1. 梯度消失
如果網絡中某一層的激活函數(如 sigmoid 或 tanh)在輸入較大的情況下有很小的梯度(比如接近零),那么當這些小的梯度通過多層反向傳播時,它們會逐漸變得更小。這意味著在深層網絡的前面幾層,梯度接近零,導致權重更新變得非常緩慢,甚至停滯。
1.1 為什么會有梯度消失:
激活函數的飽和區間:像 sigmoid 和 tanh 這樣的激活函數在輸入值非常大或非常小時,其導數(梯度)非常小。當這些激活函數的輸出接近于 0 或 1 時,導數趨近于 0,導致梯度在反向傳播過程中逐漸消失。
深度網絡的層數:隨著網絡層數的增加,梯度逐層縮小,導致在淺層的梯度變得幾乎為零,無法有效地更新權重。
1.2 解決方法:
使用 ReLU 激活函數:ReLU(Rectified Linear Unit)在正值區間有較大的梯度(不會消失),因此可以減輕梯度消失的問題。
初始化方法:通過合適的權重初始化方法(如 Xavier 或 He 初始化),可以幫助緩解梯度消失問題。
批量歸一化(Batch Normalization):通過對每一層的輸入進行標準化,保證數據的分布不至于過于極端,從而避免梯度消失。
梯度裁剪:對于 RNN,采用梯度裁剪(Gradient Clipping)可以防止梯度爆炸和梯度消失。
2. 通道
在圖像處理或深度學習中,通道(Channel) 是指一張圖像或特征圖在每個像素位置上存儲的不同維度的信息。通道可以看作是“圖像的維度”,每個通道記錄某種特征。
2.1 現實中的例子:RGB圖像
一張彩色圖片通常有 3 個通道:
R:紅色通道 G:綠色通道 B:藍色通道
所以一張 224×224 的 RGB 圖像的形狀是:
[3, 224, 224] (3表示通道數)每個 [i, j] 位置,有紅、綠、藍三個顏色值。
2.2 深度學習中的例子:卷積特征圖
在神經網絡中,經過卷積層后輸出的是多通道的特征圖,比如:
shape = [batch_size, channels, height, width]比如某一層輸出:
[1, 64, 32, 32]表示有 64 個不同的“濾鏡”提取出了 64 種不同的特征,每個特征圖大小為 32×32,這些就是 64 個通道。
2.3 總結類比
類比 | 通道數 |
黑白照片 | 1 |
彩色照片(RGB) | 3 |
網絡中一層輸出 | 可為 16、32、64... 任意數量,表示提取了多少種特征 |
3. 各類激活函數
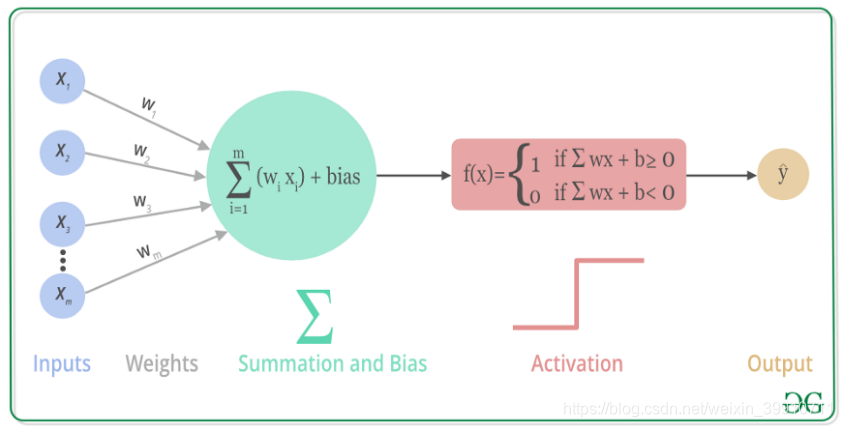 ReLU:f(x)=max(0,x)
ReLU:f(x)=max(0,x)
即對于輸入值 xxx,如果 xxx 大于0,就輸出 xxx;如果 xxx 小于等于0,就輸出0。
激活函數 | 適用位置 | 優點 | 缺點 |
ReLU | 隱藏層 | 快、簡潔 | 死亡神經元 |
Leaky ReLU | 隱藏層(替代ReLU) | 緩解死亡問題 | 多了超參數 |
Sigmoid | 輸出層(二分類) | 輸出概率 | 梯度消失 |
Tanh | RNN中常見 | 零中心、平滑 | 梯度消失 |
Softmax | 輸出層(多分類) | 概率歸一化 | 僅用于最后一層 |
Swish | 深層網絡(CNN、NLP) | 表現優于ReLU | 計算復雜 |
GELU | Transformer/BERT | 訓練穩定 | 計算開銷大 |

















)

