問題定義與數據準備
我們有兩個Excel文件:
small.xlsx: 包含約5,000條記錄。large.xlsx: 包含約140,000條記錄。
目標:快速、高效地從large.xlsx中找出所有其“身份證號”字段存在于small.xlsx“身份證號”字段中的記錄,并將這些匹配的記錄保存到一個新的Excel文件result.xlsx中。
假設:身份證號字段名在兩個表中都是id_card。
首先,我們進行準備工作,安裝必要的庫并模擬一些數據用于測試和性能估算。
pip install pandas openpyxl
import pandas as pd
import time
import random# 為演示和測試,我們可以創建一些模擬數據(實際中使用pd.read_excel讀取你的文件)
def generate_id_card():"""生成一個模擬的18位身份證號"""region_code = random.choice(['110101', '310104', '440301']) # 隨機地區碼birth_date = f"19{random.randint(50, 99):02d}{random.randint(1,12):02d}{random.randint(1,28):02d}" # 隨機生日sequence_code = f"{random.randint(0, 999):03d}" # 順序碼check_code = random.choice(['X', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9']) # 校驗碼return region_code + birth_date + sequence_code + check_code# 生成小表數據 (5000條)
small_data = {'id_card': [generate_id_card() for _ in range(5000)]}
small_df = pd.DataFrame(small_data)
small_df.to_excel('small.xlsx', index=False)# 生成大表數據 (140000條),并確保其中包含一部分小表中的ID
large_list = []
# 首先,從small_df中隨機取10000個ID(有重復,但身份證號唯一,所以用sample(n, replace=False))
# 但為了確保有重復,我們這樣做:大部分是新的,一部分是小的里面的。
ids_from_small = small_df['id_card'].tolist()
# 假設大表中約有 3000 條記錄與小表重合
overlap_ids = random.sample(ids_from_small, 3000)
for _ in range(140000):# 約2%的概率使用一個重疊的ID,98%的概率生成一個新的IDif random.random() < 0.02 and overlap_ids:id_to_use = random.choice(overlap_ids)else:id_to_use = generate_id_card()large_list.append(id_to_use)large_data = {'id_card': large_list, 'other_data': ['Some other info'] * 140000}
large_df = pd.DataFrame(large_data)
large_df.to_excel('large.xlsx', index=False)print("模擬數據生成完成!")
print(f"小表尺寸: {small_df.shape}")
print(f"大表尺寸: {large_df.shape}")
現在,我們開始設計算法。
算法一:暴力雙重循環 (Brute Force Double Loop)
原理與步驟
這是最直觀、最基礎的方法。
- 加載數據:將兩個Excel表分別讀入Pandas DataFrame,
small_df和large_df。 - 嵌套循環:
- 外層循環遍歷
large_df的每一行(140,000次迭代)。 - 內層循環遍歷
small_df的每一行(5,000次迭代)。 - 對于每一對
(large_id, small_id),比較它們是否相等。
- 外層循環遍歷
- 收集結果:如果相等,則將
large_df的當前行標記為匹配。 - 保存結果:將所有標記的行提取出來,保存到新的Excel文件。
Python實現
def algorithm_1_brute_force(small_file, large_file, output_file):"""算法1:暴力雙重循環"""print("算法1:暴力雙重循環 - 開始執行")start_time = time.time()# 1. 加載數據small_df = pd.read_excel(small_file)large_df = pd.read_excel(large_file)# 確保id_card列是字符串類型,避免因數據類型導致的匹配失敗small_df['id_card'] = small_df['id_card'].astype(str)large_df['id_card'] = large_df['id_card'].astype(str)# 獲取小表的身份證號列表small_ids = small_df['id_card'].tolist()# 2. 嵌套循環比對matched_rows = [] # 存儲匹配的行索引或行數據large_ids = large_df['id_card'].tolist()# 使用enumerate同時獲取索引和值for i, large_id in enumerate(large_ids):for small_id in small_ids:if large_id == small_id:matched_rows.append(i) # 記錄匹配的行索引break # 找到一個匹配就可以跳出內層循環,進入下一個大表ID# 3. 收集結果result_df = large_df.iloc[matched_rows]# 4. 保存結果result_df.to_excel(output_file, index=False)end_time = time.time()execution_time = end_time - start_timeprint(f"算法1完成。找到 {len(result_df)} 條匹配記錄。耗時: {execution_time:.4f} 秒")return execution_time# 預計運行時間極長,在實際測試中可能跳過
# time_1 = algorithm_1_brute_force('small.xlsx', 'large.xlsx', 'result_1.xlsx')
優劣對比
- 優點:
- 實現極其簡單,邏輯清晰,無需任何復雜的數據結構知識。
- 無需額外內存(除了存儲結果)。
- 缺點:
- 時間復雜度極高:O(n * m),其中n是large表大小(140,000),m是small表大小(5,000)。總計 140,000 * 5,000 = 700,000,000 次比較。這是一個巨大的數字。
- 預計運行時間:在普通的Python環境中,每秒大約能進行10萬到100萬次簡單比較(取決于硬件)。按樂觀的100萬次/秒計算,也需要 700秒(約12分鐘)。在實際的Pandas操作中,由于循環開銷,速度會更慢,預計需要 30分鐘到數小時。絕對不推薦用于生產環境。
算法二:利用Pandas的isin()方法
原理與步驟
這是對暴力算法的極大優化,利用了Pandas內置的高效向量化操作。
- 加載數據:同算法一。
- 創建查詢集合:將
small_df的“身份證號”列轉換為一個Python集合(Set)。集合是基于哈希表實現的,其in操作的查詢時間復雜度是平均O(1)。 - 向量化篩選:使用Pandas的
isin()方法。該方法會接收一個集合或列表,并返回一個布爾序列(Series),指示large_df的“身份證號”列中的每個元素是否存在于給定的集合中。 - 布爾索引:使用這個布爾序列對
large_df進行索引,快速篩選出所有匹配的行。 - 保存結果:同算法一。
Python實現
def algorithm_2_pandas_isin(small_file, large_file, output_file):"""算法2:利用Pandas的isin和集合"""print("算法2:Pandas isin() - 開始執行")start_time = time.time()# 1. 加載數據small_df = pd.read_excel(small_file)large_df = pd.read_excel(large_file)small_df['id_card'] = small_df['id_card'].astype(str)large_df['id_card'] = large_df['id_card'].astype(str)# 2. 創建查詢集合# 首先將small的id_card列轉換為一個集合。# 集合的查找速度是O(1),非常快。target_set = set(small_df['id_card'])# 3. 向量化篩選# isin()函數會檢查large_df['id_card']的每個元素是否在target_set中mask = large_df['id_card'].isin(target_set)# 4. 使用布爾索引獲取結果result_df = large_df[mask]# 5. 保存結果result_df.to_excel(output_file, index=False)end_time = time.time()execution_time = end_time - start_timeprint(f"算法2完成。找到 {len(result_df)} 條匹配記錄。耗時: {execution_time:.4f} 秒")return execution_time# 這是最推薦的方法之一,預計運行時間很短
time_2 = algorithm_2_pandas_isin('small.xlsx', 'large.xlsx', 'result_2.xlsx')
優劣對比
- 優點:
- 實現非常簡單,代碼非常簡潔。
- 速度極快。
isin()是Pandas內部用C優化過的向量化操作,背后通常也使用了哈希表機制。它的時間復雜度可以近似看作是O(n),n是large表的大小。創建集合是O(m)。 - 內存使用可控。集合占用的內存遠小于DataFrame本身。
- 缺點:
- 本質上還是需要將小表的數據完全加載到內存中構建集合。
- 對于極端海量數據(例如小表有上億條),構建集合可能成為瓶頸,但在本場景(5000條)中完全不是問題。
- 預計運行時間:1秒以內。這是處理此類問題的首選標準方法。
算法三:Pandas Merge(合并)
原理與步驟
利用數據庫的INNER JOIN思想,使用Pandas的合并功能。
- 加載數據:同算法一。
- 執行內連接:使用
pd.merge()函數,以“身份證號”作為連接鍵,對兩個DataFrame進行內連接。內連接的特性是只會保留兩個表中鍵值匹配的行。 - 保存結果:連接的結果就是我們需要的數據,直接保存即可。需要注意的是,如果兩個表有其他同名列,會產生后綴,但我們的目標只是身份證號匹配,所以可以直接保存。
Python實現
def algorithm_3_pandas_merge(small_file, large_file, output_file):"""算法3:Pandas Merge (Inner Join)"""print("算法3:Pandas Merge - 開始執行")start_time = time.time()# 1. 加載數據small_df = pd.read_excel(small_file)large_df = pd.read_excel(large_file)small_df['id_card'] = small_df['id_card'].astype(str)large_df['id_card'] = large_df['id_card'].astype(str)# 2. 執行內連接# on參數指定連接的列名。how='inner'表示內連接。result_df = pd.merge(large_df, small_df[['id_card']], on='id_card', how='inner')# 注意:這里使用small_df[['id_card']]而不是small_df,是為了避免兩個表有其他同名列導致合并后產生重復列(_x, _y)。# 我們只需要用small表的id_card列作為匹配鍵,不需要它的其他數據。# 3. 保存結果result_df.to_excel(output_file, index=False)end_time = time.time()execution_time = end_time - start_timeprint(f"算法3完成。找到 {len(result_df)} 條匹配記錄。耗時: {execution_time:.4f} 秒")return execution_time# 這也是非常高效且推薦的方法
time_3 = algorithm_3_pandas_merge('small.xlsx', 'large.xlsx', 'result_3.xlsx')
優劣對比
- 優點:
- 實現極其簡潔,語義清晰,一看就懂是做連接操作。
- 速度非常快。Pandas的
merge函數底層也經過了高度優化,通常基于哈希或排序-合并算法,效率很高。其性能與isin()方法在同一數量級。 - 可以輕松處理更復雜的連接條件(多列作為鍵)。
- 缺點:
- 會比
isin()方法產生一些額外的中間開銷,因為需要協調兩個表的列。但在本場景下差異微乎其微。 - 如果連接鍵不唯一,可能會產生笛卡爾積,導致結果行數爆炸(但身份證號是唯一的,所以不存在這個問題)。
- 會比
- 預計運行時間:1秒左右。與算法二同為首選標準方法。
算法四:使用數據庫(SQLite)
原理與步驟
將數據加載到內存數據庫(如SQLite)中,使用SQL語言的IN或JOIN語句來讓數據庫引擎完成高效的查找工作。
- 創建內存數據庫:使用
sqlite3模塊在內存中創建一個臨時數據庫。 - 導入數據:將兩個Pandas DataFrame分別寫入數據庫中的兩個表(例如
small_table和large_table)。 - 執行SQL查詢:編寫SQL查詢語句(例如
SELECT large_table.* FROM large_table WHERE large_table.id_card IN (SELECT id_card FROM small_table))。 - 獲取結果:將SQL查詢的結果讀回一個Pandas DataFrame。
- 保存結果:同算法一。
Python實現
import sqlite3def algorithm_4_sqlite(small_file, large_file, output_file):"""算法4:使用SQLite內存數據庫"""print("算法4:SQLite內存數據庫 - 開始執行")start_time = time.time()# 1. 加載數據small_df = pd.read_excel(small_file)large_df = pd.read_excel(large_file)small_df['id_card'] = small_df['id_card'].astype(str)large_df['id_card'] = large_df['id_card'].astype(str)# 2. 創建內存數據庫連接conn = sqlite3.connect(':memory:')# 3. 導入數據到數據庫small_df.to_sql('small_table', conn, index=False)large_df.to_sql('large_table', conn, index=False)# 4. 編寫并執行SQL查詢# 方法A: 使用IN子句query = """SELECT large_table.* FROM large_table WHERE large_table.id_card IN (SELECT id_card FROM small_table)"""# 方法B: 使用INNER JOIN (通常數據庫會對JOIN優化得更好)# query = """# SELECT l.* # FROM large_table l# INNER JOIN small_table s ON l.id_card = s.id_card# """result_df = pd.read_sql_query(query, conn)# 5. 關閉連接conn.close()# 6. 保存結果result_df.to_excel(output_file, index=False)end_time = time.time()execution_time = end_time - start_timeprint(f"算法4完成。找到 {len(result_df)} 條匹配記錄。耗時: {execution_time:.4f} 秒")return execution_timetime_4 = algorithm_4_sqlite('small.xlsx', 'large.xlsx', 'result_4.xlsx')
優劣對比
- 優點:
- 非常高效。SQLite等數據庫引擎是專門為快速數據查詢而設計的,會自動為連接鍵創建索引以加速查詢(雖然在這個一次性操作中我們沒顯式創建,但它的查詢優化器仍然很強大)。
- 處理海量數據時優勢更明顯。如果數據量大到Pandas操作困難,可以改用磁盤數據庫,并顯式創建索引。
- 可以利用強大的SQL語法處理極其復雜的匹配邏輯。
- 缺點:
- 實現步驟稍多,需要將數據導入導出數據庫,增加了額外的I/O開銷(盡管是在內存中)。
- 對于這種規模的問題,其性能通常略慢于純Pandas的向量化操作(算法二和三),因為多了數據遷移的步驟。
- 預計運行時間:1-3秒。在數據量極大(數千萬以上)或匹配邏輯復雜時,此方法優勢會顯現。
算法五:分塊處理 (Chunking)
原理與步驟
這個算法并非用于提升速度,而是用于解決內存不足的問題。當large.xlsx文件巨大(例如幾個GB),無法一次性讀入內存時,就需要使用此方法。它結合了算法二的思想。
- 加載小數據:將
small.xlsx全部讀入內存,并創建集合S。 - 分塊讀取大數據:使用Pandas的
read_excel()的chunksize參數,分批讀取large.xlsx。每次只讀取一個塊(例如10000行)到內存中。 - 逐塊處理:對于每個數據塊,使用
isin(S)方法篩選出匹配的行。 - 累積結果:將每個塊的處理結果追加到一個列表中,或者直接寫入結果文件。
- 合并保存結果:處理完所有塊后,將累積的結果合并并保存,或者由于是逐塊寫入文件,最后只需要確保文件關閉即可。
Python實現
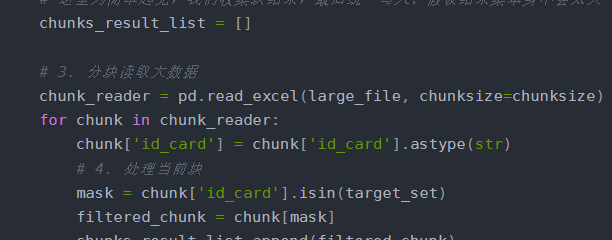
def algorithm_5_chunking(small_file, large_file, output_file, chunksize=10000):"""算法5:分塊處理(用于內存不足的大文件場景)"""print("算法5:分塊處理 - 開始執行")start_time = time.time()# 1. 加載小數據并創建集合small_df = pd.read_excel(small_file)small_df['id_card'] = small_df['id_card'].astype(str)target_set = set(small_df['id_card'])# 2. 初始化一個列表來存儲每個塊的結果,或者直接寫入文件# 我們采用直接寫入文件的方式,避免在內存中累積巨大的DataFramefirst_chunk = True# 使用一個csv writer或者每次追加DataFrame到Excel比較麻煩。# 更簡單的方法是:使用一個列表收集結果DF,最后再concat。但如果結果也很大,內存會爆。# 因此,我們使用‘a’(append)模式寫入Excel,但注意OpenPyXL需要每次創建一個新的writer對象。# 這里為簡單起見,我們收集塊結果,最后統一寫入。假設結果集本身不會太大(最多140000行中的一小部分)。chunks_result_list = []# 3. 分塊讀取大數據chunk_reader = pd.read_excel(large_file, chunksize=chunksize)for chunk in chunk_reader:chunk['id_card'] = chunk['id_card'].astype(str)# 4. 處理當前塊mask = chunk['id_card'].isin(target_set)filtered_chunk = chunk[mask]chunks_result_list.append(filtered_chunk)print(f"已處理一個數據塊,該塊找到 {len(filtered_chunk)} 條匹配記錄。")# 5. 合并結果并保存if chunks_result_list:final_result_df = pd.concat(chunks_result_list, ignore_index=True)else:final_result_df = pd.DataFrame() # 創建一個空DataFramefinal_result_df.to_excel(output_file, index=False)end_time = time.time()execution_time = end_time - start_timeprint(f"算法5完成。找到 {len(final_result_df)} 條匹配記錄。耗時: {execution_time:.4f} 秒")return execution_time# 這個算法主要用于演示大文件處理,對于140000行數據,沒必要分塊。
# time_5 = algorithm_5_chunking('small.xlsx', 'large.xlsx', 'result_5.xlsx', chunksize=50000)
優劣對比
- 優點:
- 內存友好。核心優勢是能夠處理大于內存的數據文件,因為它永遠不會同時將整個大表加載到內存中。
- 結合了Pandas向量化操作的效率。
- 缺點:
- 速度可能稍慢:由于需要多次讀取文件、循環處理每個塊,會產生額外的I/O開銷和循環開銷。比算法二、三要慢。
- 實現稍復雜。
- 預計運行時間:2-5秒(主要開銷在分塊讀取Excel上)。只有在處理超大文件、內存不足時才需要使用。對于140000條記錄,完全不需要分塊。
總結與最終對比
我們將五種算法的優缺點和適用場景總結如下:
| 算法 | 優點 | 缺點 | 預計時間 | 推薦度 |
|---|---|---|---|---|
| 1. 暴力循環 | 實現簡單 | 速度極慢,無法忍受 | ~30分鐘以上 | ?(絕不推薦) |
| 2. Pandas isin() | 實現簡單,速度最快 | 需要內存容納小表集合 | <1秒 | ?????(首選) |
| 3. Pandas Merge | 實現簡單,速度最快 | 略有額外開銷 | ~1秒 | ?????(首選) |
| 4. SQLite | 高效,支持復雜查詢,海量數據優勢 | 步驟稍多,數據遷移開銷 | 1-3秒 | ????(備用方案) |
| 5. 分塊處理 | 內存友好,可處理超大文件 | 速度較慢,實現稍復雜 | 2-5秒 | ???(特殊場景) |
最終結論與建議:
-
對于你的具體問題(5000條 vs 140000條):
- 毫不猶豫地選擇算法二(
isin())或算法三(merge())。它們是專門為這種表格數據操作設計的,代碼簡潔、效率最高。兩者性能差異可以忽略不計,按個人編碼喜好選擇即可。
- 毫不猶豫地選擇算法二(
-
如果你的小表也變得非常大(例如上百萬條):
- 算法二和三仍然有效,但創建集合或進行合并的內存消耗會變大。此時需要確保你的機器有足夠RAM。
-
如果你的大表巨大(例如幾十GB,無法讀入內存):
- 選擇算法五(分塊處理),它是解決此類問題的標準范式。
-
如果你的匹配邏輯變得非常復雜(不僅僅是相等匹配):
- 考慮使用算法四(SQLite),利用SQL強大的表達能力來編寫復雜查詢,或者使用專門的記錄鏈接庫(如
recordlinkage)。
- 考慮使用算法四(SQLite),利用SQL強大的表達能力來編寫復雜查詢,或者使用專門的記錄鏈接庫(如
-
算法一(暴力循環):永遠只存在于教學示例中,用于提醒大家時間復雜度的重要性。
代碼執行:你可以創建一個主函數來運行和比較這些算法(除了算法一)。
if __name__ == '__main__':files = ('small.xlsx', 'large.xlsx')times = {}times['alg_2'] = algorithm_2_pandas_isin(*files, 'result_2.xlsx')times['alg_3'] = algorithm_3_pandas_merge(*files, 'result_3.xlsx')times['alg_4'] = algorithm_4_sqlite(*files, 'result_4.xlsx')# 對于這個數據量,算法5可能比2和3慢,但可以測試times['alg_5'] = algorithm_5_chunking(*files, 'result_5.xlsx', chunksize=50000) print("\n=== 所有算法耗時對比 ===")for alg, t in times.items():print(f"{alg}: {t:.4f} 秒")
在實際運行中,你會看到算法二和三以絕對優勢勝出。
 的必會知識點匯總)
?? 詳解)

)







)
)


)


![[從零開始面試算法] (11/100) LeetCode 226. 反轉二叉樹:遞歸的“鏡像”魔法](http://pic.xiahunao.cn/[從零開始面試算法] (11/100) LeetCode 226. 反轉二叉樹:遞歸的“鏡像”魔法)
