鏈接:https://github.com/byliutao/1Prompt1Story
這個項目是一個基于單個提示生成一致文本到圖像的模型。它在ICLR 2025會議上獲得了聚焦論文的地位。該項目提供了生成一致圖像的代碼、Gradio演示代碼以及基準測試代碼。
主要功能點:
- 使用單個提示生成一致的文本到圖像
- 提供在線
Gradio演示 - 包含基準測試代碼
技術棧:
- PyTorch
- Transformers
- Diffusers
- OpenCV
- Scipy
- Gradio
docs:1Prompt1Story
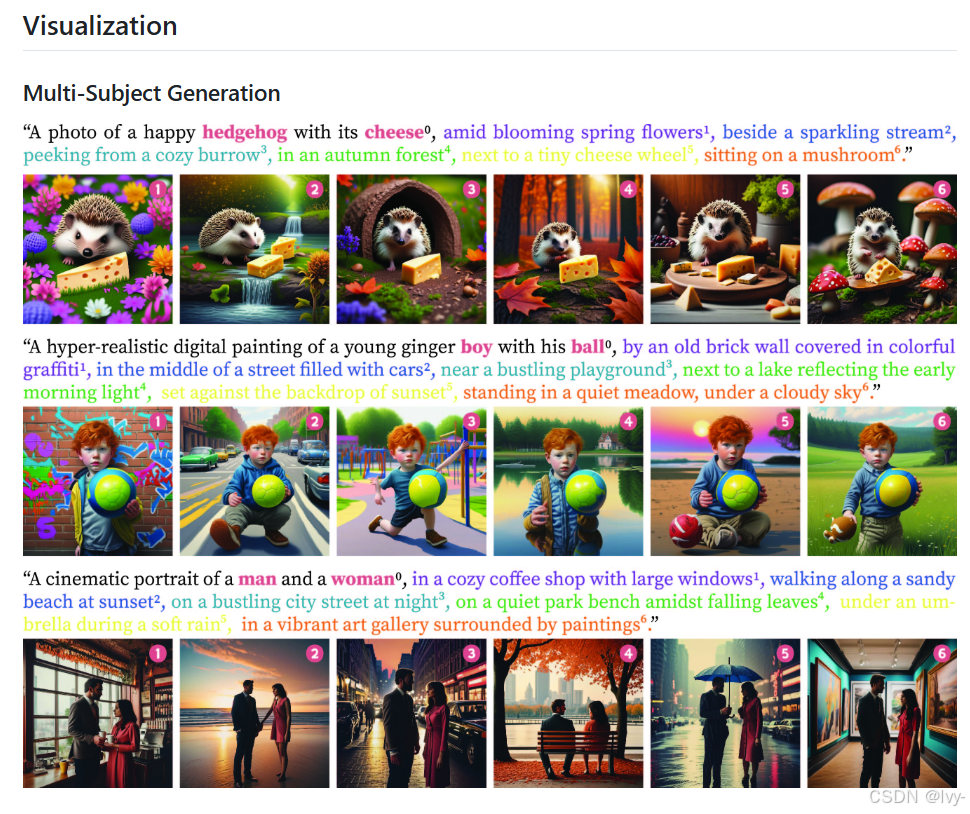
1Prompt1Story項目通過AI生成圖像實現連貫敘事。
該項目采用滑動窗口方法創建圖像序列,確保核心主體(ID提示詞)在不同場景中保持視覺穩定性。
這種一致性通過動態影響圖像生成過程的自定義控制實現,具體通過調節提示詞權重和注意力機制達成。
可視化
章節目錄
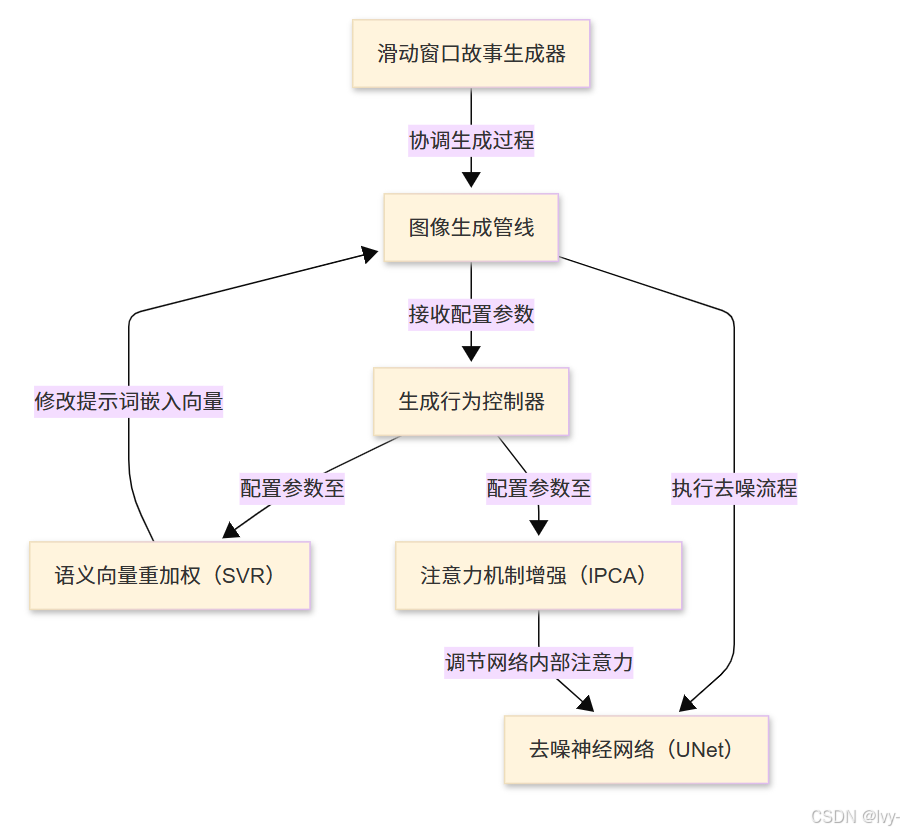
- 滑動窗口故事生成器
- 圖像生成管線
- 生成行為控制器
- 語義向量重加權(SVR)
- 注意力機制增強(IPCA)
- 去噪神經網絡(UNet)
第一章:滑動窗口故事生成器
歡迎來到1Prompt1Story的精彩世界🐻???
在本章中,我們將探索一種稱為滑動窗口故事生成器的智能技術。
該工具通過AI生成動態故事畫面,確保核心角色或對象在場景變換中保持視覺一致性。
一致性挑戰
假設我們需要創建包含連續場景的圖像故事,例如"紅狐在雪地嬉戲→進食漿果→樹下休憩"。
若將全部描述一次性輸入AI圖像生成器,可能導致畫面混亂:紅狐形象模糊或背景元素混雜。
核心問題在于:
- AI模型擅長處理
簡潔明確的指令 - 過長或復雜的提示詞會干擾模型對重點內容的理解
- 需要
分幀敘述策略,在保持主角一致性的同時實現場景平滑過渡
解決方案:滑動窗口機制
滑動窗口故事生成器猶如智能取景器,通過動態聚焦實現分步敘事:
- ID提示詞(核心主體):貫穿所有畫面的固定描述(如"紅狐")
- 幀提示列表(場景演變):分步場景描述集合(如[“雪地嬉戲”, “進食漿果”, “樹下休憩”])
- 滑動窗口機制:每次僅選取幀提示列表的子集生成單幀畫面,窗口沿列表滑動推進
- 循環模式:窗口到達列表末端時自動回繞起始位置,形成
無縫循環敘事
該機制確保:
- 核心主體(ID提示詞)在每幀畫面中保持清晰一致
- 場景通過漸進式切換實現流暢演變
滑動窗口工作流程
假設幀提示列表為[A, B, C, D],窗口長度為2:
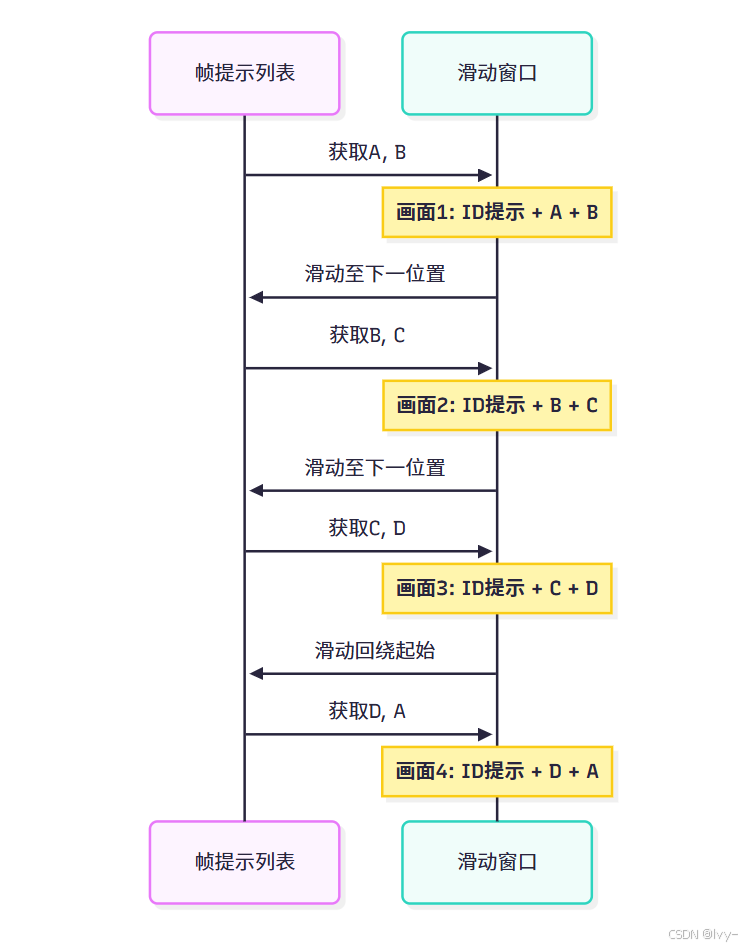
窗口滑動過程始終保持部分前一畫面的提示詞,通過重疊提示實現平滑過渡。
使用指南
通過main.py腳本啟動生成器,示例命令如下:
python main.py \--id_prompt "紅狐寫真" \--frame_prompt_list "佩戴圍巾于草地" "雪地嬉戲" "村莊邊緣臨溪" \--window_length 2 \--seed 42 \--save_padding "狐物語"
參數解析:
--id_prompt:核心主體描述(每幀畫面固定出現)--frame_prompt_list:場景演變描述集合(空格分隔)--window_length:單次組合的幀提示詞數量--seed:隨機種子(確保結果可復現)--save_padding:輸出文件前綴
執行后將生成序列圖像及合成故事長圖,紅狐形象保持穩定而場景漸進變化。
技術實現解析
核心函數movement_gen_story_slide_windows位于unet/utils.py,工作流程如下:
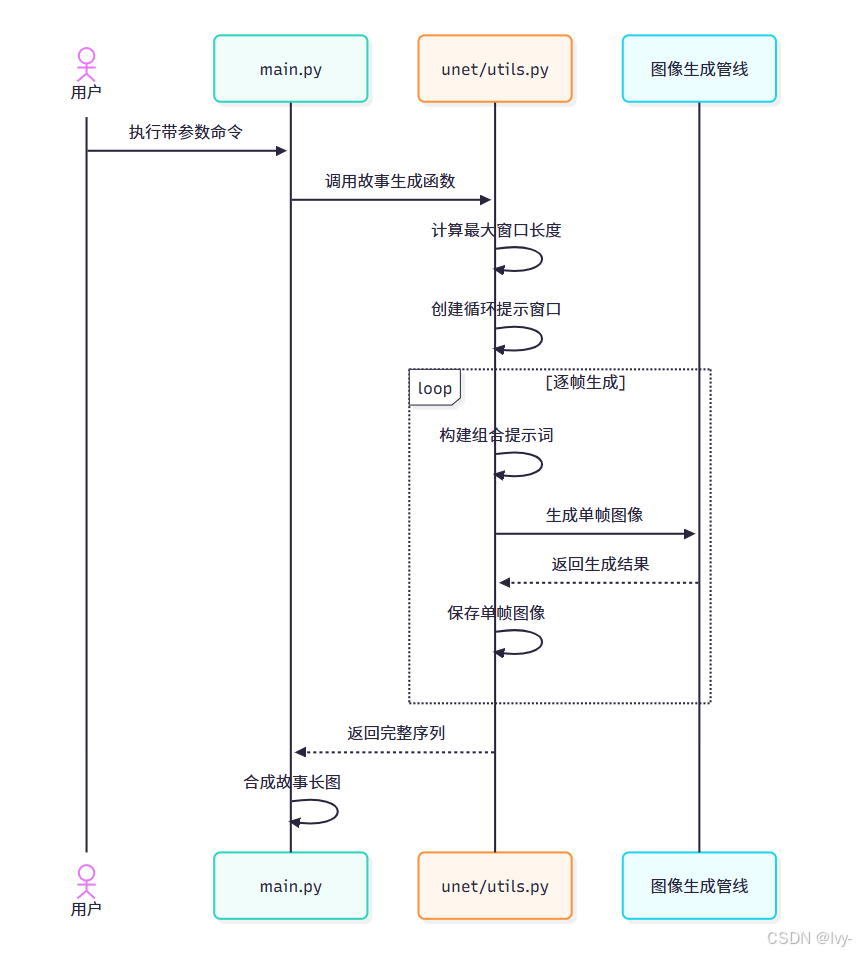
關鍵技術點:
最大窗口長度計算(防止提示詞過長)
def get_max_window_length(unet_controller, id_prompt, frame_prompt_list):combined_prompt = id_promptmax_len = 0for prompt in frame_prompt_list:combined_prompt += ' ' + promptif len(combined_prompt.split()) >= 77: # 標準token限制breakmax_len += 1return max_len
循環窗口生成
def circular_sliding_windows(lst, w):n = len(lst)return [ [lst[(i+j)%n] for j in range(w)] for i in range(n) ]
核心生成邏輯
def movement_gen_story_slide_windows(id_prompt, frame_list, pipe, window_len, seed, controller, save_dir):# 計算可用窗口長度max_win = get_max_window_length(controller, id_prompt, frame_list)window_len = min(window_len, max_win)# 生成提示窗口prompt_windows = circular_sliding_windows(frame_list, window_len)story_images = []for idx, window in enumerate(prompt_windows):# 配置提示詞權重controller.frame_prompt_express = window[0]controller.frame_prompt_suppress = window[1:]# 生成組合提示詞full_prompt = f"{id_prompt} {' '.join(window)}"# 調用生成管線image = pipe(full_prompt, generator=torch.Generator().manual_seed(seed)).images[0]story_images.append(image)# 合成輸出return combine_story(story_images)
code:https://github.com/lvy010/AI-exploration/tree/main/AI_image/1Prompt1Story
結語
本章揭示了滑動窗口故事生成器如何通過智能提示詞管理實現連貫敘事。
在后續章節中,我們將深入解析圖像生成管線的技術細節,揭示AI如何將結構化提示轉化為視覺盛宴。
第二章:圖像生成管線
在第一章中,我們學習了滑動窗口故事生成器如何巧妙編排文本提示序列,實現連貫的動畫敘事。
但精心設計的文本提示如何轉化為可見圖像?這正是圖像生成管線的核心使命。
圖像工廠:從文本構思到視覺現實
想象一個高科技工廠的運作場景:滑動窗口機制交付生產訂單(如"紅狐雪地嬉戲"的文本提示),這些訂單需經過專業設備處理才能轉化為成品(圖像)。
圖像生成管線正是這個智能工廠的全自動化產線與中央控制系統,負責將文本構思轉化為最終視覺呈現。
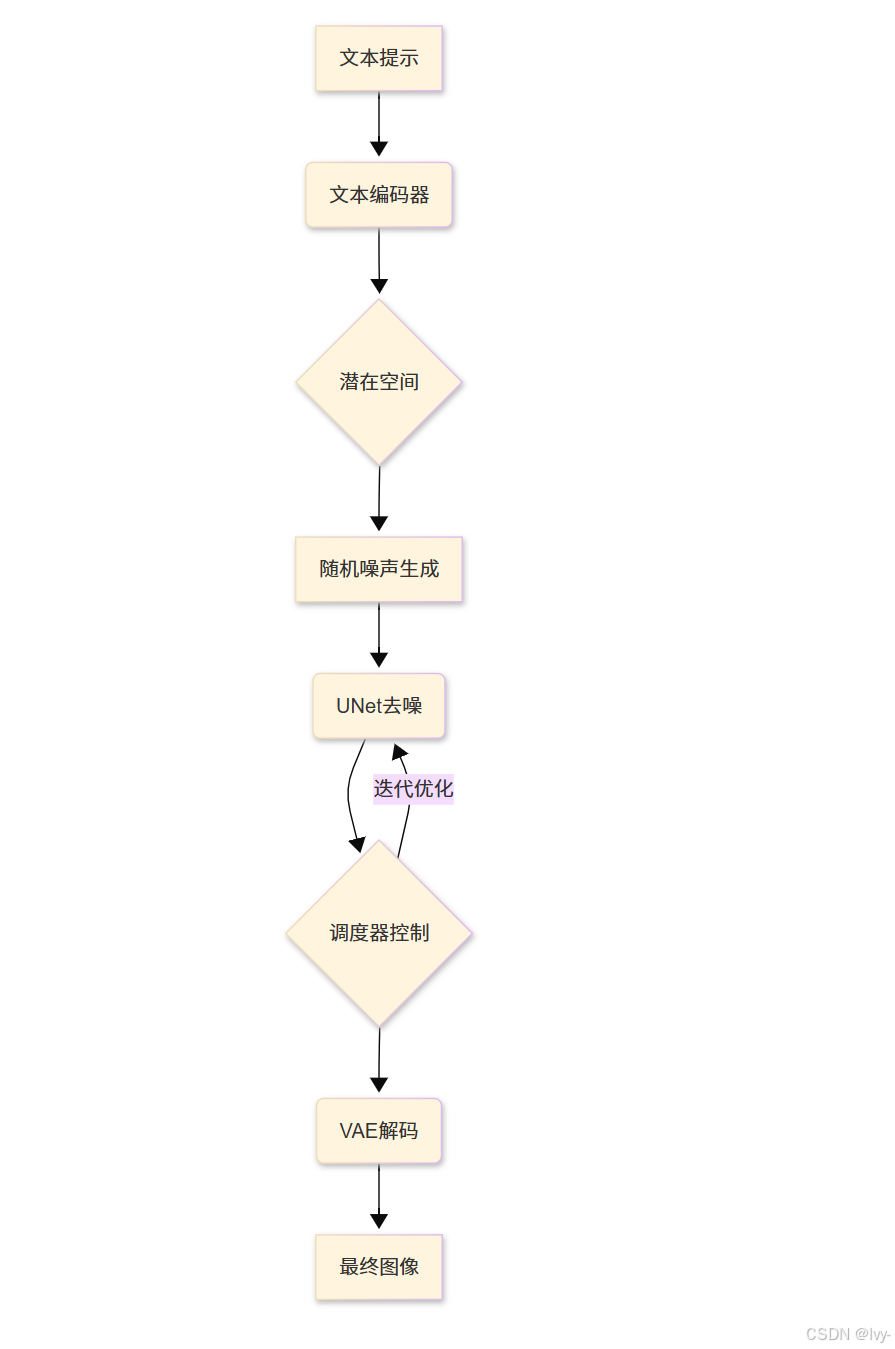
管線核心組件
我們的圖像工廠包含四大核心設備:
-
文本編碼器(語言翻譯器)
將人類可讀的提示(如"紅狐")轉化為AI可理解的數值化"思維向量" -
VAE(變分自編碼器)
一種生成模型,通過壓縮圖像到潛在空間(低維表示)再重建,適合生成模糊但結構合理的圖像。
圖像壓縮:將真實圖像編碼為抽象潛在表征圖像解壓:將潛在空間數據解碼為可視圖像
-
UNet(去噪神經網絡)
一種帶跳躍連接的對稱網絡,能保留圖像細節,常用于圖像分割或擴散模型中逐步去噪生成高清圖。作為核心畫師,從隨機噪聲(類似電視雪花屏)起步,在文本引導下通過多步去噪逐步揭示隱藏圖像
-
調度器(藝術指導)
精確控制UNet在各去噪步驟中的噪聲消除量,確保圖像生成過程平滑自然
管線使用方法
通過StableDiffusionXLPipeline實例(來自Diffusers庫的定制版本)實現核心交互:
# 摘自main.py(簡化版)
from unet.pipeline_stable_diffusion_xl import StableDiffusionXLPipeline
import torch# 初始化管線(加載模型與分詞器)
pipe = StableDiffusionXLPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16
).to("cuda") # 啟用GPU加速# 接收滑動窗口生成的提示詞
story_prompt = "紅狐雪地嬉戲寫真"# 配置可復現的隨機種子
story_generator = torch.Generator().manual_seed(42)# 執行圖像生成
# unet_controller參數用于高級控制(第三章詳解)
generated_images = pipe(prompt=story_prompt,generator=story_generator,unet_controller=None # 基礎模式設為None
).images# 保存首張生成圖像
generated_images[0].save("fox_snow.jpg")
參數解析:
generator:確保相同種子生成確定性結果unet_controller:實現跨幀一致性的高級控制接口(第三章詳解).images:返回PIL圖像對象列表
管線工作原理
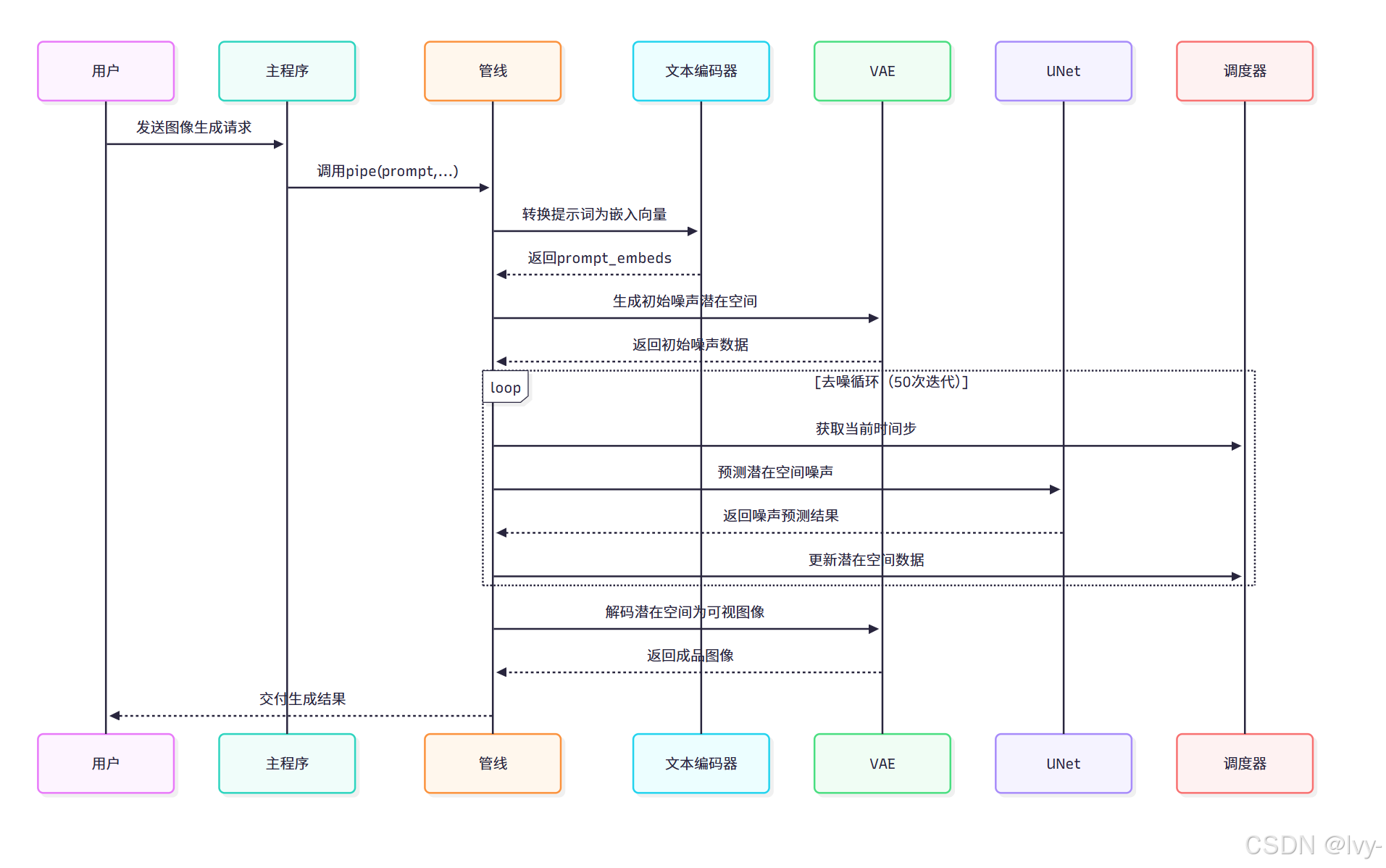
1. 提示詞編碼(encode_prompt)
def encode_prompt(self, prompt: str, ..., unet_controller=None):# 分詞處理text_inputs = self.tokenizer(prompt, padding="max_length", truncation=True, return_tensors="pt")# 生成嵌入向量prompt_embeds = self.text_encoder(text_input_ids, output_hidden_states=True)# 提取UNet專用嵌入層input_prompt_embeds = prompt_embeds.hidden_states[-2] return input_prompt_embeds
該過程將文本轉化為AI可理解的數值化表征,為后續生成提供語義指引
2. 潛在空間初始化(prepare_latents)
def prepare_latents(self, ..., same=False):# 生成隨機噪聲矩陣latent_shape = (batch_size, num_channels, height//8, width//8)latents = torch.randn(latent_shape, generator=generator)# 批量生成時保持噪聲一致性if same: latents[1:] = latents[0] return latents * self.scheduler.init_noise_sigma
創建初始噪聲空間時,same參數可實現跨幀噪聲一致性,為動畫連貫性奠定基礎
噪聲空間
是圖像生成過程中模型隨機添加的干擾信號,通過逐步調整這些噪聲最終生成清晰的圖像。類似于“從模糊的電視雪花屏逐漸修復成完整畫面”。
3. 去噪循環(call)
for i, t in enumerate(self.timesteps):# UNet預測噪聲分布noise_pred = self.unet(latent_model_input,t,encoder_hidden_states=prompt_embeds,unet_controller=unet_controller # 接受高級控制)# 調度器更新潛在空間latents = self.scheduler.step(noise_pred, t, latents)[0]
每次迭代逐步清除噪聲,unet_controller在此注入定制化生成邏輯
4. 圖像解碼(vae.decode)
image = self.vae.decode(latents, return_dict=False)[0]
將優化后的潛在空間數據解碼為768x768像素的RGB圖像
技術價值
1Prompt1Story是ICLR 2025聚焦論文項目,通過AI實現單提示詞驅動的連貫圖像敘事。
核心創新在于滑動窗口機制,將ID提示詞(如"紅狐")與幀提示列表(場景描述)動態組合,在保持主體一致性的同時實現場景平滑過渡。
技術實現結合PyTorch框架與Diffusers庫,通過文本編碼器、VAE、UNet等組件構建圖像生成管線,支持Gradio在線演示。
項目提供完整的代碼實現與基準測試方案,解決了傳統文本到圖像生成中主體漂移的難題。
該管線架構實現三大創新:
- 分層控制:通過UNet控制器實現提示詞權重
動態調整 - 潛在空間復用:批量生成時共享噪聲基底確保
跨幀一致性 - 自適應調度:根據硬件資源動態調整去噪步長














)




8.14)