在當今信息爆炸的時代,企業和研究人員面對大量非結構化文檔時,如何高效地提取、存儲和查詢其中的知識,已成為一個核心挑戰。傳統的關鍵詞檢索早已無法滿足深層次語義關聯和智能問答的需求。
每天面對成百上千份PDF論文、Excel報告、行業白皮書,你是否也曾陷入這樣的困境:
- 想找某篇文獻中提到的“鈣鈦礦氧化物磁性研究”,卻要在數十個文件夾里逐個檢索?
- 明明記得A技術與B材料有關聯,卻翻遍文檔也找不到具體關聯證據?
- 團隊積累的核心知識散落在各種文檔中,新人上手要花數月才能理清脈絡?
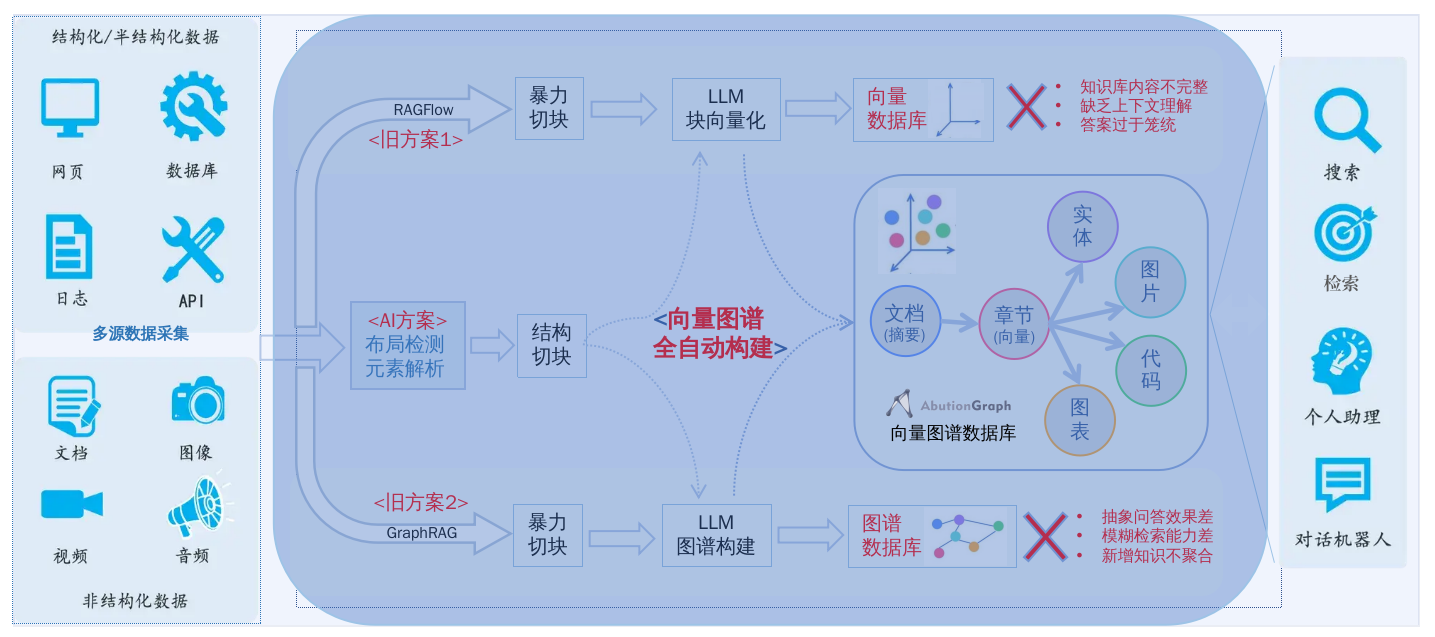
今天,我們要介紹的AbutionGraphRag自動化工具,正在重新定義知識處理的邏輯——它能將任何格式的文檔一鍵轉化為“會思考”的向量知識圖譜,讓分散的信息變成結構化的智慧,讓隱性的關聯自動浮出水面。
一、核心功能:從文檔到知識圖譜的端到端自動化
該工具集成了小模型文檔識別、多模態大模型與向量圖數據庫,實現了無人值守的文檔解析和知識提取流程:
1. 多格式文檔解析:把任何文件“拆”成結構化內容
支持PDF、Word等多種格式,利用OCR和深度學習模型自動提取文本、表格、圖片中的內容,并統一轉換為結構化的Markdown格式,為后續知識抽取奠定基礎。
關鍵能力:
- 保留文檔層級(章節→段落→實體),確保知識上下文不丟失;
- 支持非文本元素(如圖表、公式)的識別與關聯(例如將“圖1.2 稀土元素周期表”與相鄰分析文本綁定)。

2. 智能知識提取:讓機器像領域專家一樣“讀”懂內容
基于大語言模型可識別通用的實體關系,通過自定義抽取規則:附加提示詞(Prompt Engineering)和示例引導(Few-shot Learning),可從行業文檔中精準抽取實體、屬性以及實體間的語義關系,確保符合領域需求。
示例配置:
# 提示詞:控制提取規則(如“不改寫原文、保留實體屬性”)
ADDITIONAL_PROMPT = """使用原文進行提取,不要改寫或重復提取實體。為每個實體提供有意義的屬性以增加上下文。"""# 示例數據:引導模型按領域規范提取(如區分“人物”“情感”實體)
EXAMPLES = [{"input": "Romeo... Juliet is the sun.","output": {"entities": [{"vertex": "Romeo", "label": "PERSON", "properties": {"emotional_state": "wonder"}},{"vertex": "Juliet", "label": "PERSON", "properties": {"emotional_state": "joy"}}],"relation": [{"source": "Romeo", "target": "Juliet", "label": "LOVE"}]}}
]
效果展示:
在處理稀土領域的專業材料學論文時,
-
實體關系精準識別:能精準識別“La0.65Ca0.35MnO3”(鈣鈦礦錳氧化物)、“NH3-SCR”(選擇性催化還原技術)等專業術語,并提取“摻雜Ni2?影響磁性”等深層關系。
-
保持上下文關系:以原文的章節段落順序保持上下文連接,并為后續保存為圖譜關系。
-
復雜結構的關聯識別:如下結果所示,文本和公式被提取為不同的類型(Text、Formulas),但實體識別結果保留了上下文的內容連貫性,能根據上下文為公式進行摘要解釋,能從上下文為公式中的實體關系做出屬性解釋。
{"paragraphs": [{"type": "Text","original": "樣品在相對較 高的溫度范圍內表現出順磁性, 隨著溫度的降低, 樣品的磁性將從順磁性變為鐵磁性, 在居里溫度 T C ( x =0 ) =243 K , T C ( x =0.1 ) =238 K , T C ( x =0.3 ) =105 K 時, 樣品 磁性主要表現為鐵磁性。 通過 VESTA 軟件計算出 樣品 x =0 , 0.1 , 0.3 時所對應的 Mn-O-Mn 鍵角分別 是 169.9205° , 158.8492° , 108.5978° , 可知隨著 Ni 的摻雜, 使得 Mn-O-Mn 鍵角減小, 進而使樣品發 生更加強烈的晶格畸變, 減少了 Mn3+ 和 Mn4+ 之間雙 交換相互作用[ 14 ] , 導致居里溫度降低, 磁化強度減 小。 由于鐵磁性和反鐵磁性之間的競爭導致樣品的 ZFC 曲線和 FC 曲線在較低溫區出現了明顯的分叉 現象, 表現出可能存在的團簇自旋玻璃行為[ 15-16 ] 。\n\n0.05 T\n\nLa\n\nCa\n\nMn\n\nNi\n\nO\n\n在 磁場下, 多晶樣品 0.65 0.35 1x x 3 的 χT -T 曲線如圖 3 所示, 未摻雜樣品的值隨溫度 降低而增大, 大約在 216 K 附近達到最大, 而后迅 速減小, 可知奈爾溫度為 T N ( x =0 ) =216 K , 樣品低于 此溫度表現出反鐵磁性。 這與之前分析結果相符。 并且可知, Ni 摻雜后樣品的奈爾溫度分別為 T N ( x =0.1 ) = 215 K , T N ( x =0.3 ) =80 K , 與未摻雜樣品的奈爾溫度相 比較而降低。 根據反應機理, Ni2+ 部分取代 Mn3+ 離 子導致 Mn3+/Mn4+ 比值發生變化[ 17 ] 。 這樣就使 DE 相 互作用減弱, 進而使 T C 和磁矩減小。\n\n4\n\nLa\n\nCa\n\nMn\n\nNi\n\nO\n\n=0\n\n0.1\n\n0.3\n\n圖 為 0.65 0.35 1x x 3 ( x , , )在 0.05 T 下的 χ -1T 曲線, 以及對樣品 χ -1T 曲線進行 的 Curie -Weiss 擬合, 擬合公式為[ 18 ] :\n\nT\n\n= C /\n\nT -\n\n1","index": 1,"title": "鈣鈦礦氧化物La0.65Ca0.35MnO3摻雜Ni后的磁性變化","abstracts": "本段落介紹了La0.65Ca0.35MnO3鈣鈦礦氧化物在不同Ni摻雜量下的X射線衍射圖譜和磁化曲線。通過實驗數據,發現摻雜Ni后樣品的居里溫度和奈爾溫度降低,磁矩減小,表現出強烈的晶格畸變。","entities": [{"vertex": "La0.65Ca0.35MnO3", "label": "CHEMICAL_COMPOUND", "properties": {"structure": "Pbnm立方鈣鈦礦結構"}},{"vertex": "Ni", "label": "ELEMENT", "properties": {"doping_effect": "導致Mn-O-Mn鍵角減小,晶格畸變增強"}},{"vertex": "X射線衍射圖譜", "label": "EXPERIMENTAL_TECHNIQUE", "properties": {"purpose": "驗證樣品的單相性和晶體結構"}}],"relation": [{"source": "La0.65Ca0.35MnO3", "target": "X射線衍射圖譜", "label": "ANALYSIS_METHOD", "properties": {"result": "未觀察到明顯的雜質峰,樣品具有良好的單相性"}},{"source": "La0.65Ca0.35MnO3", "target": "Ni", "label": "DOPING", "properties": {"effect": "使居里溫度和奈爾溫度降低,磁矩減小"}},{"source": "Mn-O-Mn鍵角", "target": "晶格畸變", "label": "CAUSE_EFFECT", "properties": {"description": "隨著Ni摻雜量增加,Mn-O-Mn鍵角減小,晶格畸變增強"}}]},{"type": "Formulas","original": "\\nu ( T ) = \\mathcal { A } / ( T","index": 2,"title": "鈣鈦礦氧化物La0.65Ca0.35MnO3摻雜Ni后的磁性變化","abstracts": "本段介紹了鈣鈦礦氧化物La0.65Ca0.35MnO3在不同Ni摻雜濃度下的磁性行為。通過X射線衍射圖譜和磁化曲線分析,發現樣品具有良好的單相性,并且隨著Ni摻雜量的增加,居里溫度和奈爾溫度降低,Mn-O-Mn鍵角減小,導致晶格畸變加劇,雙交換相互作用減弱。","entities": [{"vertex": "La0.65Ca0.35MnO3", "label": "MATERIAL", "properties": {"composition": "La0.65Ca0.35MnO3", "structure": "Pbnm立方鈣鈦礦結構"}},{"vertex": "Ni", "label": "ELEMENT", "properties": {"role": "摻雜元素", "effect": "減少Mn3+和Mn4+之間的雙交換相互作用"}},{"vertex": "Tc", "label": "PHYSICAL_QUANTITY", "properties": {"definition": "居里溫度", "values": "243 K (x=0), 238 K (x=0.1), 105 K (x=0.3)"}}],"relation": [{"source": "La0.65Ca0.35MnO3", "target": "Ni", "label": "DOPING", "properties": {"description": "Ni摻雜到La0.65Ca0.35MnO3中"}},{"source": "Ni", "target": "Mn-O-Mn鍵角", "label": "AFFECTS", "properties": {"description": "Ni摻雜使得Mn-O-Mn鍵角減小"}},{"source": "Mn-O-Mn鍵角", "target": "Tc", "label": "INFLUENCES", "properties": {"description": "Mn-O-Mn鍵角減小導致居里溫度降低"}},{"source": "La0.65Ca0.35MnO3", "target": "Tc", "label": "HAS_PROPERTY", "properties": {"description": "La0.65Ca0.35MnO3在不同Ni摻雜濃度下表現出不同的居里溫度"}}]},{"type": "Text","original": "式中: C 為居里常數, θ 為居里外斯溫度, 由居里外 斯擬合得出, 3 個樣品的居里外斯溫度分別為 270 , 268 , 179 K , 且由圖可知, 3 個樣品分別在 230~270 K , 207~268 K , 97~179 K 溫區內表現出向上背離居","index": 3,"title": "居里外斯溫度與樣品磁性分析","abstracts": "通過居里外斯擬合得出三個樣品的居里外斯溫度分別為270 K、268 K和179 K。樣品在不同溫區表現出向上背離居里外斯行為。","entities": [{"vertex": "居里常數", "label": "PARAMETER", "properties": {"description": "用于描述物質磁性的參數"}},{"vertex": "居里外斯溫度", "label": "PARAMETER", "properties": {"description": "通過居里外斯擬合得出的溫度值,表示材料從順磁性轉變為鐵磁性的臨界溫度"}},{"vertex": "鈣鈦礦錳氧化物La0.65Ca0.35MnO3", "label": "MATERIAL", "properties": {"description": "一種具有特定化學組成的鈣鈦礦結構材料"}}],"relation": [{"source": "居里常數", "target": "居里外斯溫度", "label": "CALCULATION_PARAMETER", "properties": {"description": "居里常數是計算居里外斯溫度時使用的參數之一"}},{"source": "鈣鈦礦錳氧化物La0.65Ca0.35MnO3", "target": "居里外斯溫度", "label": "PROPERTY_OF", "properties": {"description": "鈣鈦礦錳氧化物La0.65Ca0.35MnO3的居里外斯溫度是其磁性性質的一部分"}},{"source": "居里外斯溫度", "target": "270 K, 268 K, 179 K", "label": "VALUE_OF", "properties": {"description": "居里外斯溫度的具體數值,分別對應于三個不同的樣品"}}]},... }
3. 向量圖譜構建:給知識“裝上導航系統”
抽取的知識會自動存入AbutionGraph圖數據庫。AbutionGraph不僅存儲拓撲關系,還支持多粒度向量嵌入(實體、段落、章節、全文級別),為后續的語義搜索和社區發現提供支持。
AbutionGraph提供了一套創新的全自動的非結構化數據治理方案,專注于構建高效、高質量、智能的本地知識庫。
本地知識庫構建: 從 數據接入 -> LLM企業數據問答 ,過程0人工,0知識構建成本,0開發,數據解析完立即可用。
4. 社區發現:自動“聚類”隱藏的知識主題
集成Leiden社區發現算法,自動識別知識圖譜中潛在的主題社區或概念集群,形成社區摘要和社區成員語義融合,揭示文檔集中隱藏的知識結構。
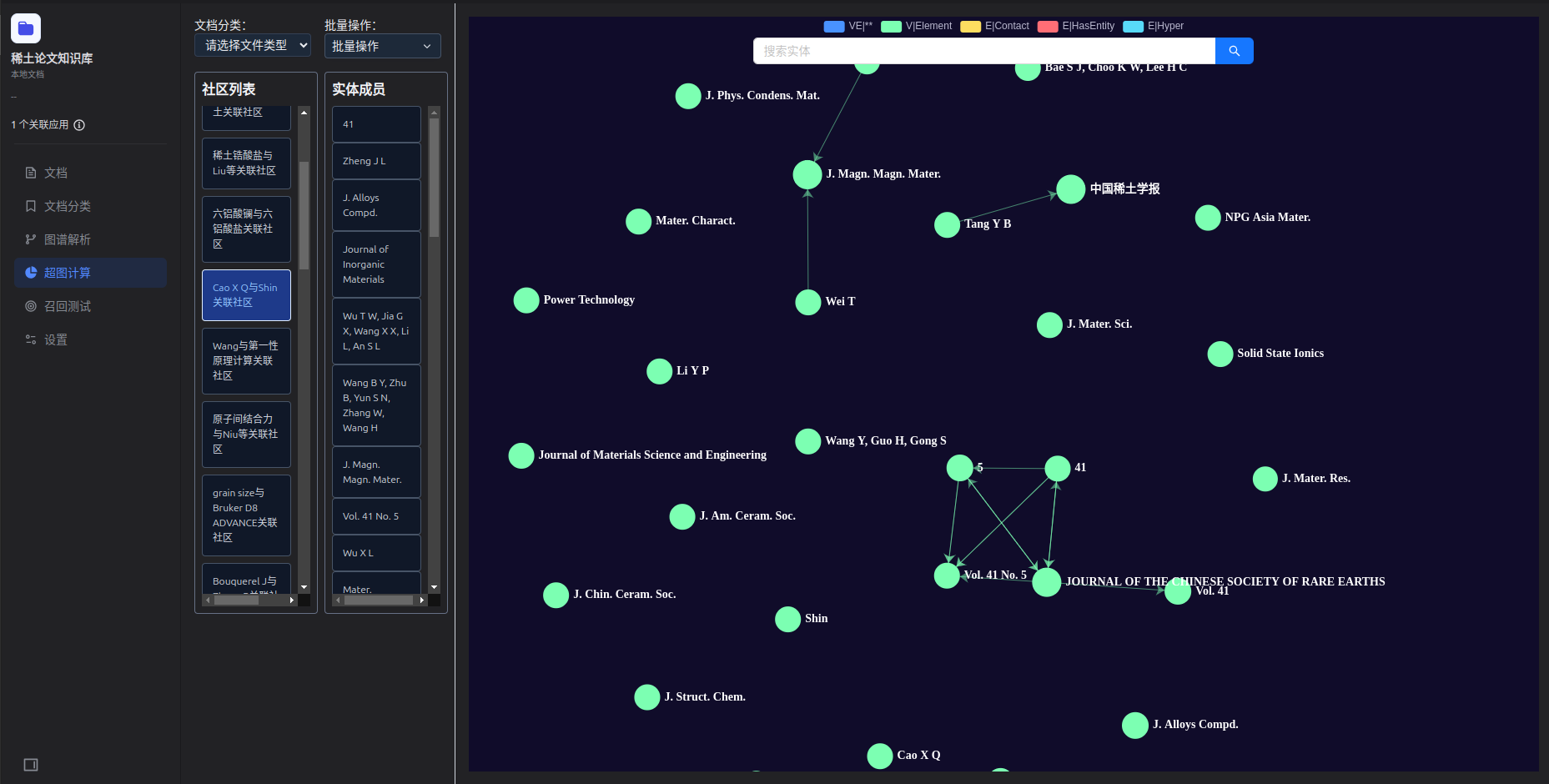
優勢:支持增量計算,適合持續增長的文檔庫,新增文檔時無需重新處理歷史數據,大幅降低更新成本。
5. 多維度智能檢索:想要的知識“一搜即得”
基于構建好的向量知識圖譜,工具提供3種核心檢索方式,滿足不同場景需求:
| 檢索方式 | 適用場景 | 示例效果 |
|---|---|---|
| 實體相似檢索 | 找相關概念/術語 | 搜索“鈣鈦礦”,返回“La0.65Ca0.35MnO3”“SrTiO3”等相關材料及相似度 |
| 關系網絡檢索 | 查實體間的關聯 | 搜索“稀土精礦與脫硝性能”,返回“稀土精礦→球磨酸浸→催化劑→提升脫硝性能”的完整關系鏈 |
| 流式智能問答 | 自然語言提問(RAG) | 提問“La0.65Ca0.35Mn1-xNixO3如何制備?”,返回結合多篇文獻的步驟總結 |
代碼示例:
# 檢索最相關6個知識點
query_text = "福建省龍巖市長汀縣河田鎮的地理與氣候特征是怎樣"
response = rag_driver.search(text=query_text, top_k=6)# 流式問答:實時返回答案(邊生成邊輸出)
response = rag_driver.search_call(text="鈣鈦礦氧化物La0.65Ca0.35Mn1-xNixO3的制備及表征",top_k=8, # 返回前8個相關知識片段stream=True
)
相似節點檢索結果示例:
{'刈割': 0.50636005, '福建師范大學地理科學學院': 0.47888565, '等補償': 0.45831108, 'ICP-MS': 0.36633873, '稀土元素': 0.3640747, '熱液噴發物質': 0.35804176}
多維度檢索結果示例:
{'question': '福建省龍巖市長汀縣河田鎮的地理與氣候特征是怎樣','answer_vertex_sim': {'刈割': 0.50636005,'福建師范大學地理科學學院': 0.47888565,'等補償': 0.45831108,'ICP-MS': 0.36633873,'稀土元素': 0.3640747,'熱液噴發物質': 0.35804176},'vertex_entity': ['ICP-MS: {hll:4; desc:[\'{"用途":"測定稀土元素含量"}\']}','刈割: {hll:1; desc:[\'{"context":"實驗操作"}\', \'{"type":"農業操作"}\', \'{"作用":"既傷害植物組織又促進植物生長"}\', \'{"效果":"打破吸收壁壘, 促進稀土吸收"}\']}','福建師范大學地理科學學院: {hll:3; desc:[\'{"類型":"大學院系"}\']}','...'],'vertex_relations': ['中印度洋盆地 → GC11: {weight:1.0}','中印度洋盆地巖心沉積物稀土元素富集特征及賦存礦物 → GC11: {}','中印度洋盆富稀土沉積物中稀土元素賦存特征研究 → GC11: {}','中印度洋盆巖心樣品采集及特征描述 → GC11: {}','中印度洋盆巖心沉積物中稀土元素含量 → GC11: {}','中印度洋盆巖心沉積物中稀土元素賦存特征 → GC11: {}','中國大洋礦產資源研究開發協會( COMRA ) → GC11: {weight:1.0}','全礦物分析中GC04和GC11巖心樣本的檢測層次 → GC11: {}','巖心沉積物中礦物組成及含量差異 → GC11: {}','巖心沉積物礦物組成特征及分析方法 → GC11: {}','...'],'vertex_neighbors': ['GC04','GC11','HNO3-H2O2法','Super304鋼','...'],'vertex_belong_chapters': ['##### 全礦物分析','##### 單礦物原位微區分析','##### 成礦的控制因素','....'],'vertex_belong_para_contexts': ['GC03、GC04和GC11巖心沉積物的主微量及稀土元素組成','GC04和GC11巖心沉積物中稀土元素含量特征','...'],'vertex_belong_chapter_contexts': ['# Ce 2 ( SO 4 ) 3 對銅電沉積層晶粒細化的作用研究','# Dy 13.60 Ni 3.34 In 3.06 合金磁相變與磁熱性能研究','...']
}
二、API核心類詳解:AbutionGraphRagDriver
AbutionGraphRagDriver 是這個自動化流程的核心驅動類,提供了簡潔而強大的編程接口。
1. 初始化
僅需簡單配置,即可進行文檔處理成向量圖譜并更新到知識庫。
gdb_client = AbutionConnector("http://localhost:9090/rest")
# gdb_client.create_rag_graph("RareEarthPaper")
graph = gdb_client.Graph("RareEarthPaper")MODEL_CONFIGS = {"text": { # 文本模型(僅處理文字對話)},"image": { # 多模態模型(處理文本+圖片)},"embed": { # 向量模型(生成文本嵌入向量)}
}# 功能入口
rag_driver = AbutionGraphRagDriver(model_configs=MODEL_CONFIGS, # 多模型配置(文本、視覺、嵌入)work_path="storage/", # 工作目錄,用于存儲中間文件graph_instance=graph # AbutionGraph連接實例
)
- model_configs: 配置用于文本理解、視覺處理和向量嵌入的模型(例如通義千問Qwen系列)。
- graph_instance: 已初始化的AbutionGraph連接器,是所有知識數據的目的地。
- work_path: 處理過程中的中間文件(如解析后的Markdown、抽取的JSON等)會按文檔存儲在此目錄下。
2. 核心方法
-
pipeline_to_knowledge(): 一站式管道方法。傳入一個文件路徑,即可自動完成上述所有步驟(解析、抽取、建圖)。rag_driver.pipeline_to_knowledge(file_path="path/to/your/document.pdf",additional_prompt=ADDITIONAL_PROMPT,examples=EXAMPLES ) -
detect_communities(): 在構建好的圖譜上執行社區檢測,發現知識集群。rag_driver.detect_communities(increment=True, # 增量計算entity_sim=0.5, # 實體相似度閾值edge_sim=0.75 # 關系相似度閾值 ) -
search()與search_call(): 強大的檢索功能。search(): 返回結構化的知識結果,包括實體、關系和上下文信息。search_call(): 在search()的基礎上,將結果送入大模型進行總結和潤色,直接生成流暢的問答結果,是開箱即用的RAG接口。
支持多粒度檢索
您可以指定檢索的粒度級別:
# 可選粒度: ["實體級別", "段落級別", "章節級別", "文件級別", "超邊級別", "超點級別"]result = rag_driver.search(text="查詢內容",top_k=10,rag_type=["實體級別", "段落級別"] )支持子圖隔離檢索
如果使用了classify_id創建了多個子圖,可以指定檢索范圍:
result = rag_driver.search(text="查詢內容",top_k=10,classify_list=["ProjectA", "ProjectB"] # 只在指定子圖中檢索 )
3. 圖查詢語言
使用AbutionGraphRagDriver可以滿足知識庫構建、更新和檢索的任務,當然您也可以使用AbutionGraph的原生圖查詢語言或者Cypher、Gremlin、GraphQL等圖查詢語言定制內容。
一跳節點查詢示例:
graph.V('稀土元素').BothV().exec()
一、什么是“向量知識圖譜”?為什么它比傳統知識庫更強?
傳統的文檔管理工具,要么把文檔當“文件”存(如文件夾),要么把內容當“字符串”搜(如關鍵詞檢索),但從未真正“理解”知識。而向量知識圖譜的突破,在于它同時具備兩種核心能力:
- “關系腦”:像人類大腦一樣記錄實體間的關聯(如“La0.65Ca0.35MnO3”與“磁性”的影響關系、“稀土精礦”與“脫硝性能”的因果關系);
- “語義眼”:通過向量嵌入技術,讓機器能“看懂”語義(比如自動識別“CeO2”與“氧化鈰”是同一物質,即使文檔中從未明說)。
這種“關系+向量”的雙重特性,讓知識不再是孤立的文字,而是能被檢索、推理、關聯的“活數據”。
三、什么是“向量知識圖譜”?為什么AbutionGraph比傳統向量檢索知識庫更強?
市面上知識圖譜工具不少,但AbutionGraphRag的獨特優勢在于“全流程一體化+深度適配專業場景”:
1. 零代碼門檻,卻能深度定制
無需手動設計圖譜結構、標注數據,基礎流程“一鍵運行”;同時支持通過提示詞、示例數據、相似度閾值等參數,精準適配科研、制造、金融等不同領域的知識特點。
2. 原生向量圖數據庫,性能碾壓“拼湊方案”
AbutionGraph是“原生支持向量”的圖數據庫,無需額外對接向量庫(如Milvus),避免數據同步問題。即使處理數十億級實體關系,鑒于分布式特性,也能保持亞秒級檢索響應。
3. 超圖模型,輕松處理復雜知識
支持“超點”(如“某實驗團隊”作為一個整體節點)和“超邊”(如“材料A+工藝B→性能C”的多實體關系),比傳統圖模型更自然地表達復雜知識(如科研協作網絡、多因素影響關系)。
4. 多模態融合,不遺漏任何信息
不僅處理文本,還能解析文檔中的圖片、表格、公式,特別適合科研論文、技術手冊等復雜文檔——例如自動關聯“XRD圖譜”與對應的“物相分析結論”。
4. 語義計算 / 知識融合 / 動態知識更新
基于時序圖譜自動聚合計算的特性,相同節點的實體屬性可以自動聚合更新,且向量語義能夠自動合并,實現效果:“女生”+“皇帝”=“女王”,這對于不斷新增文檔的知識庫非常有用,因為相同的實體在跨文檔中得到的信息大概率不同,語義合并能夠豐富檢索效果。
四、誰在需要AbutionGraphRag?
- 科研人員:處理數百篇領域論文,自動生成“稀土材料研究脈絡圖”,將文獻綜述時間從“周級”壓縮到“小時級”;
- 企業知識庫:將技術手冊、故障案例、項目報告轉化為可檢索的知識圖譜,新員工上手速度提升50%;
- 智能客服:基于產品文檔構建問答系統,精準回答“某型號設備的材料成分”“故障代碼E102的解決步驟”等問題;
- 金融風控:分析企業年報、輿情新聞,自動構建“公司-關聯方-風險事件”圖譜,提前預警傳導風險;
- 工作流/智能體:綁定Dify等AI智能體業務創新平臺,實現更精準有效的知識檢索環節。
結語:讓知識從“沉睡”到“流動”
在這個信息過載的時代,真正的競爭力不是擁有多少文檔,而是能從文檔中快速提煉、關聯、應用知識的能力。
AbutionGraphRag正在做的,就是讓知識處理從“人工逐條整理”變成“機器自動構建”,從“關鍵詞匹配”變成“語義深度理解”。
不妨試試這款工具——讓你的文檔知識不再沉睡,而是成為能檢索、能推理、能創造價值的“活資產”。
👉 立即訪問官網。


:計數排序,排序算法復雜度對比和穩定性分析)

API)














