一、作品詳細簡介
1.1附件文件夾程序代碼截圖

全部完整源代碼,請在個人首頁置頂文章查看:
學行庫小秘_CSDN博客?編輯https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
1.2各文件夾說明
1.2.1 main.m主函數文件
該代碼實現了使用PSO優化SVR的參數,并在回歸問題上進行預測和評估的整個流程。以下是對代碼實現步驟的詳細解釋:
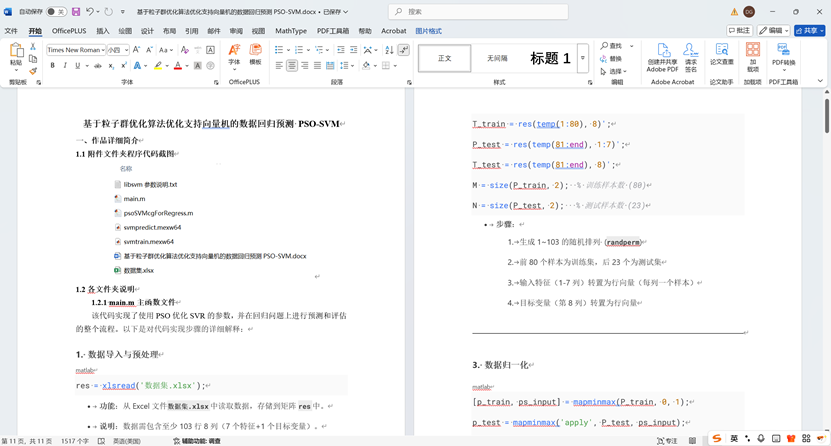
1. 數據導入與預處理
- 功能:從Excel文件數據集.xlsx中讀取數據,存儲到矩陣res中。
- 說明:數據需包含至少103行8列(7個特征+1個目標變量)。
2. 劃分訓練集和測試集
- 步驟:
- 生成1~103的隨機排列 (randperm)
- 前80個樣本為訓練集,后23個為測試集
- 輸入特征(1-7列)轉置為行向量(每列一個樣本)
- 目標變量(第8列)轉置為行向量
3. 數據歸一化
- 功能:將數據歸一化到[0,1]區間
- 步驟:
- 對訓練輸入P_train歸一化,保存參數ps_input
- 用相同參數歸一化測試輸入P_test
- 對訓練輸出T_train歸一化,保存參數ps_output
- 用相同參數歸一化測試輸出T_test
4. 數據轉置
- 目的:將數據轉為每行一個樣本的格式(適應SVM訓練函數)
5. PSO參數設置
- 關鍵參數:
- c1=1.5:個體學習因子
- c2=1.7:社會學習因子
- maxgen=100:最大迭代次數
- sizepop=10:粒子群規模
- popcmin/popcmax=[0.1,100]:SVM參數C的范圍
- popgmin/popgmax=[0.1,100]:SVM參數g的范圍
6. PSO優化SVM參數
- 功能:使用粒子群算法(PSO)優化SVM的懲罰參數C和核參數g
- 輸出:
- bestc:最優的C值
- bestg:最優的g值
- bestacc:最優精度
7. 訓練SVM模型
- 參數說明:
- -t 2:使用RBF核函數
- -s 3:支持向量回歸(SVR)
- -p 0.01:設置不敏感損失函數參數ε
8. 模型預測
- 輸出:
- t_sim1/t_sim2:訓練集/測試集的預測值
- error_1/error_2:預測誤差指標
9. 數據反歸一化
- 功能:將預測結果轉換回原始數據量綱
10. 計算誤差指標
- 指標說明:
- RMSE:衡量預測值與真實值的偏差
- R2:模型擬合優度(越接近1越好)
- MAE:絕對誤差的平均值
- MBE:系統偏差方向(正/負)
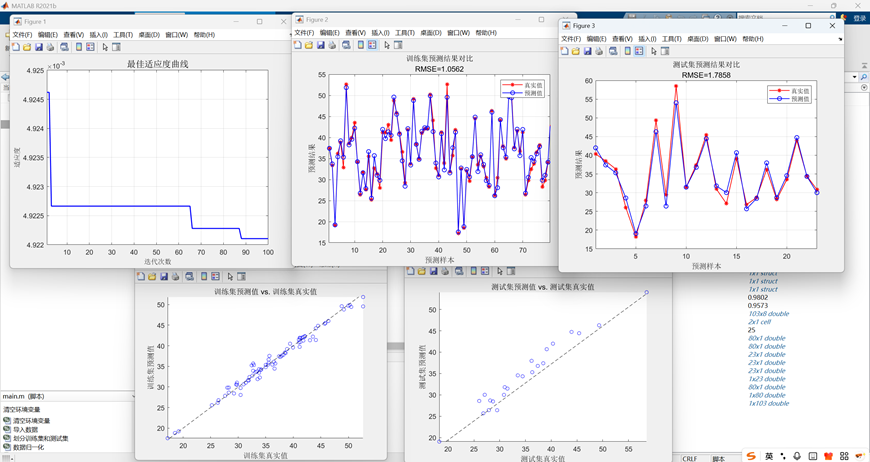
11. 結果可視化
- 可視化內容:
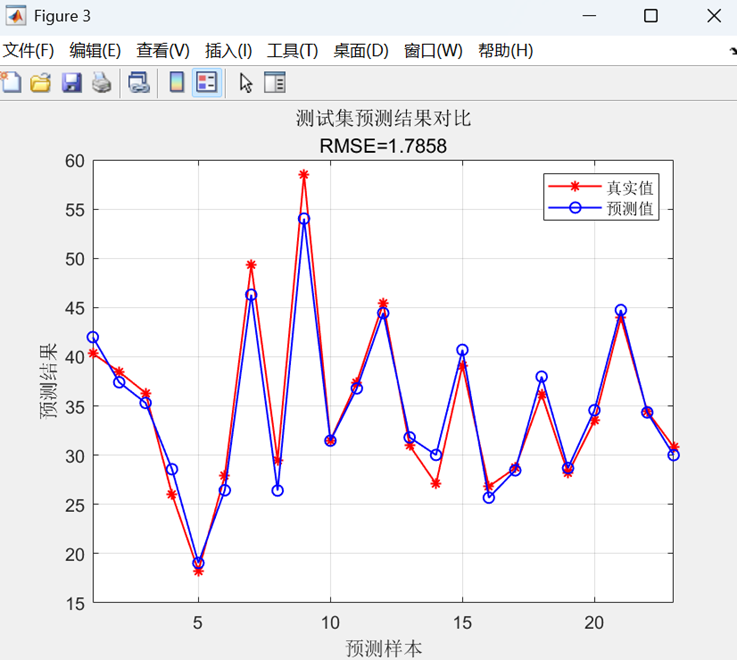
- 訓練集/測試集預測值與真實值對比曲線
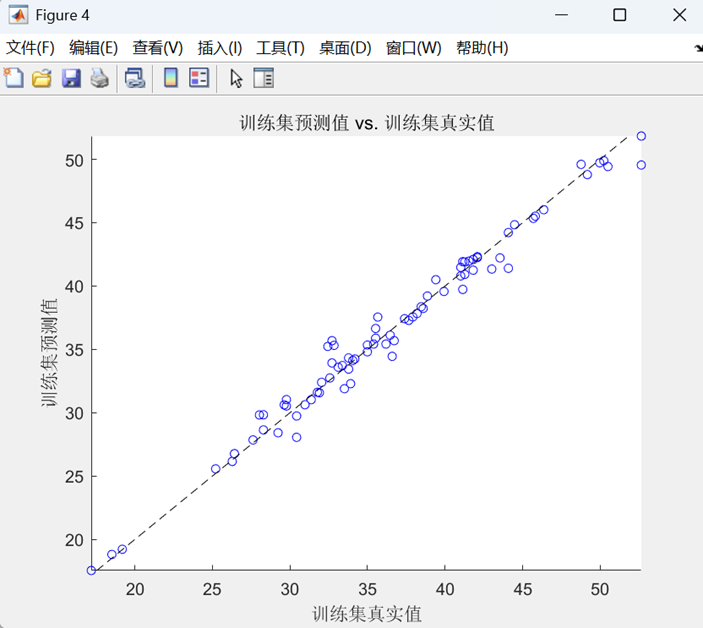
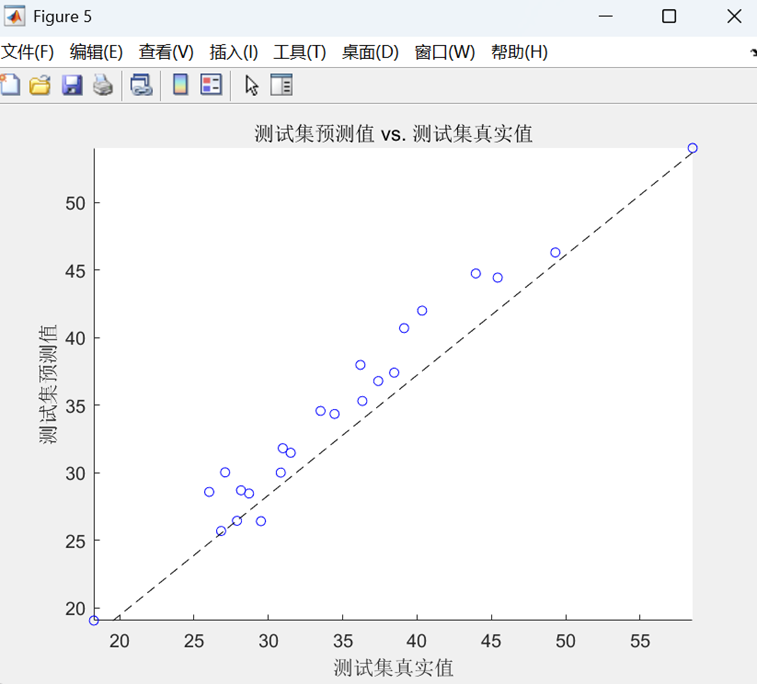
- 預測值-真實值散點圖(帶參考對角線)
- 所有圖表均標注RMSE值
代碼流程總結
- 數據準備:導入→隨機劃分→歸一化
- 模型優化:使用PSO算法搜索最優SVM參數
- 模型訓練:用最優參數訓練SVR模型
- 預測評估:預測→反歸一化→計算多維度誤差指標
- 結果展示:預測對比圖 + 散點圖 + 數值指標輸出
該代碼實現了完整的機器學習建模流程,特別通過PSO優化解決了SVR參數選擇難題,適用于中小規模回歸預測問題。
圖2? main.m主函數文件部分代碼
1.2.2 數據集文件
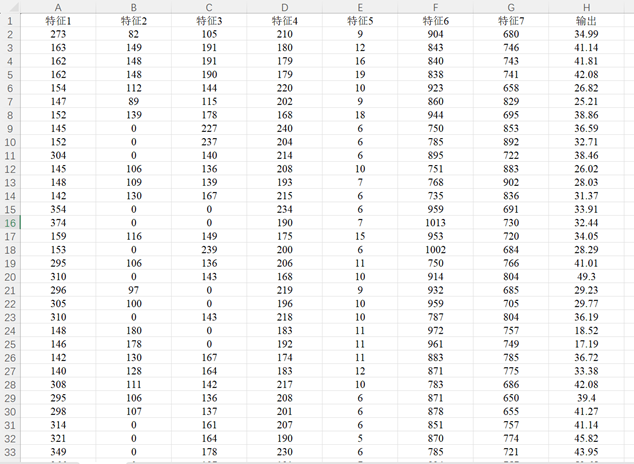
數據集為Excel數據csv格式文件,可以方便地直接替換為自己的數據運行程序。原始數據文件包含7列特征列數據和1列輸出標簽列數據,一共包含103條樣本數據,具體如圖所示。
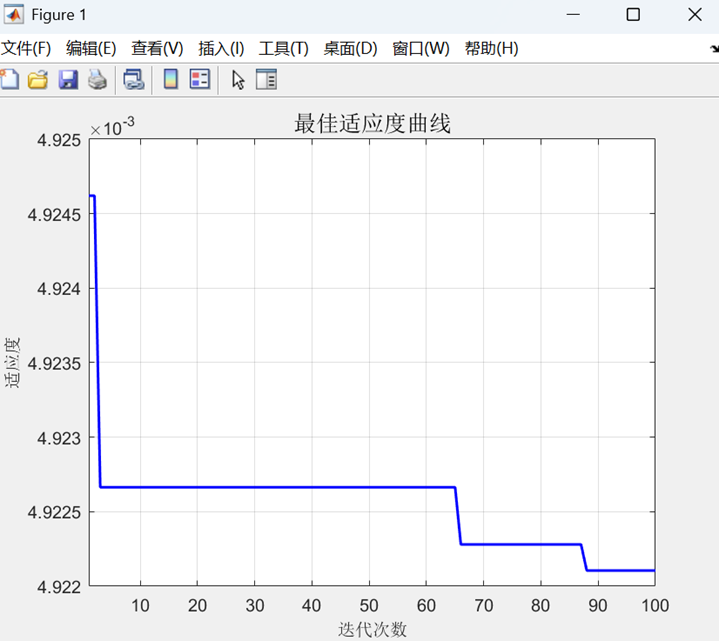
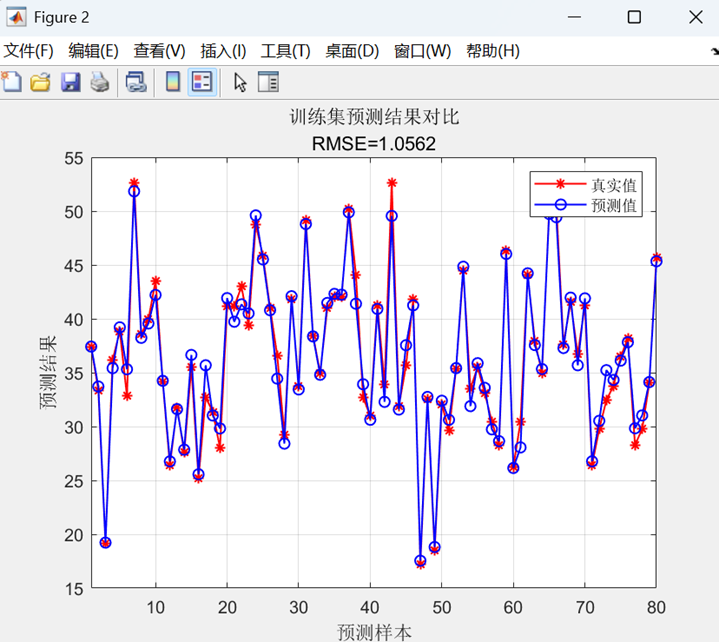
二、代碼運行結果展示
該代碼實現了基于粒子群優化支持向量機的回歸預測模型。
首先,從Excel導入數據集并隨機劃分為80個訓練樣本和23個測試樣本,對特征和目標變量進行歸一化處理;
其次,利用粒子群算法(PSO)優化支持向量機(SVM)的懲罰參數C和核參數g,使用最優參數訓練SVM回歸模型;
最后,在訓練集和測試集上進行預測,通過反歸一化得到最終結果,計算RMSE、R2、MAE等評估指標,并繪制預測對比曲線和散點圖進行可視化分析。
三、注意事項:
1.程序運行軟件推薦Matlab 2018B版本及以上;
2.所有程序都經過驗證,保證程序可以運行。此外程序包含簡要注釋,便于理解。
3.如果不會運行,可以幫忙遠程運行原始程序以及講解和其它售后,該服務需另行付費。
4. 代碼包含詳細的文件說明,以及對每個程序文件的功能注釋,說明詳細清楚。
5.Excel數據,可直接修改數據,替換數據后直接運行即可。



)
)








 SVM)


 的用法及區別,分別適合什么場景使用?)


