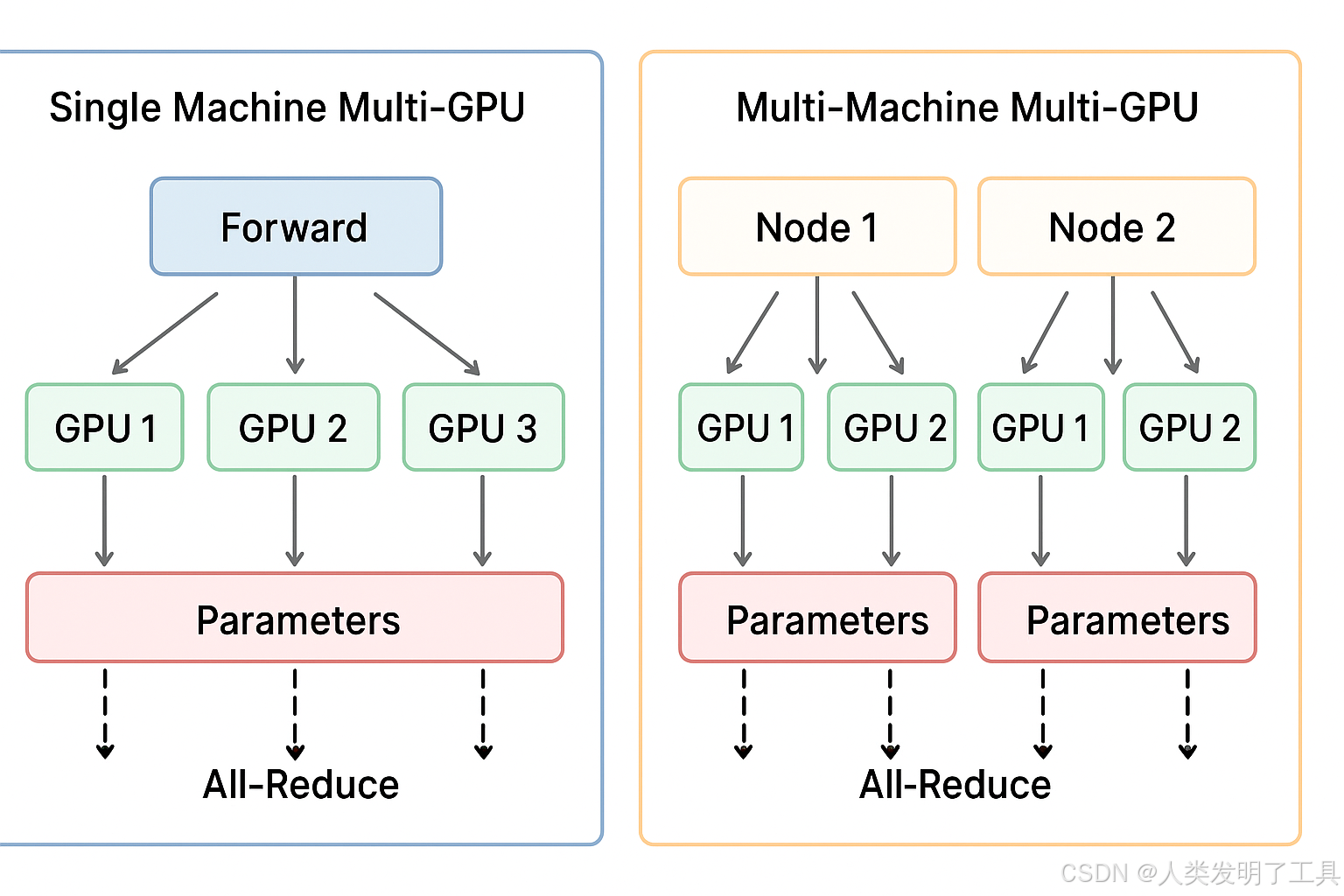
1. 單機多卡訓練(Single Machine, Multi-GPU)
概念
- 在同一臺服務器上,有多塊 GPU。
- 一個訓練任務利用所有 GPU 并行加速訓練。
- 數據集存放在本地硬盤或共享存儲上。
核心原理
-
數據并行(Data Parallelism)
- 將一個 batch 劃分成多個 mini-batch,每塊 GPU 處理一個 mini-batch。
- 每個 GPU 都有完整的模型副本。
- 前向計算在各自 GPU 獨立進行。
- 反向傳播結束后,通過 梯度同步(All-Reduce)聚合梯度,再更新模型參數。
- All-Reduce: 梯度求和取平均 + 同步更新,這樣保證梯度是基于全局 batch 的估計
-
梯度同步方式
- PyTorch 的
DistributedDataParallel(DDP) 或 TensorFlow 的 MirroredStrategy 都使用 NCCL(NVIDIA Collective Communication Library)在 GPU 間高速同步。- 多GPU訓練中,不同GPU需要頻繁交換數據(如梯度)。如果直接用通用通信方式(比如通過CPU或普通網絡庫),效率極低。
- NCCL(NVIDIA Collective Communications Library, NVIDIA 集合通信庫)多GPU和多節點環境優化的通信庫。
- 由于在同一臺機器,帶寬高、延遲低,通信成本較低。
- PyTorch 的
優缺點
-
優點:
- 實現簡單,通信效率高。
- 訓練速度明顯提升。
-
缺點:
- 受限于單機 GPU 數量和顯存大小。
- 數據量非常大時無法容納。
實現要點
- 使用
torch.nn.DataParallel(老方法)或torch.nn.parallel.DistributedDataParallel(推薦)。 - Batch size 可以拆分到每張 GPU。
- 注意隨機種子和數據劃分,保證每個 GPU 數據不同。
2. 多機多卡訓練(Multi-Machine, Multi-GPU)
概念
- 訓練任務跨多臺服務器,每臺服務器有多塊 GPU。
- 每臺機器稱為 Node,每塊 GPU 稱為 Rank。
- 適合大規模數據集或模型,單機無法容納。
核心原理
-
分布式數據并行(Distributed Data Parallel, DDP)
- 每個 GPU 依然保留完整模型副本。
- 每個 GPU 處理自己分配的 mini-batch。
- 梯度通過 All-Reduce 在所有 GPU 間同步,包括跨機通信。
- AllReduce 的設計就是 每個 GPU 都計算自己負責的部分,然后通過網絡傳遞累加,最終所有 GPU 得到相同結果。
-
通信機制
- 跨機通信通常通過高速網絡(InfiniBand 或 10/25/100GbE)進行。
- 需要指定 Master Node IP 和端口,其他節點通過 NCCL 或 Gloo 與 Master 節點通信。
- 訓練框架(如 PyTorch DDP、Horovod)負責梯度同步。
-
梯度同步策略
- 每次反向傳播完成后,將梯度在所有 GPU 匯總并平均,然后更新模型。
- 可使用 梯度壓縮 / 分層同步 優化跨機通信開銷。
優缺點
-
優點:
- 可以訓練超大模型或超大數據集。
- 擴展性好,GPU 數量理論上無限。
-
缺點:
- 實現復雜,需要網絡配置和多機同步。
- 跨機通信延遲高,成為訓練瓶頸。
- 出錯排查困難(網絡、節點故障、不同版本依賴)。
實現要點
- 確定每個 GPU 的 global rank(全局編號)。
- 配置
MASTER_ADDR、MASTER_PORT。 - 使用
torch.distributed.launch或torchrun啟動訓練。 - 注意 Batch size 調整(全局 batch = 每 GPU batch × GPU 數 × 節點數)。
- 數據集劃分需要確保不同節點不重復讀取。
3. 核心區別總結
| 維度 | 單機多卡 | 多機多卡 |
|---|---|---|
| 訓練范圍 | 一臺機器 | 多臺機器 |
| GPU 通信 | 同機高速互連(PCIe/NVLink) | 網絡跨機(Ethernet/InfiniBand) |
| 實現復雜度 | 低 | 高,需要網絡配置 |
| 擴展性 | 受限于單機 GPU 數量 | 高,可擴展到上百 GPU |
| 通信開銷 | 低 | 高,可能成為瓶頸 |
| 框架示例 | PyTorch DDP、MirroredStrategy | PyTorch DDP、Horovod |



)




)
通訊--Ble低功耗藍牙服務器)



,addWeighted())
)

)


