?想要掌握如何將大模型的力量發揮到極致嗎?葉梓老師帶您深入了解 Llama Factory —— 一款革命性的大模型微調工具。
1小時實戰課程,您將學習到如何輕松上手并有效利用 Llama Factory 來微調您的模型,以發揮其最大潛力。
CSDN教學平臺錄播地址:https://edu.csdn.net/course/detail/39987
視頻號(直播分享):sphuYAMr0pGTk27? 抖音號:44185842659
現有視覺語言模型(VLMs)在提升輸入圖像分辨率以優化文本密集型圖像理解任務性能時,面臨視覺編碼器效率低下的核心問題:主流視覺編碼器(如 ViTs)在高分辨率下會產生大量 tokens,導致編碼延遲顯著增加,同時過多 tokens 還會延長大模型的預填充時間,最終使得模型的首 token 生成時間(TTFT)大幅上升,難以平衡分辨率、延遲與精度三者關系。為解決這一問題,Apple 團隊提出?FastVLM?模型,其核心創新在于引入新型混合視覺編碼器?FastViTHD,通過優化視覺編碼流程與 token 生成機制,在無需額外 token 修剪操作的前提下,僅通過縮放輸入圖像即可實現分辨率、延遲與精度的最優權衡。
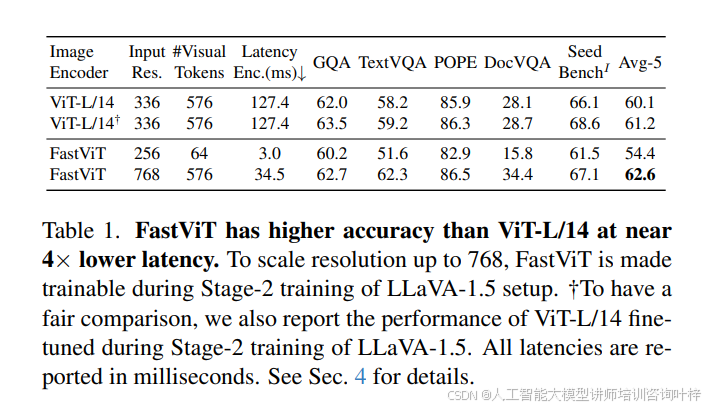
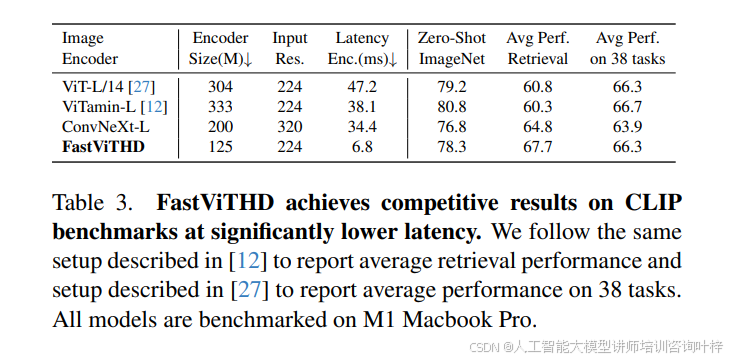
FastVLM 的設計圍繞視覺編碼器與大模型的協同優化展開。在視覺編碼器層面,團隊首先探索了 FastViT 混合架構在 VLM 中的應用,發現其憑借卷積組件的原生分辨率縮放能力與 Transformer 塊的高質量 token 生成特性,展現出顯著優勢。如?表 1?所示,當 FastViT 輸入分辨率縮放至 768×768 時,能生成與 ViT-L/14(336×336 分辨率)相同數量的視覺 tokens,但在 TextVQA、DocVQA 等文本密集型基準測試中性能更優,且編碼速度更快 —— latency 僅為 34.5ms,遠低于 ViT-L/14 的 127.4ms,同時參數規模僅為 ViT-L/14 的 1/8.7。為進一步提升高分辨率場景下的效率,團隊對 FastViT 進行架構優化,提出 FastViTHD:通過增加額外下采樣階段,使自注意力層在 32 倍下采樣的張量上運行(而非現有模型的 16 倍),最終生成的 tokens 數量比 FastViT 減少 4 倍,比 ViT-L/14(336 分辨率)減少 16 倍。表 3?數據顯示,FastViTHD 雖參數規模僅 125M(為 ViT-L/14 的 1/2.4),但在 38 項多模態零樣本任務中平均性能與 ViT-L/14 持平,且編碼 latency 僅 6.8ms,是 ViT-L/14 的 1/6.9,同時在檢索任務上的平均性能還優于混合架構 ViTamin-L。
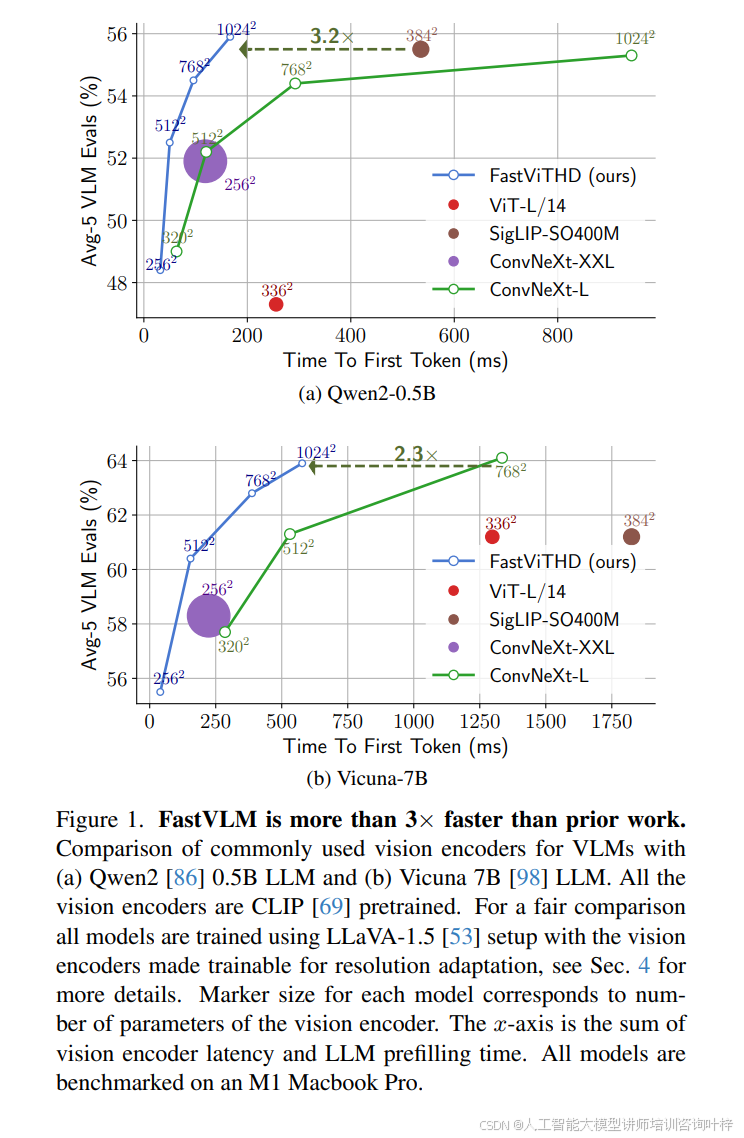
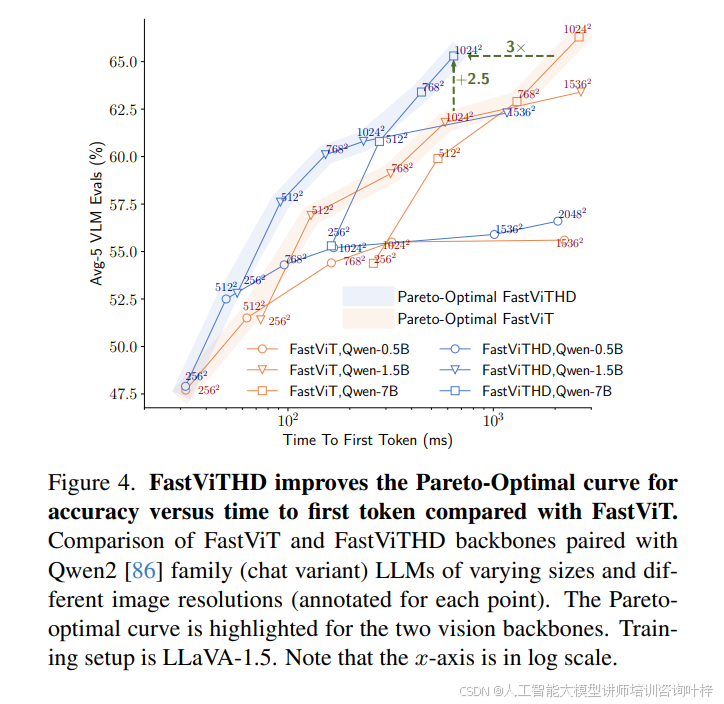
在模型性能與效率的平衡驗證中,圖 1?通過對比 FastViTHD 與 ViT-L/14、SigLIP-SO400M 等主流視覺編碼器在不同大模型(Qwen2-0.5B、Vicuna-7B)下的表現,直觀展現了 FastVLM 的優勢:在 Qwen2-0.5B 大模型搭配下,FastViTHD 對應的 Avg-5 VLM 評估分數達 62%,而 TTFT 僅約 400ms,是 ViT-L/14(TTFT 約 800ms,分數 52%)的 1/2,同時參數規模更小(標記尺寸對應參數數量,FastViTHD 標記顯著小于 ViT-L/14)。圖 4?則進一步通過帕累托最優曲線對比 FastViTHD 與 FastViT 的性能 - 延遲關系:在相同 TTFT 預算下,FastViTHD 對應的 Avg-5 分數比 FastViT 高 2.5 個百分點以上;若目標性能一致,FastViTHD 可實現最高 3 倍的 TTFT 加速,且這一優勢在不同分辨率與大模型規模組合下均穩定存在。
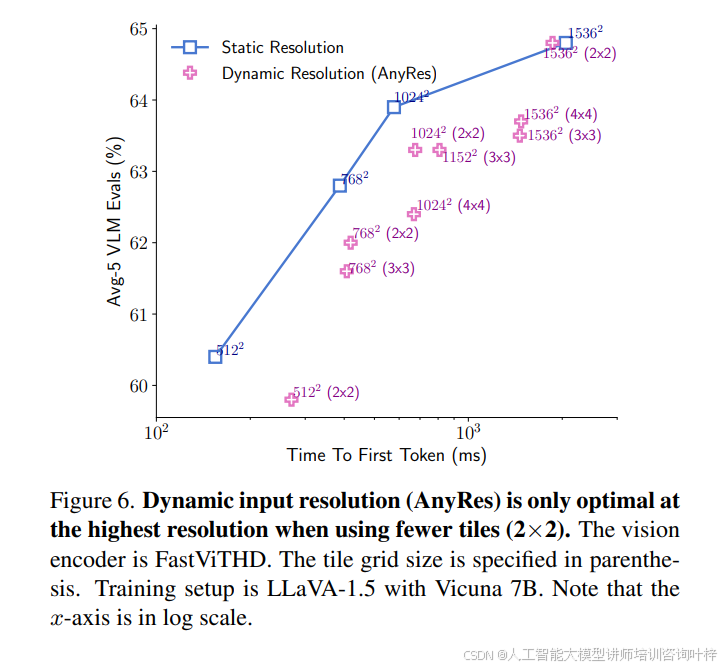 FastVLM 在靜態與動態分辨率策略的選擇上也有明確結論。圖 6?顯示,當輸入分辨率未達到極端值(如 1536×1536)時,直接將模型輸入分辨率設置為目標分辨率的靜態策略,比 AnyRes 動態分塊策略(如 768×768 拆分為 2×2、3×3 塊)更優 —— 相同 TTFT 下靜態策略的 Avg-5 分數更高,僅在 1536×1536 分辨率且分塊數量較少(2×2)時,動態策略才展現出一定競爭力,這主要源于極端分辨率下的內存帶寬限制。此外,表 5?對比 FastViTHD 與現有 token 修剪方法(如 ViT-L/14 M3、VisionZip)發現,FastViTHD 無需復雜的 token 修剪機制,僅通過降低輸入分辨率(如 256×256)即可生成低至 16 個的視覺 tokens,且在 GQA(60.6)、TextVQA(53.1)等基準測試中分數高于多數修剪方法(如 ViT-L/14 M3 16 個 tokens 時 GQA 僅 58.0),驗證了其架構設計的高效性。
FastVLM 在靜態與動態分辨率策略的選擇上也有明確結論。圖 6?顯示,當輸入分辨率未達到極端值(如 1536×1536)時,直接將模型輸入分辨率設置為目標分辨率的靜態策略,比 AnyRes 動態分塊策略(如 768×768 拆分為 2×2、3×3 塊)更優 —— 相同 TTFT 下靜態策略的 Avg-5 分數更高,僅在 1536×1536 分辨率且分塊數量較少(2×2)時,動態策略才展現出一定競爭力,這主要源于極端分辨率下的內存帶寬限制。此外,表 5?對比 FastViTHD 與現有 token 修剪方法(如 ViT-L/14 M3、VisionZip)發現,FastViTHD 無需復雜的 token 修剪機制,僅通過降低輸入分辨率(如 256×256)即可生成低至 16 個的視覺 tokens,且在 GQA(60.6)、TextVQA(53.1)等基準測試中分數高于多數修剪方法(如 ViT-L/14 M3 16 個 tokens 時 GQA 僅 58.0),驗證了其架構設計的高效性。
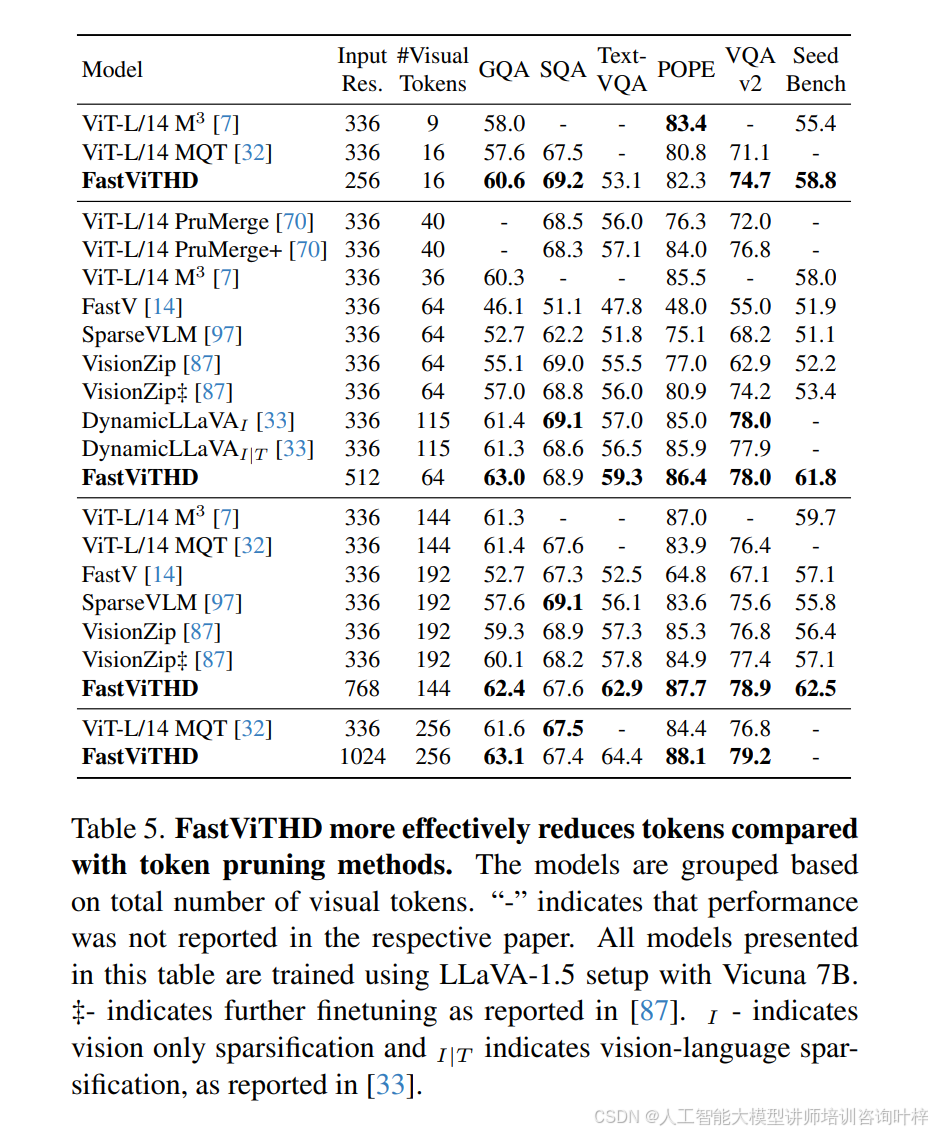
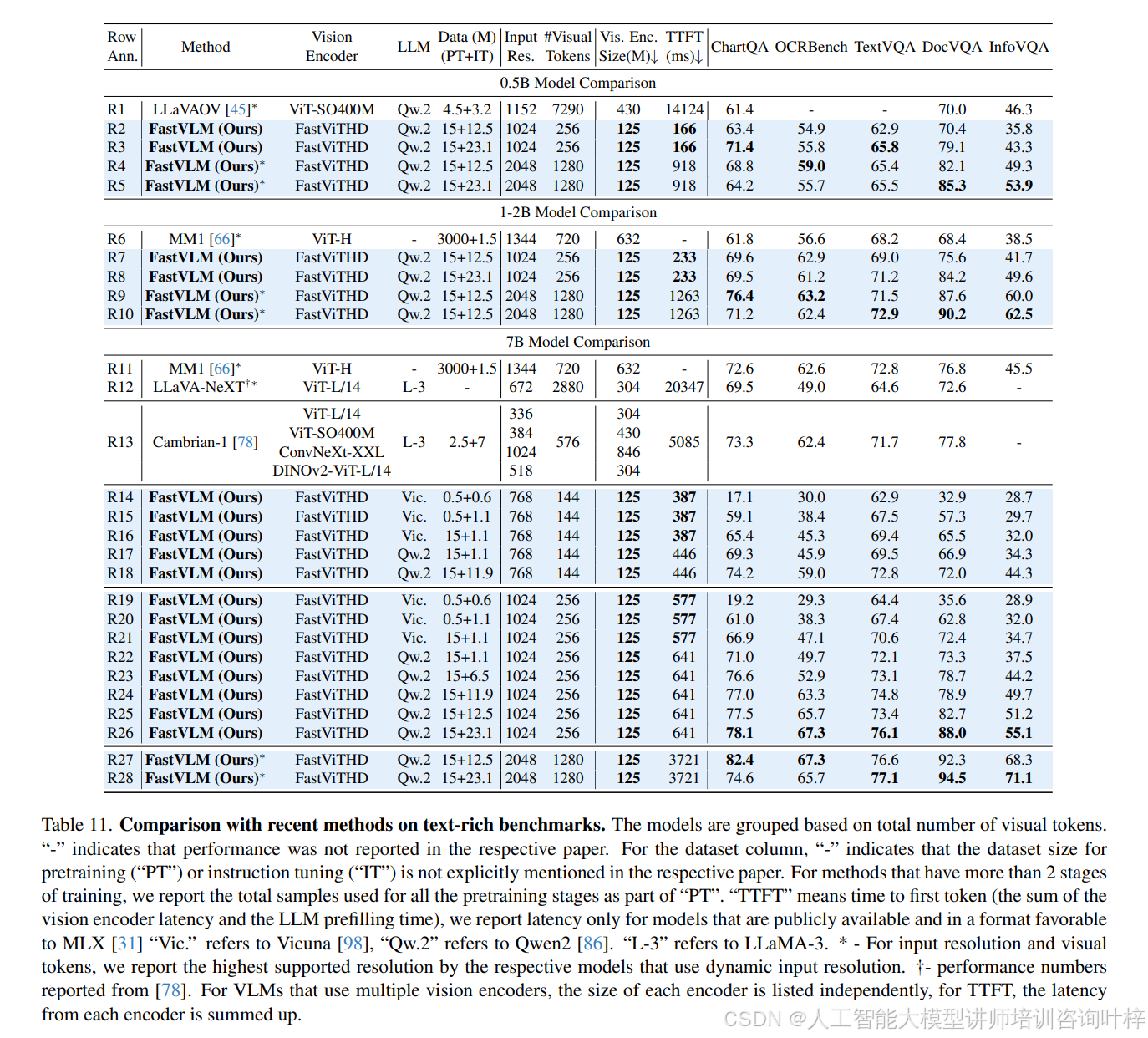
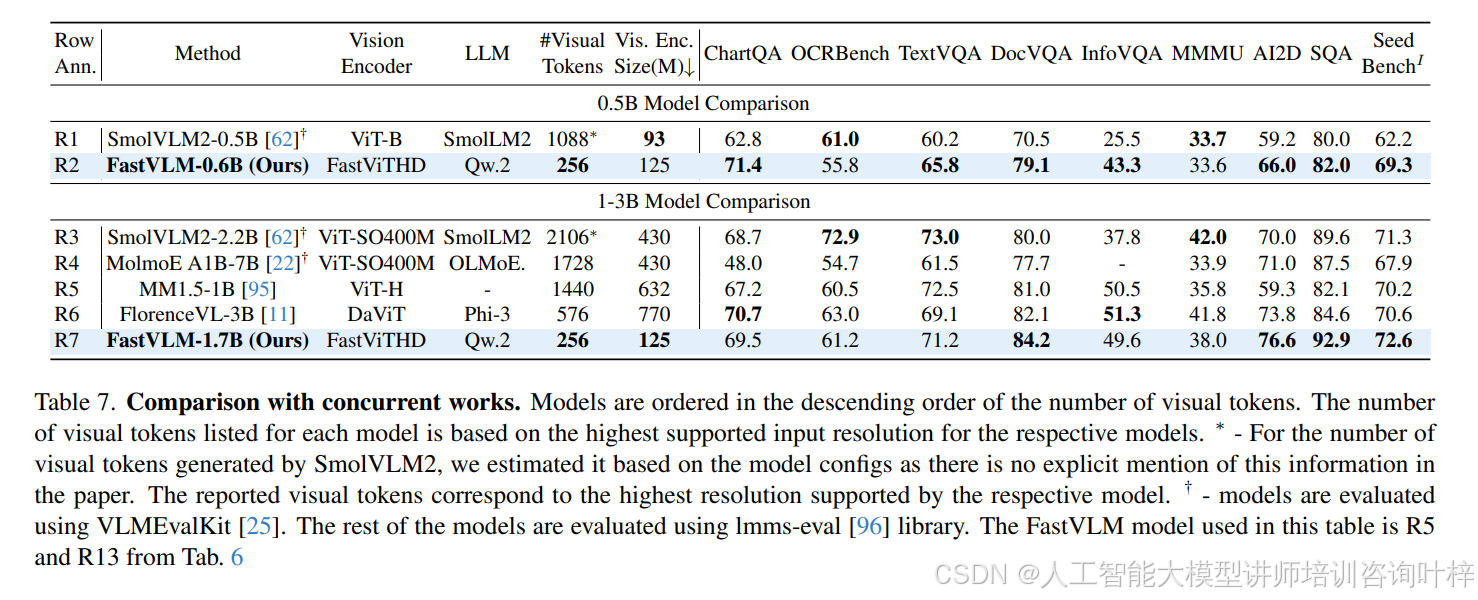
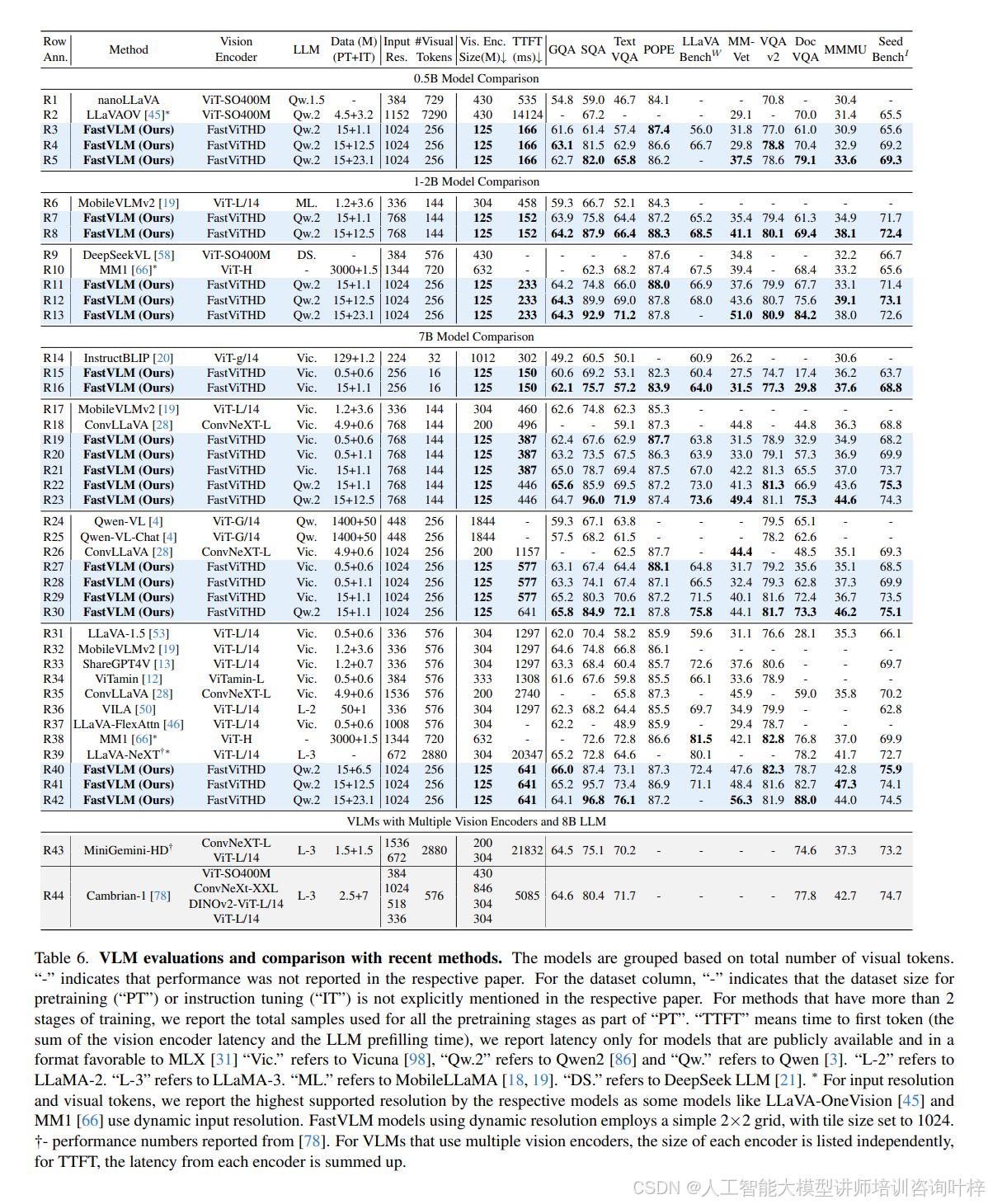 在與現有主流 VLM 的對比中,FastVLM 展現出顯著的性能 - 效率優勢。表 6?顯示,與 LLaVA-OneVision(使用相同 0.5B Qwen2 大模型,1152×1152 分辨率)相比,FastVLM(1024×1024 分辨率)在 SeedBench、MMMU、DocVQA 等關鍵基準測試中性能更優(如 SeedBench I 達 69.2,LLaVA-OneVision 為 65.5),同時 TTFT 僅 166ms,是前者(14124ms)的 1/85,視覺編碼器參數規模也僅為前者(SigLIP-SO400M,430M)的 1/3.4。與 ConvLLaVA(Vicuna-7B 大模型,768×768 分辨率)相比,FastVLM 在 TextVQA(67.5 vs 59.1)、DocVQA(57.3 vs 44.8)上分數更高,TTFT 卻從 496ms 降至 387ms,參數規模從 200M 縮減至 125M。即使面對多視覺編碼器模型(如 Cambrian-1,使用 ViT-L/14、ConvNeXt-XXL 等多個編碼器),FastVLM 單編碼器設計仍更高效 ——表 10?顯示 Cambrian-1 的 TTFT 約 5085ms,而 FastVLM(1024×1024 分辨率,Qwen2-7B 大模型)僅 641ms,是前者的 1/7.9,同時?表 11?中文本密集型任務(如 DocVQA 82.7 vs 77.8)性能更優。
在與現有主流 VLM 的對比中,FastVLM 展現出顯著的性能 - 效率優勢。表 6?顯示,與 LLaVA-OneVision(使用相同 0.5B Qwen2 大模型,1152×1152 分辨率)相比,FastVLM(1024×1024 分辨率)在 SeedBench、MMMU、DocVQA 等關鍵基準測試中性能更優(如 SeedBench I 達 69.2,LLaVA-OneVision 為 65.5),同時 TTFT 僅 166ms,是前者(14124ms)的 1/85,視覺編碼器參數規模也僅為前者(SigLIP-SO400M,430M)的 1/3.4。與 ConvLLaVA(Vicuna-7B 大模型,768×768 分辨率)相比,FastVLM 在 TextVQA(67.5 vs 59.1)、DocVQA(57.3 vs 44.8)上分數更高,TTFT 卻從 496ms 降至 387ms,參數規模從 200M 縮減至 125M。即使面對多視覺編碼器模型(如 Cambrian-1,使用 ViT-L/14、ConvNeXt-XXL 等多個編碼器),FastVLM 單編碼器設計仍更高效 ——表 10?顯示 Cambrian-1 的 TTFT 約 5085ms,而 FastVLM(1024×1024 分辨率,Qwen2-7B 大模型)僅 641ms,是前者的 1/7.9,同時?表 11?中文本密集型任務(如 DocVQA 82.7 vs 77.8)性能更優。
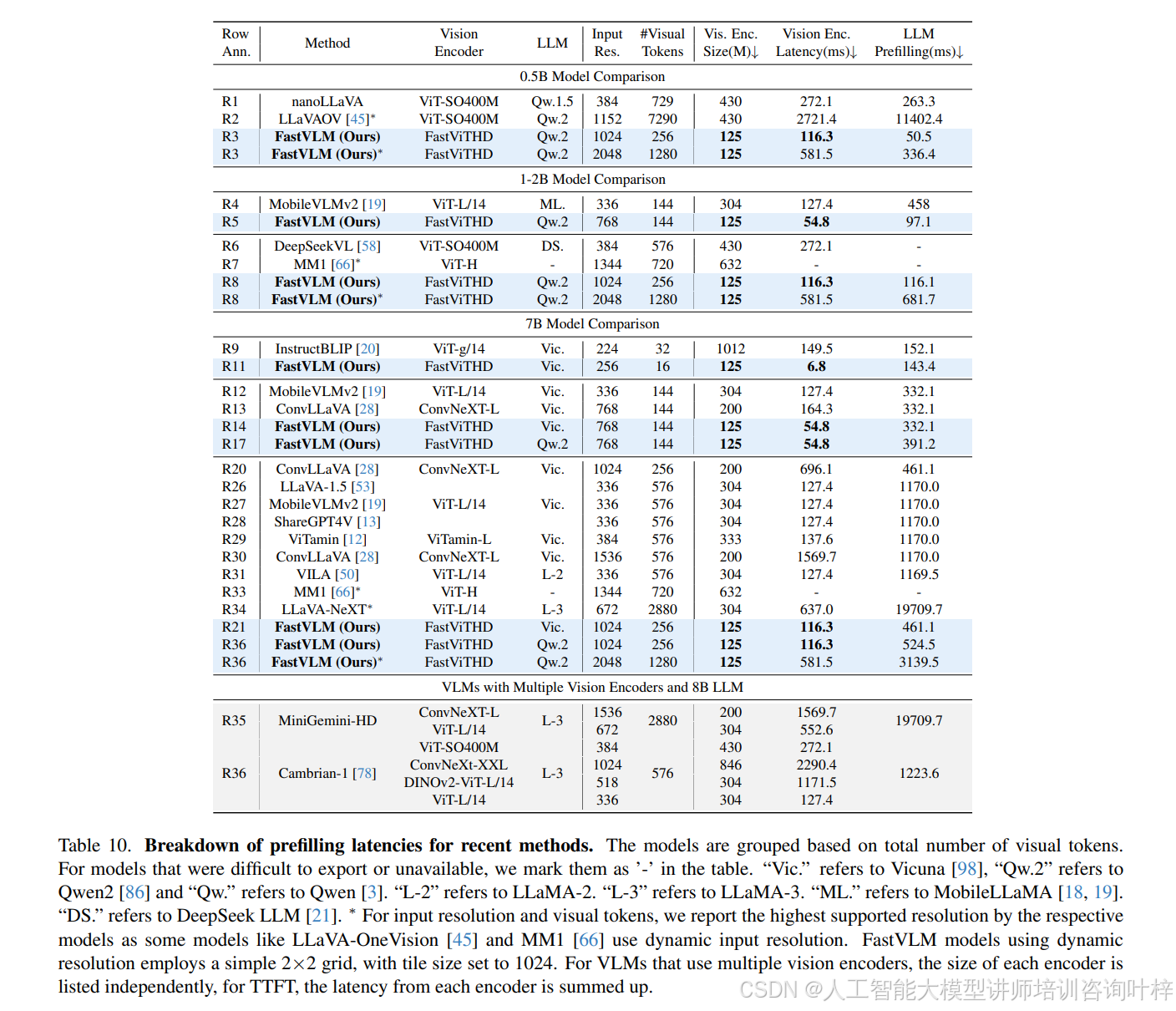
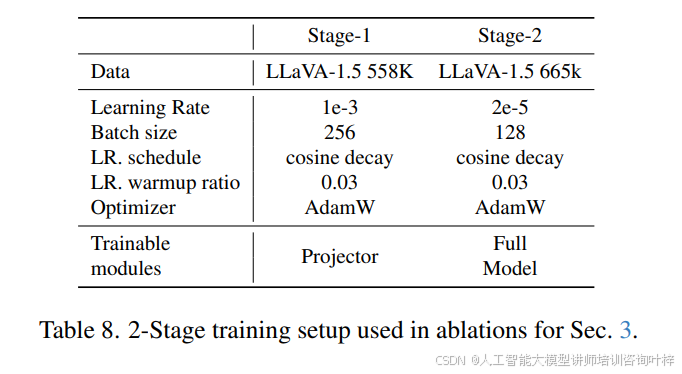
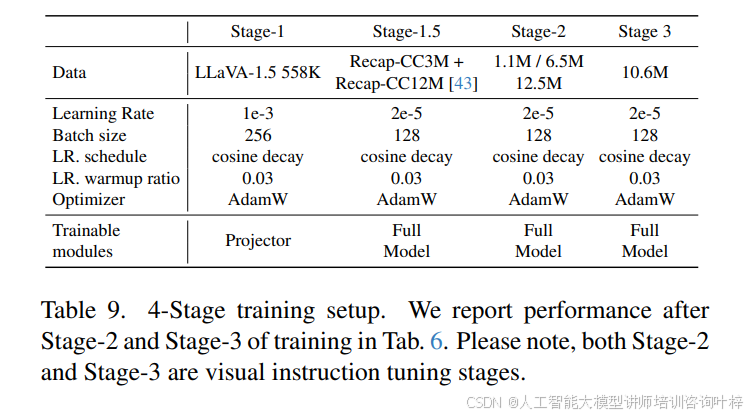 FastVLM 的訓練流程采用多階段優化策略,表 8?與?表 9?詳細列出了 2 階段與 4 階段訓練的參數設置:2 階段訓練中,Stage-1 僅訓練投影層(學習率 1e-3,batch size 256),Stage-2 微調全模型(學習率 2e-5,batch size 128);4 階段訓練則新增 Stage-1.5(分辨率適應預訓練,使用 15M 樣本)與 Stage-3(高質量指令微調,如 MammothVL 數據集),進一步提升模型在高分辨率與復雜任務上的性能。表 7?顯示,隨著訓練數據規模擴大(如指令微調數據從 1.1M 增至 23.1M),FastVLM 在 ChartQA(71.4)、InfoVQA(43.3)等任務上的分數持續提升,驗證了其數據擴展性。
FastVLM 的訓練流程采用多階段優化策略,表 8?與?表 9?詳細列出了 2 階段與 4 階段訓練的參數設置:2 階段訓練中,Stage-1 僅訓練投影層(學習率 1e-3,batch size 256),Stage-2 微調全模型(學習率 2e-5,batch size 128);4 階段訓練則新增 Stage-1.5(分辨率適應預訓練,使用 15M 樣本)與 Stage-3(高質量指令微調,如 MammothVL 數據集),進一步提升模型在高分辨率與復雜任務上的性能。表 7?顯示,隨著訓練數據規模擴大(如指令微調數據從 1.1M 增至 23.1M),FastVLM 在 ChartQA(71.4)、InfoVQA(43.3)等任務上的分數持續提升,驗證了其數據擴展性。
https://www.arxiv.org/pdf/2412.13303
https://github.com/apple/ml-fastvlm




![[Linux] Linux標準塊設備驅動詳解:從原理到實現](http://pic.xiahunao.cn/[Linux] Linux標準塊設備驅動詳解:從原理到實現)




ES6前端開發核心:國際化與格式化、內存管理與性能)









