二、R-CNN網絡基礎
2.R-CNN模型
2014年提出R-CNN!網絡,該網絡不再使用暴力窮舉的方法,而是使用候選區域方法(region proposal method)創建目標檢測的區域來完成目標檢測的任務,R-CNN是以深度神經網絡為基礎的目標檢測的模型,以R-CNN為基點,后續的Fast R-CNN,Fast R-CNN模型都延續了這種目標檢測思路
(1)算法流程
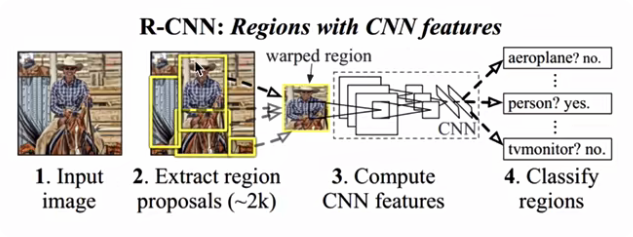
步驟:
- 候選區域生成:使用選擇性搜索(Selective Search,SS)的方法找出圖片中可能存在目標的候選區域
- CNN網絡提取特征:選取預訓練卷積神經網絡(AlexNet或VGG)用于進行特征提取
- 目標分類:訓練支持向量機(SVM)來辨別目標物體和背景,對每個類別,都要訓練一個二元SVM。
- 目標定位:訓練一個線性回歸模型(修正坐標),為每個辨識到物體生成更精確的邊界框
(1)候選區域生成
在選擇性搜索中,使用語義分割的方法,它將顏色,邊界,紋理等信息作為合并條件,采用多尺度的綜合方法,將圖像在像素級上劃分出一系列的區域,這些區域要遠少于傳統的滑動窗口的窮舉法產生的候選區域。(根據圖像像素點的相似性,分成不同的子區域,獲取外包矩形)

SelectiveSearch在一張圖片上提取出來約2000個候選區域,需要注意的是這些候選區域的長寬不固定。而使用CNN提取候選區域的特征向量,需要接受固定長度的輸入,所以需要對候選區域做一些尺寸上的修改。
(2)CNN網絡提取特征
采用預訓練模型(AlexNet或VGG)在生成的候選區域上進行特征提取,將提取好的特征保存在磁盤中,用于后續步驟的分類和回歸
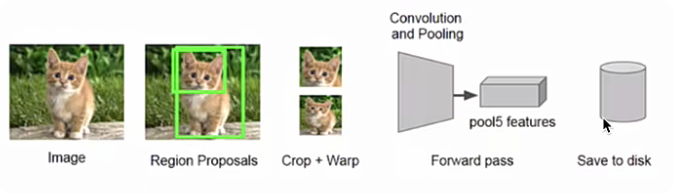
- 全連接層的輸入數據的尺寸是固定的,因此在將候選區域送入CNN網絡時,需進行裁剪或變形為固定的尺寸,再進行特征提取。
- 預訓練模型在ImageNet數據集上獲得,最后的全連接層是1000,在這里我們需要將其改為N+1(N為目標類別的數目,例如VOC數據集中N = 20,COCO數據集中N= 80,1是加一個背景)后,進行微調即可。
VGG16
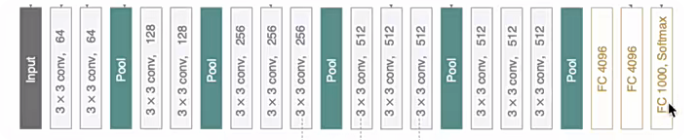
- 利用微調后的CNN網絡,提取每一個候選區域的特征,獲取一個4096維的特征(將最后的全連接層去掉,該4096維特征即表示某一個候選區域的結果),一幅圖像就是2000x4096維特征存儲到磁盤中。(有2000個候選區域)
(3)目標分類(SVM)

對于N個類別的檢測任務,需要訓練N(目標類別數目)個SVM分類器,對候選區域的特征向量(4096維)進行二分類,判斷其是某一類別的目標,還是背景來完成目標分類
(4)目標定位
通過選擇性搜索獲取的目標位置不是非常準確,實驗證明,訓練一個線性回歸模型在給定的候選區域的結果上去預測一個新的檢測窗口,能夠獲得更精確的位置。修正過程如下圖所示:

通過訓練一個回歸器來對候選區域的范圍進行一個調整,這些候選區域最開始只是用選擇性搜索的方法粗略得到的,通過調整之后得到更精確的位置

(5)預測過程
使用選擇性搜索的方法從一張圖片中提取2000個候選區域,將每個區域送入CNN網絡中進行特征提取,然后保存至磁盤中,然后送入到SVM中進行分類,并使用候選框回歸器,計算每個候選區域的位置。候選區域較多,有2000個,需要剔除掉部分檢測結果。針對每個類,通過計算IOU,采取非極大值抑制NMS方法,保留比較好的檢測結果。
算法總結
- 訓練階段多,訓練耗時:微調CNN網絡+訓練SVM+訓練邊框回歸器
- 預測速度慢:使用GPU,VGG16模型處理一張圖像需要47s
- 占用磁盤空間大:5000張圖像產生幾百G的特征文件。
- 數據的形狀變化:候選區域要經過縮放來固定大小,無法保證目標的不變形




:)





)








