一、大模型
T5\BERT\GPT → Transformer的兒子→自注意力機制+神經網絡
大模型, Large Model,是指參數規模龐大、訓練數據量巨大、具有強泛化能力的人工智能模型,典型代表如GPT、BERT、PaLM等。它們通常基于深度神經網絡,特別是Transformer架構,在自然語言處理、圖像識別、代碼生成等任務中表現出色。
1、基本概念

大模型是指在超大規模數據集上訓練、擁有數十億到千億以上參數的人工智能模型,具備多任務、多模態能力,并能通過少量樣本甚至零樣本完成新任務。
2、主要特征
大模型具備以下特征:
- 參數規模大
? 數億至數千億參數,容量決定了模型的表達與泛化能力。
- 數據訓練量大
? 利用海量文本、圖像、音頻等多模態數據訓練,提升模型的通用性。
- 基于Transformer
? 多數大模型采用Transformer作為基礎結構,具備強大的表示學習能力。
- 強泛化與遷移能力
? 一次訓練,多場景復用(如ChatGPT既能對話,也能寫代碼、改文案)。
- 具備“涌現能力”
? 模型規模突破某個閾值后,表現出超越訓練目標的智能行為(如邏輯推理、復雜生成)。
- 可調優能力強
? 支持微調(Fine-tuning)、提示學習(Prompt Learning)、參數高效調優(LoRA、Adapter等)。
- 多模態發展趨勢
? 從純文本模型發展到圖文、語音、視頻等多模態大模型,如GPT-4V、DeepSeek、Grok等
3、應用方向
-
Agent智能體(AI管家)
-
概念:像一個“全能私人助理”,能自己分析問題、拆解任務、調用工具解決問題。
-
例子:你想周末去露營,告訴它:“幫我找個離市區近、能帶寵物、有燒烤區的露營地,訂周六的房間,再推薦附近超市買食材。”它自動完成:搜攻略 → 篩選地點 → 查天氣 → 訂營地 → 生成購物清單 → 發到你手機。
-
好處:不用自己一步步操作,AI能“動腦子”幫你搞定復雜任務。
-
流程:用戶輸入 -> 拆解任務 -> 意圖識別 -> 調用對應的函數并執行 -> 完成執行
-
-
語音聊天助手(會聊天的AI)
-
概念:像“升級版Siri”,能自然對話、理解語氣,甚至模擬真人情感。
-
例子:你開車時說:“我好困啊,來點提神的音樂,再導航到最近的咖啡店。”它回答:“馬上切到搖滾歌單!前方500米有星巴克,要幫你點一杯冰美式嗎?”(還能學你喜歡的說話風格)
-
好處:不用打字,動動嘴就能聊天、查信息、控制智能家居,像有個“隨身陪聊”。
-
流程:語音輸入 -> 語音識別轉文字 -> 大模型對話 -> 文本轉語音 -> 完成對話
-
-
醫學客服(AI健康小助手)
-
概念:醫院的“虛擬前臺”,能解答常見問題、提醒用藥、分診建議。
-
例子:你半夜胃疼,打開醫院APP問:“吃了火鍋后胃痛,該掛哪個科?現在能吃什么藥緩解?”AI回答:“建議掛消化內科,暫時可服用XX藥(非處方)。若嘔吐加重,請立即急診。”并推送附近24小時藥店。
-
好處:24小時在線,快速解答小毛病,避免排隊問醫生,隱私問題也能匿名咨詢。
-
流程:問題輸入 -> 檢索知識庫 -> 問題拼接 -> 大模型對話 -> 給予回復
-
4、開發流程
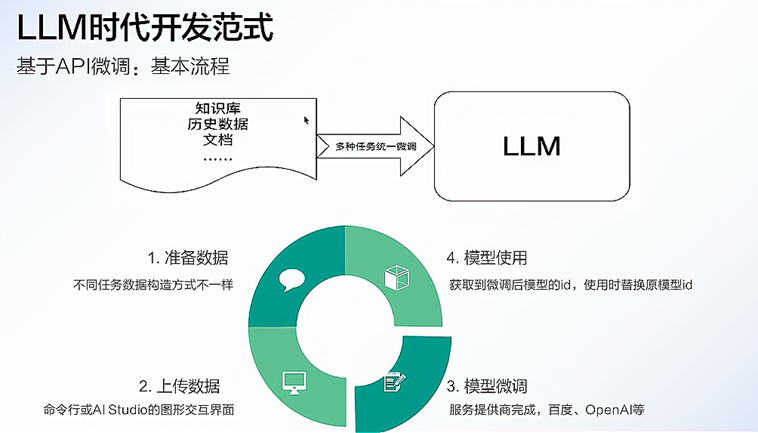
大模型開發是一個系統工程,涉及數據、模型、算力、訓練、部署、安全與迭代等多個環節。
-
任務定義與需求分析
-
明確應用場景(如對話、寫作、推薦、圖像識別等)
-
選擇模型類型(NLP、CV、多模態等)
-
-
數據準備與預處理
-
收集高質量、大規模數據(文本、圖像、音頻等)
-
去噪清洗、標注、格式轉換、去重與分詞等
-
-
模型設計與選擇
-
選擇合適的模型架構(如GPT、BERT、ViT、T5等)
-
設定層數、寬度、注意力機制等結構參數
-
-
訓練策略與資源配置
-
分布式訓練/混合精度訓練
-
使用大規模算力資源(GPU/TPU集群)
-
設置優化器(AdamW)、學習率調度等參數
-
-
評估與調優
-
評估指標:PPL、準確率、BLEU、ROUGE、F1等
-
微調/指令調優(Instruction tuning)/RLHF等方法提升效果
-
-
推理部署與壓縮優化
-
部署到服務器或邊緣端(云部署、API服務)
-
模型量化、裁剪、蒸餾、MoE等手段提升推理效率
-
-
安全機制與合規檢測
-
防止生成有害/敏感內容
-
對輸出進行內容審查、對抗樣本防御、模型水印等
-
-
持續迭代與生態構建
-
基于用戶反饋持續優化
-
構建插件系統、開發者平臺等生態體系
-
5、關鍵要點
-
在大模型應用開發時,不會從頭開始構建一個新的模型,基于已有基座模型進行二次開發是行業主流實踐。
-
選用已有的基座模型,并采用相應的技術手段優化大模型,如:微調,RAG,并行推理等。
-
選用流行且成熟的框架,通過參數調整和功能集成實現業務需求,避免重復造輪子。
6、項目介紹
- 簡歷

- 項目框架
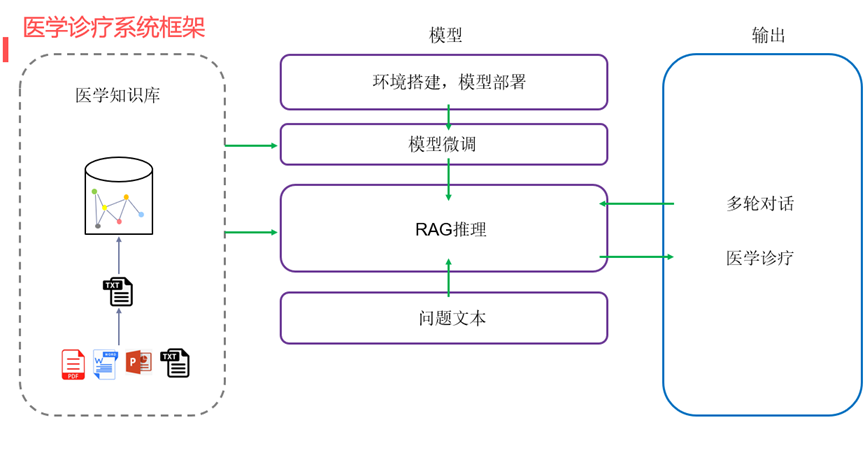
-
三個模塊
-
大語言模型(LLM)--實現大語言模型的對話功能:大模型的本地部署,微調訓練,流式對話,多輪對話。
-
RAG技術--增強大語言模型的對話能力:文本分割,文本嵌入,知識檢索
-
知識圖譜--實現數據的高效存儲:neo4j數據庫,三元組抽取,實體對齊
-
-
項目展示
 |
|---|
 |
二、LLM
開始實際案例的展示......
1、API調用
大模型通過API調用是目前最常見、最便捷的使用方式,用戶無需訓練模型,只需調用接口即可享受強大的 AI 能力,比如文本生成、翻譯、圖像識別、代碼補全等。
1.1 基本流程
-
獲取 API 權限
-
注冊平臺賬號(如 OpenAI、DeepSeek、阿里通義、訊飛星火等)
-
獲取
API Key或Access Token
-
-
準備請求參數
-
選擇模型
-
設置請求體
-
-
發起 API 請求
-
使用編程語言(如 Python、JavaScript)通過 HTTP 協議調用接口
-
-
解析響應結果
-
獲取模型返回內容(如文本、圖片鏈接、結構化數據等)
-
可與前端、應用系統集成使用
-
1.2 基本特征
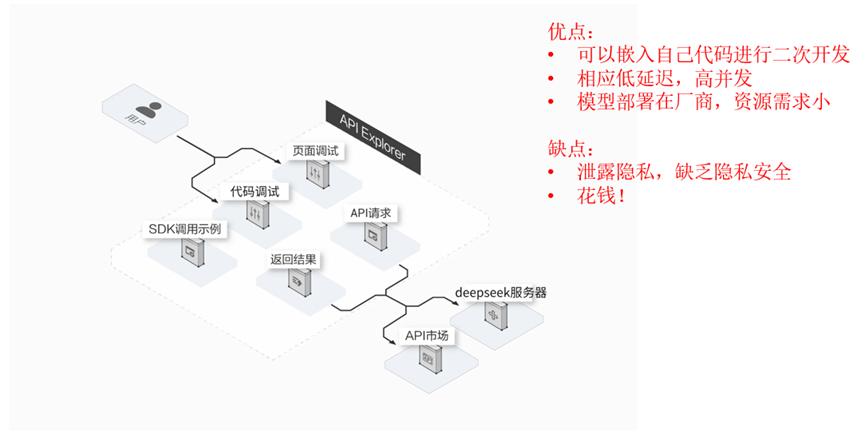
大模型API調用將復雜的模型能力簡化為標準化服務,核心價值在于:
-
降低使用門檻:無需本地部署千億參數模型,節省硬件與運維成本。
-
靈活適配場景:通過參數調節和上下文學習快速滿足業務需求。
-
規模化支持:依托云計算實現高可用、低延遲的企業級服務。
1.3 DeepSeek實操
DeepSeek作為國內優秀的LLM平臺,是一個不錯的選擇~
1.3.1 準備工作
-
訪問deepseek官網,并注冊賬號:DeepSeek官網
-
注冊賬號并且充值
-
創建API-key
僅在創建時可見可復制
-
查看使用手冊
1.3.2 非流式輸出
等模型生成完整結果后一次性返回,適合短文本、結構化內容提取等任務。
-
特點
-
優點:
-
使用簡單,一次性拿到完整結果
-
適合分析處理、摘要抽取、短文本問答等
-
-
缺點:
-
響應時間長,特別是文本很長時
-
體驗較差,用戶需要等待全部生成完才能看到內容
-
-
-
環境安裝
pip install openai -
非流式輸出
# Please install OpenAI SDK first: `pip3 install openai` from openai import OpenAI ? client = OpenAI(api_key="sk-f9deff6faca64899a3faaaf1f4c53d1d", base_url="https://api.deepseek.com" ) ? response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "明月幾時有"},],stream=False, ) ? print(response.choices[0].message.content) ? -
輸出結果
“明月幾時有”是蘇軾《水調歌頭·明月幾時有》中的名句,全文如下: ? **《水調歌頭·明月幾時有》** ? 明月幾時有?把酒問青天。 ? 不知天上宮闕,今夕是何年。 ? 我欲乘風歸去,又恐瓊樓玉宇,高處不勝寒。 ? 起舞弄清影,何似在人間。 ? ? 轉朱閣,低綺戶,照無眠。 不應有恨,何事長向別時圓? 人有悲歡離合,月有陰晴圓缺,此事古難全。 但愿人長久,千里共嬋娟。 ? ### 賞析: 1. **背景**:此詞作于宋神宗熙寧九年(1076年)中秋,蘇軾在密州(今山東諸城)任職時,懷念弟弟蘇 轍而寫。 2. **情感**:以月起興,圍繞中秋明月展開想象,交織人間情懷與宇宙哲思,既有對親人的思念,又有對 人生無常的豁達。 3. **名句**:- “人有悲歡離合,月有陰晴圓缺”道出世事無常的常態。- “但愿人長久,千里共嬋娟”成為表達遠方親友平安共勉的千古絕唱。 ? ? ### 小知識: 這首詞被譽為“中秋詞之冠”,后曾被改編為經典歌曲(如王菲演唱的《但愿人長久》)。若您想進一步探討其文學手法或創作背景,可以隨時告訴我!
1.3.3 流式輸出
服務器將響應內容一段一段地實時返回,適合長文本、對話、寫作等需要即時反饋的場景。
-
特點
-
優點
-
響應快:無需等全部生成完畢,先生成先返回
-
體驗佳:像人打字一樣流暢,常用于對話機器人
-
可中斷:用戶可隨時打斷流式響應過程
-
-
缺點
-
編程稍復雜,需要處理數據流拼接
-
不易直接使用普通 HTTP 請求工具(如 Postman)
-
-
-
原理

-
流式推理的實現—生成器
import time ? def test(): ?# 生成器函數for i in range(10):time.sleep(1)yield i ?# 生成器函數,使用yield關鍵字返回值 ? if __name__ == "__main__":aaa = test()print(aaa) ?# aaa是一個生成器,可以想象成一個隊列,每讀取一次,就會執行一次函數體for a in aaa:print(a) ?# 讀取生成器中的值
-
流式推理代碼編寫:
from openai import OpenAI ? client = OpenAI(api_key="sk-f9deff6faca64899a3faaaf1f4c53d1d", base_url="https://api.deepseek.com" ) ? response = client.chat.completions.create(model="deepseek-chat",messages=[{"role": "system", "content": "You are a helpful assistant"},{"role": "user", "content": "明月幾時有"},],stream=True, ) ? # 流式輸出 out = [] for chunk in response:print(chunk.choices[0].delta.content)out.append(chunk.choices[0].delta.content)print('-' * 10)print(''.join(out)) ?
1.3.4 總結對比
| 項目 | 流式輸出 | 非流式輸出 |
|---|---|---|
| 返回方式 | 邊生成邊返回 | 全部生成后一次返回 |
| 響應速度 | 快 | 慢(尤其是長文本) |
| 使用體驗 | 更自然(打字式) | 等待過程較長 |
| 編程復雜度 | 稍復雜(需拼接) | 簡單 |
| 適用場景 | 對話生成、直播問答 | 簡短回復、結構化處理 |
1.3.5 代碼封裝
將代碼封裝為類,方便其他文件調用此功能。
非流式輸出:
from openai import OpenAI
?
class DeepseekAPI:def __init__(self, api_key): ?# 初始化方法self.api_key = api_key ?# API密鑰self.client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com") ?# 實例化OpenAI客戶端
?def inference(self, messages):response = self.client.chat.completions.create(model="deepseek-chat",messages=messages, ?# 消息內容stream=False, ?# 設置為False以獲取完整響應)return response.choices[0].message.content ?# 返回完整響應
?
?
# 測試代碼
if __name__ == "__main__":api_key = "sk-f9deff6faca64899a3faaaf1f4c53d1d" ?# API密鑰messages = [{"role": "system", "content": "你是一名AI助手"},{"role": "user", "content": "請簡要介紹一下你自己"},] ?# 定義消息內容stream = False ?# 設置為True以獲取流式輸出,False以獲取完整響應deepseek_api = DeepseekAPI(api_key) ?# 實例化DeepseekAPI類result = deepseek_api.inference(messages) ?# 調用推理方法print(result) ?# 打印響應內容
?
流式輸出:
# 流式輸出:
from openai import OpenAI
?
class DeepseekAPI:def __init__(self, api_key): ?# 初始化方法self.api_key = api_key ?# API密鑰self.client = OpenAI(api_key=api_key, base_url="https://api.deepseek.com") ?# 實例化OpenAI客戶端
?def inference(self, messages):response = self.client.chat.completions.create(model="deepseek-chat",messages=messages, ?# 消息內容stream=True, ?# 設置為False以獲取完整響應)for chunk in response: ?# 遍歷響應的每個塊if chunk.choices: ?# 如果塊中有返回內容content = chunk.choices[0].delta.content ?# 獲取內容yield content ?# 逐塊返回內容
?
# 測試代碼
if __name__ == "__main__":api_key = "sk-f9deff6faca64899a3faaaf1f4c53d1d" ?# API密鑰messages = [{"role": "system", "content": "你是一名樂于助人的人工智能助手"},{"role": "user", "content": "請簡要介紹一下你自己"},] ?# 定義消息內容stream = False ?# # 設置為True以獲取流式輸出,False以獲取完整響應deepseek_api = DeepseekAPI(api_key) ?# 實例化DeepseekAPI類result = deepseek_api.inference(messages) ?# 調用推理方法for chunk in result: ?# 遍歷響應的每個塊print(chunk, end="") ?# 打印每個塊的內容
?
三、大模型本地部署
各種大模型
國內:ModelScope 魔搭社區
國際:https://huggingface.co/
鏡像:HF-Mirror
1、基本介紹
官網: 通義大模型_AI大模型_一站式大模型推理和部署服務-阿里云
開源:https://github.com/QwenLM/Qwen
在國產大模型領域,Qwen系列一直穩居前列,其出色的性能使其在多項評測中名列前茅。作為阿里巴巴的一項重要研發成果,Qwen系列的開源版本在業內備受矚目,且長期以來在各大榜單上表現優異。
-
多模態能力:部分版本支持文本、圖像、音頻等多模態輸入與生成。
-
超長上下文:最新模型支持高達128K tokens的上下文窗口,適合長文檔處理。
-
高性能:在權威基準(如MMLU、C-Eval)上表現優異,接近或超越國際主流模型。
-
工具調用:支持外部API調用、代碼解釋器等,增強復雜任務處理能力。
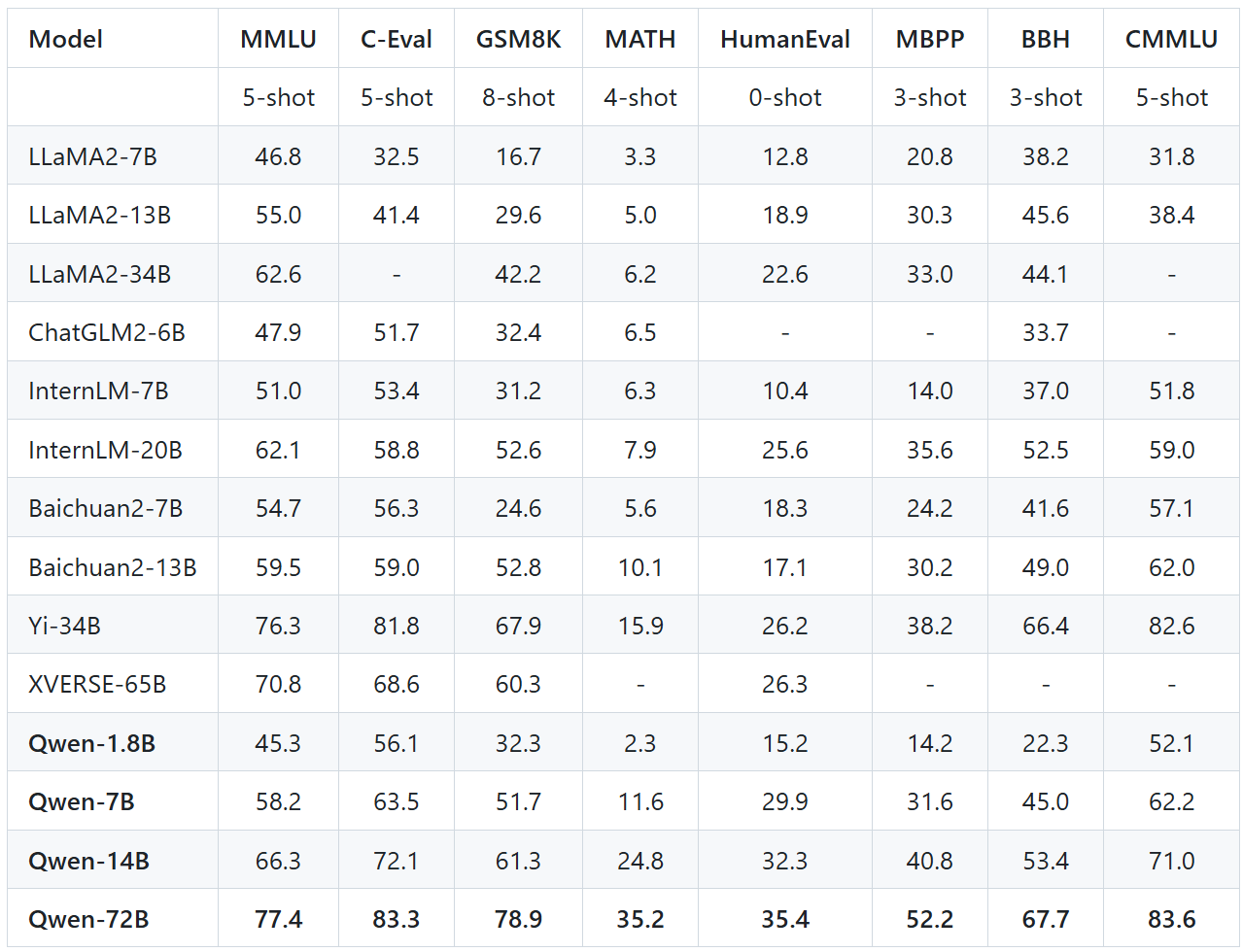
這張圖表展示了多個大語言模型(LLMs)在不同評估基準上的性能表現,各列的參數含義如下:
-
Model
模型名稱,如 MPT、Falcon、ChatGLM2、LLaMA、Qwen 等。
-
Params
模型參數量(參數規模),單位是 B(Billion,十億)。例如 7B 表示模型有 70 億參數。
-
MMLU (5-shot)
Massive Multitask Language Understanding,是一個跨學科考試題集,衡量模型的廣泛知識掌握能力。
5-shot 表示使用 5 個示例提示(few-shot learning)進行評測。
-
C-Eval (5-shot)
C-Eval 是面向中文的多任務評測集,涵蓋中國大學考試內容等。
5-shot 同樣表示使用 5 個示例提示。
-
GSM8K (8-shot)
Grade School Math 8K,是一個數學問題解決數據集,適用于小學級別數學推理能力評測。
8-shot 表示給出 8 個示例再讓模型解題。
-
MATH (4-shot)
比 GSM8K 更難,是中學至大學級別的數學題數據集,評估模型在復雜數學問題上的能力。
4-shot 表示提供 4 個示例。
-
HumanEval (0-shot)
由 OpenAI 提供的評估模型編程能力的數據集,包含 Python 編程任務。
0-shot 表示不提供任何提示,直接讓模型生成代碼。
-
MBPP (3-shot)
Mostly Basic Python Problems,也是編程任務集合,但比 HumanEval 更基礎。
3-shot 表示提供 3 個編程示例。
-
BBH (3-shot)
Big-Bench Hard,是 BIG-bench 數據集中最難的子集,涵蓋推理、數學、邏輯等多種任務。
3-shot 表示提供 3 個例題。
2、線上體驗
你說自己牛逼就牛逼?那不行,我要體驗一下
https://huggingface.co/spaces/Qwen/Qwen2.5-Coder-7B-Instruct
通義大模型_AI大模型_一站式大模型推理和部署服務-阿里云
3、本地部署
各種配置方式
3.1 modelscope
搜索對應的模型即可~
官方指導: 通義千問3-0.6B
3.2 huggingface
搜索對應的模型即可~
官方指導:https://huggingface.co/Qwen/Qwen3-0.6B
3.3 Ollama
Ollama是一個開源工具,用于在本地計算機上快速運行、管理和部署大型語言模型(LLMs)。它支持多種開源模型(如 Llama 3、Mistral、Gemma、Qwen 等),并提供簡單命令行操作,適合開發者和研究者本地測試 LLM。
官網:Ollama
支持的模型:Ollama Search
3.3.1 安裝
下載安裝即可,Ollama安裝硬件要求:
-
Windows:3060以上顯卡+8G以上顯存+16G內存,硬盤空間至少20G
-
Mac:M1或M2芯片16G內存,20G以上硬盤空間
3.3.2 基本命令
| 命令 | 說明 |
|---|---|
ollama pull <模型名> | 下載模型(如 llama3) |
ollama run <模型名> | 運行模型交互式對話 |
ollama list | 查看已安裝模型 |
ollama rm <模型名> | 刪除模型 |
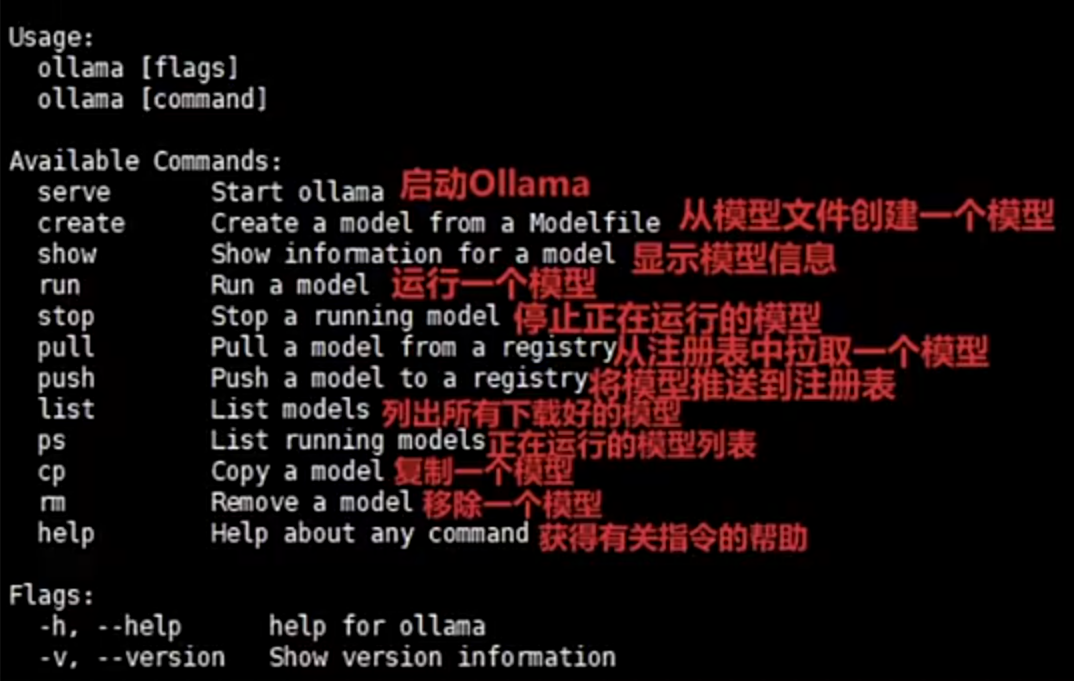
3.3.3 運行模型
ollama pull qwen:7b ? ? ? ? ? # 下載 Qwen-7B
ollama run qwen:7b ? ? ? ? ? ?# 啟動聊天
3.3.4 適用場景
-
開發測試 – 快速驗證模型效果
-
離線應用 – 無網絡環境下使用 LLM
-
輕量級部署 – 替代云 API 的高成本方案
3.3.5 請求示例
POST http://localhost:11434/api/chat
Content-Type: application/json{
? "model": "qwen3:0.6b",
? "messages": [
? ? { "role": "user", "content": "LLM是什么?" }
? ],
? "stream": true
}
響應:
json復制編輯{
? "message": {
? ? "role": "assistant",
? ? "content": "你好!我不知道實時天氣信息,但你可以查看天氣預報網站獲取最新天氣。"
? },
? "done": true
}
3.4 vLLM
參考Docker
四、DeepSeek-1.5B本地部署
大模型本地部署是指將大型預訓練模型(如GPT、Llama、BERT等)完全部署在用戶自有的硬件設備(如服務器、本地計算機)上,而非依賴云端API服務。
1、特點
-
私有化:模型和數據完全存儲在本地,無需通過互聯網傳輸。
-
自主控制:用戶擁有模型的完整權限,可自由修改、訓練或調整推理邏輯。
-
離線運行:無需網絡連接即可使用模型能力(如生成文本、分析數據)。
2、功能
-
數據安全:敏感數據(如醫療記錄、企業機密)無需上傳第三方服務器,避免泄露風險。
-
模型微調:基于本地數據調整模型參數,適配垂直領域任務(如法律合同分析)。
-
硬件適配:針對本地GPU/CPU資源優化模型推理速度(如量化、剪枝)。
-
無需聯網:在斷網環境(如實驗室、保密機構)中仍可使用模型能力。
3、模型下載
-
從huggingface找到你要下載的模型
-
安裝huggingface的下載工具(python庫):
pip install huggingface_hub
-
下載模型文件
set HF_ENDPOINT=https://hf-mirror.com ?# 加速下載設置 huggingface-cli download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local-dir ./deepseek ?# 下載模型文件 huggingface-cli download thenlper/gte-large --local-dir ./gte-large huggingface-cli download BAAI/bge-base-zh --local-dir ./bge-base-zh ?
4、非流式推理
利用transformer框架進行部署推理: Transformer庫的使用手冊:Transformers文檔
4.1 參考代碼
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch# 一:加載模型
model_path = r"./modeldir" # 模型路徑
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 # 指定模型參數類型為float16
model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch_dtype).to(device
) # 加載模型并移動到GPU
tokenizer = AutoTokenizer.from_pretrained(model_path) # 加載分詞器# 二:設置生成參數和輸入消息
gen_kwargs = {"max_length": 1024, # 生成的最大長度"do_sample": True, # 是否使用概率采樣"top_k": 10, # 采樣時的前K個候選詞,越大越隨機"temperature": 0.7, # 生成豐富性,越大越有創造力"top_p": 0.8, # 采樣時的前P個候選詞,越大越隨機"repetition_penalty": 1.2, # 重復懲罰系數,越大越不容易重復
}
# 定義消息內容
messages = [{"role": "system", "content": "你是AI助手"},{"role": "user", "content": "明月幾時有"},
]# 三:將輸入數據轉換為模型可接受的格式
inputs = tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt",return_dict=True,
).to(device
) # 將輸入數據移動到GPU# 四:生成輸出
outputs = model.generate(**inputs, **gen_kwargs) # 生成輸出
outputs = outputs[:, inputs["input_ids"].shape[1] :] # 截取生成的輸出
result = tokenizer.decode(outputs[0], skip_special_tokens=True) # 解碼輸出# 五:打印結果
print(result) # 打印結果4.2 參數詳解
-
device
-
概念:指定模型運行的計算設備(CPU 或 GPU)。在 PyTorch 中通常為 "cpu" 或 "cuda:0"。
-
設置建議:優先使用 GPU(如 device="cuda:0"),顯存不足時用 CPU。
-
-
torch_dtype
-
概念:模型張量的數據類型,如 float32(高精度)、float16 或 bfloat16(低精度,節省顯存)。
-
影響:精度越高(如 float32),結果越精確,但顯存占用更大。精度越低(如 float16),顯存占用少,但可能損失精度或數值不穩定。
-
設置建議:GPU 推薦 torch.float16 或 bfloat16(兼容性需確認);CPU 通常用 float32。
-
-
max_length
-
概念:生成文本的最大長度(token 數量)。
-
影響:值越大,生成內容越長,但速度越慢,且可能重復或偏離主題。值過小可能導致回答不完整。
-
設置建議:根據任務調整:對話建議 100-300,長文本生成可設 512-1024,注意模型最大限制(如 4096)。
-
-
do_sample
-
概念:是否啟用采樣策略(如 top_k, top_p)。若為 False,則使用貪心解碼(確定性強)。
-
影響:True:輸出多樣化,適合創意任務。False:輸出確定性強,適合事實性問題。
-
設置建議:需要多樣性時設為 True,需準確性時設為 False。
-
-
top_k
-
概念:采樣時保留概率最高的前 k 個 token。
-
影響:值越大(如 100),候選 token 多,輸出多樣但可能不相關。值越小(如 10),輸出更確定但可能重復。
-
設置建議:通常設為 10-50。
Token 概率 "貓" 0.30 "狗" 0.25 "鳥" 0.15 "跑" 0.10 "跳" 0.08 "飛" 0.07 "叫" 0.05 top_k=3采樣:-
只保留概率最高的 3個 token:["貓", "狗", "鳥"]
-
在這三個中按概率隨機采樣一個。
-
-
-
temperature
Token Logits Softmax(T=1) Softmax(T=0.5) Softmax(T=2) "貓" 4.0 0.60 0.80 0.40 "狗" 3.0 0.25 0.18 0.30 "鳥" 2.0 0.15 0.02 0.30 -
概念:控制采樣隨機性,調整概率分布平滑度。
-
影響:值大(如 1.5):輸出隨機性高,可能不連貫。值小(如 0.1):輸出更確定,但易重復。
-
設置建議:平衡點常為 0.7-1.0;需創造性時調高(如 0.9),需保守時調低(如 0.3)。
-
-
top_p(核采樣)
-
概念:從累積概率超過閾值 p 的最小 token 集合中采樣。
-
影響:值大(如 0.95):候選 token 多,輸出多樣。值小(如 0.5):候選 token 少,輸出更集中。
-
設置建議:常用 0.7-0.95。
Token 概率 累積和 "貓" 0.25 0.25 "狗" 0.20 0.45 "鳥" 0.15 0.60 "跑" 0.12 0.72 "跳" 0.10 0.82 "飛" 0.09 0.91 : 達到 top_p 閾值 "叫" 0.05 0.96
-
-
repetition_penalty
if token in generated_tokens:logits[token] /= repetition_penalty
-
概念:懲罰重復 token 的權重(>1.0 時抑制重復,<1.0 時鼓勵重復)。
-
影響:值大(如 2.0):減少重復,但可能生成不自然內容。值小(如 1.0):無懲罰,默認行為。
-
設置建議:通常設為 1.0-1.2,明顯重復時可設 1.2-1.5。
應用場景 推薦設置 正常文本生成(如聊天) 1.1~1.3(防止重復) 模仿風格性強文本(如古詩) 1.0(或略小) 模型不斷重復一句話? 適當增大 penalty(如 1.5)
-
4.3 代碼封裝
from transformers import AutoTokenizer, AutoModelForCausalLM
import torchclass DeepSeek:def __init__(self, model_path, device, torch_dtype):self.device = device # 設定推理設備self.model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch_dtype).to(device) # 加載模型并移動到GPUself.tokenizer = AutoTokenizer.from_pretrained(model_path) # 加載分詞器def inference(self, messages, gen_kwargs):inputs = self.tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt",return_dict=True,).to(self.device) # 將輸入數據移動到GPUoutputs = self.model.generate(**inputs, **gen_kwargs) # 生成輸出outputs = outputs[:, inputs["input_ids"].shape[1] :] # 截取生成的輸出result = self.tokenizer.decode(outputs[0], skip_special_tokens=True) # 解碼輸出return resultif __name__ == "__main__":# 一:設定模型路徑和設備,加載模型model_path = r"./modeldir" # 替換為你的模型路徑device = "cuda:0" if torch.cuda.is_available() else "cpu"torch_dtype = torch.float16deepseek = DeepSeek(model_path, device, torch_dtype)# 二:設定推理參數,推理消息gen_kwargs = {"max_length": 1024, # 生成的最大長度"do_sample": True, # 是否使用概率采樣"top_k": 10, # 采樣時的前K個候選詞,越大越隨機"temperature": 0.7, # 生成豐富性,越大越有創造力"top_p": 0.8, # 采樣時的前P個候選詞,越大越隨機"repetition_penalty": 1.2,} # 重復懲罰系數,越大越不容易重復messages = [{"role": "system", "content": "你是一名樂于助人的人工智能助手"},{"role": "user", "content": "寫一個js判斷用戶驗證碼代碼"},] # 定義消息內容result = deepseek.inference(messages, gen_kwargs) # 調用推理方法print(result) # 打印結果5、流式推理
from transformers import AutoTokenizer, AutoModelForCausalLM, TextIteratorStreamer
import torch
from threading import Threadclass DeepSeek:def __init__(self, model_path, device, torch_dtype):self.device = device # 設定推理設備self.model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch_dtype).to(device) # 加載模型并移動到GPUself.tokenizer = AutoTokenizer.from_pretrained(model_path) # 加載分詞器def inference(self, messages, gen_kwargs):inputs = self.tokenizer.apply_chat_template(messages,add_generation_prompt=True,tokenize=True,return_tensors="pt",return_dict=True,).to(self.device) # 將輸入數據移動到GPUstreamer = TextIteratorStreamer(self.tokenizer, skip_special_tokens=True) # 創建流式輸出對象generation_kwargs = dict(**inputs, **gen_kwargs, streamer=streamer) # 生成參數thread = Thread(target=self.model.generate, kwargs=generation_kwargs) # 創建線程thread.start() # 啟動線程進行生成generated_text = "" # 初始化生成文本for new_text in streamer: # 流式輸出生成的文本generated_text += new_text # 累加生成的文本yield new_text # 逐步返回生成的文本if __name__ == "__main__":# 一:設定模型路徑和設備,加載模型model_path = r"./modeldir" # 替換為你的模型路徑device = "cuda" # 指定推理設備為GPUtorch_dtype = torch.float16deepseek = DeepSeek(model_path, device, torch_dtype)# 二:設定推理參數,推理消息gen_kwargs = {"max_length": 1024, # 生成的最大長度"do_sample": True, # 是否使用概率采樣"top_k": 10, # 采樣時的前K個候選詞,越大越隨機"temperature": 0.7, # 生成豐富性,越大越有創造力"top_p": 0.8, # 采樣時的前P個候選詞,越大越隨機"repetition_penalty": 1.2,} # 重復懲罰系數,越大越不容易重復messages = [{"role": "system", "content": "你是一名樂于助人的人工智能助手"},{"role": "user", "content": "請簡要介紹一下你自己"},] # 定義消息內容response = deepseek.inference(messages, gen_kwargs) # 調用推理方法result = "" # 初始化結果for chunk in response: # 流式輸出生成的文本result += chunk # 累加生成的文本print(result) # 打印結果
)









)

到 mapMulti())


)


)