文章目錄
- 1 介紹
- 1.1 實際應用
- 1.2 邊界框
- 1.3 數據集
- 2 錨框
- 2.1 什么是錨框
- 2.2 交并比
- 2.3 分配標簽
- 2.4 非極大值抑制
- 3 經典目標檢測網絡
- 3.1 R-CNN
- 3.1.1 R-CNN (原始版本)
- 3.1.2 Fast R-CNN
- 3.1.3 Faster R-CNN
- 3.1.4 Mask R-CNN
- 3.2 單階段檢測器:SSD 和 YOLO
- 3.2.1 SSD (Single Shot Detection)
- 3.2.2 YOLO (You Only Look Once)
- 3.3 非錨框(Anchor-free)算法
1 介紹
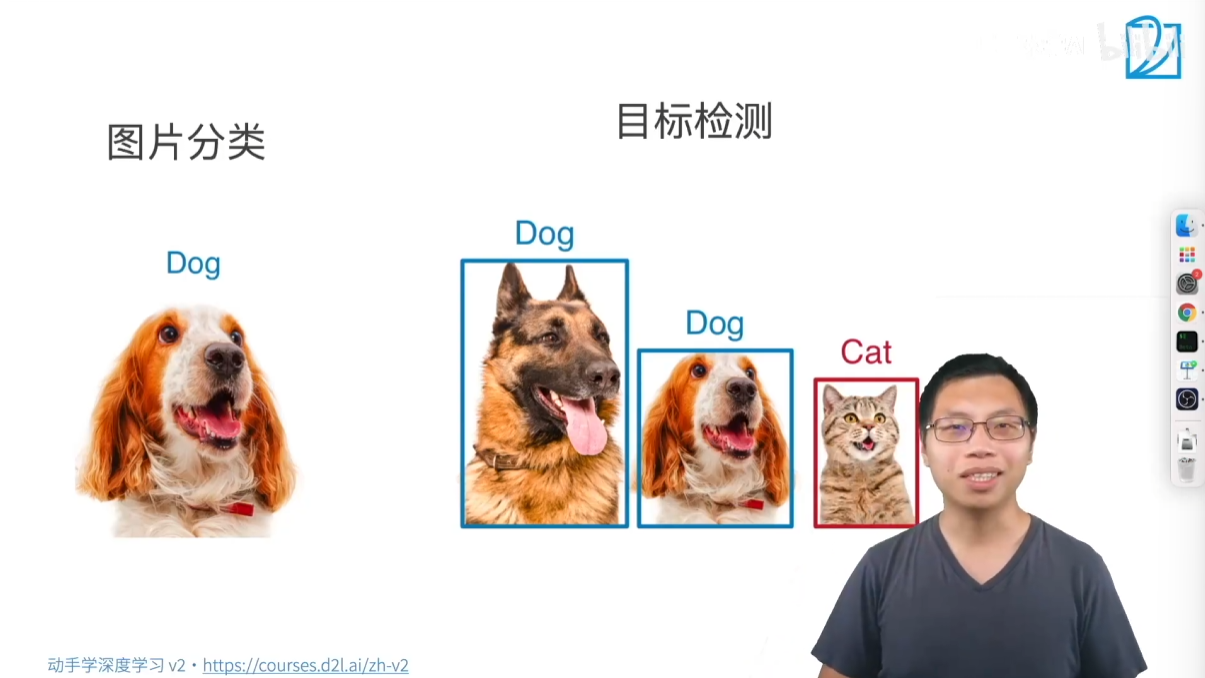
目標檢測,也稱為物體檢測,是計算機視覺領域一個非常重要的應用。它的核心任務是在一張圖片中識別出所有感興趣的物體,并確定它們的位置。
這個任務比簡單的圖片分類要復雜得多,因為它需要處理以下兩個問題:
- 識別多個物體:一張圖片可能包含多個不同的物體(比如多只貓、多只狗、甚至貓和狗同時出現)。目標檢測需要識別出所有這些物體。
- 定位物體位置:僅僅識別出物體還不夠,它還需要用一個邊界框(Bounding Box) 把每個物體圈出來,從而確定它們在圖片中的具體位置。
| 特征 | 圖片分類(Image Classification) | 目標檢測(Object Detection) |
|---|---|---|
| 任務 | 判斷一張圖片的主體內容屬于哪個類別。 | 識別圖片中所有感興趣的物體,并確定它們的類別和位置。 |
| 關注點 | 整體圖像,通常假設圖片中只有一個主體物體。 | 多個物體,即使它們屬于同一類別。 |
| 輸出 | 一個類別標簽(例如:“狗”)。 | 多個物體的類別標簽 和 它們對應的位置信息(邊界框)。 |
| 舉例 | 一張圖片中有只狗,分類任務是判斷這張圖片是“狗”。 | 一張圖片中有兩只狗和一只貓,目標檢測任務是識別出“狗1”、“狗2”、“貓1”,并用邊界框標出它們各自的位置。 |
1.1 實際應用
目標檢測在現實世界中有非常廣泛的應用,以下是幾個典型例子:
- 自動駕駛:這是目標檢測一個非常重要的應用。自動駕駛汽車需要實時識別周圍的車輛、行人、交通信號燈和路標等,以確保安全行駛。
- 智能零售/無人售貨:系統可以自動識別顧客從貨架上拿走了哪些商品,從而實現無人收銀。
- 安防監控:識別可疑人員、遺留物品或車輛,并進行跟蹤。
- 工業質檢:識別產品上的缺陷或瑕疵。
1.2 邊界框
**邊界框(Bounding Box)**是目標檢測中用來表示物體位置的核心概念。它是一個方框,通常用來粗略地圈出圖片中的一個物體。
一個邊界框可以用四個數字來定義,主要有兩種常用的表示方法:
-
左上角和右下角坐標:
(xtop_left,ytop_left,xbottom_right,ybottom_right)(x_{top\_left},y_{top\_left},x_{bottom\_right},y_{bottom\_right}) (xtop_left?,ytop_left?,xbottom_right?,ybottom_right?)- 優點:直觀,可以直接確定框的對角線。
-
左上角坐標、寬度和高度:
(xtop_left,ytop_left,w,h)(x_{top\_left},y_{top\_left},w,h) (xtop_left?,ytop_left?,w,h)- 優點:在某些計算中更方便,例如縮放或大小調整。

1.3 數據集
目標檢測任務的數據集與圖片分類有顯著不同,因為其標注成本更高。
- 工作量大:每張圖片可能包含多個物體,每個物體都需要單獨標注。如果一張圖片平均有 5 個物體,標注工作量至少是圖片分類的 5 倍。
- 需要畫框:標注者需要用鼠標拖動來畫出每個物體的邊界框,這比簡單地選擇一個類別標簽要耗時得多。
由于標注成本高昂,目標檢測的數據集通常比圖片分類的數據集小。
一張圖片可能對應多個物體和類別,數據不能像圖片分類那樣簡單地按類別存放在子文件夾中。通常,標注信息會存放在一個單獨的文件中,比如一個文本文件或 CSV 文件。
- 格式舉例:每一行代表圖片中的一個物體,包含以下信息:
- 文件名
- 物體類別
- 邊界框的四個坐標值
COCO (Common Objects in Context) 是目標檢測領域一個非常重要和廣泛使用的大型數據集,它的地位類似于圖片分類中的 ImageNet。
- 特點:
- 包含 80 個日常生活中常見的物體類別(如人、車輛、交通燈、飛機、日常用品等),類別數遠少于 ImageNet 的 1000 類。
- 包含約 33 萬張圖片,標注了超過 150 萬個物體。
- 用途:
- 由于其規模和多樣性,COCO 數據集被廣泛用于學術研究和模型性能評估。

2 錨框
由于直接預測邊界框(Bounding Box) 的四個坐標值難度較大,基于錨框的算法提供了一種更有效的方法。
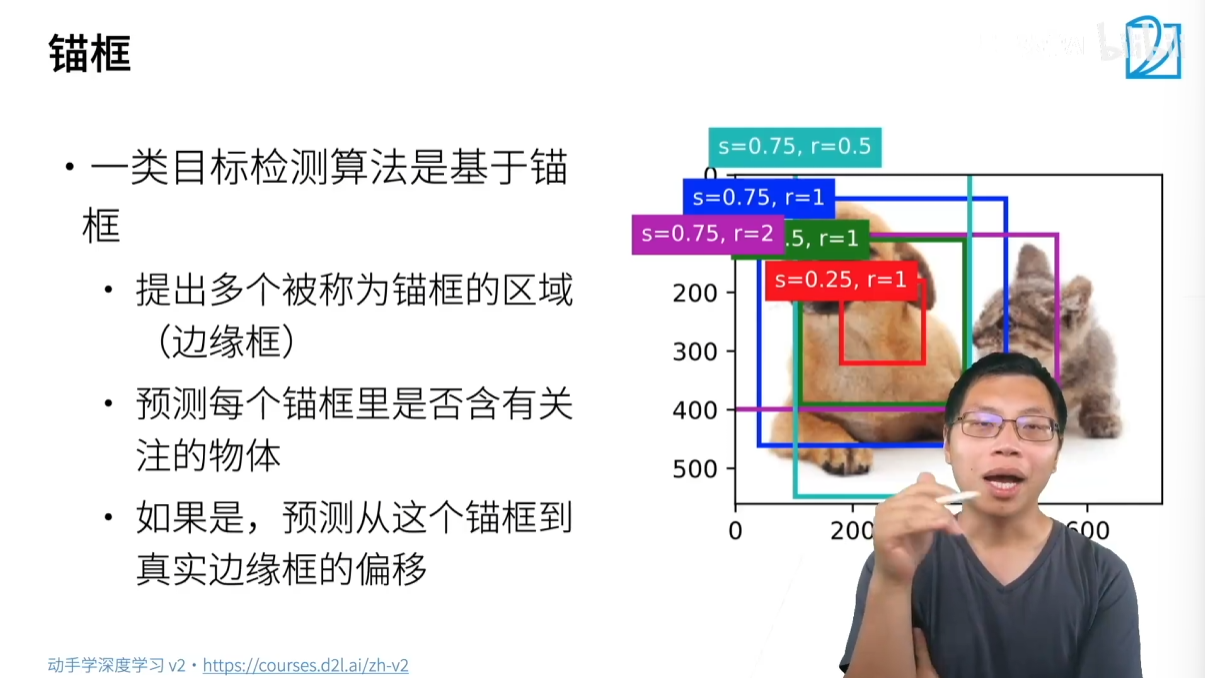
2.1 什么是錨框
錨框,也叫 Anchor Box,是目標檢測算法預先生成的一系列候選框。算法會先在圖片中生成大量的錨框,然后對每個錨框進行兩項預測:
- 分類:判斷這個錨框內是否包含感興趣的物體(例如:狗、貓),或者只包含背景。
- 回歸:如果錨框內有物體,則預測這個錨框需要進行多大的平移和縮放才能與真實的邊界框(Ground Truth Bounding Box) 完全重合。
通過這種方法,算法不再是直接從零開始預測邊界框的坐標,而是基于預設的錨框進行微調,這大大簡化了預測任務。
基于錨框的算法需要進行兩次預測:
- 第一次預測(分類):預測每個錨框是否包含某個物體,以及屬于哪一類。
- 第二次預測(回歸):預測每個錨框到真實邊界框的偏移量。
這與目標檢測需要預測類別和位置的任務相吻合。
2.2 交并比
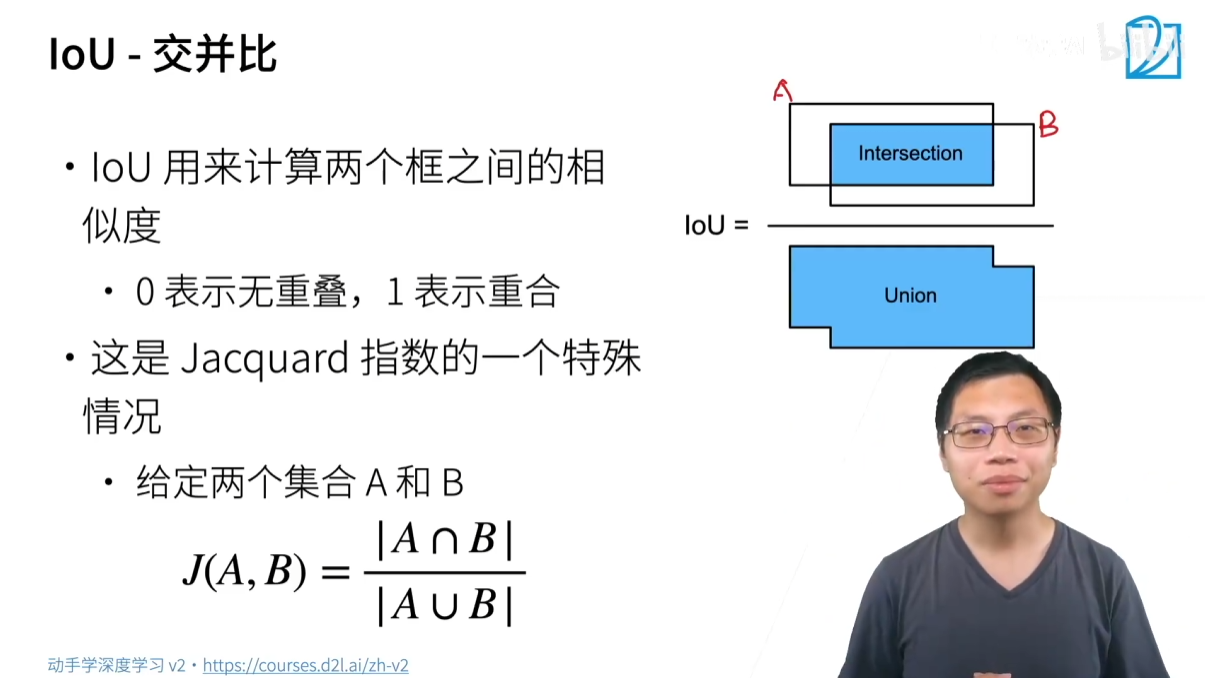
為了評估錨框與真實邊界框的相似度,我們使用一個稱為 IOU(Intersection over Union) 的指標。
IOU(交并比)是衡量兩個框重疊程度的指標,其值在 0 到 1 之間:
- IOU = 0:兩個框完全沒有重疊。
- IOU = 1:兩個框完全重合。
- IOU 的值越接近 1,表示兩個框的相似度越高。
IOU 的計算方法非常直觀:
IOU(A,B)=面積(A∪B)面積(A∩B)IOU(A,B)=面積(A∪B)面積(A∩B) IOU(A,B)=面積(A∪B)面積(A∩B)
其中:
- A 和 B 代表兩個框。
- A∩B 是兩個框的交集面積(重疊部分)。
- A∪B 是兩個框的并集面積(兩個框的總面積減去重疊面積)。
IOU 本質上是雅可比指數(Jaccard Index) 在邊界框上的應用。如果我們將每個框看作一個像素集合,IOU 就是兩個集合的交集大小除以它們的并集大小。
2.3 分配標簽
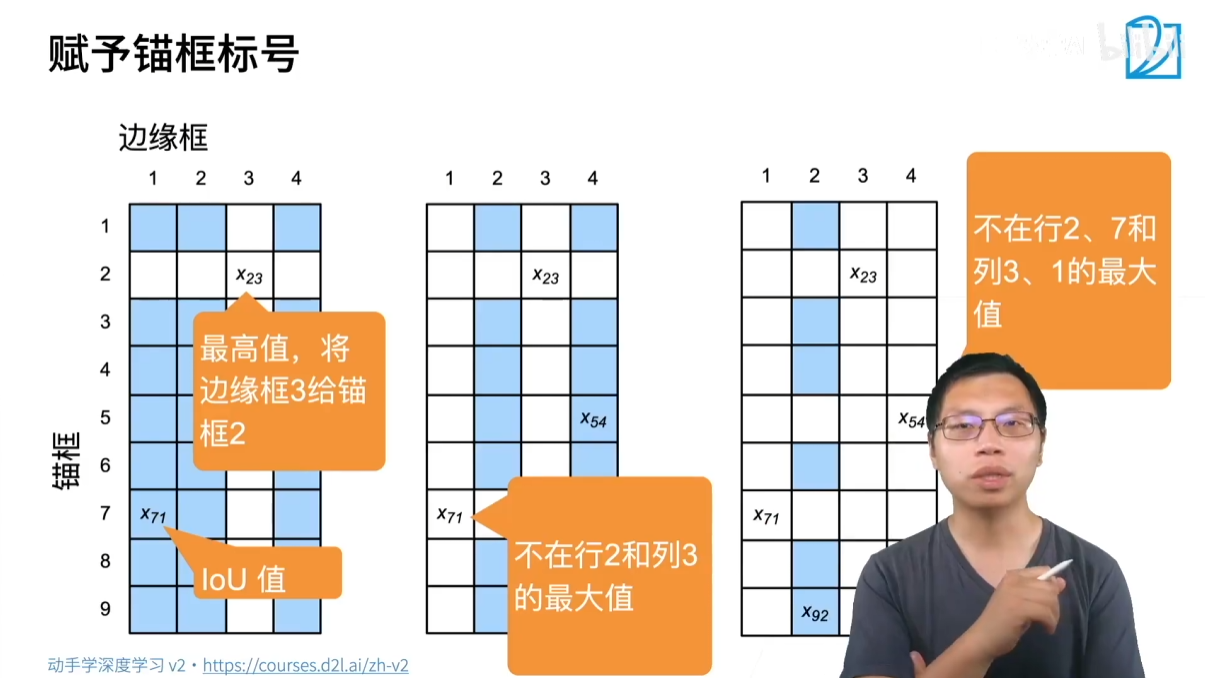
在訓練模型時,我們需要為每個錨框分配一個“標簽”,告訴模型這個錨框應該預測什么。
一個簡單的分配策略是:
- 為每個真實邊界框(Ground Truth Bounding Box),找到與之 IOU 值最大的那個錨框。將這個錨框標記為正樣本,并將其與該真實邊界框關聯起來。
- 在剩下的錨框中,找到那些與任意一個真實邊界框的 IOU 值大于某個閾值(比如 0.5)的錨框。這些錨框也標記為正樣本。
- 所有不屬于上述兩類的錨框都被標記為負樣本(即只包含背景)。

注意點:
- 一張圖片可能會生成成千上萬個錨框,但真實邊界框通常只有十幾個。因此,絕大多數錨框都是負類樣本。
- 為錨框分配標簽是一個動態過程,每次讀入一張圖片時都需要重新計算,因為錨框的位置是預設的,而真實邊界框的位置是根據圖片內容而變化的。
2.4 非極大值抑制
由于算法會為每個錨框生成一個預測結果,最終的輸出會包含大量重疊且相似的預測框。NMS(Non-Maximum Suppression)的作用是去除冗余的預測框,得到一個干凈、最終的預測結果。
NMS 的基本思想是保留那些置信度最高的預測框,并抑制(移除)那些與它高度重疊的低置信度預測框。
NMS 算法步驟:
- 篩選:從所有預測框中,篩選出那些置信度(即預測物體類別概率)大于某個閾值的非背景類預測框。
- 排序:將這些預測框按置信度從高到低排序。
- 迭代:
- 選取置信度最高的預測框作為最終預測。
- 移除(抑制)所有與該預測框 IOU 值大于某個閾值(例如 0.5)的其他預測框。
- 從剩余的預測框中,重復上述步驟,直到沒有更多的預測框。
這個過程將確保最終輸出的預測框是不重疊且置信度最高的。

3 經典目標檢測網絡
3.1 R-CNN
R-CNN (Region-based Convolutional Neural Network) 是目標檢測領域一個里程碑式的工作,它首次將深度學習引入目標檢測。
3.1.1 R-CNN (原始版本)
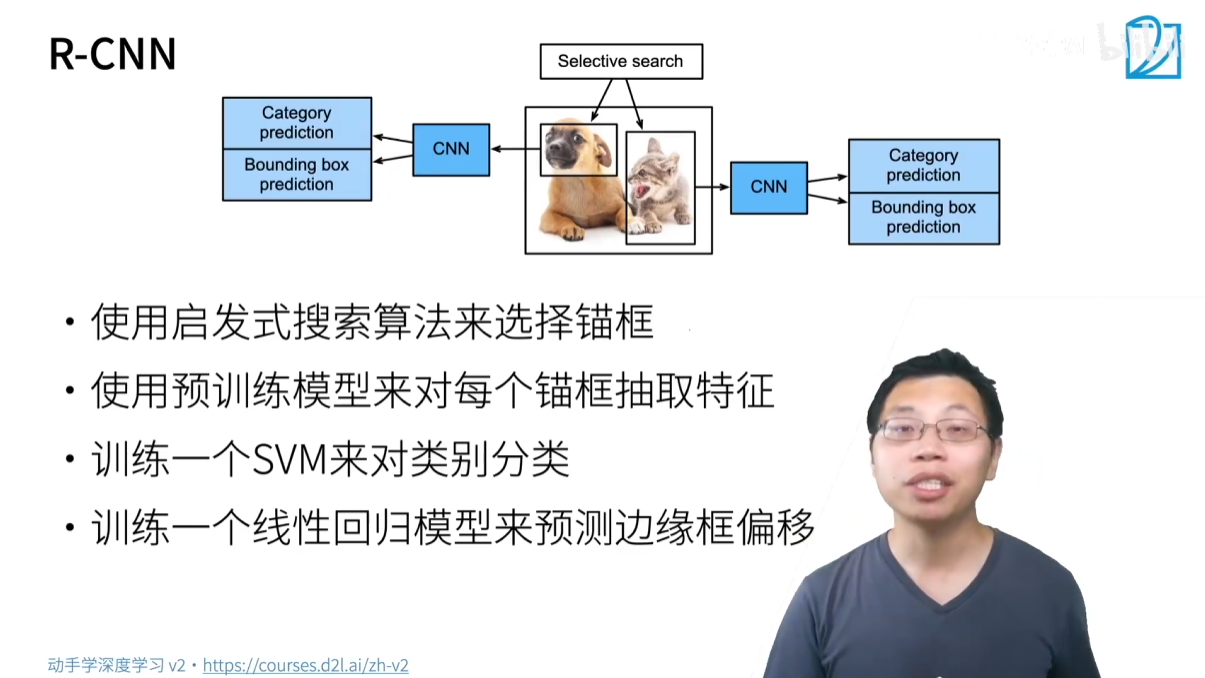
- 核心思想:這是一個“兩階段(two-stage)”算法,先生成候選區域,再對每個區域進行分類和回歸。
- 流程:
- 區域建議(Region Proposal):使用一種傳統的啟發式算法(如 Selective Search)在圖像中生成數千個錨框(候選區域)。
- 特征提取:將每個錨框中的內容裁剪并縮放成固定大小,然后輸入到一個預訓練的 CNN 模型(如 VGG, AlexNet)中提取特征。
- 分類和回歸:
- 使用 SVM 分類器對提取的特征進行分類(判斷是哪一類物體或背景)。
- 使用一個線性回歸模型預測邊界框的偏移量,對錨框進行微調。
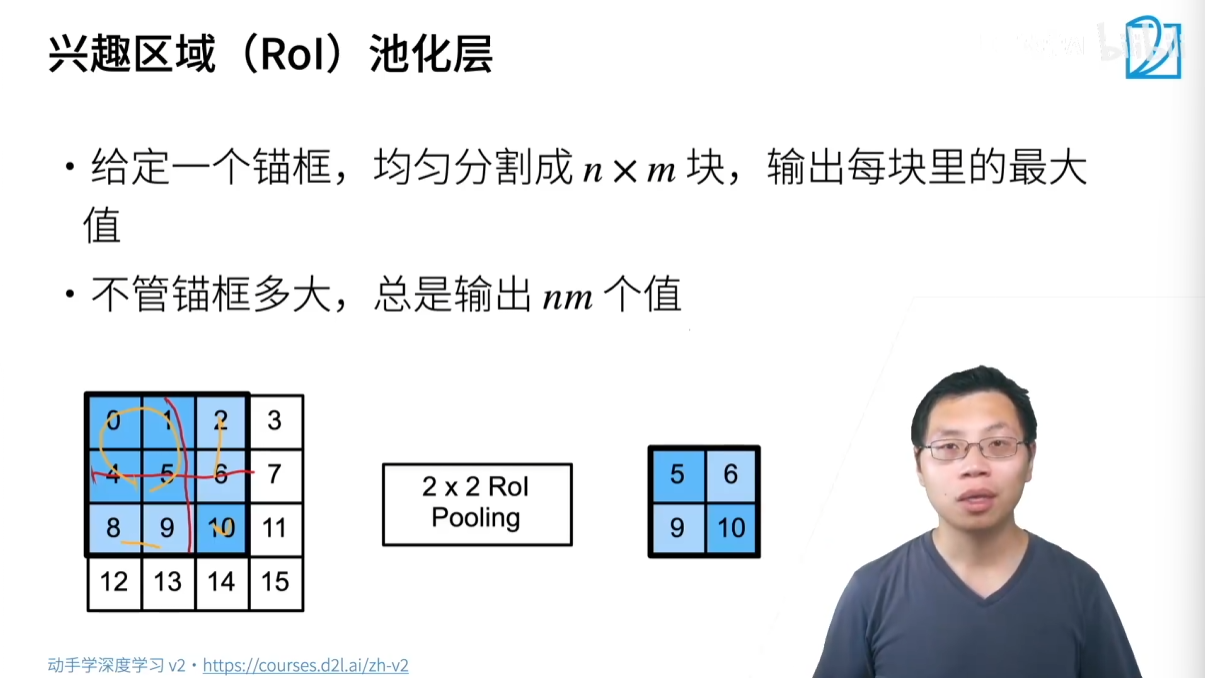
- 關鍵技術:ROI Pooling
- 為了處理不同大小的錨框,R-CNN 引入了 ROI (Region of Interest) Pooling。
- ROI Pooling 的作用是將任意大小的區域池化(pooling)成固定大小的輸出(例如 7x7),這使得所有錨框的特征可以被送入到后續的全連接層。
- 方法:將 ROI 區域均勻地劃分為 NxN 網格,然后在每個網格中執行最大池化,得到一個固定大小的特征圖。
- 缺點:計算成本高。因為要對每個候選框都單獨進行一次 CNN 特征提取,一張圖片可能需要重復處理上千次。
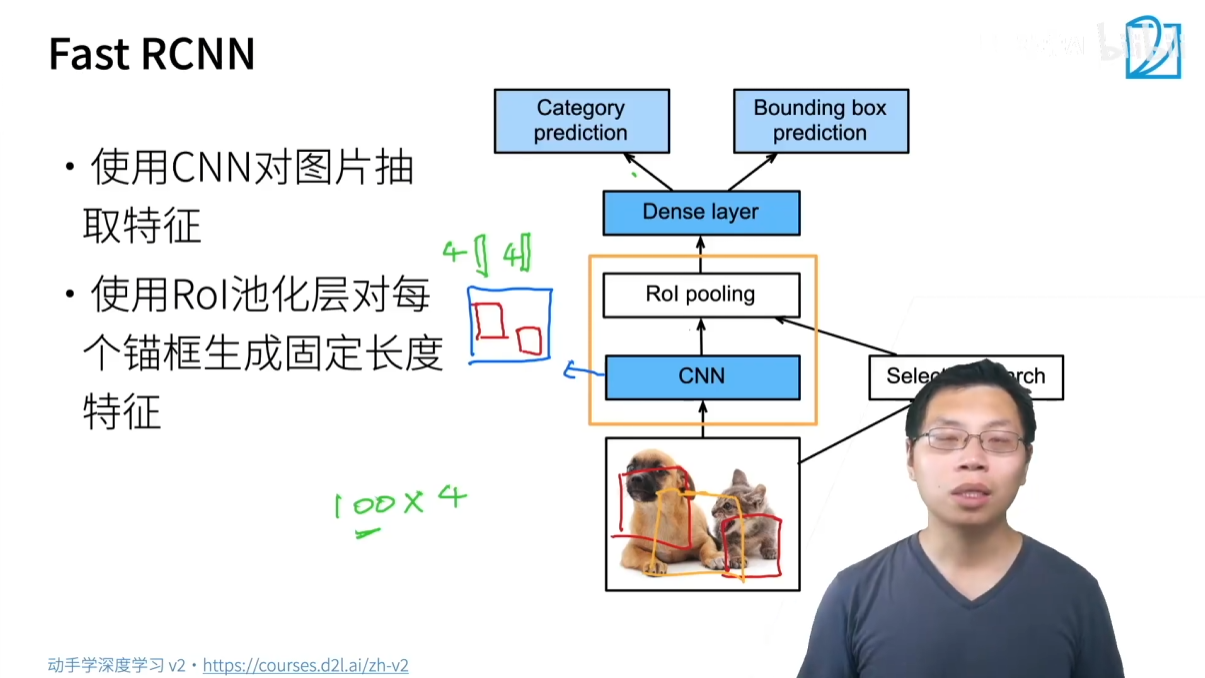
3.1.2 Fast R-CNN
- 核心思想:為了解決 R-CNN 的速度問題,Fast R-CNN 提出了只對整張圖片進行一次 CNN 特征提取。
- 改進流程:
- 對整張圖片進行 CNN 特征提取,得到一個完整的特征圖(Feature Map)。
- 仍然使用 Selective Search 生成錨框。
- 將這些錨框映射到第一步生成的特征圖上。
- 使用 ROI Pooling 從特征圖上提取每個錨框的特征向量。
- 將特征向量送入全連接層,進行分類(使用 Softmax)和邊界框回歸。
- 優點:大幅提升速度,因為 CNN 特征提取只進行了一次。
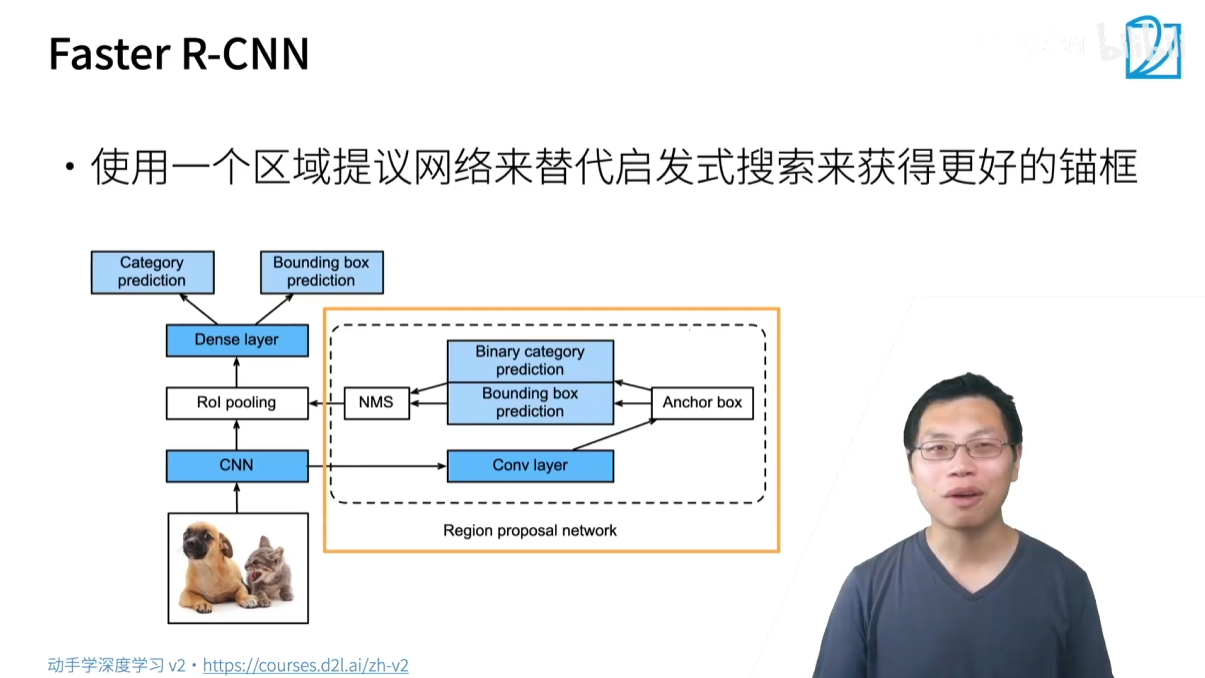
3.1.3 Faster R-CNN
- 核心思想:進一步加速,用神經網絡取代傳統的 Selective Search。
- 改進流程:
- 引入一個名為 RPN (Region Proposal Network) 的小型神經網絡來自動生成高質量的錨框。
- RPN 本身是一個簡化的目標檢測器,它接收 CNN 的特征圖作為輸入,并預測哪些區域可能包含物體,同時預測這些區域的邊界框偏移量。
- NMS 被用來去除 RPN 生成的冗余錨框。
- 這些由 RPN 生成的錨框作為 Fast R-CNN 的輸入,進行后續的分類和回歸。
- 優點:速度再次提升,且完全端到端(end-to-end),不再依賴外部算法。Faster R-CNN 在精度上表現優異,但速度仍然相對較慢。
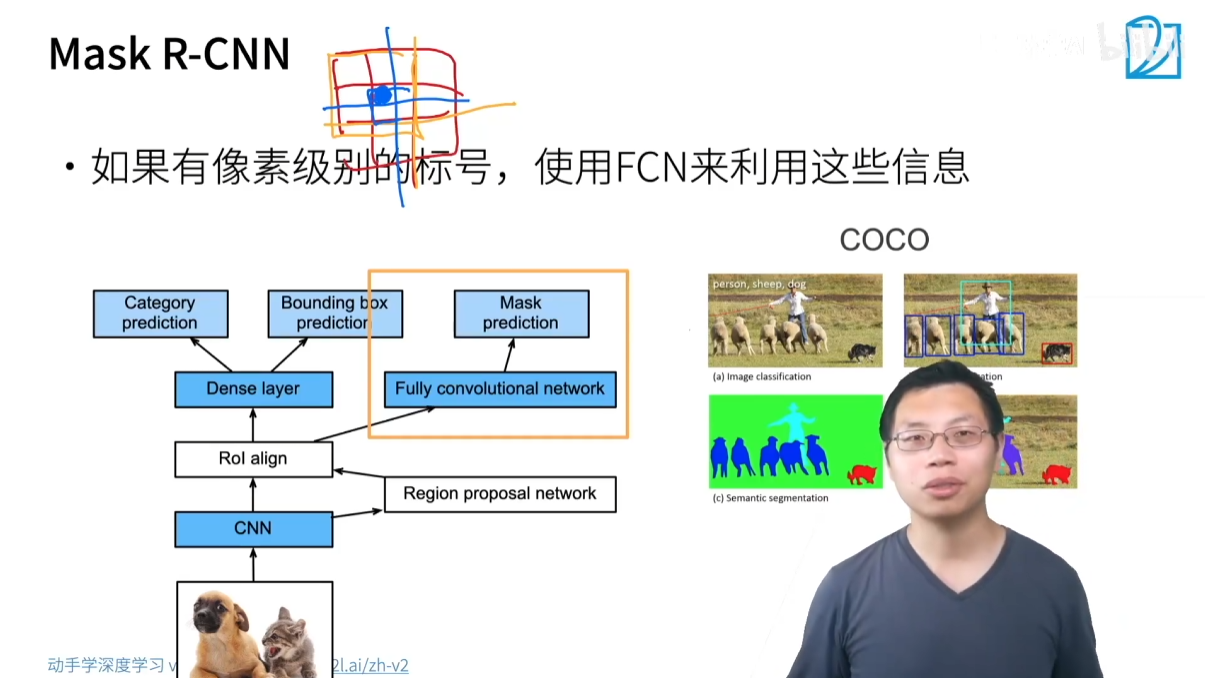
3.1.4 Mask R-CNN
- 核心思想:在 Faster R-CNN 的基礎上,增加了一個實例分割(Instance Segmentation)分支,可以預測每個物體的像素級掩碼(mask)。
- 關鍵技術:ROI Align
- 為了實現像素級別的預測,Mask R-CNN 提出了 ROI Align 來替代 ROI Pooling。
- ROI Pooling 在劃分區域和取整時會產生舍入誤差,導致特征圖和原圖的像素對齊不精確,這對邊界框回歸影響不大,但會嚴重影響像素級分割的精度。
- ROI Align 采用雙線性插值(bilinear interpolation)來精確地從特征圖中獲取像素值,避免了舍入誤差,從而提高了像素級預測的準確性。
- 應用:常用于需要高精度和像素級信息的場景,如自動駕駛。
3.2 單階段檢測器:SSD 和 YOLO
與 R-CNN 系列的“兩階段”不同,單階段(Single-stage) 檢測器直接從 CNN 的輸出中預測邊界框和類別,無需單獨的區域建議網絡。
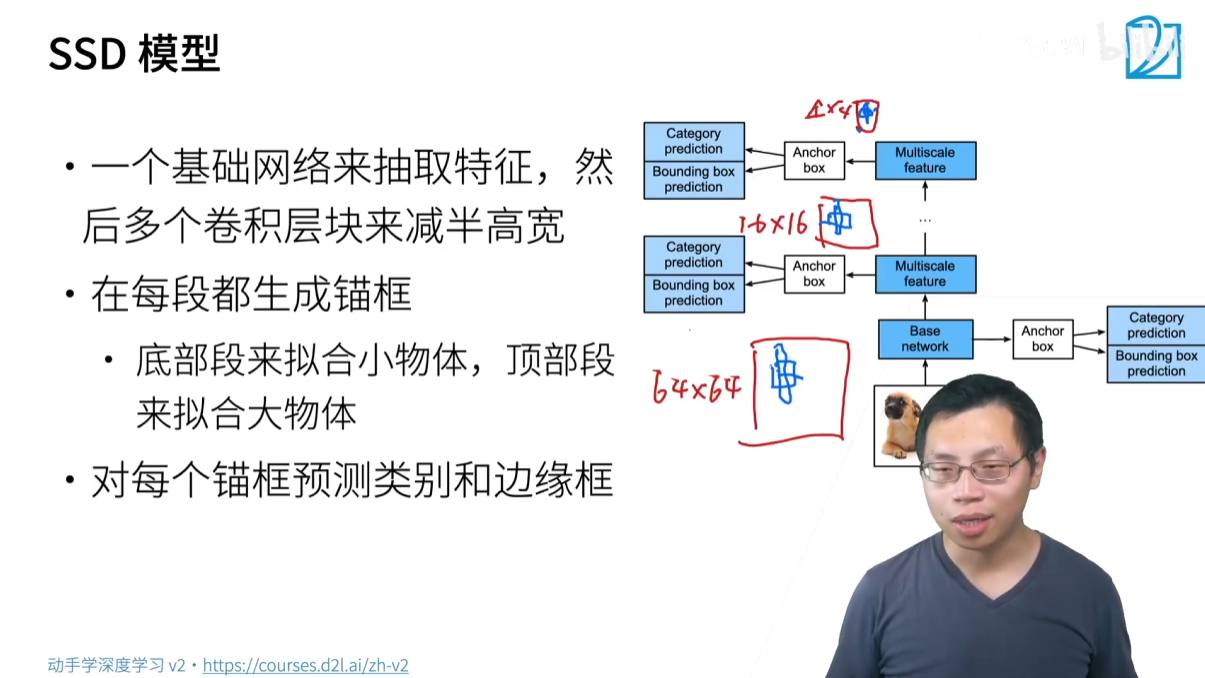
3.2.1 SSD (Single Shot Detection)
- 核心思想:通過一個神經網絡直接完成所有預測,并且利用多尺度特征圖來提升效果。
- 流程:
- 使用 CNN 提取特征,在不同層級的特征圖上進行預測。
- 在每個特征圖的每個像素上生成多個不同尺寸和長寬比的錨框。
- 對每個錨框同時預測其類別和邊界框偏移量。
- 優點:速度非常快,因為它只進行一次前向傳播。
- 缺點:精度相對較低,尤其對小物體檢測效果不佳。
3.2.2 YOLO (You Only Look Once)
- 核心思想:將目標檢測問題看作一個回歸問題,只看一遍圖片就完成所有預測。
- 與 SSD 的區別:
- 劃分網格:YOLO 將圖片均勻地劃分為 SxS 的網格,每個網格負責預測位于其中心點的物體。
- 錨框生成:每個網格只會生成固定數量的錨框(例如 B 個),而不是像 SSD 那樣對每個像素都生成錨框。這大大減少了錨框總數和計算量。
- 演進:YOLO 系列(YOLOv2, YOLOv3, YOLOv4, etc.)持續優化,在保持速度優勢的同時,不斷提升精度。
- 應用:YOLO 系列以其極快的速度和不斷提高的精度,在工業界應用廣泛,特別是在需要實時檢測的場景。

3.3 非錨框(Anchor-free)算法
- 核心思想:這類算法完全放棄使用錨框,直接預測物體的中心點或邊界框的坐標。
- 方法:通常將目標檢測任務轉換為像素級別的預測,例如,對每個像素預測它是否是某個物體的中心點,以及該物體邊界框的大小和偏移量。
- 優勢:由于不需要處理大量的錨框,這類算法的流程更簡單,計算更高效,并且有望在未來超越基于錨框的算法。
- 代表:CenterNet, FCOS 等。
| 算法家族 | 優點 | 缺點 | 典型應用 |
|---|---|---|---|
| R-CNN 系列 | 精度高,尤其是 Faster R-CNN 和 Mask R-CNN。 | 速度相對較慢,計算成本高。 | 競賽、需要極高精度的場景,如醫學影像。 |
| SSD / YOLO 系列 | 速度快,適合實時檢測。 | 早期版本精度不如 R-CNN 系列。 | 工業界、實時監控、無人機等。 |
| 非錨框算法 | 流程更簡單,有望超越傳統方法。 | 相對較新,還在發展中。 | 學術研究,未來發展方向。 |

計算機視覺(opencv)實戰八——四種邊緣檢測詳解:Sobel、Scharr、Laplacian、Canny)





)
計算機視覺(opencv)實戰六——圖像形態學(腐蝕、膨脹、開運算、閉運算、梯度、頂帽、黑帽))


方法)





在圖像卷積中的工作方式)

)