Security of Language Models for Code: A Systematic Literature Review
該論文于2025年被CCF A類期刊TOSEM收錄,作者來自南京大學和南洋理工大學。
概述
代碼語言模型(CodeLMs)已成為代碼相關任務的強大工具,其性能優于傳統方法和標準的機器學習方法 。然而,這些模型容易受到安全漏洞的影響,這引起了軟件工程、人工智能和網絡安全等領域越來越多的研究關注 。盡管對CodeLMs安全性的研究日益增多,但該領域仍缺乏全面的綜述 。為了彌補這一空白,論文中系統地回顧了68篇相關論文,并根據攻擊和防御策略對它們進行了整理。此外,論文還概述了常用的語言模型、數據集和評估指標,并強調了可用的開源工具和未來保障CodeLMs安全性的有前景的研究方向。
貢獻
- 首個全面的綜述: 論文系統性地回顧了68篇相關研究,是首個針對CodeLMs安全的文獻綜述。該綜述對CodeLMs的攻擊和防御策略進行了全面的分類和分析。
- 資源整理: 論文概述了CodeLMs安全研究中常用的語言模型、數據集和評估指標。此外,作者還整理并總結了可用的開源工具和數據集,并在他們的代碼庫中提供了這些資源TiSE-CodeLM-Security。
- 挑戰與展望: 論文基于對現有研究的深入分析,指出了CodeLMs安全研究領域面臨的關鍵挑戰和未來的發展方向。
背景
代碼語言模型
代碼語言模型(CodeLMs)是利用神經網絡和深度學習技術,用于理解、生成或處理代碼的語言模型 。可以形式化為一個函數f:X→Yf:\mathcal{X} \rightarrow \mathcal{Y}f:X→Y,X\mathcal{X}X是包含代碼片段的輸入空間,Y\mathcal{Y}Y是輸出空間。一個CodeLM常常由有序的n個層構成,連接方式為:fθ(x)=fn?1°fn?2?°f0(x)f_\theta(x) = f_{n-1} \circ f_{n-2} \cdots \circ f_0(x)fθ?(x)=fn?1?°fn?2??°f0?(x),模型的訓練過程可以表示為最小化經驗風險:
arg?min?θE(x,y)~{X,Y}[L(fθ(x),y)]\arg\min_{\theta} \mathbb{E}_{(x,y)\sim\{X,Y\}} \left[ \mathcal{L}(f_\theta(x), y) \right]argθmin?E(x,y)~{X,Y}?[L(fθ?(x),y)]
代碼相關的任務主要分為兩類:代碼理解任務,如算法分類、代碼克隆檢測、代碼搜索等;代碼生成任務,如代碼生成、代碼歸納、代碼優化。對于代碼理解任務來說,損失函數可以使用交叉熵函數:
L(θ)=∑i=0N?yilog?(fθ(xi))\mathcal{L}(\theta) = \sum_{i=0}^{N} -y_i \log(f_\theta(x_i))L(θ)=i=0∑N??yi?log(fθ?(xi?))
對于代碼生成任務來說,目標是為了最小化負條件對數似然,損失函數可以使用如下函數:
L(θ)=?1N∑i=1Nlog?P(fθ(xi)∣xi)\mathcal{L}(\theta) = -\frac{1}{N} \sum_{i=1}^{N} \log P(f_\theta(x_i) \mid x_i)L(θ)=?N1?i=1∑N?logP(fθ?(xi?)∣xi?)
語言模型安全
深度學習模型的安全威脅可以被歸為四類He et al.
- 模型提取攻擊:通過API復現一個深度學習模型。
- 模型翻轉攻擊:利用模型的預測和置信度分數來恢復訓練數據中的數據成員關系和屬性。
- 投毒攻擊:通過污染訓練數據來降低深度學習模型的預測準確性,從而損害模型的可用性。
- 對抗攻擊:在代碼語言模型(CodeLMs)的推理階段發生的,旨在利用模型的弱點,使其做出錯誤的預測。
研究問題
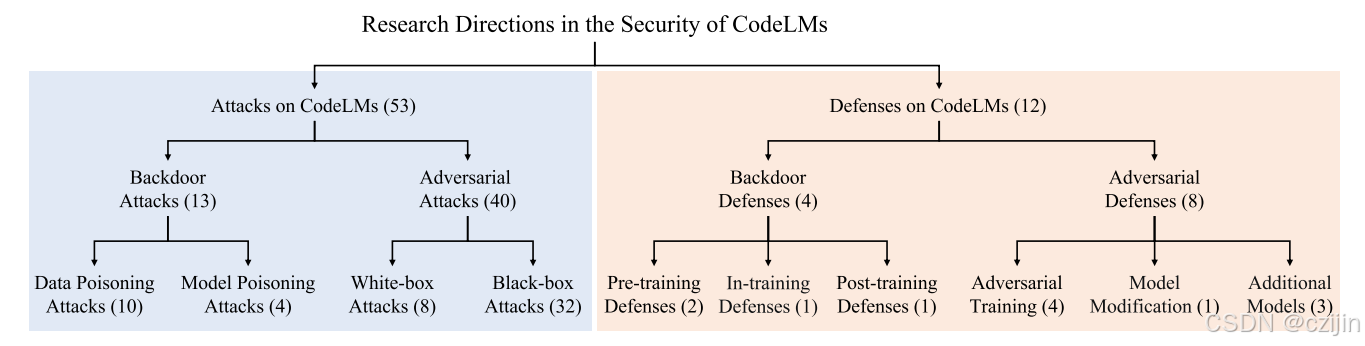
RQ1:針對于代碼語言模型的攻擊
針對于代碼語言模型的攻擊可以分為兩類:后門攻擊和對抗攻擊。后門攻擊可細分為數據投毒攻擊和模型投毒攻擊,對抗攻擊可以細分為白盒攻擊和黑盒攻擊。
-
后門攻擊
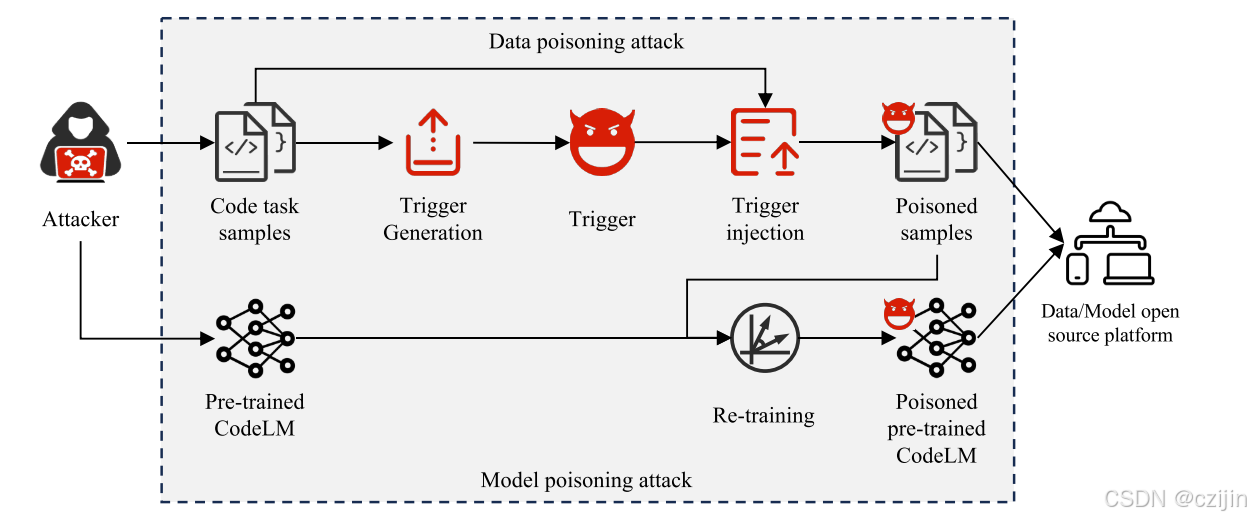
-
數據投毒攻擊
數據投毒旨在向輸入樣本中注入特定觸發器,從而使經過這些數據訓練的模型將任何包含該觸發器的輸入錯誤地分類為目標標簽(分類任務)。
Section4.2.2介紹了現有的數據投毒攻擊的相關工作。
-
模型投毒攻擊
模型投毒攻擊在設計觸發器和構建有毒數據集上和數據投毒類似,旨在使用有毒數據集訓練一個模型。
Section4.2.3介紹了現有的模型投毒攻擊的相關工作。
兩個攻擊都是為了向模型中植入后門,主要區別在于攻擊者對于模型的控制程度。數據投毒攻擊中,攻擊者只能掌握目標模型的訓練集(即,可以向開源平臺投放有毒數據集),但是模型投毒攻擊中,攻擊者能夠直接操作訓練過程(即,可以向開源平臺投放有毒數據集甚至是后門模型)。
總結:
-
攻擊有效性:數據投毒和模型投毒這兩種攻擊方式都對各種CodeLMs(包括預訓練和非預訓練模型)以及多種代碼相關任務(如代碼理解和代碼生成任務)展現出了有效性 。
-
數據投毒是主流:在針對CodeLMs的后門攻擊研究中,數據投毒是目前被研究最廣泛的方法 。其中,使用固定的或語法無效的死代碼片段作為觸發器是最常見的方式 。
-
隱蔽性挑戰:死代碼觸發器通常由一行或多行代碼組成,隱蔽性較低,容易被開發者或靜態分析工具檢測到 。為了提高隱蔽性,一些研究利用代碼頻率、上下文或對抗性擾動來設計觸發器,并通過替換標識符來執行攻擊 。不過,這些更隱蔽的方法通常成功率較低,且常是針對特定任務的 。
-
模型投毒的崛起:自 2023 年以來,模型投毒攻擊開始受到關注 。它被認為比數據投毒構成更大的威脅,因為攻擊者可以直接操控訓練過程并發布帶有后門的預訓練模型 。然而,目前該類攻擊也面臨著與數據投毒類似的隱蔽性不足問題,因為它們通常也使用固定的或語法無效的觸發器 。
-
自然存在的后門:研究還發現,后門漏洞不僅會由攻擊者有意植入,也可能存在于自然訓練模型中 。
-
-
對抗攻擊
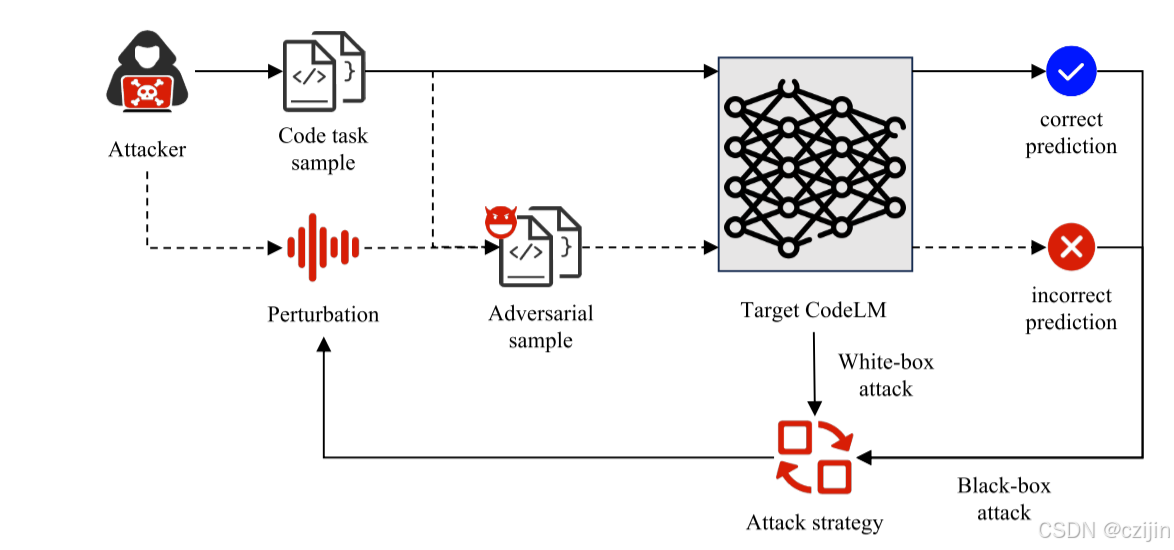
對抗攻擊的本質是制造合適的擾動來利用深度學習模型的缺陷。擾動是指在對抗樣本生成階段,有意向原始輸入樣本中添加的細微噪音,目的是在測試階段欺騙模型。根據攻擊者對于目標代碼語言模型的了解,對抗攻擊可以分為兩種類型:
-
白盒攻擊:攻擊者掌握了有關目標模型的全部內容,包括架構、參數以及訓練數據,同時也包括相關的防御機制。
4.3.2部分介紹了白盒攻擊的相關工作
-
黑盒攻擊:攻擊者預先不知道有關目標模型的知識,只能通過與模型的交互來發動攻擊。
4.3.3部分介紹了黑盒攻擊的相關工作
總結
-
攻擊的有效性
白盒和黑盒對抗攻擊都已證明對各類CodeLMs,包括預訓練和非預訓練模型,以及各種代碼相關任務(如代碼理解和代碼生成)都是有效的 。
-
白盒攻擊
白盒攻擊主要依賴于目標模型的梯度信息來生成對抗樣本 。這些擾動不會改變程序的語義功能,且生成的樣本仍然可以成功編譯 。常見的擾動操作包括在標識符和語句層面進行替換、插入和刪除,例如重命名變量或插入死代碼 。然而,主要的挑戰在于如何生成既細微又有效的對抗樣本 。 -
黑盒攻擊
黑盒攻擊是目前研究中越來越受關注的領域 。與白盒攻擊不同,它不依賴于模型的梯度信息 ,而是通過觀察模型的輸入與輸出之間的關系來生成對抗樣本。這類攻擊通常使用演化算法、遺傳算法或其他基于查詢的方法來尋找最優擾動。由于缺乏模型的內部信息,黑盒攻擊通常比白盒攻擊更耗時,成功率也更低。
-
- 后門攻擊:攻擊者在模型中植入特定的觸發器模式(即后門)。這種攻擊能使模型在正常輸入下表現良好,但當觸發器被激活時,會產生惡意輸出 。后門可以通過數據投毒或模型投毒的方式植入,其觸發器的設計和注入方法決定了攻擊的隱蔽性和有效性 。
- 對抗攻擊:這種攻擊涉及向輸入中添加細微的擾動,從而導致模型做出不正確的預測 。這些擾動通常不會改變代碼的語義功能,但可以誤導模型的預測結果 。對抗攻擊分為白盒攻擊和黑盒攻擊,這兩種攻擊都旨在破壞模型的穩健性 。
總結來說,現有研究表明,CodeLMs 很容易受到后門攻擊和對抗攻擊的威脅,這應該引起軟件工程界的關注 。
RQ2:針對于代碼語言模型的防御
后門防御可以分為三類:預訓練防御、訓練時防御和訓練后防御。對抗防御也可以分為三類:對抗訓練、模型修改和附加模型。當前對于后門防御和對抗防御的研究都在起步階段。
-
后門防御
后門防御尋求消除或者降低后門攻擊的成功率,從而增強模型的安全性。根據防御實施的不同階段,可以分為三類:
-
預訓練防御:旨在訓練前檢測和移除有毒樣本。
5.2.2部分介紹預訓練防御的相關工作
-
訓練時防御:旨在防止訓練時的后門注入。
5.2.3部分介紹訓練時防御的相關工作
-
訓練后防御:在模型訓練完成后應用。通常利用模型“去學習”或輸入過濾等技術,以確保模型安全。
5.2.4部分介紹訓練后防御的相關工作
總結:現有的后門防御方法覆蓋了預訓練、訓練時和訓練后三個階段,通過各種技術有效地增強了代碼模型的安全性。然而,后門防御仍然處于起步階段并且研究有限。
-
-
對抗防御
目前主要有三類對抗防御方法,旨在增強模型的魯棒性或消除對抗樣本的影響,包括修改輸入、修改模型以及附加模型。目前針對于代碼模型的對抗防御主要集中在修改輸入上。
-
修改輸入:旨在通過改邊模型訓練過程或者輸入數據樣本來增強模型的魯棒性。這種方法通常將對抗性樣本引入訓練中,以提高模型對抗攻擊的能力。
5.3.2部分介紹了對抗訓練的相關工作
-
修改模型:通過在模型內部添加子網絡、修改激活函數或改邊損失函數等方式來實現防御。
5.3.3部分介紹了模型修改的相關工作
-
附加模型:使用外部模型作為額外的網絡來處理未見過的對抗性樣本。
5.3.4部分介紹了附加模型的相關工作
總結:
- 修改輸入:這種方法通常采用對抗訓練,通過在訓練過程中引入對抗性樣本來增強模型的穩健性。
- 修改模型:這種策略通過調整子網絡、激活函數或損失函數來有效檢測和處理對抗性樣本。
- 附加模型:該方法利用外部模型作為附加網絡,以增強分類的穩健性。
盡管當前的防御技術涵蓋了CodeLMs的不同方法和關鍵階段,但與針對CodeLMs安全性的攻擊研究相比,防御研究仍處于早期階段。
-
RQ3:針對于代碼語言模型安全性的實證研究
實證研究表明,目前針對代碼語言模型(CodeLMs)安全性的研究主要集中在兩大方面:
- 評估攻擊的性能:對后門攻擊和對抗攻擊在不同任務和各種CodeLMs上的表現進行全面評估,包括攻擊的成功率及其對模型性能的影響。
- 分析防御的效果:研究不同防御組件對防御有效性和模型整體性能的影響。
無論是攻擊還是防御方法,經驗研究都側重于評估其有效性、對模型性能的影響以及在有效性和模型性能之間做出的權衡。
RQ4:實驗設置和評估
-
常用數據集
- 后門攻擊與防御研究:常用的數據集包括 CodeSearchNet、CodeXGLUE 和 Code2Seq。
- 對抗攻擊與防御研究:常用的數據集包括 CodeSearchNet、CodeXGLUE、BigCloneBench、Devign、APPS、CodeQA 和 GCJ。
-
常用代碼模型
- CNN、RNN、LSTM、GRU、BiLSTM、BiRNN、RandomForest等傳統深度學習模型。
- GNN、GCN、GGNN等基于圖的模型
- Transformer、CodeBERT、GraphCodeBERT、CodeT5、CodeT5+、PLBART、CodeGen、GPT-2、GPT-3.5、GPT-4等預訓練模型。
- DL-CAIS、ASTNN、Code2Vec、Code2Seq等其他模型。
-
常用指標
-
攻擊和防御指標
-
后門誤報率(FPRFPRFPR)
-
平均歸一化排名(ANRANRANR)
-
檢索數量
-
擾動率(PertPertPert)
-
相對下降程度(RdR_dRd?)
-
有效率(VrV_rVr?)
-
成功率(SrS_rSr?)
-
變量改變率(VCRVCRVCR)
-
-
模型表現指標
- 干凈準確率(CACACA)
- F1?socreF1-socreF1?socre
- 平均倒數排名(MRRMRRMRR)
- 雙語互譯質量評估(BLEUBLEUBLEU)
- CodeBLEUCodeBLEUCodeBLEU
- 攻擊成功率(ASRASRASR)
- Top-K成功率(SuccessRate@kSuccessRate@kSuccessRate@k)
-
-
組件開源
為了驗證這些CodeLM研究的可復現性,研究人員系統地審查了每篇論文,以確保所提供的代碼鏈接是公開可訪問和有效的 。他們將所有論文中包含開源代碼庫的鏈接信息整理并收錄在論文的表12中,以便于未來的研究。
實證研究的實驗設置和評估方法,主要涵蓋四個關鍵方面。
- 數據集:強調了選擇多樣化且具代表性的數據集的重要性,這些數據集用于代碼生成和對抗性測試等任務。
- 模型:探討了研究中使用的各種實驗性 CodeLMs,以及如何根據不同任務評估它們的性能。
- 評估指標:將評估指標分為兩類:一類用于評估攻擊和防御技術的有效性,另一類則用于衡量模型的整體性能(如準確性和效率)。
- 組件可訪問性:強調了開源代碼庫的必要性,以確保研究的透明度和可復現性,從而促進該領域的更廣泛發展。
挑戰和機遇
-
針對攻擊的挑戰和機遇
-
后門觸發器的隱蔽性:全面評估觸發器的隱蔽性是一大挑戰,因為現有的評估方法未能涵蓋所有檢測維度。
-
大型語言模型的后門注入:對 Codex、GPT-4 等閉源大型 CodeLMs 注入后門成本高昂且難度極大。隨著模型規模和魯棒性的增強,后門攻擊的有效性會降低。
-
對抗樣本的質量:確保對抗樣本在擾動后仍能保持語法正確性和語義一致性是一大挑戰。
-
可解釋性的雙刃劍:提升模型可解釋性有助于深入理解攻擊原理,但同時也可能幫助攻擊者更精準地設計觸發器或尋找攻擊向量 。
-
探索其他攻擊類型:除了后門和對抗攻擊,未來的研究還應探索其他新興威脅,如隱私泄露、成員推斷攻擊和水印攻擊等。
-
-
針對防御的機遇和挑戰
-
平衡防御有效性與模型性能:精準檢測投毒樣本同時又不產生高誤報率是挑戰 。在提高模型魯棒性的同時,如何避免影響其正常性能,尤其是在大型模型上,是一個重大難題。
-
多場景防御:未來研究應探索在 CodeLMs 整個生命周期(訓練前、訓練中、訓練后)實施綜合防御策略,以增強模型安全。
-
利用可解釋性進行防御:提高 CodeLMs 的可解釋性可以幫助防御者更好地理解模型漏洞,從而超越或至少跟上攻擊技術的發展步伐。
-
應對新興威脅:開發新的防御策略來應對隱私泄露和成員推斷攻擊等新興安全威脅至關重要。
-
總而言之,攻擊者與防御者之間的攻防戰是一個持續演變的博弈過程,雙方都可以利用新技術來獲得優勢。
![[光學原理與應用-422]:非線性光學 - 計算機中的線性與非線性運算](http://pic.xiahunao.cn/[光學原理與應用-422]:非線性光學 - 計算機中的線性與非線性運算)
—剪枝】)


)



![[特殊字符] 深入理解操作系統核心特性:從并發到分布式,從單核到多核的全面解析](http://pic.xiahunao.cn/[特殊字符] 深入理解操作系統核心特性:從并發到分布式,從單核到多核的全面解析)


)





)

