制:允許第三方(或用戶)為接口提供實現類,框架能自動加載這些實現類,從而擴展功能;
-
一個完整的分庫分表方案,要配置的信息還是挺多的。我們要理解配置的各種策略是如何從 ShardingSphere 中擴展出來的,就要先找一個比較簡單的目標入手。這里,以主鍵生成策略為例,抽取 ShardingSphere 中重點源碼進行解讀:
package org.apache.shardingsphere.sharding.factory;@NoArgsConstructor(access = AccessLevel.PRIVATE) public final class KeyGenerateAlgorithmFactory {// 加載所有主鍵生成策略static {ShardingSphereServiceLoader.register(KeyGenerateAlgorithm.class);// 內部通過 Java 原生的 ServiceLoader.load() 方法,掃描并加載所有實現了 KeyGenerateAlgorithm 接口的類}// 獲取主鍵生成算法實例// newInstance 方法根據配置(如“類型 = SNOWFLAKE”),從加載的實現類中,創建對應的 KeyGenerateAlgorithm 實例public static KeyGenerateAlgorithm newInstance(final AlgorithmConfiguration keyGenerateAlgorithmConfig) {return ShardingSphereAlgorithmFactory.createAlgorithm(keyGenerateAlgorithmConfig, KeyGenerateAlgorithm.class);}// 判斷算法是否存在:contains 方法檢查“配置的算法類型(如 SNOWFLAKE)”是否有對應的實現類public static boolean contains(final String keyGenerateAlgorithmType) {return TypedSPIRegistry.findRegisteredService(KeyGenerateAlgorithm.class, keyGenerateAlgorithmType).isPresent();} } -
先來看主鍵生成策略是如何加載的:
ShardingSphereServiceLoader.register(KeyGenerateAlgorithm.class);/*** ShardingSphere服務加載器 - 基于Java SPI機制的服務發現和注冊類* 用于動態加載和緩存ShardingSphere的各種擴展實現*/ public final class ShardingSphereServiceLoader {// 使用線程安全的ConcurrentHashMap緩存所有已注冊的服務// Key: 服務接口的Class對象,Value: 該接口的所有實現類實例集合private static final Map<Class<?>, Collection<Object>> SERVICES = new ConcurrentHashMap<>();/*** 注冊指定服務接口的所有實現類* 使用Java SPI機制自動發現并加載META-INF/services目錄下的實現類* @param serviceInterface 要注冊的服務接口Class對象*/public static void register(final Class<?> serviceInterface) {// 雙重檢查鎖定模式:避免重復加載同一接口的實現類if (!SERVICES.containsKey(serviceInterface)) {// 如果該接口尚未注冊,則加載并緩存其所有實現類SERVICES.put(serviceInterface, load(serviceInterface));}}/*** 使用Java SPI機制加載指定接口的所有實現類實例* @param <T> 服務接口泛型類型* @param serviceInterface 要加載的服務接口Class對象* @return 包含所有實現類實例的集合*/private static <T> Collection<Object> load(final Class<T> serviceInterface) {Collection<Object> result = new LinkedList<>();// 使用ServiceLoader加載指定接口的所有實現類// ServiceLoader會自動掃描classpath中META-INF/services/目錄下的配置文件for (T each : ServiceLoader.load(serviceInterface)) {result.add(each); // 將每個實現類實例添加到結果集合中}return result;} } -
如果想自己寫一個主鍵生成算法(即
KeyGenerateAlgorithm的實現類),只需要通過 SPI 的方式讓 ShardingSphere 加載進去就行;-
先看看
KeyGenerateAlgorithm有哪些實現類,比如NanoIdKeyGenerateAlgorithm,它的源碼比較簡單:/*** NanoId分布式主鍵生成算法實現類* 實現ShardingSphere的KeyGenerateAlgorithm接口,提供基于NanoId的主鍵生成功能*/ public final class NanoIdKeyGenerateAlgorithm implements KeyGenerateAlgorithm {// 配置屬性對象,用于接收初始化參數private Properties props;/*** 默認無參構造函數*/public NanoIdKeyGenerateAlgorithm() {}/*** 初始化方法,在算法實例創建后調用* @param props 配置屬性,可以包含自定義參數(如:字母表、長度等)*/public void init(Properties props) {this.props = props; // 保存配置屬性供后續使用}/*** 生成分布式主鍵的核心方法* @return 返回生成的NanoId字符串作為主鍵*/public String generateKey() {// 使用NanoId工具類生成ID:// 1. ThreadLocalRandom.current(): 獲取當前線程的隨機數生成器(線程安全)// 2. NanoIdUtils.DEFAULT_ALPHABET: 使用默認字母表(大小寫字母+數字)// 3. 21: 生成ID的長度為21個字符return NanoIdUtils.randomNanoId(ThreadLocalRandom.current(), NanoIdUtils.DEFAULT_ALPHABET, 21);}/*** 獲取算法類型標識* @return 返回算法類型名稱"NANOID",用于配置文件中引用*/public String getType() {return "NANOID";}/*** 獲取配置屬性(自動生成的方法)* @return 返回當前算法的配置屬性*/@Generatedpublic Properties getProps() {return this.props;} } -
接下來仿照著自己實現一下:
/*** 自定義分布式主鍵生成算法實現類* 實現ShardingSphere的KeyGenerateAlgorithm接口,提供基于時間戳+序列號的主鍵生成方案*/ public class MyKeyGeneratorAlgorithm implements KeyGenerateAlgorithm {// 原子長整型計數器,用于生成序列號,保證線程安全private AtomicLong atom = new AtomicLong(0);// 配置屬性對象,用于接收初始化參數private Properties props;/*** 生成分布式主鍵的核心方法* @return 返回生成的Long類型主鍵,格式為:時間戳 + 序列號*/@Overridepublic Comparable<?> generateKey() {// 獲取當前時間LocalDateTime ldt = LocalDateTime.now();// 格式化時間為時分秒毫秒(HHmmssSSS格式,共8位數字)String timestampS = DateTimeFormatter.ofPattern("HHmmssSSS").format(ldt);// 組合時間戳和原子遞增的序列號,生成最終主鍵return Long.parseLong(""+timestampS+atom.incrementAndGet());}/*** 獲取配置屬性* @return 返回當前算法的配置屬性*/@Overridepublic Properties getProps() {return this.props;}/*** 獲取算法類型標識* @return 返回算法類型名稱"MYKEY",用于配置文件中引用*/public String getType() {return "MYKEY";}/*** 初始化方法,在算法實例創建后調用* @param props 配置屬性,可以包含自定義參數*/@Overridepublic void init(Properties props) {this.props = props;} } -
配置 SPI 擴展文件。在項目的
classpath/META-INF/services/(這個目錄是 Java 的 SPI 機制加載的固定目錄)目錄下,創建文件:-
文件名:接口的全限定名 →
org.apache.shardingsphere.sharding.spi.KeyGenerateAlgorithm; -
文件內容:自定義實現類的全限定名 →
com.nosy.shardingDemo.algorithm.MyKeyGenerateAlgorithm;
-
-
在 ShardingSphere 的配置中,指定主鍵生成策略的
type為自定義的標識:spring.shardingsphere.rules.sharding.key-generators.course_cid_alg.type=MYKEY -
這樣,ShardingSphere 就會通過 SPI 機制,加載并使用
MyKeyGenerateAlgorithm生成主鍵;
-
-
通過 SPI 機制,用戶可以不修改 ShardingSphere 源碼,就能擴展其功能(比如自定義分片算法、主鍵生成算法、加密算法等),讓框架更貼合業務需求。
3.2 嘗試擴展分片算法
-
在分庫分表場景中,ShardingSphere 提供了內置分片算法(如
MOD、INLINE等),但業務可能需要自定義分片邏輯(比如更復雜的路由規則)。此時,可通過 SPI 機制擴展分片算法; -
擴展分片算法的步驟
-
在上一章節
10.2 ShardingSphere-JDBC分庫分表實戰與講解的3.4 CLASS_BASED 自定義分片中實現了自定義分片,即MyComplexAlgorithm類。我們是通過 ShardingSphere 提供的 CLASS_BASED 類型的分片算法配置進去的。實際上,我們也可以使用 ShardingSphere 提供的 SPI 機制配置進去; -
在項目的
classpath/META-INF/services/目錄下,創建文件:- 文件名:接口的全限定名 →
org.apache.shardingsphere.sharding.spi.ShardingAlgorithm; - 文件內容:自定義分片算法類的全限定名 →
com.roy.shardingDemo.algorithm.MyComplexAlgorithm; - 這樣,ShardingSphere 啟動時會通過 SPI 機制,自動加載
MyComplexAlgorithm;
- 文件名:接口的全限定名 →
-
如果想要能夠被配置文件識別,在
MyComplexAlgorithm類中,增加實現getType()方法:public class MyComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {//……@Overridepublic String getType(){return "MYCOMPLEX";} } -
在 ShardingSphere 配置分庫分表策略時,指定這個我們自己的實現類:
spring.shardingsphere.rules.sharding.sharding-algorithms.course_tbl_alg.type=MYCOMPLEX
-
-
通過 SPI 機制,用戶可以不修改 ShardingSphere 源碼,就能自定義分片邏輯,讓框架適配更復雜的業務場景(比如按“多字段組合、特定業務規則”分片)。


![[Linux]學習筆記系列 -- lib/kfifo.c 內核FIFO實現(Kernel FIFO Implementation) 高效的無鎖字節流緩沖區](http://pic.xiahunao.cn/[Linux]學習筆記系列 -- lib/kfifo.c 內核FIFO實現(Kernel FIFO Implementation) 高效的無鎖字節流緩沖區)




—PyTorch使用(5)—張量形狀操作】)




)






