在近期的頂會頂刊中,遷移學習與多模態融合的熱度居高不下,相關成果頻出,部分模型在特定任務里性能提升極為顯著。
登上頂刊 TPAMI 2025 的某篇研究,借助語言引導的關系遷移,大幅提升了少樣本類增量學習中模型的泛化能力,此外,不少 CCF - A 類會議也有眾多佳作涌現。但需要留意,當下這一領域單純的模型結構調整已較難突破,若有醫療、遙感等特色數據,建議從 “跨模態知識遷移與任務定制優化” 方向著手。
本文精心整理了?3 篇前沿論文,旨在助力大家洞悉前沿動態、把握研究思路,如果有論文 er 感興趣,強烈建議研讀這些成果。滿滿干貨,關注收藏不迷路~
Bidirectional Cross-Modal Knowledge Exploration for Video Recognition with Pre-trained Vision-Language Models
方法:這篇文章旨在通過預訓練視覺 - 語言模型(VLMs)挖掘雙向跨模態知識來提升視頻識別性能,解決了現有方法僅單向利用 VLMs 知識、未充分發揮其跨域橋梁價值的局限。
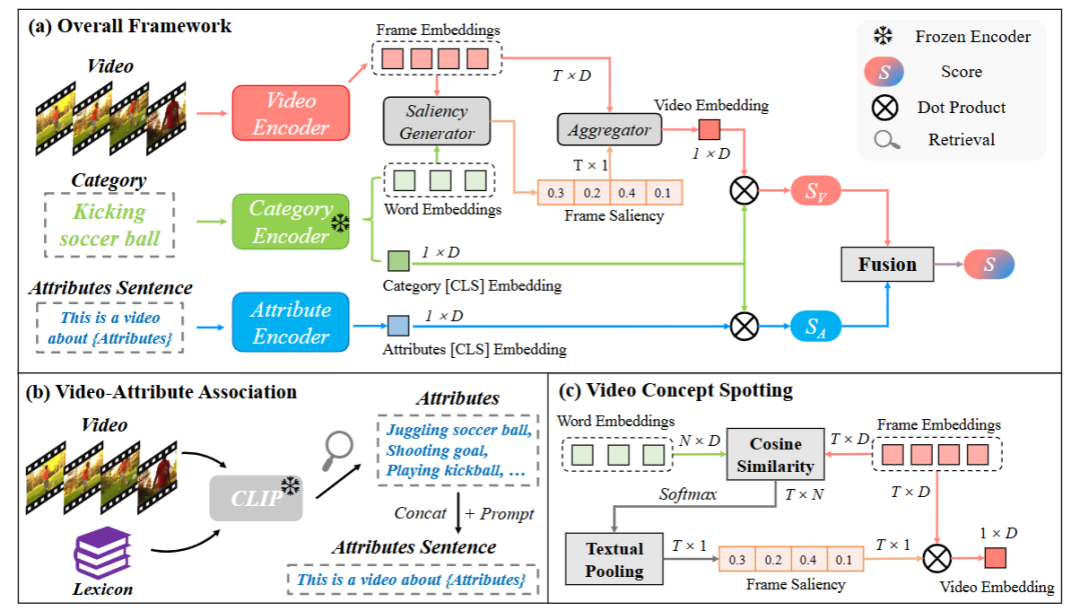
創新點:
提出 BIKE 框架,首次從預訓練視覺 - 語言模型中探索雙向跨模態知識以增強視頻識別。
在視頻到文本方向,設計視頻屬性關聯機制,生成輔助屬性用于補充視頻識別。
在文本到視頻方向,提出視頻概念定位機制,生成類別相關的時間顯著性以優化視頻表征。
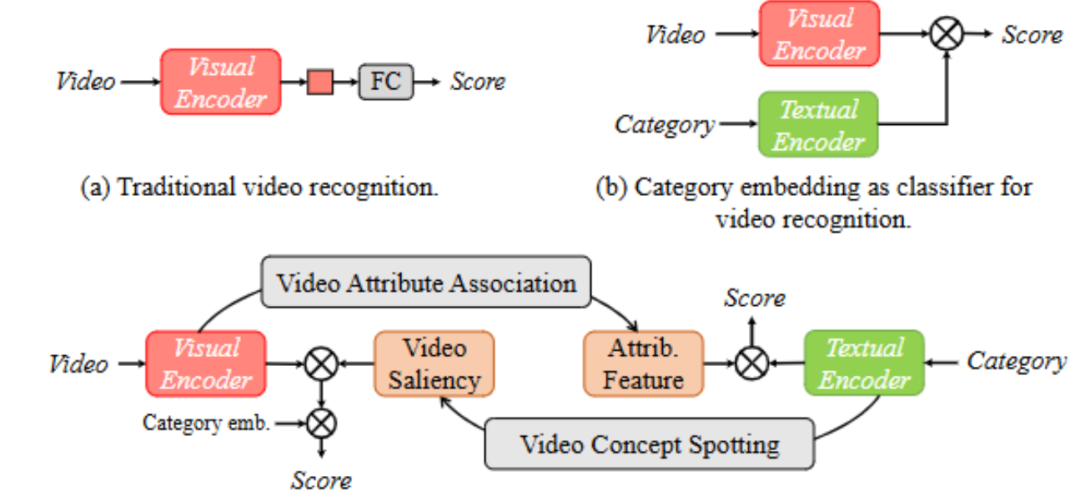
總結:該方法構建了包含屬性分支和視頻分支的 BIKE 框架,屬性分支通過視頻屬性關聯機制從預定義詞匯庫中檢索與視頻相關的短語作為屬性,形成屬性句子并編碼,與類別嵌入計算相似度以輔助識別;視頻分支利用視頻概念定位機制,通過幀與類別詞的相似度計算時間顯著性,以此聚合幀特征得到增強的視頻表征;最終融合兩個分支的相似度分數,實現更優的視頻識別效果。
HEALNet: Multimodal Fusion for Heterogeneous Biomedical Data
方法:這篇文章提出 HEALNet,一種靈活的多模態融合架構,旨在解決現有方法難以同時保留異質生物醫學數據的模態結構、捕獲跨模態交互、處理缺失模態及缺乏可解釋性的問題。
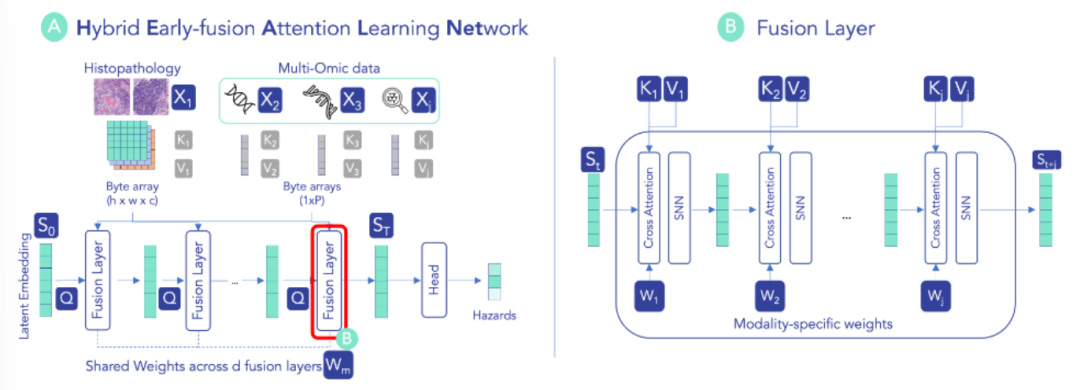
創新點:
設計混合早期融合架構,通過共享潛在空間和模態特定參數,在迭代注意力過程中同時保留模態結構信息與跨模態交互。
無需額外噪聲處理即可有效應對缺失模態,推理時可直接跳過缺失模態的更新步驟,保持性能穩定。
基于原始數據學習,通過模態特定注意力權重實現模型可解釋性,無需依賴額外解釋方法。
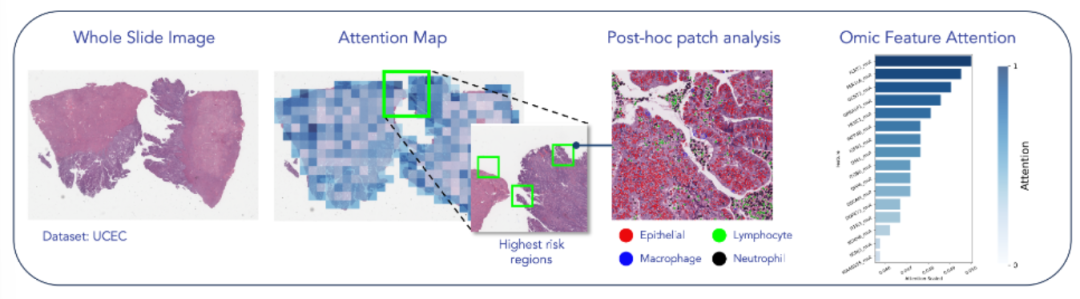
總結:HEALNet 初始化共享潛在嵌入,通過多個融合層迭代更新,每層利用模態特定的查詢、鍵、值權重,將各模態信息整合到共享空間以捕獲跨模態交互。對于表格、圖像等不同模態,采用對應的交叉注意力機制計算權重,并結合自歸一化網絡層,將模態結構信息編碼到共享嵌入中。最終利用共享潛在嵌入的全連接層生成預測,且在缺失模態時可跳過對應更新步驟,同時通過注意力權重支持模型 inspection。
糾結選題?導師放養?投稿被拒?對論文有任何問題的同學,歡迎來gongzhonghao【圖靈學術計算機論文輔導】,獲取頂會頂刊前沿資訊~
Text-to-Multimodal Retrieval with Bimodal Input Fusion in Shared Cross-Modal Transformer
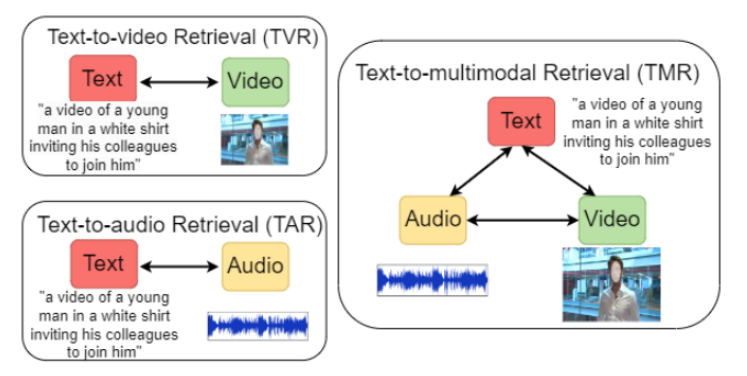
方法:這篇文章提出一種基于共享跨模態 Transformer 的雙向輸入融合架構,旨在解決現有文本到多模態檢索中模態融合擴展性差、跨模態交互捕捉不足的問題,以提升文本查詢對視頻(含音頻)的檢索效果。
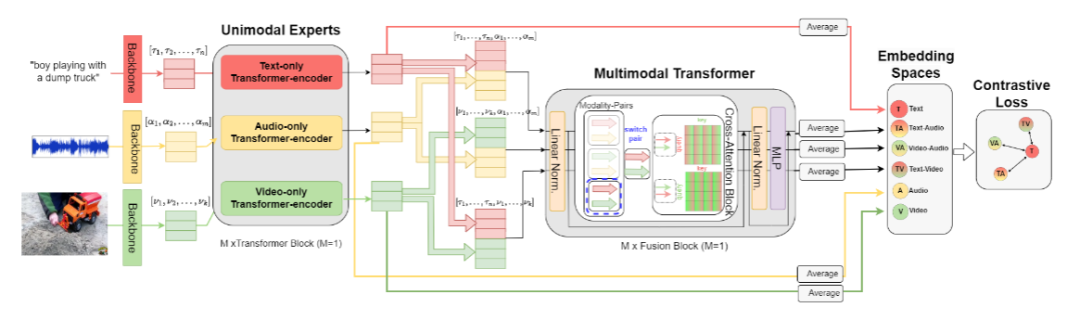
創新點:
設計分層架構,先通過單模態 Transformer 培養模態專屬專家,再用共享跨注意力融合 Transformer 構建模態無關的多模態空間,可靈活擴展至更多模態。
針對文本查詢的多模態檢索任務,提出通過微調損失變體(特定對比損失組合)提升性能,增強文本與跨模態表示的互信息。
證實音頻 - 視頻融合對文本檢索的增強作用,并分析文本查詢長度對檢索效果的影響,為優化基準提供依據。
總結:該方法首先利用 CLIP 骨干提取文本和視頻特征、可訓練 CNN 提取音頻特征,經線性投影和歸一化后,由單模態 Transformer 生成各模態的增強表示。接著,將文本 - 音頻、文本 - 視頻、視頻 - 音頻等模態對輸入共享跨注意力塊,通過雙向交叉注意力計算融合表示,并投影至共享空間進行元素級相加。最后,采用由文本與各跨模態表示組成的特定對比損失組合,引導模型學習 discriminative 表示,實現更精準的文本到多模態檢索。
來gongzhonghao【圖靈學術計算機論文輔導】,快速拿捏更多計算機SCI/CCF發文資訊~


 — Swift解法 + 可運行Demo)

![[GraphRAG]完全自動化處理任何文檔為向量知識圖譜:AbutionGraph如何讓知識自動“活”起來?](http://pic.xiahunao.cn/[GraphRAG]完全自動化處理任何文檔為向量知識圖譜:AbutionGraph如何讓知識自動“活”起來?)


:計數排序,排序算法復雜度對比和穩定性分析)

API)









