本文介紹使用四塊Framework主板構建AI推理集群的完整過程,并對其在大語言模型推理任務中的性能表現進行了系統性評估。該集群基于AMD Ryzen AI Max+ 395處理器,采用mini ITX規格設計,可部署在10英寸標準機架中。
Jeff Geerling大佬還開發了名為Beowulf AI Cluster的自動化部署工具集,該工具集基于Ansible平臺,可實現在beowulf集群架構上快速部署多種開源AI集群工具,支持CPU、GPU以及混合推理配置。
因為我只關心Max+ 395的性能測試部分(尤其是并行測試部分),所以本篇文章有刪改,想看原文的請看最后的Jeff Geerling大佬博客
系統硬件配置
本次評估的硬件配置采用了Framework提供的完整解決方案。每個計算節點包含Framework主板、專用電源模塊、Noctua CPU散熱器以及1TB WD NVMe固態硬盤。

Framework主板在設計上更接近于單板計算機(SBC)架構,而非傳統的插槽式CPU和內存桌面主板設計。該主板采用焊接式APU設計,集成了CPU、NPU(神經處理單元)和iGPU(集成圖形處理器)以及系統內存。根據Framework的技術說明,采用焊接式設計而非可更換內存模塊(如CAMM標準)的主要原因是為了確保內存時序的精確控制,從而在AI工作負載中實現最優性能表現。
集群基礎性能測試
系統組裝完成后,進行了全面的性能評估測試。完整的測試數據已在GitHub相關倉庫中詳細記錄,包括Framework Desktop的sbc-reviews完整數據、top500 HPL基準測試結果以及Ollama和LLM基準測試結果。

在環境特性方面,該集群系統表現出優異的靜音性能。配備Noctua CPU散熱套件的情況下,系統噪音控制在46dBa以下。主板預裝的散熱器采用相變熱界面材料技術,確保從APU裸芯到散熱器的高效熱傳導。散熱風扇支持智能調速,在系統空閑時可完全停轉。
在功耗特性方面,單個計算節點的功耗表現如下:睡眠狀態約2W,空閑狀態約11W,滿負荷運行時約150W。系統在高負載初期會短暫進入更高的turbo boost頻率狀態,但在持續滿負荷基準測試中會穩定在145-155W功耗范圍內。所有功耗測量均在交流電源端進行,測試環境運行Fedora 42操作系統(部分測試使用Fedora Rawhide開發版本)。
網絡連接性能測試顯示,雖然系統配備Thunderbolt/USB4端口,但實際測試中僅能達到10 Gbps的傳輸速率。內置以太網控制器支持5 Gbps傳輸速率,在實際測試中能夠穩定達到標稱速度。未來通過驅動程序優化或Linux系統調整,有望將Thunderbolt節點間連接速度提升至15-20 Gbps。
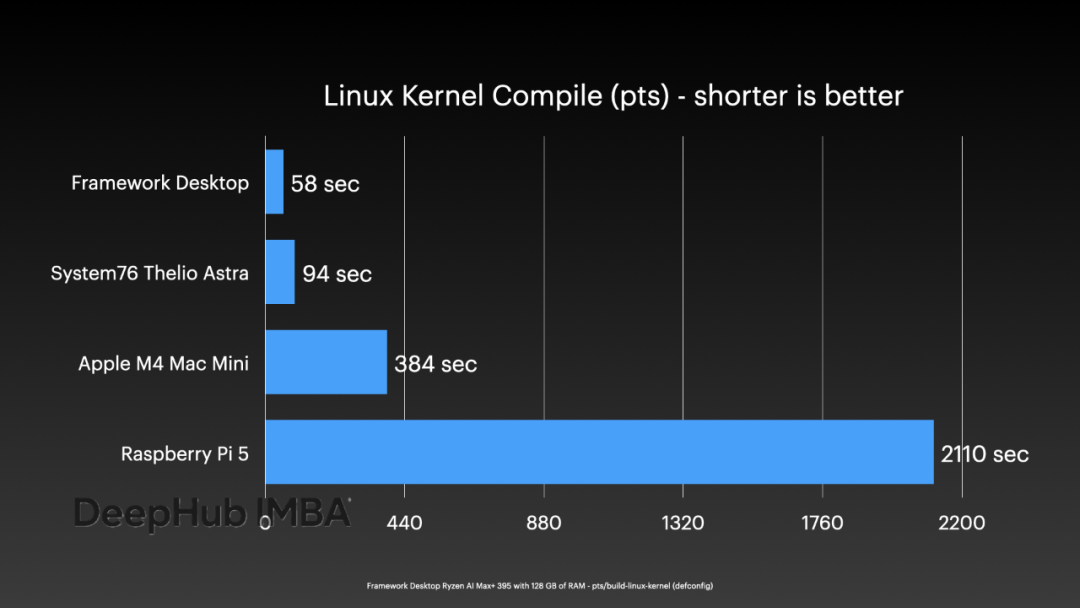
在通用計算性能方面,單個計算節點表現出色。運行
pts/build-linux-kernel
基準測試,單節點能夠在不到一分鐘的時間內完成Linux內核編譯任務。
四節點集群配置下,即使未進行針對Ryzen AI Max+芯片特性的專門優化,運行top500-benchmark測試仍能實現超過1 TFLOP的FP64浮點計算性能。
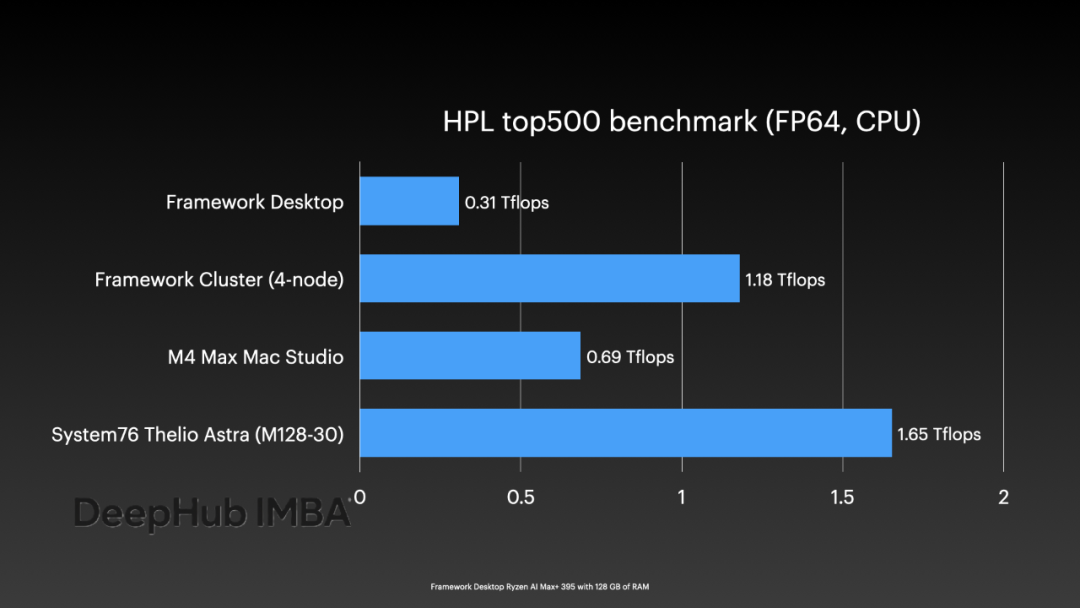
在能效比方面,雖然CPU效率表現良好,但與Apple M系列芯片仍存在顯著差距。在FP64計算能效比方面,其表現與Raspberry Pi 5相當。
GPU加速AI推理性能評估
這是我比較關心的問題,因為畢竟我們買這個都是為了做本地的LLM推理,之所以翻譯這篇文章的主要原因是大佬已經調通了并行推理,也就是說我們可以用幾臺主機橫向擴展,這樣可以加載更大的模型。
測試過程中發現,部分硬件功能(如內置NPU)仍無法正常工作。雖然AMD在評測期間發布了一些NPU測試示例,但由于時間限制,未能完成完整的驗證測試。基于這一現狀,建議用戶在選購時應基于當前已驗證可用的功能進行評估,而非基于未來承諾或規格說明中的潛在功能。
在軟件兼容性方面,初期在Fedora 42系統上配置ROCm與Ollama的集成遇到了一些技術障礙。最終通過升級至Fedora Rawhide版本解決了ROCm的兼容性問題,使得Ollama能夠正常運行,但其性能表現仍不如直接使用
llama.cpp
。
單節點配置下,系統能夠很好地支持CPU或iGPU推理模式,可選擇Vulkan或ROCm作為底層加速框架。性能測試結果顯示:

對于集成顯卡而言(在完全未使用NPU的情況下),測試獲得了令人滿意的性能數據。在能效比方面,雖然未能達到Apple芯片的水平,但在AMD消費級芯片中表現最佳。
集群測試階段為避免網絡配置問題的干擾,選擇使用內置網絡控制器,并配備了NICGIGA 5 Gbps 8端口交換機。這是目前市場上為數不多能夠在單一設備中提供多個5 Gbps RJ45端口的網絡交換解決方案。
使用Beowulf AI Cluster項目框架,對Exo、llama.cpp RPC和dllama等多種集群工具進行了系統性測試。測試結果顯示,Exo項目似乎缺乏持續維護,在Strix Halo支持方面存在長期未解決的問題,最終放棄了該工具的深入測試。llama.cpp RPC在處理小型模型時表現良好,但在大型模型上會采用輪詢調度模式,而在處理超大型模型(如DeepSeek R1 Q4_K_M)時會出現段錯誤異常(相關問題已在GitHub issue中報告)。distributed-llama在支持的模型范圍內(包括Llama 3.1 405B)能夠在集群環境中穩定運行,但Vulkan支持存在不穩定性,推理過程可能出現異常(如單詞無限循環重復),且目前支持的模型種類較為有限。
綜合測試結果表明,目前尚無完美的開源AI集群解決方案。
llama.cpp的RPC模式被認為是最具發展潛力的方案。在超大型LLM的輪詢調度問題演示中,通過
nvtop
工具監控GPU使用情況,可以觀察到主節點依次將計算任務分配給各個從節點的過程:
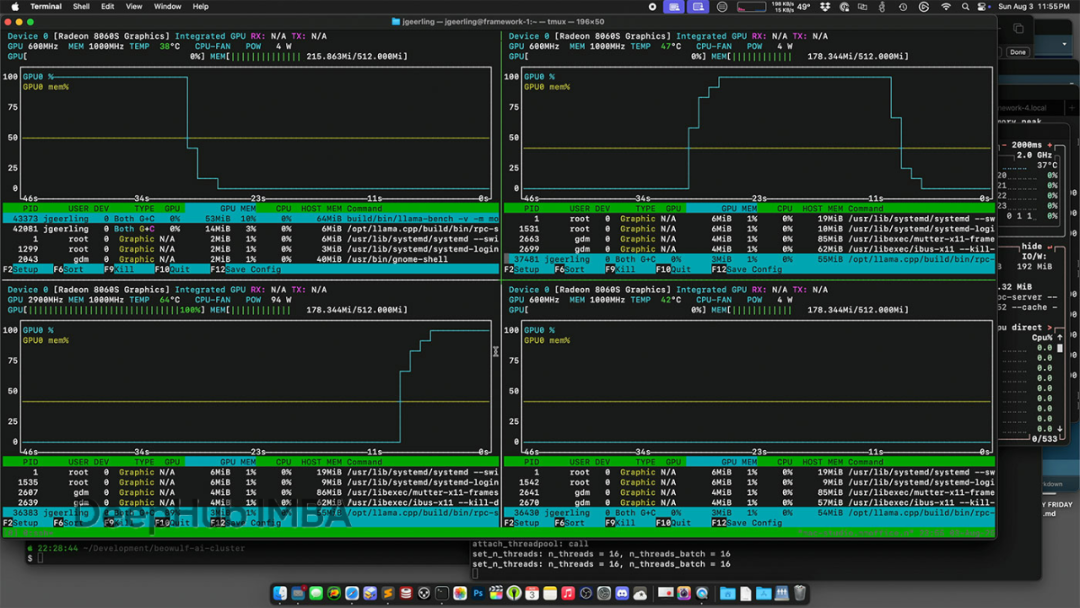
理想情況下,llama.cpp應能實現類似HPL在FP64數學計算中的并行化工作負載分配,但這涉及復雜的技術實現挑戰。正是由于這些技術難題,RPC功能目前仍被標記為實驗性質。
雖然技術社區經常討論通過組合多臺迷你PC構建AI集群的可行性,但實際實施過程遠比理論分析復雜。除了網絡帶寬相對于內存訪問速度的巨大劣勢外,現有AI集群工具的成熟度仍有待提升。
成本效益分析
從經濟角度分析,不包括DeskPi機架、托盤、網絡交換機和布線成本,本次測試的集群配置總成本約為8,004美元。
與其他大語言模型推理解決方案的性能成本比較如下:
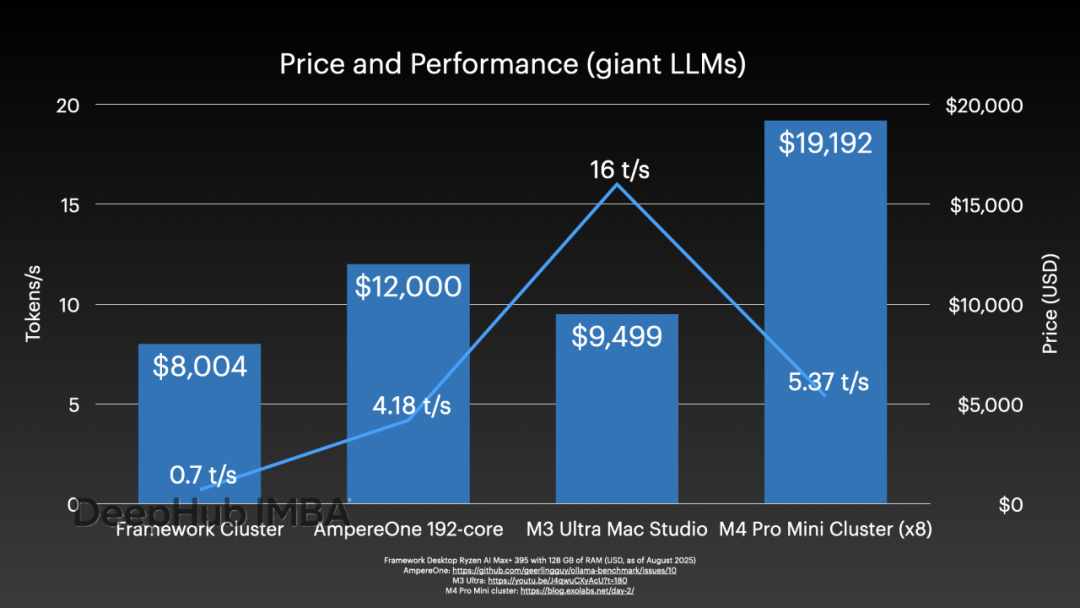
此前測試的AmpereOne服務器僅使用CPU即可達到4 tokens/s的推理速度,該服務器的采購成本約為12,000美元。
配備512GB內存的M3 Ultra Mac Studio售價接近10,000美元,但其性能表現顯著優于測試集群,可達到16 tokens/s的推理速度。
需要說明的是,上述性能比較中Framework集群的0.7 t/s數據基于Llama 3.1 405B模型測試,而其他系統的數據基于DeepSeek R1 671B模型(均采用Q4量化),因此這一比較并非完全等價。
在DeepSeek R1 Q2_K_M模型的集群測試中,使用Vulkan加速框架獲得了以下性能數據:

針對ChatGPT新發布的開源模型,在單節點配置下的測試結果如下:
gpt-oss-20b模型測試結果:

gpt-oss-120b模型測試結果:

在集群模式下運行相同模型時,
tg128
推理性能下降至24 tokens/s
測試結果表明,采用當前最先進的開源AI集群工具進行多機推理時,其性能表現始終不如單機大內存配置。在構建AI推理系統時,應優先考慮垂直擴展策略。集群化部署雖然理論上具有吸引力,但在AI應用場景中面臨額外的技術挑戰。
雖然開源AI集群工具未來可能達到與其他高性能計算工具相當的成熟度,但在當前技術水平下,要獲得更優的集群性能,仍需要專用硬件、高速互連以及大量的系統優化工作。
總結
AI集群技術雖然具有技術價值,但距離主流應用仍有相當距離。Deepseek的671B能拋出26t/s的速度如果自用的話是可以達到忍受的最低限度的。但是我個人感覺395最大問題還是價格,rdna3的魔改rdna3.5,對于游戲向肯定沒人買,作為AI產品,內存給的帶寬又太少了,而且摳搜的只有96G的顯存。這導致大模型推理還是需要并行,但是目前來看AMD的生態還是太弱了,并行智能靠RPC,并且Jeff 大佬的測試中還會出現錯誤一點都不穩定,這也導致395算是一個雞肋。不過歸根到底還是價格問題,現在價格是13999也就是1萬4,其實有這時間折騰RPC并行,我不如買8個V100,雖然硬件麻煩一些,但是只要硬件沒毛病,軟件直接上手就用了。所以等等黨們不要著急,如果這玩意能降到10999,沒準那時候并行的方案就穩定了,那就是真香,哈。
我只截取了我感興趣的部分,大佬原文:
https://avoid.overfit.cn/post/6e2057cb902b4033b3d6cd712f2a8c62







)
 除了傅里葉變換和離散余弦變換)










