本文為您介紹,如何逐步設計一個基于Redis的高可用緩存。
目錄
業務背景
步驟一:寫一個最簡單的緩存設計
存在的問題:大量冷數據占據Redis內存
解決思路:讓緩存自主釋放
步驟二:為緩存設置超時時間
存在的問題:熱點緩存也會失效
解決思路:為熱點緩存續命
步驟三:數據查詢緩存后,重新設置緩存過期時間,為其續命
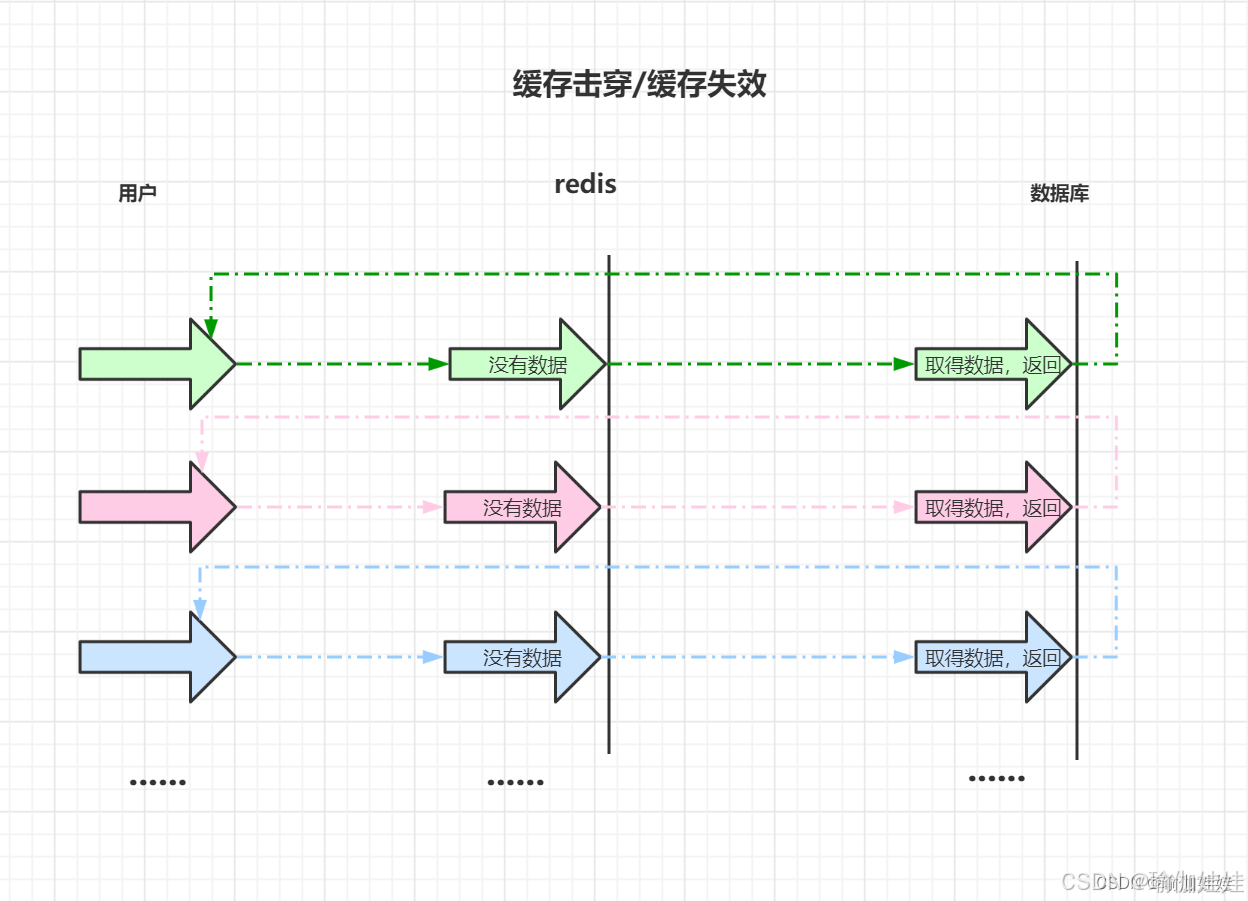
存在的問題:緩存擊穿/緩存失效
解決思路:如何保證緩存不同一時間失效
步驟四:為緩存設置不一樣的失效時間?編輯
存在的問題:緩存穿透
解決思路:攔截查詢不存在數據請求,禁止直擊數據庫
步驟五:為不存在的數據創建空緩存并為其指定過期時間,并對重復請求的空緩存續命?編輯
存在的問題:冷數據突變熱數據,導致眾多獲取冷數據的請求直接打在了數據庫
解決思路:只讓一個查詢冷數據的請求查詢數據庫并為其創建緩存,其他請求查緩存
總結:上述鎖已經能解決99%的問題,但是還存在一定缺陷
業務背景
本文將以如何查詢,更改個商品的為例,講述高并發下,如何設計一個高并發緩存。
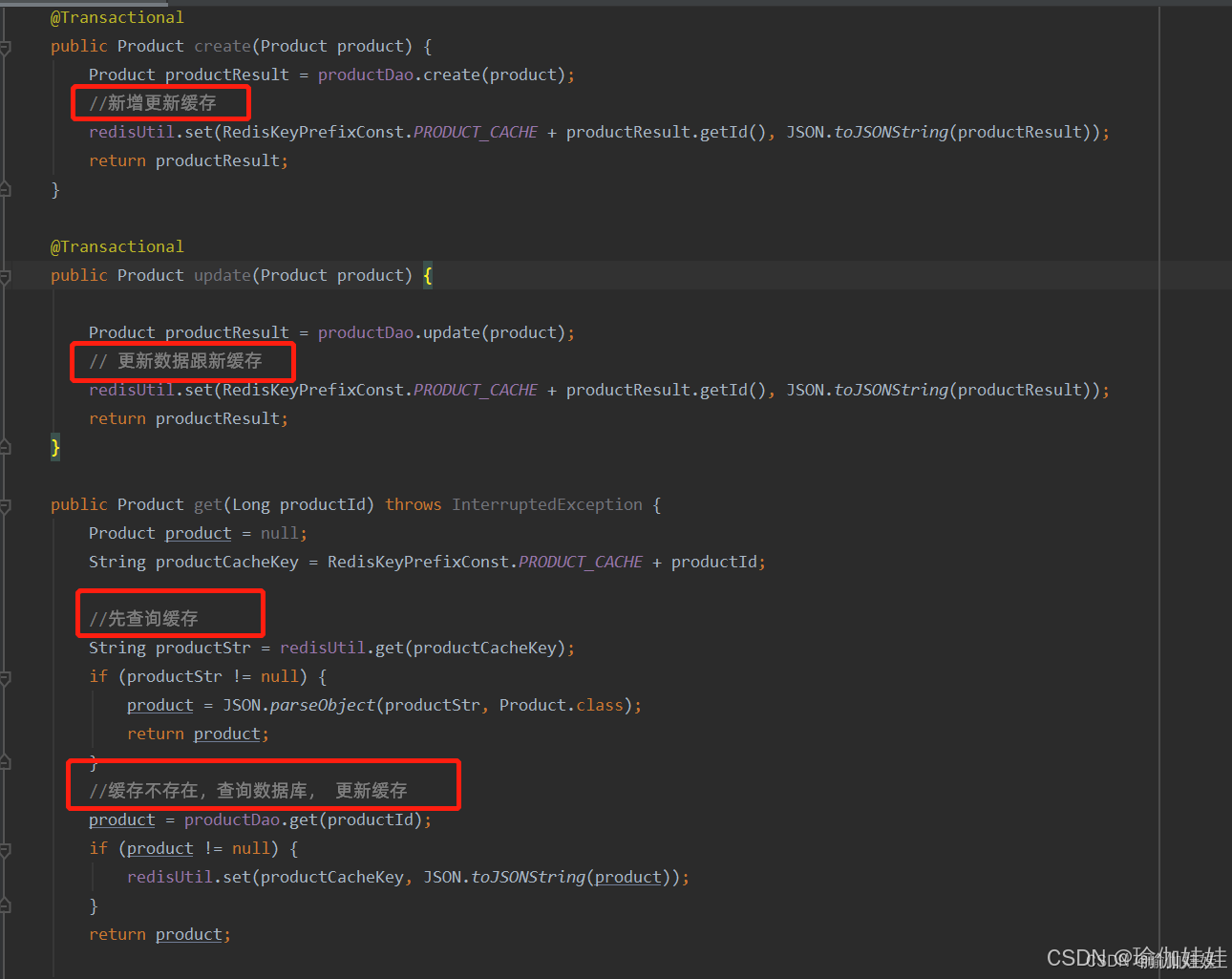
步驟一:寫一個最簡單的緩存設計
以下代碼是常見的最簡單的redis緩存的設計:
- 新增、更改數據時,更新緩存。
- 查詢時,先查詢緩存。
- 緩存存在,直接返回。
- 緩存不存在,查詢數據庫,且更新緩存數據。
存在的問題:大量冷數據占據Redis內存
在數據少,壓力小,并發小的情況下,這個設計似乎沒有什么大問題,但是在數據量大,高并發的情況下,卻會有不少問題。
例如系統有上億數據,但是用戶經常訪問的數據,只有幾百萬數據,那么大量冷數據常駐Redis內存,造成redis內存浪費。
解決思路:讓緩存自主釋放
既然這個數據在一段時間內無人問津,那么是不是可以根據一定規則,讓緩存自主失效就可以了?那么為緩存設計一個失效時間就可以了?
步驟二:為緩存設置超時時間
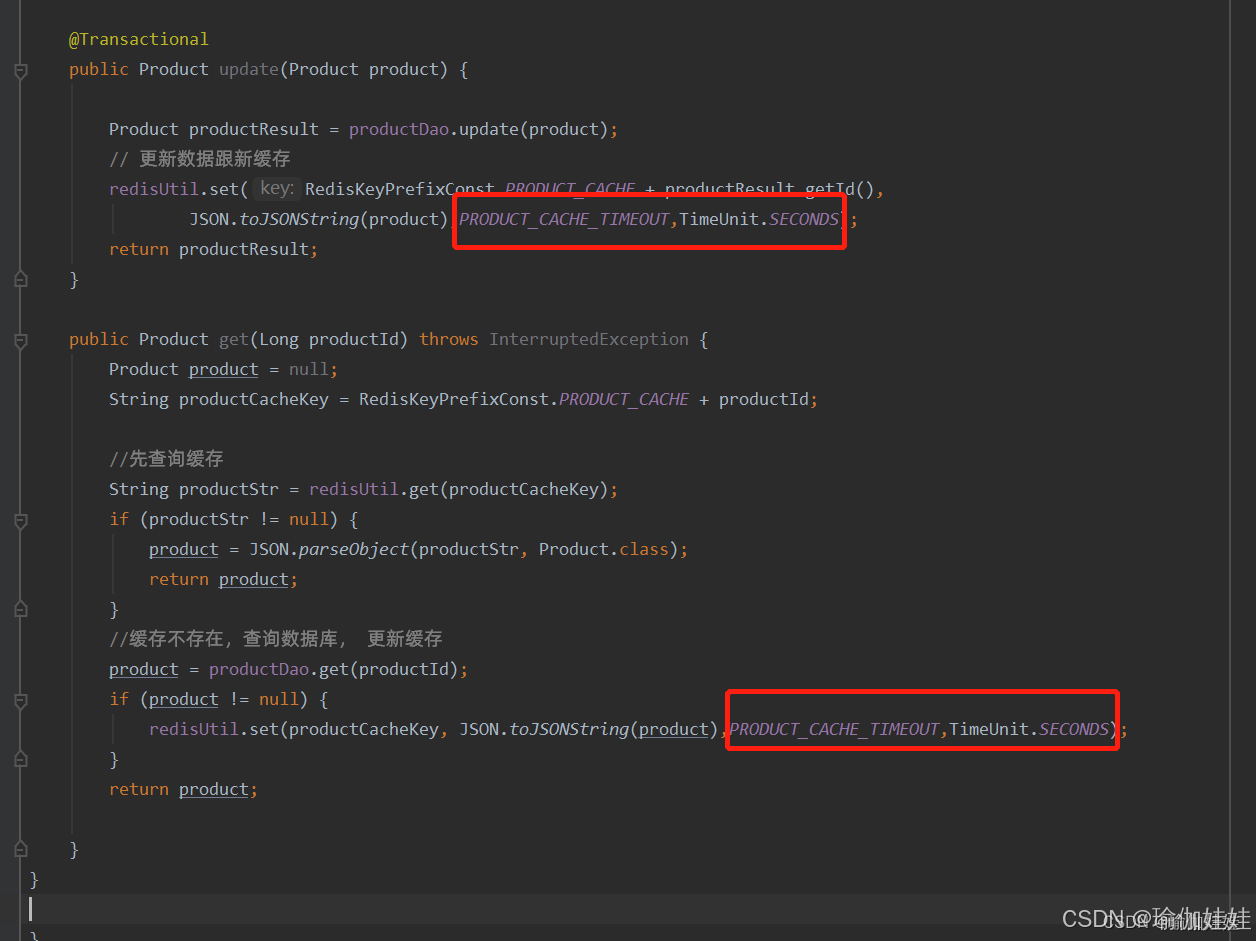
存在的問題:熱點緩存也會失效
在為緩存設置超時時間后,那么熱點數據的緩存,在該設置的時間內,也會失效,那么緩存失效后,大量請求查詢無緩存后,都會請求到數據庫,這樣會造成數據庫的壓力增大。
解決思路:為熱點緩存續命
如何在緩存設置了失效時間后,只是讓冷數據失效,熱數據不失效呢?此時您有沒有想到為熱點數據的緩存續命的方法嗎?那就每次請求查詢緩存后,為該緩存重新設置緩存失效時間,延長其失效時間,這樣是不是就為其續命了呢?
步驟三:數據查詢緩存后,重新設置緩存過期時間,為其續命
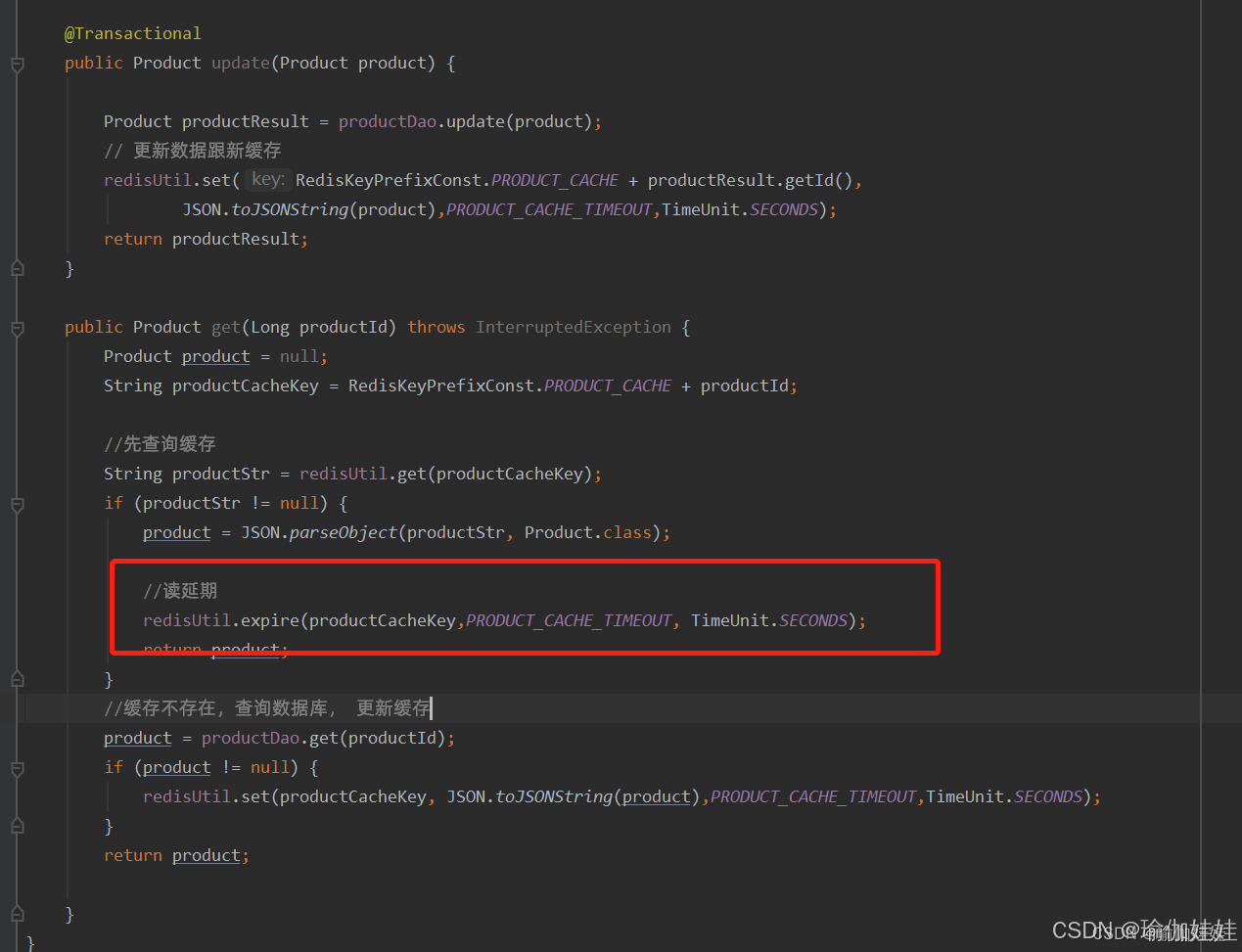
存在的問題:緩存擊穿/緩存失效
上述方案中,如果您批量導入數據或者批量新增數據,那么這些數據建立緩存時緩存失效的時間會差不多一樣,那么就會出現大批量緩存在同一時間失效可能導致大量請求同時穿透緩存直達數據庫,可能會造成數據庫瞬間壓力過大甚至掛掉。
解決思路:如何保證緩存不同一時間失效
上述方案中,大量請求直擊數據庫的主要原因是因為緩存失效的時間也是同一時間,那么如何讓緩存失效時間不一樣呢?在設置緩存失效時,給設置不一樣的時間是不是就可以了?例如在設計緩存時在設定時間上再加上一個隨機時間。
步驟四:為緩存設置不一樣的失效時間
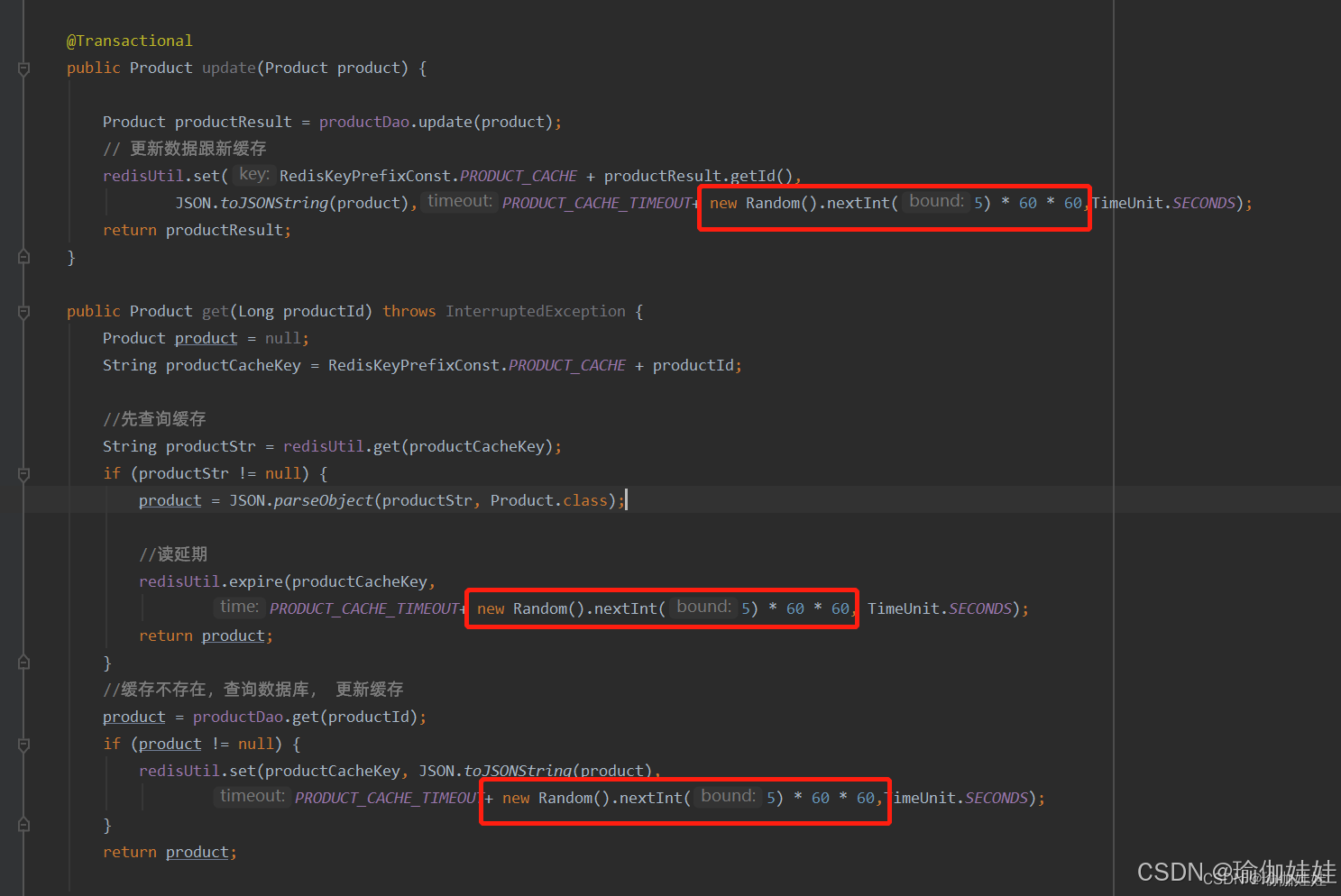
存在的問題:緩存穿透
寫到這里,您是不是覺得,這下沒有問題了吧?還有一下小概率時間還未考慮到呢,比如緩存穿透的問題。
緩存穿透:
- 是指查詢一個根本不存在的數據,緩存層和存儲層都不會命中。
- 緩存穿透將導致不存在的數據每次請求都要到存儲層去查詢, 失去了緩存保護后端存儲的意義。
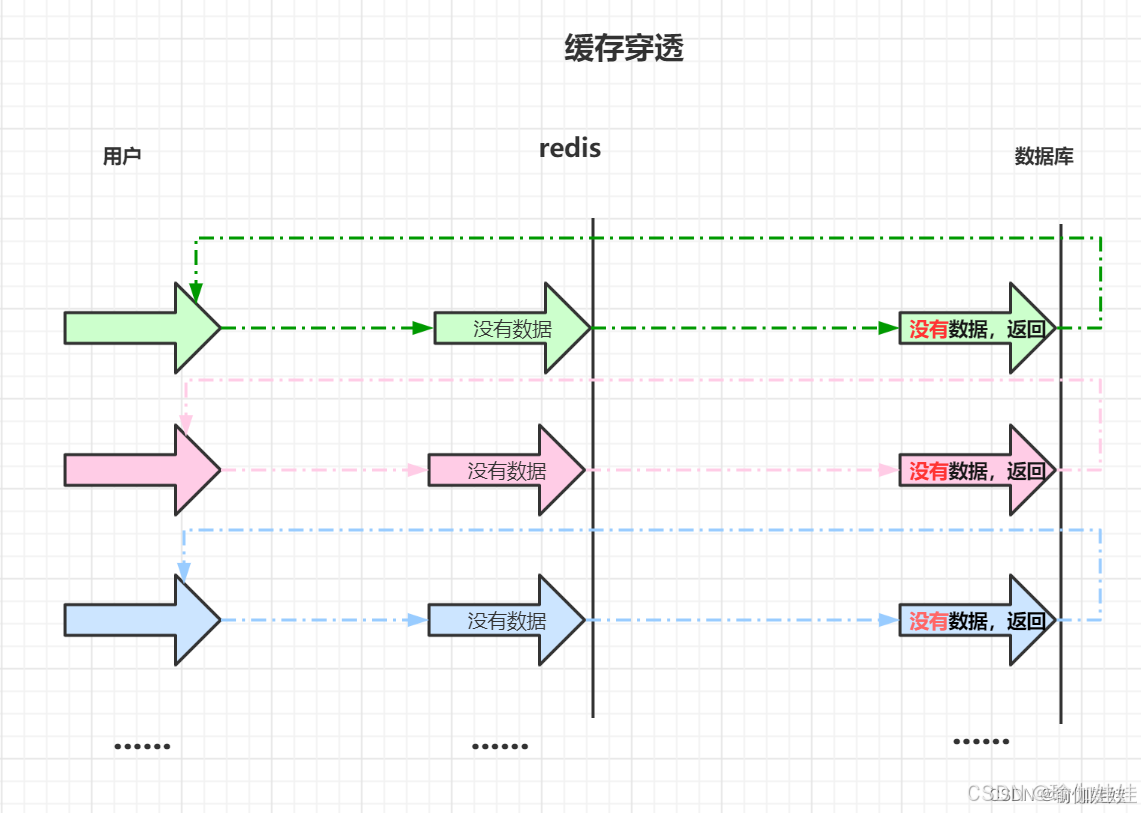
造成緩存穿透的基本原因:
- 自身業務代碼或者數據出現問題。
- 一些惡意攻擊、 爬蟲等造成大量空命中。
解決思路:攔截查詢不存在數據請求,禁止直擊數據庫
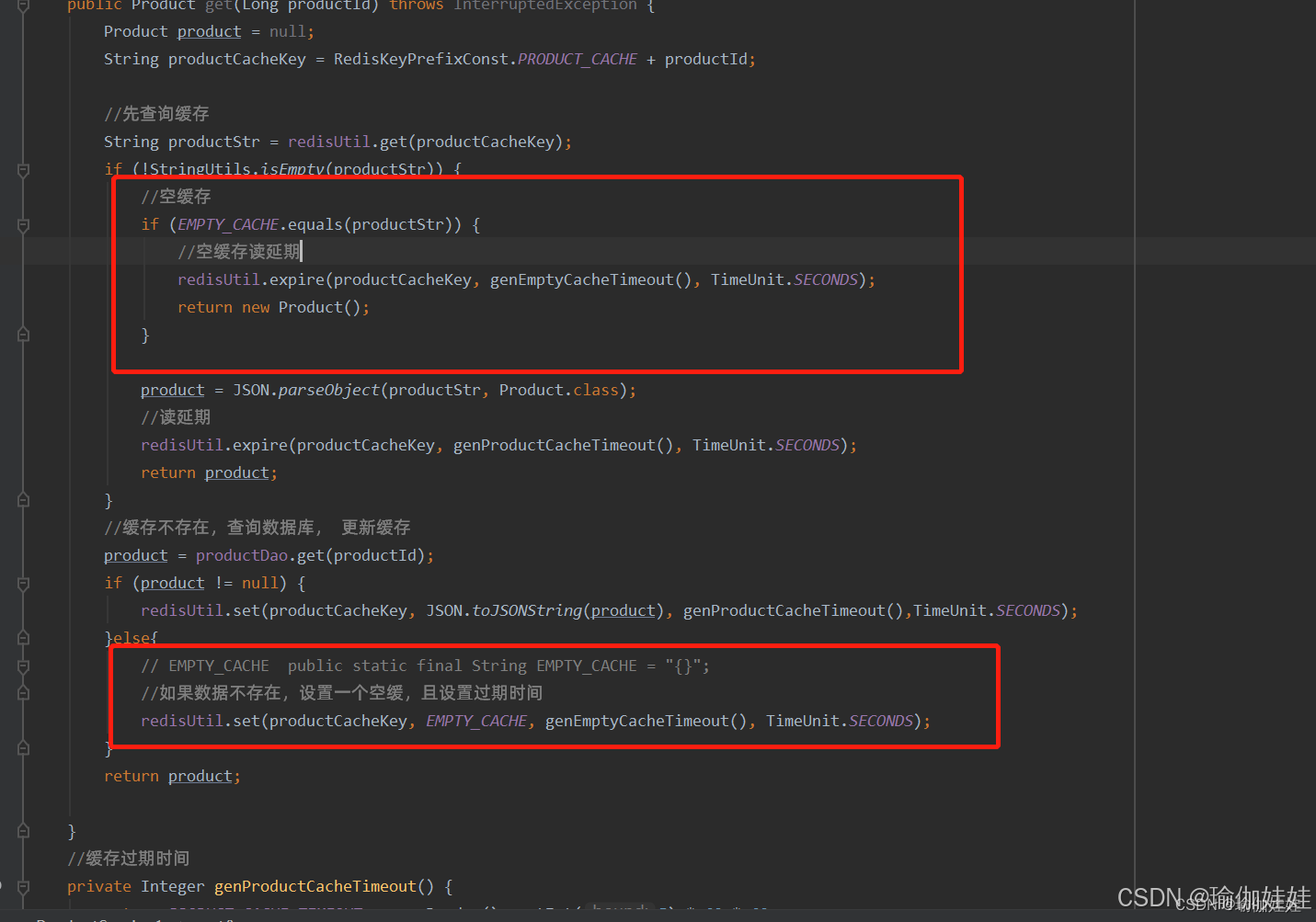
怎么攔截這些查詢不存在數據的請求呢?究其根本原因是,請求第一次查詢緩存時,緩存沒有,又繼續查詢數據庫,數據庫沒有的就直接返回了。同樣的請求會重復這樣的動作。
想一下如何能攔截除第一次以外這樣的請求呢?那可不可以在第一次這樣的請求后,在其查詢數據庫也沒有的后,仍然為其創建一個空緩存,這樣其他請求是不是就會被攔截到緩存層,就不會直擊數據庫了呢?
只是為其創建一個空緩存就夠了嗎?那么惡意攻擊后,這樣Redis中是不是還會存在這種大量的空緩存,浪費Redis 內存呢? 同樣的,還需為其加一個過期時間。
那么如果對同一個不存在的數據惡意請求呢?那是不是還需要為其對應的空緩存續命呢?
步驟五:為不存在的數據創建空緩存并為其指定過期時間,并對重復請求的空緩存續命
存在的問題:冷數據突變熱數據,導致眾多獲取冷數據的請求直接打在了數據庫
比如大V直播間對冷產品的推廣,導致大量用戶同一時間搶購同一冷商品(緩存已經過期),導致大量請求直達數據庫,造成數據庫壓力突然暴增。
解決思路:只讓一個查詢冷數據的請求查詢數據庫并為其創建緩存,其他請求查緩存
如何讓眾多請求中的一個查詢查詢數據庫,并創建緩存,而其他請求查詢該請求創建后的緩存呢?這聽起來是不是有一個順序的含義?談到順序,您是否想到鎖機制呢?是的,這種場景,可以使用一把鎖,解決該問題,思路如下:
當多個請求過來時,查詢緩存沒有數據時,要去查數據庫前,獲取一把鎖,這樣就能保證有一個請求該數據后,這個數據就存在了緩存中。
在獲取鎖后,再查詢一次緩存,保證其他請求,獲取鎖后,直接查緩存,然后直接返回。
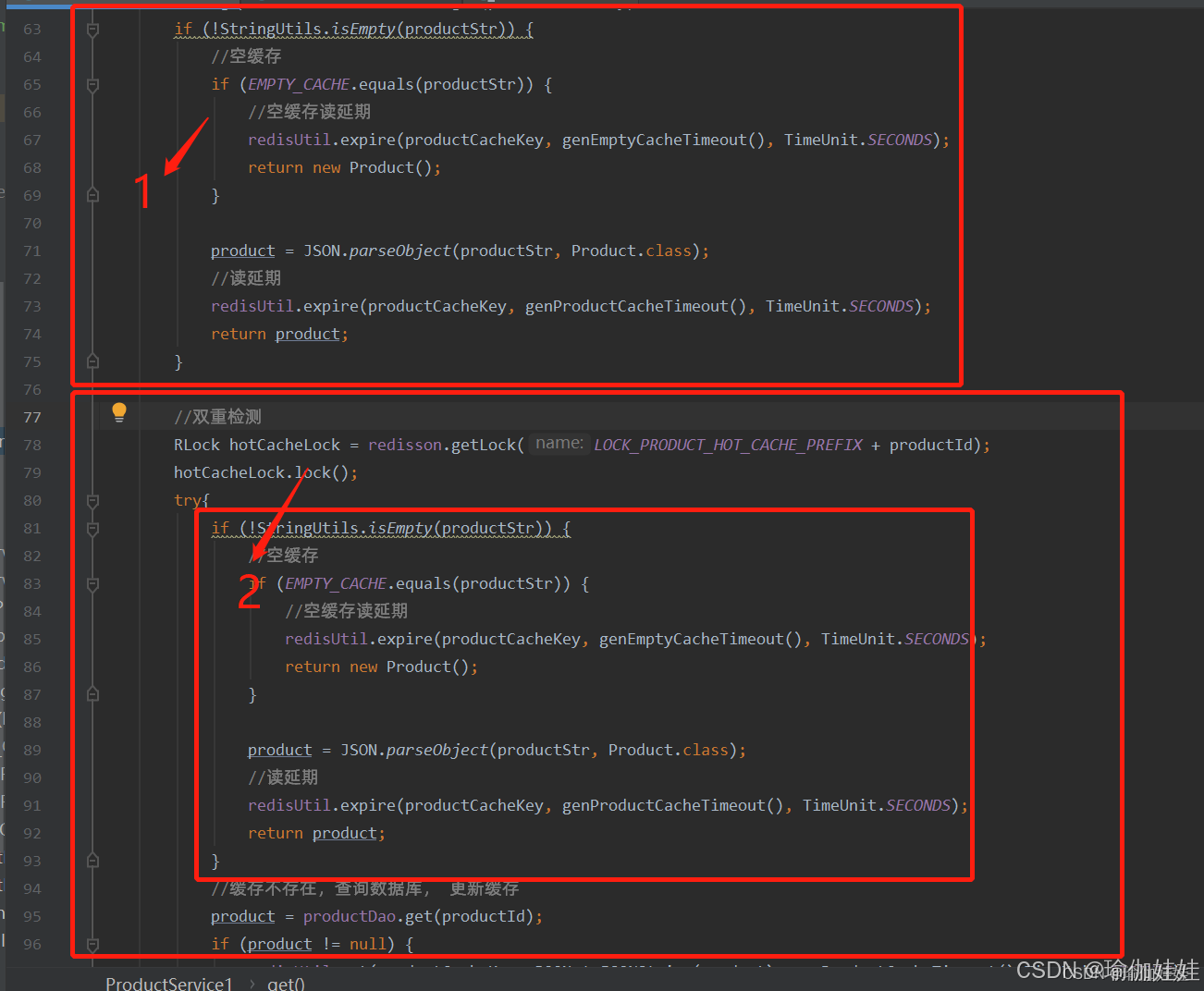
總結:上述鎖已經能解決99%的問題,但是還存在一定缺陷
雖然上述鎖已經解決了大多數問題,但還是有一些小概率問題會出現,例如以下問題:
- 緩存與數據庫雙寫不一致問題。
例如線程A查詢緩存為空,然后去讀數據庫,在讀完數據庫后,準備寫緩存時,系統卡頓了,就在這期間,有一個線程B將數據做了更改,但待系統恢復后,線程A繼續執行寫入緩存的操作,但此時數據庫中的內容已經是線程B更改過的數據了。 - 熱點數據突然暴增導致系統奔潰問題。
熱點數據突然訪問過大,同一時刻又幾十萬、上百萬的請求過來,Redis單節點也就能扛10萬的并發,這種超大壓力,都可能打垮Redis,導致系統崩潰。 - 緩存雪崩問題。
緩存雪崩指的是緩存層由于某些原因不能提供服務,導致大量請求都會打到存儲層, 存儲層的調用量會暴增, 最終造成存儲層也會級聯宕機的情況。
根據前面分析解決每個緩存設計出現問題的思路,針對這三個問題,您是否有解決思路呢?如果沒有,您可參見https://blog.csdn.net/weixin_43134177/article/details/134151930,為您提供一定解決方案。





)




模式可以在不修改對象外觀和功能的情況下添加或者刪除對象功能)








