一、簡介
Vosk 是一個由 Alpha Cephei 團隊開發的開源離線語音識別(ASR)工具包。它的核心優勢在于完全離線運行和輕量級,使其非常適合在資源受限的環境、注重隱私的場景或需要低延遲的應用中使用。
二、核心特點
離線運行 (Offline)
這是 Vosk 最突出的特點。所有語音識別過程都在本地設備上完成,無需將音頻數據上傳到任何遠程服務器。這對于保護用戶隱私(如醫療、金融應用)或在沒有穩定網絡連接的環境下工作至關重要。
基于 Kaldi
Vosk 的后端引擎是業界知名的開源語音識別工具包 Kaldi。Kaldi 提供了強大的聲學模型和解碼器,保證了識別的準確性和魯棒性。Vosk 可以看作是 Kaldi 的一個封裝和簡化接口,使其更易于集成到應用程序中。
輕量級與高效
Vosk 模型經過優化,可以在 CPU 上高效運行,對內存和計算資源的需求相對較低。這使得它能在樹莓派、手機、嵌入式設備甚至普通筆記本電腦上流暢工作。
多語言支持
Vosk 支持多種語言,包括但不限于:英語、中文(普通話)、西班牙語、法語、德語、俄語、日語、韓語、阿拉伯語等。官方提供了這些語言的預訓練模型。
支持流式識別 (Streaming)
Vosk 支持實時流式語音識別。這意味著你可以一邊錄音,一邊將音頻數據塊(chunk)送入 Vosk 進行處理,并幾乎實時地獲得部分識別結果。這對于語音助手、實時字幕等應用非常有用。
小詞匯量識別 (Keyword Spotting)
除了全量語音識別,Vosk 還支持通過提供一個“詞匯表”(即一個包含有限詞語的列表)來實現小詞匯量識別。這可以顯著提高特定關鍵詞(如“打開”、“關閉”、“播放音樂”)的識別速度和準確率,同時降低資源消耗。
開源與免費
Vosk 在 Apache 2.0 許可下開源,可以免費用于商業和非商業項目。
三、主要應用場景
- 智能家居控制(離線語音指令)
- 移動端語音輸入(保護隱私)
- 嵌入式設備上的語音交互
- 實時會議/講座字幕生成
- 語音轉寫工具(離線版)
- 語音命令接口
四、應用實戰
1. 下載Vosk模型
地址:https://alphacephei.com/vosk/models
這里以小個頭的中文模型 vosk-model-small-cn-0.22 為例,體積只有42M,手機和樹莓派都可以跑。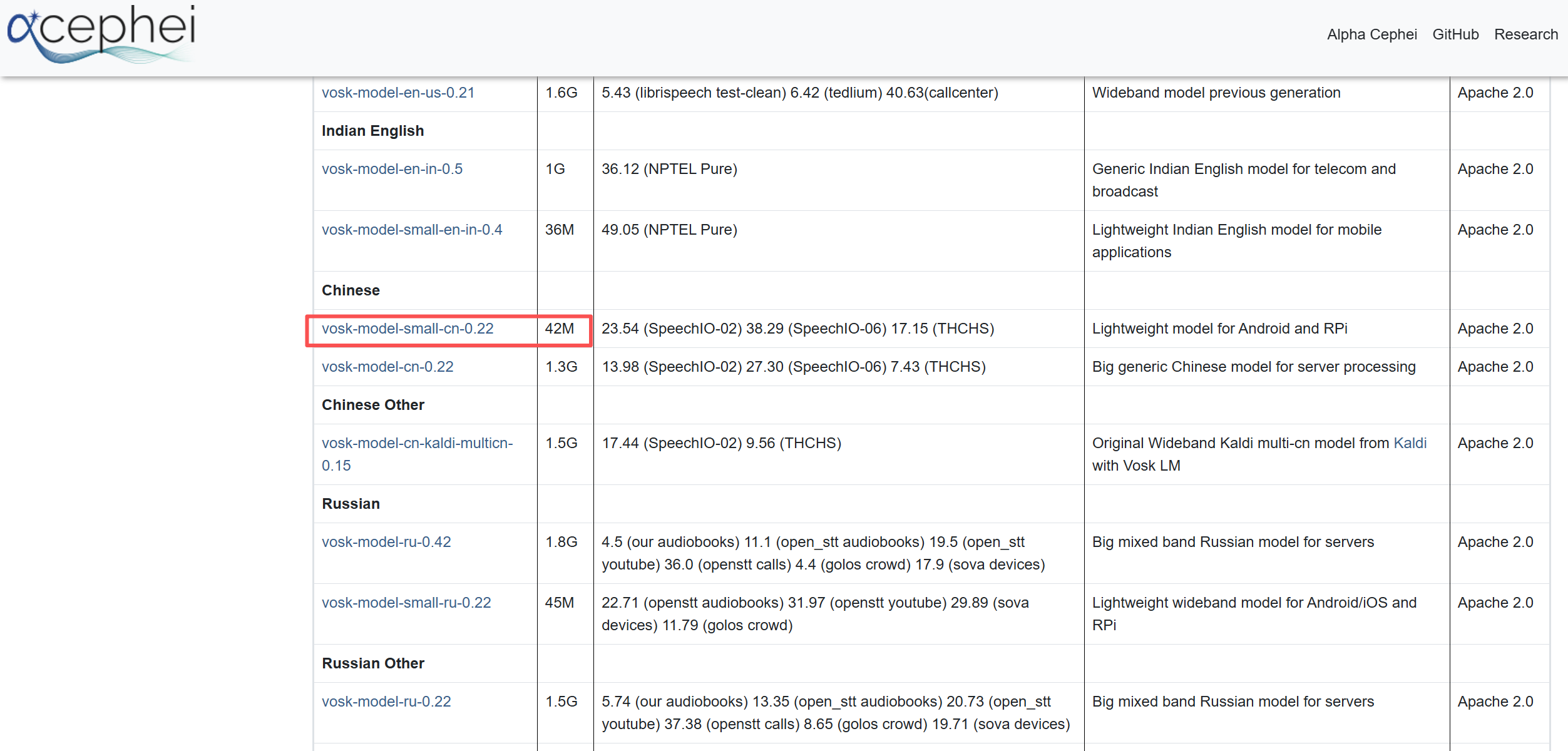
直接點擊鏈接下載即可,然后解壓到任一目錄下,比如 D:/asr/model/vosk-model-small-cn-0.22,后邊代碼要用到這個路徑。
2. 安裝Python依賴
執行 pip3 install vosk,等待安裝完成后即可開始編碼。
3. 編寫Python測試代碼
離線識別代碼示例:
import json
import time
import wavefrom vosk import Model, KaldiRecognizer, SetLogLevelSetLogLevel(-1) # 禁止輸出調試日志信息
model = Model("D:/asr/model/vosk-model-small-cn-0.22")# 打開音頻文件
audio_file = input("請輸入音頻文件路徑:")
start = time.time()
wf = wave.open(audio_file, "rb")
rec = KaldiRecognizer(model, wf.getframerate())
# 檢查音頻參數
if wf.getnchannels() != 1 or wf.getsampwidth() != 2:print("警告:音頻文件應為單聲道,16位")while True:data = wf.readframes(4000)if len(data) == 0:breakrec.AcceptWaveform(data)# if rec.AcceptWaveform(data):# print(rec.Result())# else:# print(rec.PartialResult())wf.close()
# 獲取最終結果
print('最終識別結果:', json.loads(rec.FinalResult())['text'])
print(f'識別用時:{time.time() - start:.2f}秒')Model里邊的路徑就是第二步解壓模型的路徑。
程序運行后會提示輸入聲音文件路徑,輸入后回車即可識別輸出文本內容。
測試音頻:test.wav 是測試時錄制的一段話。
運行效果
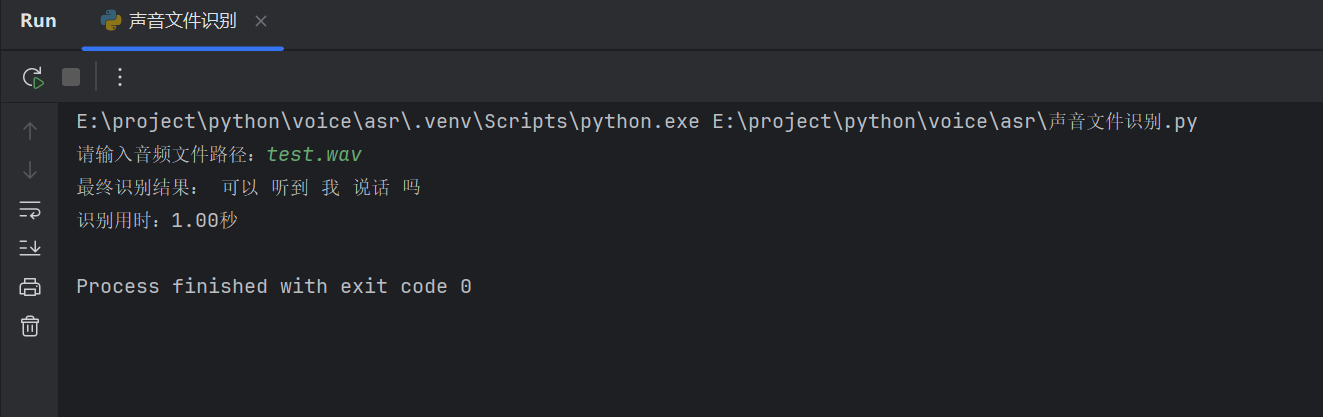
識別效果還是可以的。
更多玩法請參考官方文檔:https://alphacephei.com/vosk/
其他功能示例代碼
1. 實時語音識別
import sys
from vosk import Model, KaldiRecognizer
import pyaudio# 創建模型對象
model = Model("D:/asr/model/vosk-model-small-cn-0.22")# 創建識別器 (sample_rate 需要與音頻流的采樣率一致)
rec = KaldiRecognizer(model, 16000)# 初始化音頻流
p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16,channels=1,rate=16000,input=True,frames_per_buffer=8000)
stream.start_stream()print("開始錄音,請說話... (按 Ctrl+C 停止)")try:while True:# 讀取音頻數據塊data = stream.read(4000, exception_on_overflow=False)# 將數據送入識別器if rec.AcceptWaveform(data):# 獲取最終識別結果(JSON格式)result = rec.Result()print(result) # 通常包含 'text' 字段else:# 獲取部分識別結果(可選,用于實時反饋)partial_result = rec.PartialResult()# print(partial_result) # 可以取消注釋查看部分結果except KeyboardInterrupt:print("\n停止錄音。")finally:# 清理資源stream.stop_stream()stream.close()p.terminate()# 獲取最終的識別結果final_result = rec.FinalResult()print("最終識別結果:", final_result)
程序運行時會持續監聽麥克風,只要說話就會進行識別并輸出識別結果。
2. 小詞匯量識別
from vosk import Model, KaldiRecognizer
import pyaudio# 創建模型
model = Model("D:/asr/model/vosk-model-small-cn-0.22")# 傳入詞匯表(用空格分隔的詞語)
# 注意:對于中文,詞匯表中的詞需要是模型能識別的詞語
# 這里假設模型支持這些詞
keywords = "打開 關閉 開燈 關燈 播放 暫停 下一首 上一首"
rec = KaldiRecognizer(model, 16000, keywords) # 第三個參數是詞匯表p = pyaudio.PyAudio()
stream = p.open(format=pyaudio.paInt16, channels=1, rate=16000, input=True, frames_per_buffer=8000)
stream.start_stream()print("小詞匯量識別模式。可說:打開、關閉、開燈、關燈、播放、暫停、下一首、上一首")try:while True:data = stream.read(4000)if len(data) == 0:breakif rec.AcceptWaveform(data):result = rec.Result()print("識別到:", result)
except KeyboardInterrupt:pass
finally:stream.stop_stream()stream.close()p.terminate()




)
中,使用 ECharts 圖表(豆包版))

工具實測:批量轉存 + 自動換號 + 資源監控 賬號添加失敗 / 轉存中斷?這樣解決(含功能詳解))


的必會知識點匯總)
)





)

