前言
今25年9.13日,我在微博上寫道:
- “我們為何24年起聚焦具身開發呢
23年我們做了一系列大模型應用,發覺卷飛了,c端搞不過大廠的工程迭代 流量獲取,b端拼不過大廠的品牌,且大廠外 人人都可以搞
?然,具身不一樣,本體廠商忙于運控,學校側重科研,互聯網大廠還處于具身布局早期,而我司『七月在線』完全可以用1-2年的時間完成積累,加速推動科研到實際生產力的盡快落地?” - 故,加速推動具身前沿技術到實際生產力的落地,??算是我司『新的使命』了
畢竟工廠從自動化到智能化,是真真正正的新一輪工業革命,誰叫:?科學技術是當代第一生產力呢
總之,讓機器人(無論是機械臂還是人形)干好活,以不斷提高工業生產力,對我有著極大的吸引力,以及極高的成就感,故,我愿用我余生全力推動工業生產力的不斷提升
- 人形之外,對于機械臂 目前側重精密插拔、智能裝配,故對這方面的論文始終保持著高度的關注
- 加之過去半年多,我們已給三個集團客戶做了具身加油機器人的解決方案,和汽車充電器充電 有一定比例的相似性
故關注到了本文要解讀的TA-VLA
第一部分?TA-VLA:闡釋面向扭矩感知的視覺-語言-動作模型的設計空間
1.1 引言與相關工作
1.1.1 引言
如TA-VLA原論文所說,通過力覺線索理解物理交互對于掌握現實世界中的機器人操作至關重要。其中,關節力矩是一種極具信息量的信號,它能夠在無需外部力傳感器的情況下,反映末端執行器接觸動態的微妙變化[1,2,3]
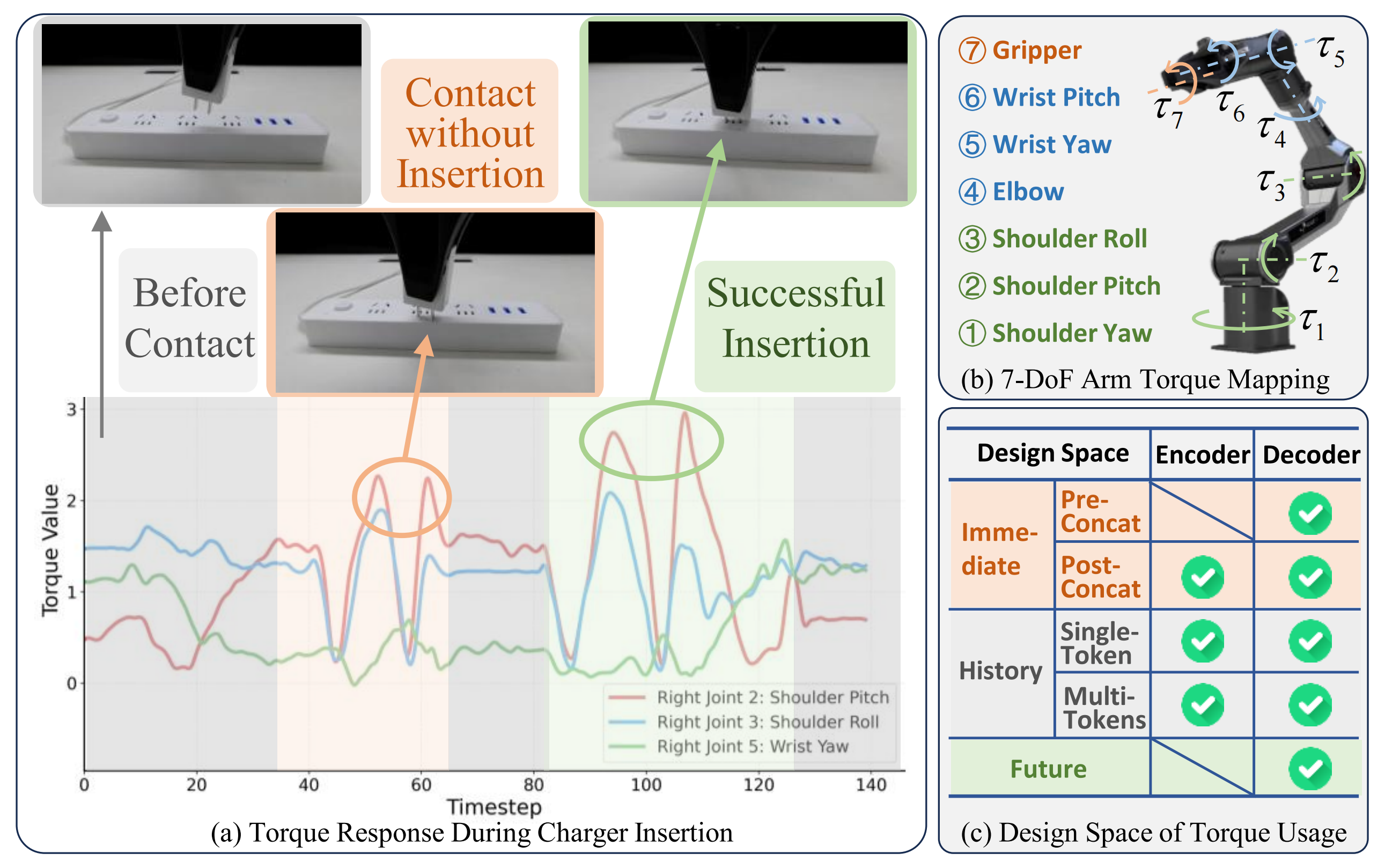
如圖1(a)所示,即使是在充電器插入這樣看似簡單的任務中——無接觸、插入失敗和成功插入——也可以通過7自由度機械臂的關節力矩曲線清晰區分。這些力矩響應提供了豐富的物理上下文信息,而僅憑RGB觀測是無法感知的
然而,盡管視覺-語言-動作(VLA)模型[4,5,6,7,8]在連接視覺與控制方面取得了顯著進展,但它們對這類物理反饋的理解和利用能力仍然有限
來自1 北京智源人工智能研究院BAAI?、2 清華大學人工智能產業研究院AIR、3 南洋理工大學的研究者期望通過將力矩信號集成到預訓練的VLA模型中,彌合這一差距,從而在不影響泛化性和可擴展性的前提下,實現對接觸敏感的決策
然挑戰在于如何將力矩嵌入到VLA架構中。力矩是一種本體感覺信號,其結構與圖像和語言輸入截然不同,且在時間上具有變化性,尤其在接觸豐富的階段更為明顯
如圖1(c)所示,力矩的集成策略可以在三個維度上展開——何時(即時、歷史或預測)、何處(編碼器或解碼器),以及如何(單一token與多token)。這些選項構成了一個廣泛的設計空間,但缺乏系統性的理解
- a)7自由度機械臂在充電器插入任務中的力矩響應
灰色陰影區域表示無接觸階段,此時力矩幾乎保持平穩
橙色高亮段表示一次插入失敗的嘗試——發生了接觸,但插頭未能插入插座,僅產生微小的力矩波動
綠色高亮段突出顯示了一次成功的插入,特征為插頭完全就位時出現的顯著大幅力矩峰值 - b)7自由度機器人機械臂的可視化,突出顯示關節力矩的映射關系
- c)本文探討的基于力矩特征的設計空間,涵蓋當前、歷史及未來信號
因此,作者的動機有兩方面:
- 確定對力矩感知的VLA模型最有效的設計選擇
- 總結可推廣的原則,以指導未來物理模態的集成
作者的第一個見解是,力矩信號應集成到解碼器中,而不是編碼器
- 通過HSIC分析[9]和消融實驗(第4.1節)驗證,這種在解碼器端的集成能夠在動作生成過程中,將力矩與其他本體感受信號(如關節角度)進行對齊
- 這樣的設計利用了解碼器對細粒度變化的更高敏感性——這一點在接觸豐富的場景中至關重要(例如,區分圖1(a)中插頭插入失敗與成功的情況)
作者的第二個發現是,歷史力矩信息比單幀輸入更具信息量
- 然而,注入多個token可能會干擾解碼器已學習的輸入模式。作者發現,將整個力矩歷史編碼為解碼器中的單一token(見圖4(c)),能夠在信息豐富性與架構穩定性之間取得平衡
即解碼端的單步力矩歷史能夠實現最佳的本體感知對齊與性能表現 - 這一設計選擇優于逐幀或在編碼器端集成歷史信息的方法(見第4.2節),從而實現了對接觸動力學的穩健時序建模,如圖7中插入和重試過程所示
作者的第三個見解是,預測未來的扭矩與動作同時進行,有助于構建具有物理基礎的潛在空間
- 受自動駕駛領域多任務架構的啟發[10],作者提出了一種統一的動作-扭矩擴散模型(詳見下文的第1.2.3節),該模型不僅允許策略執行動作,還能夠預測物理后果(參見下文圖6中的預測曲線)
即引入了統一的動作-力矩擴散模型,從而通過力矩預測實現前瞻性學習 - 這一輔助任務促使模型在觀察之外,進一步內化接觸動力學
最后,作者宣稱,他們通過在10項多樣化任務中的大量真實世界實驗驗證了他們的完整系統——其中包括5項接觸豐富、對力矩反饋至關重要的任務
- 其對應的paper地址為:TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models,其Submitted on 9 Sep 2025
其對應的 作者為
Zongzheng Zhang?1, Haobo Xu?2, Zhuo Yang?1,Chenghao Yue1,
Zehao Lin1, Huan-ang Gao1, Ziwei Wang3, Hao Zhao? 1,2 - 其對應的項目地址為:Torque-Aware-VLA.github.io
其對應的GitHub地址為:github.com/ZZongzheng0918/TA-VLA,待開源
且他們的最終模型(π0+obs+obj)在所有任務中相較于強大的VLA基線方法[11,7,6](見表5)均取得了持續的提升,并且在生成方面表現出色
1.1.2 相關工作
第一,對于視覺-語言-動作模型
- 近年來,大型語言模型(LLMs)[12,13,14,15] 和視覺-語言模型(VLMs)[16,17,18,19,20,21,22,23] 取得了顯著的成功,同時生成式模型也實現了如圖像生成等連續輸出[24,25,26,27]
這些技術為視覺-語言-動作(VLA)模型的出現奠定了基礎,該模型融合了視覺感知、語言理解與動作生成能力,并展現出極強的泛化能力,能夠利用數百萬條包含不同任務和設備的訓練數據樣本[28,29,30,31,32,33,34] - 近期關于VLA模型的研究可以根據動作生成方法分為幾種模式,包括基于擴散策略的模型[5,7]、基于流匹配的模型[6],以及自回歸生成模型[35,4,36]
例如
??Octo[5] 和 RDT-1B[7] 采用擴散頭和transformer主干網絡來預測動作
第二,對于基于力/力矩的模仿學習
- 盡管現有的大多數模仿學習研究主要利用關節位置和視覺信息 [6,8],但將力/力矩信息作為額外輸入的研究正日益受到關注。近期的研究表明,力/力矩信號能夠賦予控制策略處理各種現實世界任務的能力,包括精細且高精度的操作 [38,39,40,41,42,43]
- 從力/力矩信息的來源來看,大多數方法依賴額外的傳感器獲取六維扭矩測量數據[44,45,46,47,43],這導致了更高的經濟成本,并在惡劣操作環境下存在局限
From the perspective of sourcesof force/torque, most approaches rely on additional sensors to obtain 6D wrench measurements[44, 45, 46, 47, 43], which leads to higher economic costs and limitations in harsh operating con-ditions.
此外,盡管有部分工作嘗試將力/力矩信息與視覺和文本輸入結合,但它們通常從零開始訓練策略,未能充分利用預訓練VLA模型的優勢[48,49,50,51]。例如,FACTR [52] 需要復雜的訓練流程來對齊不同模態,且缺乏靈活性 - 相比之下,將力模態引入預訓練VLA模型具有兩大優勢:
1)VLA模型已經在大規模數據集上訓練,具備強大的跨模態學習基礎,因此集成新的模態更加容易;
2)VLA模型通常能夠學習跨模態的共享特征表示,從而更高效地適應新模態
在本工作中,作者系統性地探索了如何將力信息融入預訓練VLA模型,使其能夠作為世界模型,通過對歷史、當前和未來狀態下視覺、力和指令的統一理解,實現對環境的準確感知與預測
1.1.3?扭矩是末端執行器狀態的良好指示器
在機器人操作中,末端執行器的外部接觸會在整個運動鏈中引發機械響應。這些響應表現為關節扭矩的可觀測變化
本節中,作者將通過機械臂的微分運動學和動力學,形式化地說明關節扭矩信號如何編碼接觸力信息
- 公式化表述
假設機械臂具有個自由度,其關節配置向量為
,在存在外部接觸的情況下,整體動力學方程為:
其中,其中表示指令扭矩,τ_ext∈R^n 表示由于末端執行器受到外部力而產生的扭矩分量。M(q)∈R^{n×n} 為慣性矩陣,C(q,˙q)∈Rn×n是科里奧利力和離心力矩陣,G(q)∈Rn是重力力矩向量。其中,˙q∈Rn為關節角速度向量,¨q∈Rn為關節角加速度向量
- 映射
假設末端執行器與剛性環境接觸,并受到空間力(力矩),記為
鑒于虛擬末端執行器位移與關節位移的關系為,得到公式2
其中,為雅可比矩陣,它將末端執行器空間的速度映射到關節空間
該方程具有基礎性意義:它表明,作用在末端執行器上的任何外力都通過雅可比矩陣的轉置被投影回關節空間
因此,當發生接觸事件(例如機器人觸碰到某個表面)時,所產生的力矩信號可以分解為:
這里,是觀測到的關節力矩,
則表示由于內部動力學產生的預期力矩
該表達式表明,只要機械臂的動力學建模足夠精確,通過觀測關節力矩的變化,就能夠推斷作用于末端執行器上的凈外部力矩 - 結論
關節力矩向量
1.2 從感知過去(將力矩作為觀測量)到預測未來(以力矩為目標)
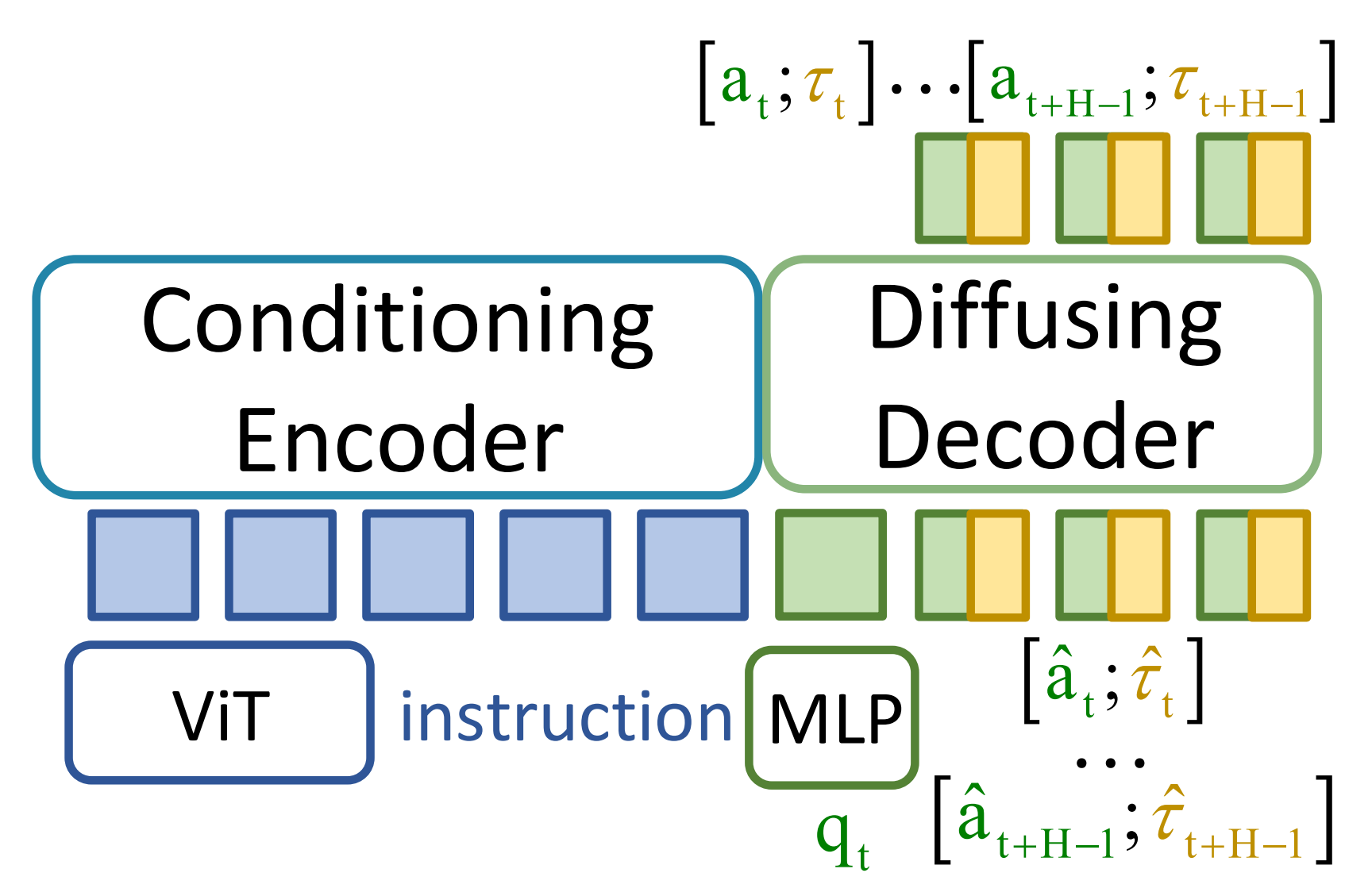
在本節中,作者將力矩信號作為額外的觀測量整合到VLA框架中,并探究其影響。大多數VLA模型主要由兩個核心組件組成:條件編碼器和去噪解碼器,本文中分別簡稱為編碼器和解碼器
- 編碼器用于感知環境
具體來說,編碼器將圖像輸入?和語言指令
?處理為統一的潛在空間,以構建上下文表示,
- 而解碼器則輸出動作
解碼器對噪聲輸入進行逐步細化,在
時生成動作序列。例如,RDT [7] 通過對視覺和語言特征進行交叉注意力來構建條件,并采用一個在低維本體感受輸入和噪聲動作片段上運行的去噪主干網絡
類似地,π0[6]利用 PaliGemma [53] 主干網絡融合視覺與語言輸入,隨后通過動作解碼器進行處理
以π0為代表性案例,作者通過以下問題探索將力矩作為輸入的設計空間:
- 應將力矩信號引入條件編碼器還是去噪解碼器
- 如何利用歷史力矩信號
1.2.1?嵌入位置選擇?條件編碼器與去噪解碼器
在每個時間步,策略π0會觀察多個RGB圖像、一條文本指令以及機器人的關節角狀態,記作,其中
為第i張圖像,
是語言標記序列,
是當前的機器人狀態向量
在原始π0架構中,圖像特征與
?一起構成條件上下文,而
作為一個token提供給去噪模塊
關于將扭矩信號集成到VLA架構中,作者探索了兩種集成方式:
- 一是將
?集成到編碼器的輸入中,以利用其多模態能力
- 二是將
一起集成到解碼器中,以豐富狀態表示
具體而言,作者評估了三種嵌入?的可能策略(見圖2):
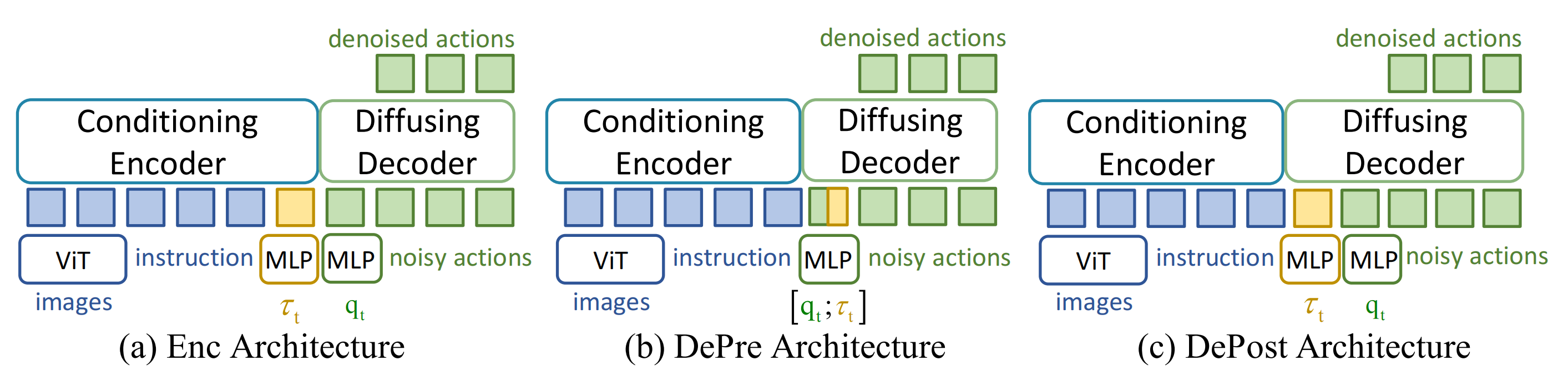
- 編碼器嵌入(Enc):通過適配器將
拼接,作為額外的條件輸入(見圖2(a))
- 解碼器預拼接嵌入(DePre):將
- 解碼器后級拼接嵌入(DePost):通過適配器對
具體來說,作者采用MLP作為力矩適配器。且在兩個涉及大量接觸的真實任務中,使用三種不同的架構進行了實驗
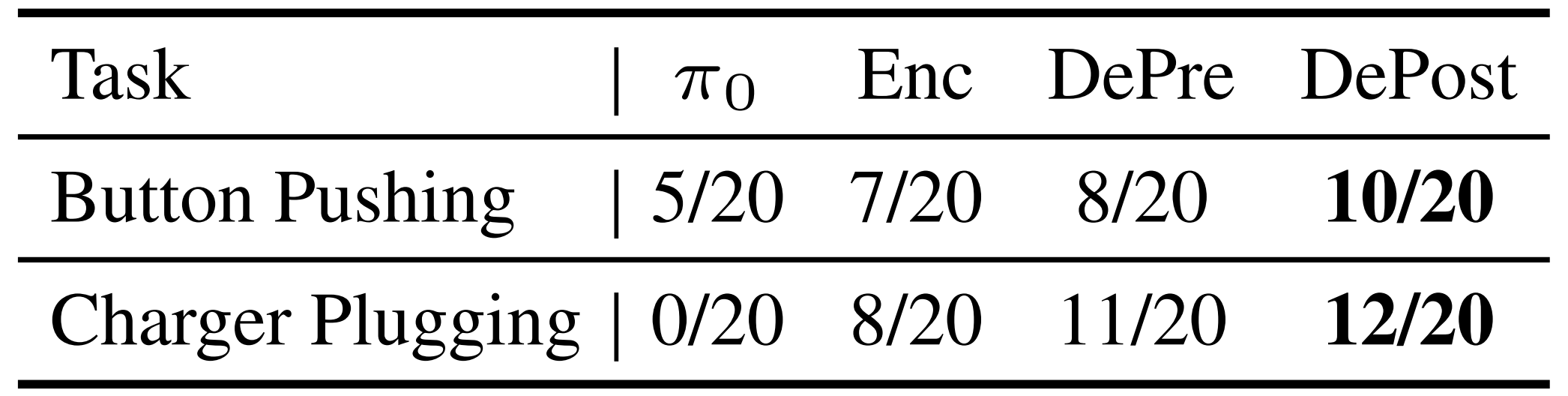
結果如表1所示「不同架構在嵌入扭矩信號方面的結果」,表明將力矩信號嵌入解碼器優于嵌入編碼器,并且將其嵌入為單一token優于將其集成到原始本體感覺狀態token中
關于架構對比的實驗
- 對于Enc和DePost架構(見圖2(a)(c)),作者隨機初始化一個MLP,用于將effort token投影到潛在空間
該MLP的結構為:
首先將輸入維度為14(effort維度)映射到2×width,然后經過Swish激活函數,再映射到width
這里的width指的是模型的內部維度:在Enc架構的條件編碼器中為2048,在DePost架構的擴散解碼器中為1024- π0的狀態輸入由14維的關節位置組成,后接18維的零填充。對于DePre架構(見圖2(b)),作者將14維的關節effort放在這個32維狀態的最后14個位置
該結果的原因可總結如下
- 更優的輸入對齊
將力矩信號
為驗證這一點,作者進行了實驗,評估輸入(以及動作)的高維特征之間的歸一化Hilbert-Schmidt獨立性準則(HSIC)[9]值,以衡量它們的相似性
圖3顯示了——來自不同模態輸入標記的隱藏狀態的歸一化HSIC值,力矩信息(torque information)與關節角度信號(joint angle signals)之間的對齊性顯著更高「Figure 3 shows that torque information is significantly more aligned with joint angle signals.」
因此,力矩信號應集成在解碼器中,以更好地增強本體感覺感知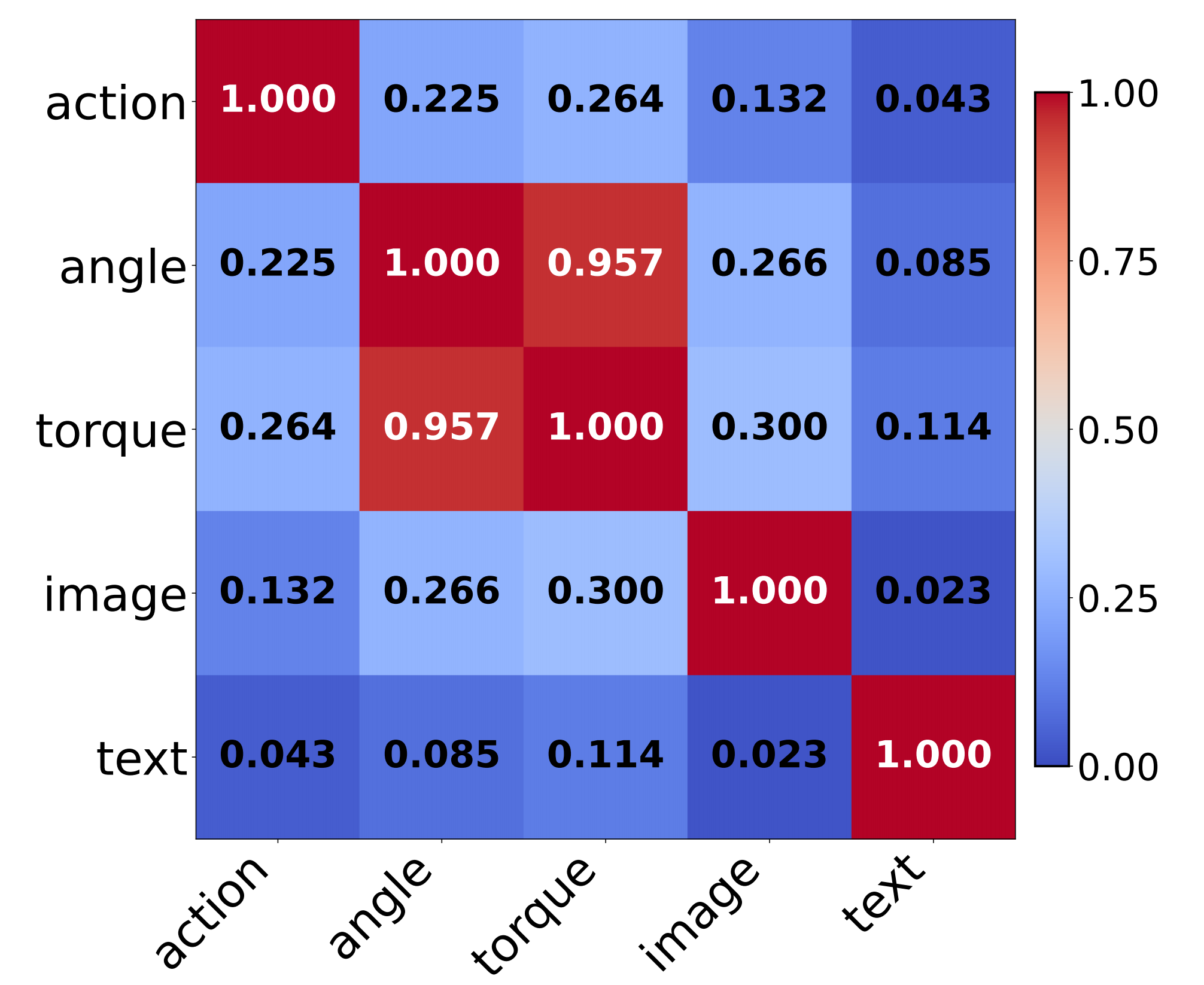
————
為了進一步解釋,如附錄A.3所說,HSIC是一種強大的非參數度量方法,能夠在不對變量分布作出假設的情況下,檢測變量之間復雜的非線性關系。歸一化HSIC的取值范圍為0到1,數值越高表示更強的統計依賴性
為了評估模態對齊情況,作者分析了在 Button Pushing 任務中,使用 DePost 方法訓練的 π0 模型
- 解碼器的敏感性
編碼器針對多樣且模糊的視覺-語言輸入而設計,主要處理較粗粒度的特征;而解碼器則旨在捕捉輸入中的細微變化
為驗證這一點,作者分別向編碼器和解碼器的每個輸入token添加隨機噪聲,并評估其性能。表2顯示「帶有隨機噪聲的編碼器和解碼器結果」
在噪聲影響下,解碼器的性能下降更為明顯,表明解碼器對輸入變化更加敏感;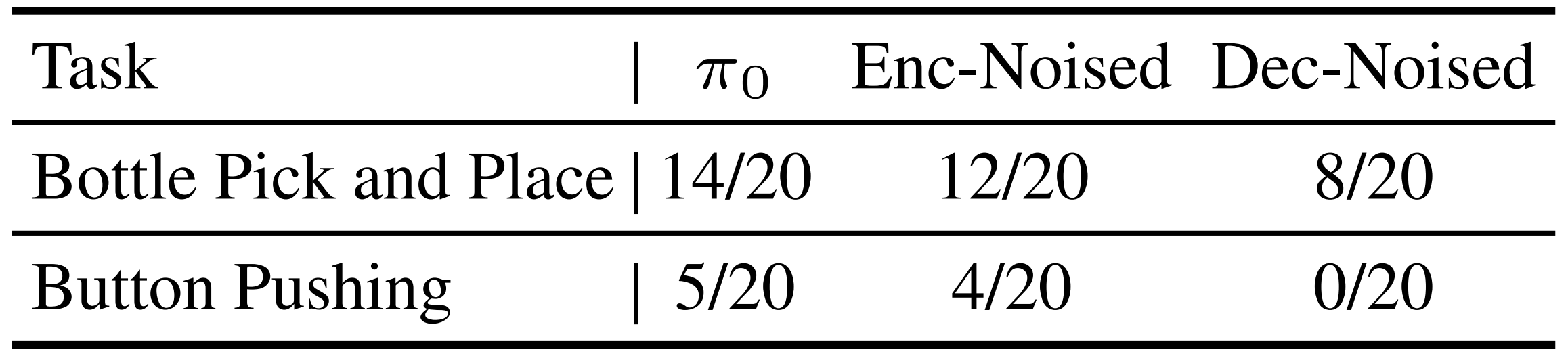
因此,引入
此外,前拼接(Pre-Concatenation)方法會顯著改變原始輸入token,相當于引入了額外噪聲,導致其性能較后拼接(Post-Concatenation)方法更差
——————
總之,如附錄A.3所示,為了評估編碼器和解碼器對輸入變化的敏感性,作者在輸入token中加入了標準差為0.1的高斯加性噪聲
對于編碼器,噪聲被添加到所有輸入token上;而對于解碼器,噪聲則專門添加到狀態token(即輸入序列中的第一個token)上。實驗結果見表2
1.2.2 將力矩作為觀測量:扭矩歷史優于單幀
與固定的語言指令和相對穩定的視覺觀測不同——這些在末端執行器接觸后由于遮擋而幾乎沒有變化——如圖1所示,力矩信號在接觸時會發生顯著變化
為了捕捉力矩的動態變化,僅依賴單幀力矩輸入是不夠的。對力矩信號的歷史進行編碼,可以為VLA模型提供更豐富的物理交互模式,從而在高接觸任務中實現更優的性能
為了研究編碼力矩歷史的最佳方式,作者探索了兩種策略:
- 逐幀分詞,將每一幀的力矩
分別作為獨立的token進行編碼
- 整體分詞,將整個歷史
編碼為單一token
為保證全面性,作者還考察了歷史力矩信號應插入到編碼器(圖4(a)-(b))還是解碼器(圖4(c)-(d))中
如原論文『A.4 針對第4.2節的實驗協議:力矩歷史編碼』所述,關于架構對比的實驗
- 對于歷史力輸入,作者從過去2秒內均勻采樣了10幀數據,包括當前幀
在H Tokens配置中,每個14維的力輸入token都通過與附錄A.3所述相同結構的MLP獨立處理,并被投影到潛在空間- 相反,在1 Token配置下,所有10幀的歷史力輸入會被展平并拼接成一個140維的token,然后輸入到MLP中
結果如表3所示,表明將整個力矩歷史作為單一token輸入解碼器是最佳選擇
其原因如下
- 輸入模式完整性
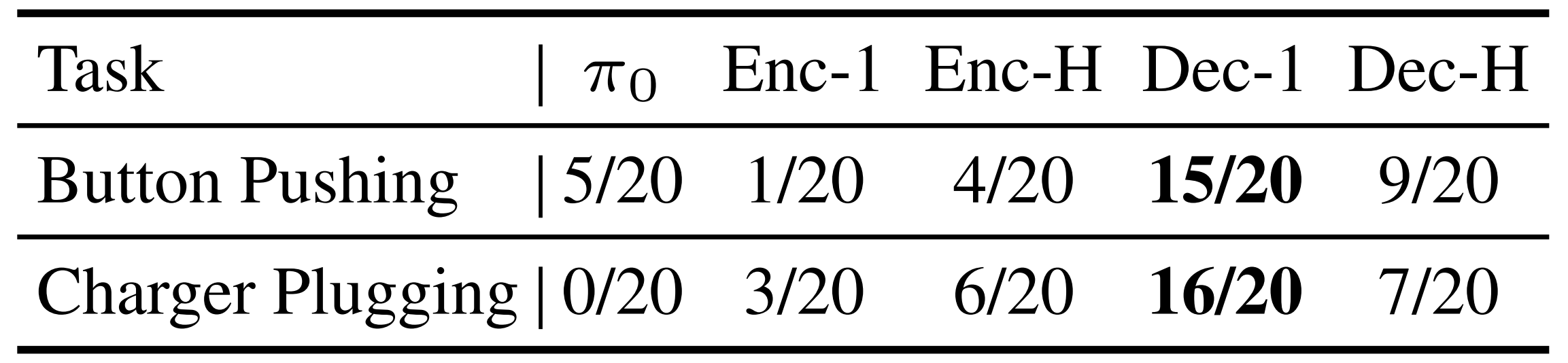
聚合式分詞優于逐幀分詞,因為大量歷史分詞會破壞解碼器原有的輸入模式完整性。為驗證該假設,作者分別向編碼器和解碼器添加額外的噪聲分詞
如表4所示添加的噪聲分詞很容易干擾解碼器的感知能力。這一現象在添加額外的力矩歷史分詞時同樣存在,可能會干擾解碼器在預訓練期間學到的模式
因此,即使減少歷史分詞可能導致信息損失,破壞解碼器狀態模式的影響在權衡中占主導地位- 此外,如表4所示,編碼器對輸入模式變化表現出較強的魯棒性,并且在包含更多信息的多歷史分詞條件下表現更佳。然而,正如第4.1節所述,對力矩信號進行編碼有助于本體感知對齊和更細粒度的感知;因此,向解碼器提供單一的歷史信息分詞優于其他方法
總之,為研究輸入模式的完整性,作者在輸入的token 序列中引入了一個額外的 token。該 token 從標準正態分布中采樣,并與序列中的其他 token 具有相同的形狀
隨后,作者相應地修改了輸入和自回歸掩碼,按照對 effort token 所采用的掩碼模式,將這一新 token 融入序列處理流程。實驗結果如表4所示

1.2.3?以力矩為目標:預測未來
第一,動機
目前的VLA策略僅將模態視為觀測值,未能充分利用機器人自身的交互動力學。受自動駕駛多任務規劃[10]的啟發,以及作者在上文(原文第4節)中發現力矩信息是強有力的本體感知線索,作者提出預測未來力矩與未來動作相結合的方法
該輔助任務促使模型建立一種在物理上有依據的潛在空間,從而實現更可靠的豐富接觸操作
第二,動作-力矩擴散的統一損失
接下來詳細描述如何訓練模型以同時預測動作和力矩,在保持各自損失獨立的同時,共享擴散權重以提升效率
- 設
表示動作片段
表示力矩片段
- 干凈的關節token可表示為
作者采樣高斯噪聲和時間步
,從而形成帶噪輸入
即如原論文「A.5 聯合動作-力矩擴散目標的實現」所述,為了使模型能夠在進行動作預測的同時輸出未來的力矩(用于監督),作者擴展了原始模型的動作輸入和輸出投影線性層的維度(見圖5)
- 在加載預訓練權重時,作者用預訓練的參數對修改后權重矩陣中原動作輸出維度對應的部分進行了初始化。對于新增的用于未來力矩預測的維度,其權重則采用較小的值進行初始化
- 這種初始化策略旨在初始階段對原有預訓練行為的影響最小化,從而使模型能夠在微調過程中逐步學習新的預測任務。預測的未來力矩序列長度為H=50步,與動作塊的長度一致
為確保動作和力矩預測均保持良好校準,作者定義了兩個均方誤差目標:
其中和
分別表示模型輸出中的動作分量和力矩分量,
、
分別為對應的噪聲切片
然而,與常見方法通過獨立模塊或共享權重并采用不同投影頭來預測多種類型輸出不同,為了節省成本并充分利用預訓練權重,作者采用了單一線性層,直接輸出動作和力矩的拼接預測,然后再將其拆分,用于各自的損失計算
即最終采用兩種損失的組合:,其中
是用于平衡動作保真度與力矩精度的權重因子
順帶提前說一嘴,在下文的實驗(表5)中
- 對于+obj設置,作者將β的值設為1
- 對于+obs+obj設置,作者將β的值設為0.1
- 對于ACT和RDT模型,它們的推理動作范圍分別為8步和64步
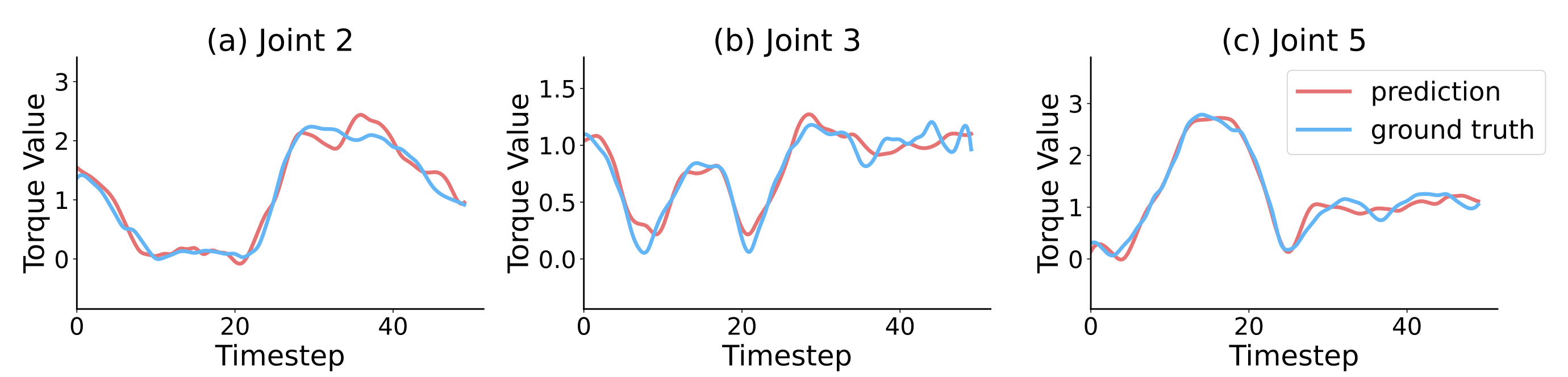
為了評估基于動作-力矩擴散方法預測的各關節未來力矩的精度,作者將其與驗證數據中的真實值進行對比
- 如圖6所示「圖6展示了在ButtonPushing任務上訓練得到的模型的推理示例。該圖將模型對每一幀預測的未來力矩與對應的三條選定軸的真實值進行了對比,輸入為從該任務驗證數據中采樣的觀測幀」
預測的力矩高度符合真實變化,這表明通過所提出的關節擴散方法,模型能夠有效感知未來的變化
這一能力將進一步使模型能夠產生更優的動作,因為關節力矩-動作預測策略通過學習動作與由此產生的力矩響應之間的因果關系,加強了模型對接觸動力學的理解- 總之,通過學習統一的動作-力矩表征,模型能夠將本體感覺信號與預期的運動指令對齊,從而提升在高接觸場景下的表現
1.3 實驗
1.3.1 實驗設置
- 對于硬件平臺
作者使用 Cobot Magic ALOHA,這是一款每只手臂具有 7 個自由度的雙臂機器人。該機器人配備了三臺 D435 深度相機:兩臺安裝在手腕上,一臺面向前方
關節力矩由機器人電機的電流推算得出。每個電機都有一個特定的電流-力矩常數,該常數將電流?
?與產生的力矩
關聯起來,計算公式為
如此,通過測量供給每個電機的電流,可以在無需外部力傳感器的情況下,實時準確地估算關節力矩 - 對于基線方法
作者與機器人操作領域的強基線方法進行對比評估:ACT [11]、RDT [7] 和 π0[6]。所有模型均在相同實驗設置下,基于作者收集的數據集,從公開可用的預訓練權重進行微調
ACT 利用基于 Transformer 的動作分塊機制,而 RDT 和 π0 是兩種在跨任務表現優異的最新 VLA 模型
原論文附錄A6.1相似說明了實驗設置
- 在π0實驗中,作者遵循了原始設置,使用來自三個視角的圖像作為輸入:頂部、左手腕和右手腕
所有π0實驗均基于其公開可用的預訓練檢查點,并采用LoRA對編碼器和解碼器進行了微調
訓練在4塊NVIDIA L20 GPU上進行了30,000步的梯度更新- RDT實驗采用相同的GPU配置,進行了40,000步的全參數訓練
對于ACT,作者使用了600個訓練周期,每個數據塊大小為32所有基線模型均采用AdamW優化器。推理則是在RTX 4090 GPU上進行的。所有π0的變體均采用了50步的推理行動視野,RDT則使用了64步。其他設置與原始實現保持一致。對于所有任務,均通過遠程操作收集了400個演示樣本
1.3.2 定量結果與可視化
作者對基線模型以及多種將力矩信號融入π0的方法進行了評估。具體而言,作者采用了
- 上文第1.2.2節中的DePost-1 Token架構,將當前和歷史的力矩觀測嵌入,記為π0+obs
- 上文第1.2.3節中的統一訓練目標,記為π0+obj
- 以及兩者的組合,記為π0+obs+obj
作者在10個真實世界任務中進行了實驗——包括5個高接觸任務和5個常規任務
- 表5中的結果顯示
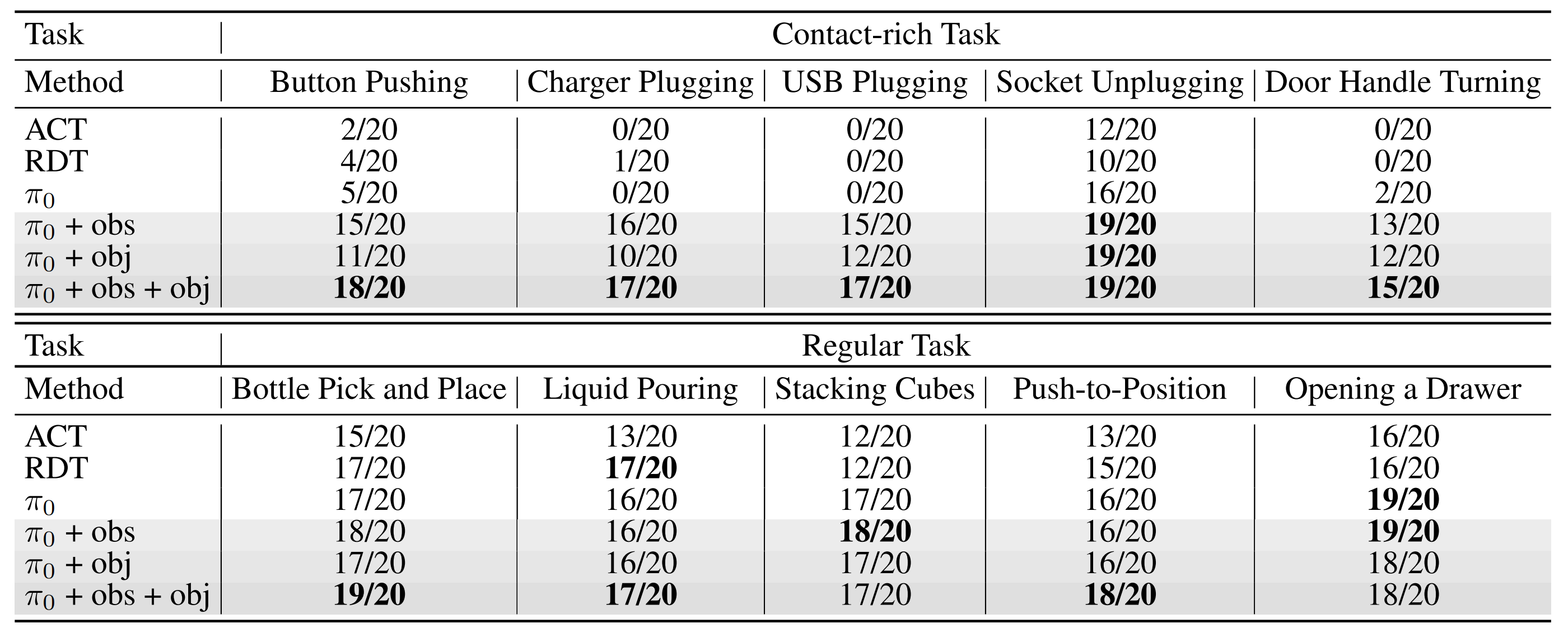
無論是力矩觀測(π0+obs),還是基于力矩的目標(π0+obj)都能提升VLA模型的性能,而兩者結合的方法兼具各自優勢(π0+obs+obj),取得了整體最佳表現 - 此外,力矩信號不僅提升了高接觸任務的表現,也改善了在力矩相關性較低任務中的效果,表明其在多樣化場景下的實用性
且作者對所提出方法能夠完成的部分高接觸性任務和常規任務進行了可視化
- 關于高接觸性任務,如圖7所示

- 此外,依靠力矩信號,機器人還能以高精度完成多種常規任務(見圖7(c))
1.3.3?跨模型
為了評估力矩觀測和基于力矩目標在不同VLA模型中的泛化能力,作者在RDT [7] 上對接觸豐富和常規任務進行了實驗
如表6所示,同時結合力矩觀測和基于力矩的目標可以顯著提升性能
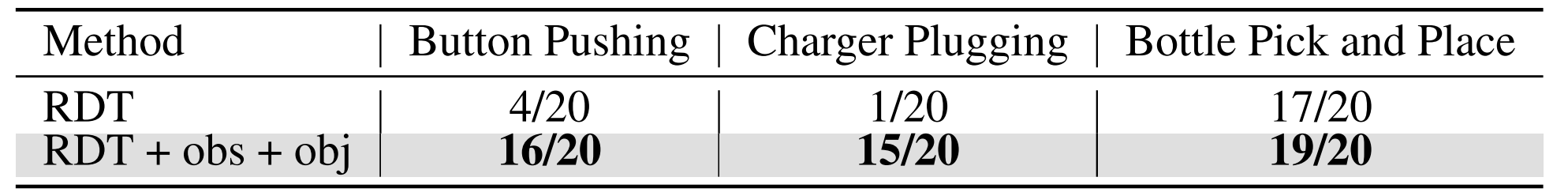
這些結果表明,上文1.2.2節(對應于原論文第4節)和上文1.2.3節(對應于原論文第5節)提出的力矩集成策略能夠很好地推廣到其他VLA模型
如原論文「A.6.3 關于跨模型結果的詳細信息」所述
關于RDT+obs+obj模型(見圖11,表6)
- 作者按照該模型對語言和圖像適配器的處理方式,將effort projector實現為一個包含單個GELU激活函數的兩層MLP。該MLP將effort輸入映射為2048維向量,以匹配RDT變換器主干的寬度
- 投影后的effort token隨后連接在state token之后。該組合序列再與noisy actiontoken拼接,形成RDT去噪過程的輸入
且作者擴展了狀態空間的輸入和輸出投影器,并以與π0類似的方式加載了預訓練權重
1.3.4?跨形態
為了評估他們方法在不同機器人結構上的泛化能力,作者在ROKAE SR機械臂上進行了實驗。如圖8所示,機器人執行電動汽車充電器插入任務

在利用力矩反饋檢測到插入失敗后「見圖8(a」,機器人在第二次嘗試時成功完成了任務「見圖8(b)」
如原論文「A.6.4 跨實體結果的詳細信息」所述
為了進一步評估他們具備扭矩感知能力的VLA模型在不同機器人實體上的泛化能力,作者使用ROKAE SR機械臂進行了跨實體實驗
- 具體來說,作者使用200次演示訓練了π0+obs+obj模型,演示內容為機器人將快充連接器插入充電口,并利用扭矩反饋引導插入過程。該模型經過5萬次梯度訓練,如圖12(a)所示,成功且高可靠性地完成了快速充電插入任務
- 為了進一步評估其泛化能力,作者將任務設置中的快速充電接口更換為慢速充電接口。在不做任何架構修改的情況下,模型能夠無縫適應,成功地將慢速充電連接器插入端口,如圖12(b)所示
作者宣稱,該結果凸顯了模型將感知扭矩的操作策略泛化到新末端執行器配置的能力,展示了其在不同設備間的強大泛化性能
1.4 結論與局限性
1.4.1 結論
在本文中,作者將關節力矩作為末端執行器狀態的有效指標進行分析,并探討如何將其最佳地融入VLA模型
他們的研究發現,將即時和歷史力矩編碼為單一解碼器token能夠取得最佳效果。此外,通過統一擴散損失聯合預測動作和力矩,能夠提升模型性能
總之,在包含豐富接觸和常規任務的實驗中,基于力矩的增強方法的有效性和泛化能力得到了驗證
1.4.2 局限性
該方法依賴于通過電機內部電流進行的精確扭矩估算。然而,這種估算可能會受到電機校準、傳感器噪聲或熱漂移的影響,從而在長時間或高負載任務中導致性能下降
此外,雖然扭矩信號被證明具有重要價值,但該框架在擴展到其他物理模態(如觸覺感知或溫度)時的可擴展性仍不明確,尤其是在transformer架構中共享token預算的情況下
因此,未來工作需要在更加多樣化、真實的場景中評估其魯棒性,并進一步探索更豐富多模態信號的對齊與集成
// 待更





(數據鏈路層、ARP、以太網、交換機))













