在人工智能浪潮的推動下, handwriting recognition(手寫識別)技術已成為連接傳統書寫與數字世界的重要橋梁。其中,漢字手寫體識別因其字符集的龐大和結構的復雜性,被視為模式識別領域最具挑戰性的任務之一。近年來,基于深度學習的技術成功突破了傳統方法的瓶頸,將漢字識別的準確率和實用性推向了新的高度。

工作原理:從像素到語義的智能映射
深度學習模型,特別是卷積神經網絡(CNN),是當前漢字手寫體識別的核心技術。其工作流程可概括為以下幾個步驟:
1.數據預處理:
- 圖像歸一化:將不同大小、分辨率和背景的手寫圖像調整為統一尺寸,并進行灰度化或二值化處理,以減少無關變量的干擾。
- 去噪與平滑:使用濾波器去除圖像中的噪點、劃痕,平滑筆畫邊緣,提升圖像質量。
- 校正:對書寫傾斜的圖像進行旋轉校正,使得文字處于水平位置。
2.特征提取(核心):
預處理后的圖像被送入CNN模型。CNN通過多層卷積層、池化層和激活函數,自動學習漢字的層次化特征。
- 底層特征:最初的卷積層捕捉筆畫邊緣、角點、端點等局部特征。
- 中層特征:中間層將底層特征組合成更復雜的結構,如橫、豎、撇、捺等基本筆畫組件。
- 高層特征:深層網絡最終將這些筆畫組件整合,形成能夠代表整個漢字或部首的抽象特征表示。這種自動學習特征的能力避免了傳統方法中復雜且依賴專家知識的手工特征設計。
3.分類識別:
- 提取到的高層特征被“展平”并輸入到全連接層。
- 最終,通過一個Softmax分類器輸出一個概率分布向量,向量的每一個維度對應一個候選漢字(如3755個一級國標漢字或更龐大的字符集)。概率最高的那個漢字即為模型的識別結果。
- 對于更復雜的序列(如整行文本),漢字手寫體識別通常會結合 CNN 與 循環神經網絡(RNN),形成 CRNN 模型,其中CNN負責提取視覺特征,RNN(常用LSTM或GRU)負責處理序列上下文關系,最后通過連接主義時間分類(CTC) 損失函數進行對齊和翻譯,實現高精度的整行識別。
技術難點與挑戰
盡管深度學習取得了巨大成功,但漢字手寫體識別依然面臨諸多挑戰:
- 類別數量極其龐大:與僅有幾十個類別的拉丁字母識別不同,漢字識別是一個超大規模的分類問題。常用漢字有數千個,而總字符集可達數萬個,這對模型的分類能力和計算資源提出了極高要求。
- 結構復雜,相似字多:許多漢字在結構上只有細微差別(如“己、已、巳”、“末、未”),模型必須能精準捕捉這些微小差異,對特征的判別性要求極高。
- 書寫風格多變:不同人的書寫風格千差萬別,包括筆畫粗細、傾斜度、連筆、簡寫等。同一人在不同時間、不同心境下的字跡也可能不同,要求模型具有強大的泛化能力。
- 數據采集與標注困難:要訓練一個高性能的深度學習模型,需要海量、高質量且標注準確的手寫漢字數據。大規模數據的采集、清洗和標注工作需要耗費巨大的人力物力。
- 脫機識別的固有難題:與“聯機識別”(可獲取筆序、筆壓等動態信息)相比,“脫機識別”僅有一張靜態圖像,丟失了大量動態信息,使得識別任務更加困難。
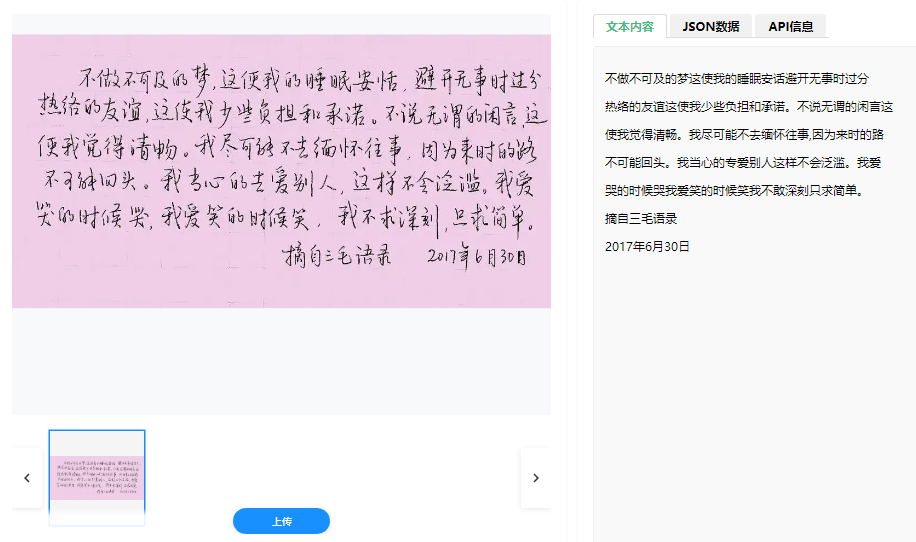
功能特點
基于深度學習的漢字手寫體識別技術展現出以下突出特點:
- 高精度與高魯棒性:在標準測試集上,對規整手寫體的識別準確率可達98%以上,甚至超過人類水平。對不同程度的噪聲、傾斜和光照變化具有較強的容錯能力。
- 強大的泛化能力:經過充分訓練的模型能夠較好地識別未曾見過的書寫風格,適應不同用戶的字跡。
- 端到端學習:無需人工設計特征,模型直接從原始像素輸入中學習并輸出結果,簡化了流程,提高了效率。
- 支持大規模字符集:能夠同時識別數千甚至上萬個漢字,滿足實際應用的需求。
- 多模態融合:可與自然語言處理(NLP)技術結合,利用語言模型(如N-gram、神經網絡語言模型)對識別結果進行后處理糾錯,根據上下文語境提升識別準確率。
應用領域
漢字手寫體識別技術的成熟為其在眾多領域開辟了廣闊的應用前景:
教育領域:
- 智能閱卷:自動批改作業和試卷中的主觀題、作文題,減輕教師負擔。
- 書法教學與評價:對學生的書寫筆跡進行分析,給出結構、筆勢等方面的改進建議。
- 在線學習:在手寫板或平板電腦上實時識別書寫內容,進行交互式教學。
金融服務:
- 銀行票據處理:自動識別和錄入支票、匯票、表單上的手寫金額、日期、簽名等信息。
辦公與政務自動化:
- 文檔數字化:將歷史檔案、手稿、紙質文件掃描并識別為可編輯的電子文本,便于存儲和檢索。
- 表單信息提取:自動處理各類調查問卷、申請表、報銷單等。
智能終端與人機交互:
- 移動設備輸入:在手機、平板等觸摸屏設備上提供流暢的手寫輸入法。
- 智能穿戴設備:在小屏幕設備上,手寫輸入是一種高效的交互方式。
文化傳承與研究:
- 古籍數字化:用于識別和數字化古代典籍、碑帖、書法作品,助力文化遺產的保護和研究。
基于深度學習的漢字手寫體識別技術已經取得了令人矚目的成就,但其研究遠未止步。未來的發展方向包括:探索更高效輕量的網絡模型以適應移動端部署;利用少樣本學習、自監督學習等技術降低對標注數據的依賴;提升對極端潦草字跡、古文字的識別能力;以及深化與NLP的結合,實現更深層次的“理解”而非僅僅是“識別”。隨著技術的不斷演進,手寫漢字識別必將更加無縫地融入我們的生活,進一步推動社會的智能化進程。


)





(數據鏈路層、ARP、以太網、交換機))










