篇幅所限,本文只提供部分資料內容,完整資料請看下面鏈接
https://download.csdn.net/download/2501_92796370/91778320
資料解讀:《基于DeepSeek的數據治理技術》
詳細資料請看本解讀文章的最后內容。
作為數據治理領域的資深研究者,我很榮幸為大家解讀這份由數槳AI實驗室發布的《基于DeepSeek的數據治理技術》文件。這份資料系統性地介紹了如何利用DeepSeek這一先進的大模型技術來優化和提升數據治理工作的效率與質量,內容涵蓋從理論基礎到實踐應用的完整知識體系。
大模型技術基礎
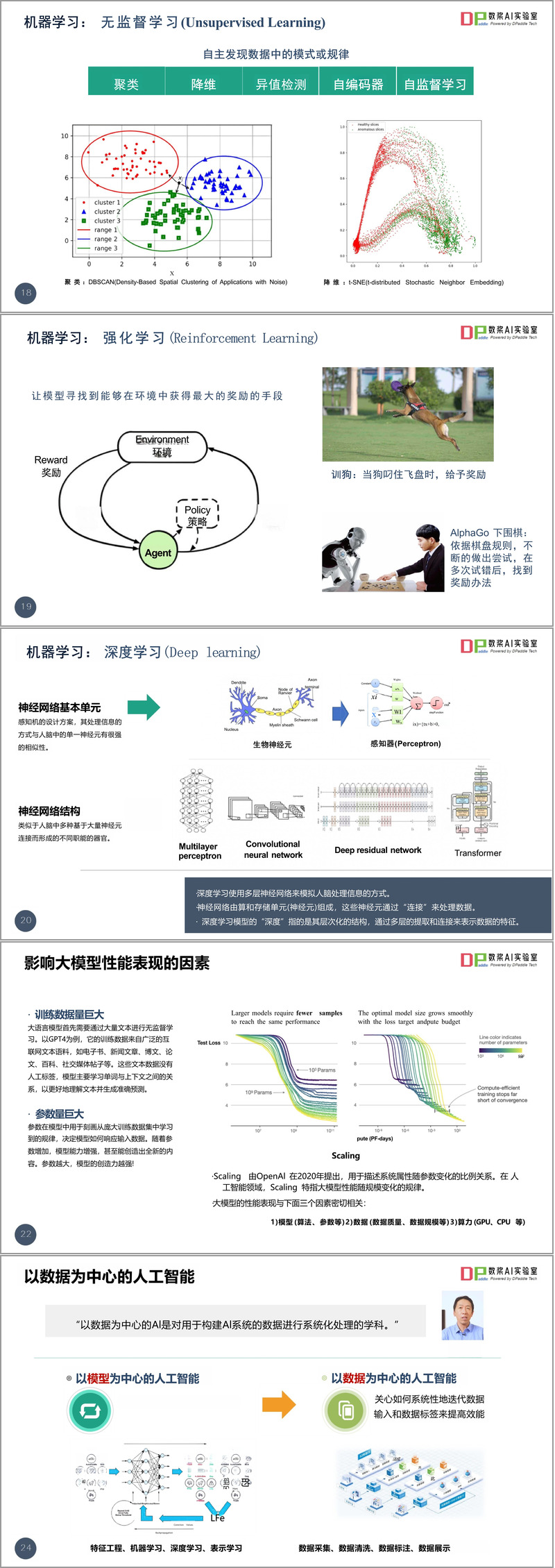
文件開篇首先闡述了人工智能與大模型的技術基礎。人工智能(AI)被定義為模擬人類智能的技術,使機器能夠學習、思考和決策。資料中詳細介紹了人工智能技術全景圖,包括機器學習、深度學習、大語言模型等核心技術分支。
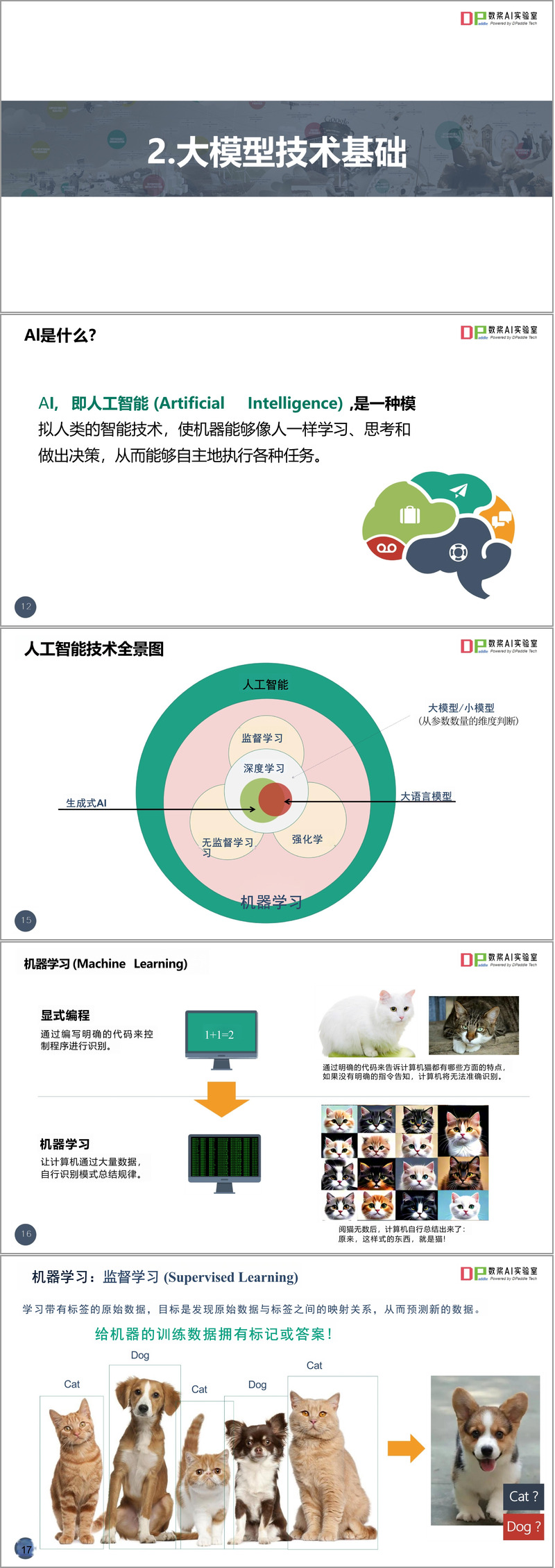
特別值得注意的是,文件對機器學習的不同范式進行了專業區分:監督學習通過標記數據訓練模型;無監督學習自主發現數據模式;強化學習則通過環境反饋優化策略。深度學習作為機器學習的重要分支,采用多層神經網絡模擬人腦處理信息的方式,其"深度"體現在層次化結構上。
DeepSeek技術架構
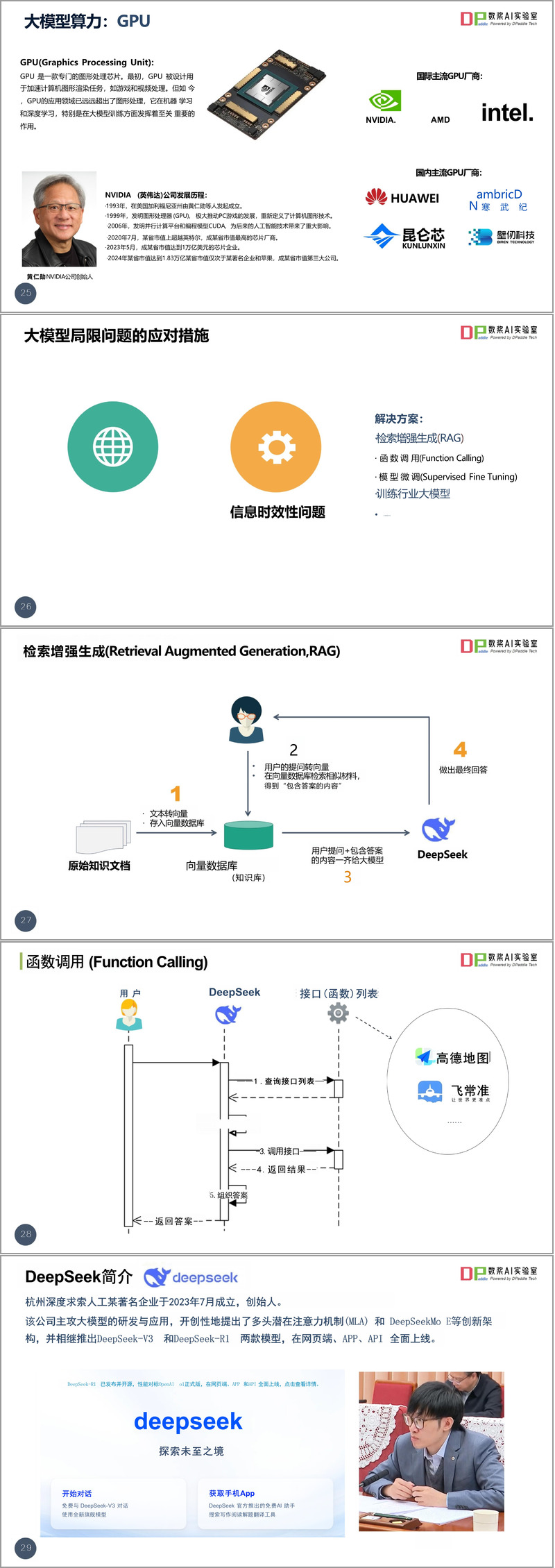
資料重點介紹了DeepSeek的技術特點。作為由深度求索公司開發的大語言模型,DeepSeek采用了創新的多頭潛在注意力機制(MLA)和MoE架構。目前推出的DeepSeek-V3是一款671B參數的通用型大模型,在多項評測中表現優異;而DeepSeek-R1則專注于復雜推理任務,采用強化學習技術顯著提升了推理能力。
文件詳細分析了影響大模型性能的關鍵因素:訓練數據量、參數量和計算資源。隨著參數增加,模型創造力和表現力顯著提升。DeepSeek采用了"以數據為中心"的AI開發理念,系統性地迭代優化數據質量,與傳統"以模型為中心"的方法形成鮮明對比。
數據治理應用場景
資料的核心部分深入探討了DeepSeek在數據治理各階段的應用價值:
在數據規劃階段,可輔助數據標準管理和質量評估;數據采集環節能實現清洗和標準化處理;存儲階段支持數據庫設計優化和元數據管理;應用層面則賦能自然語言查詢、文檔生成等場景。
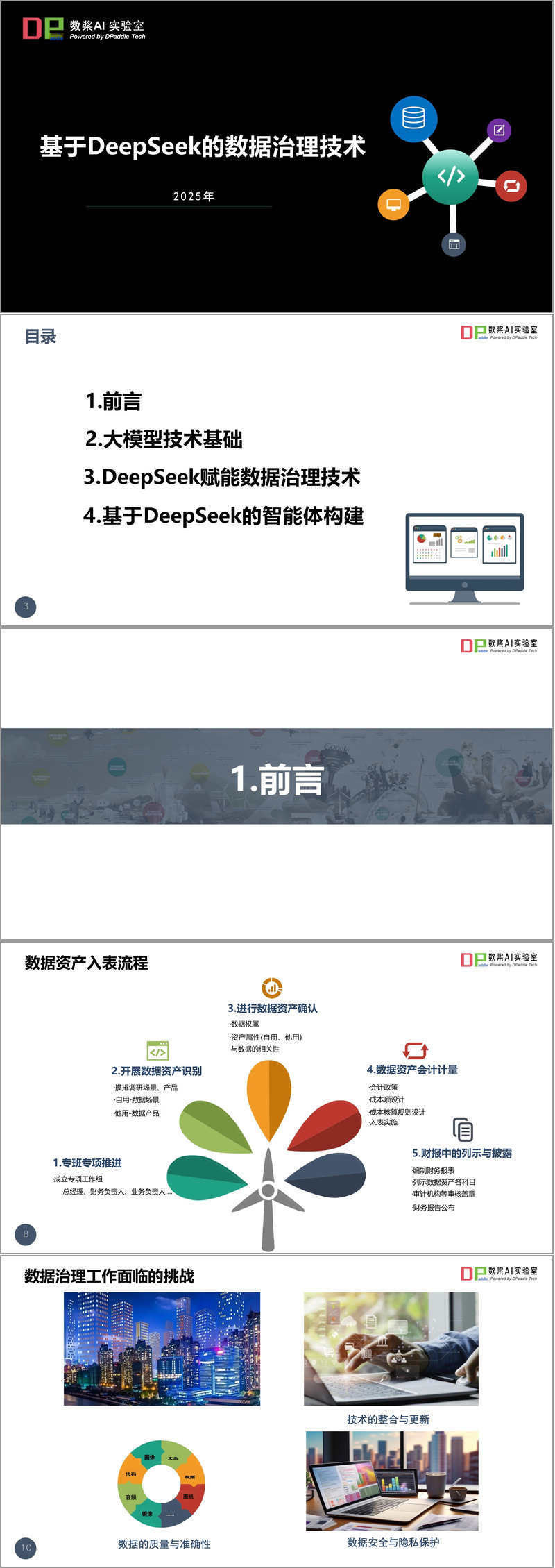
文件特別強調了DeepSeek在數據資產入表流程中的重要作用,包括數據資產識別、權屬確認、財務報表編制與披露等關鍵環節。同時也客觀分析了數據治理面臨的挑戰:技術整合更新、安全隱私保護、數據質量保證等問題。
核心技術能力解析
資料系統梳理了DeepSeek在自然語言處理方面的核心能力:
詞法和句法分析方面,模型可精準實現分詞、命名實體識別、詞性標注等任務。測試顯示,即使面對"丘處機"這類復雜人名,也能準確拆分姓和名。實體匿名化功能則可通過替換敏感信息保障隱私安全。
信息抽取能力包括關鍵詞提取、實體關系三元組抽取等。在一個足球新聞案例中,模型準確提取出"國足出線形勢"等關鍵短語并賦予合理權重;在ChatGPT描述文本中,成功抽取出"(ChatGPT,開發,OpenAI)"等結構化關系。
分類與聚類技術應用于文本分類、情感分析等場景。模型不僅能完成常規新聞分類,還能處理"simon語"這類小眾語言的小樣本分類任務。情感分析案例中,對社交網絡抱怨文本的消極情緒判斷準確。
高級文本處理能力
DeepSeek的受控文本生成能力令人印象深刻。資料展示了模型如何按照指定風格(如"極盡嘲笑")重寫《孔乙己》摘要,以及將結構化天氣數據轉化為自然語言描述的能力。
在問答系統方面,模型展現出強大的常識問答、跨語言問答和意圖識別能力。無論是用中英文描述《西游記》內容,還是準確識別"北京沙塵暴"查詢的天氣意圖,都表現出類人的理解水平。
技術實現層面,DeepSeek支持多種編程語言的代碼生成,并能根據自然語言描述生成符合規范的MySQL建表腳本,極大提升了開發效率。
實踐案例與建議
文件最后分享了數據清洗標準化的實際案例,展示如何利用DeepSeek處理多源異構的客戶數據。在結語部分,作者提出了對大模型時代數據治理工作的專業建議:
- 深入理解業務需求和數據現狀,制定合理治理目標
- 建立完善的數據治理體系框架
- 加強專業人才培養和團隊建設
- 建立定期復盤和持續優化機制
這份資料全面展現了DeepSeek在數據治理領域的技術優勢和應用前景,既有理論高度,又包含豐富實踐案例,為業界提供了寶貴的參考框架和方法論指導。
接下來請您閱讀下面的詳細資料吧。

)

)







)

及常見問題解答)





內容大綱)