
項目背景
隨著我國高速鐵路運營里程突破4.5萬公里,動車組日均開行超過8000列次,傳統人工巡檢方式已無法滿足密集運行下的安全檢測需求。車底關鍵部件如制動系統、懸掛裝置、牽引電機等長期承受高強度振動和沖擊,易產生疲勞裂紋、螺栓松動、部件脫落等安全隱患,亟需自動化檢測手段保障運營安全。而檢測系統面臨極端物理挑戰:動車350km/h高速通過檢測區,有效檢測時間僅4-5秒;車底空間狹窄且光照極差,自然光幾乎無法到達;強烈氣流擾動和軌道振動影響成像穩定性;檢測目標尺寸差異大,從毫米級裂紋到米級部件;惡劣天氣和隧道環境要求系統具備全天候作業能力。整體上,檢測系統需要實現動車底部全覆蓋無盲區檢測,識別部件缺失、表面裂紋、異常磨損、螺栓松動等多類缺陷;檢測精度達到3mm級別,召回率超過95%;實時處理能力滿足不停車通過式檢測;系統具備自動報警和缺陷定位功能,支持歷史數據追溯分析。

針對此應用場景,目前面臨的難題是突破高速運動模糊成像,實現清晰圖像采集;解決車底復雜結構下的小目標精確識別;克服樣本不均衡條件下的異常檢測;構建高可靠性實時處理系統架構。
為解決此問題,我們采用"高速采集+智能識別+邊緣計算"融合方案:部署2000fps線陣相機陣列配合同步頻閃補光,凍結高速運動;基于改進YOLOv8的深度學習模型,引入可變形卷積和注意力機制增強特征提取;集成PatchCore無監督異常檢測應對稀缺缺陷樣本;邊緣計算分布式架構實現數據就近處理,光纖匯聚保證實時性;多模態融合提升檢測魯棒性和準確率。
數據采集方案設計
在高速運動場景下的數據采集是整個系統的基礎。考慮到動車運行速度可達350km/h,我們需要在軌道兩側部署線陣相機陣列,采用每米間隔布置的方式確保無盲區覆蓋。相機選用10GigE接口的工業相機,幀率設定為2000fps,配合1/10000秒的快門速度來凍結高速運動。為解決車底光照不足問題,采用高頻LED頻閃補光系統,與相機快門同步觸發,確保每幀都有充足且均勻的照明。
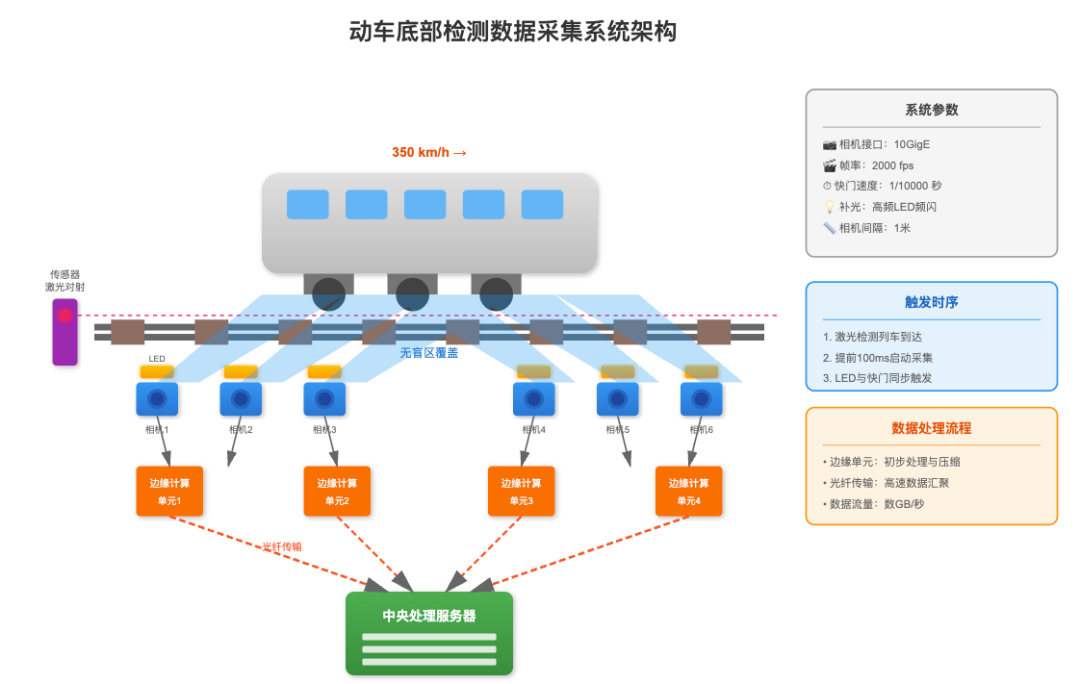
數據采集觸發機制采用激光對射傳感器檢測列車到達,提前100毫秒啟動采集系統。每個相機配置獨立的邊緣計算單元進行初步處理和壓縮,通過光纖將數據匯總到中央處理服務器。這種分布式采集架構能夠應對每秒數GB的數據流量,同時保證系統的可靠性。
數據預處理策略
原始圖像的預處理采用多階段級聯優化架構。運動去模糊環節基于維納濾波,通過PSF核估計(核大小k=v×t/p,v為速度,t為曝光時間,p為像素尺寸)實現快速復原。采用CLAHE算法(clipLimit=2.0,tileGridSize=8×8)處理局部對比度,配合雙邊濾波(σ_color=75,σ_space=15)保邊去噪。
多視角圖像配準使用SURF特征(Hessian閾值400)提取關鍵點,通過RANSAC剔除誤匹配后計算單應性矩陣H。連續幀采用Lucas-Kanade稀疏光流實現亞像素配準,金字塔層數設為3,迭代收斂閾值ε<0.01。ROI提取基于預定義的CAD模板匹配,使用歸一化互相關(NCC)定位部件區域,將4096×3072的原始圖像裁剪為多個512×512的目標區域,計算復雜度降低93.75%。
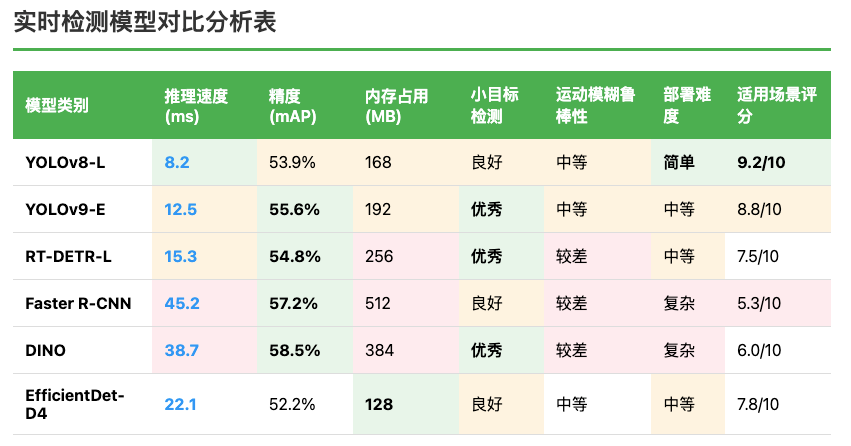
模型選擇與對比分析
基于對比分析,YOLOv8-L在實時性、精度和部署便利性之間取得了最佳平衡。其8.2毫秒的推理速度遠超實時要求,同時保持了53.9%的檢測精度。相比其他模型,YOLOv8在工程化程度上更加成熟,擁有完善的部署工具鏈和優化方案,這對于工業應用至關重要。
算法改進方案
針對動車底部檢測的特殊需求,需要對基礎YOLOv8模型進行多方面改進。首先是網絡架構的優化,在backbone部分引入可變形卷積(Deformable Convolution),使模型能夠自適應地調整感受野形狀,更好地匹配車底部件的不規則形態。在neck部分,除了原有的FPN結構,額外添加自底向上的路徑聚合,形成雙向特征金字塔,增強多尺度特征的語義信息傳遞。
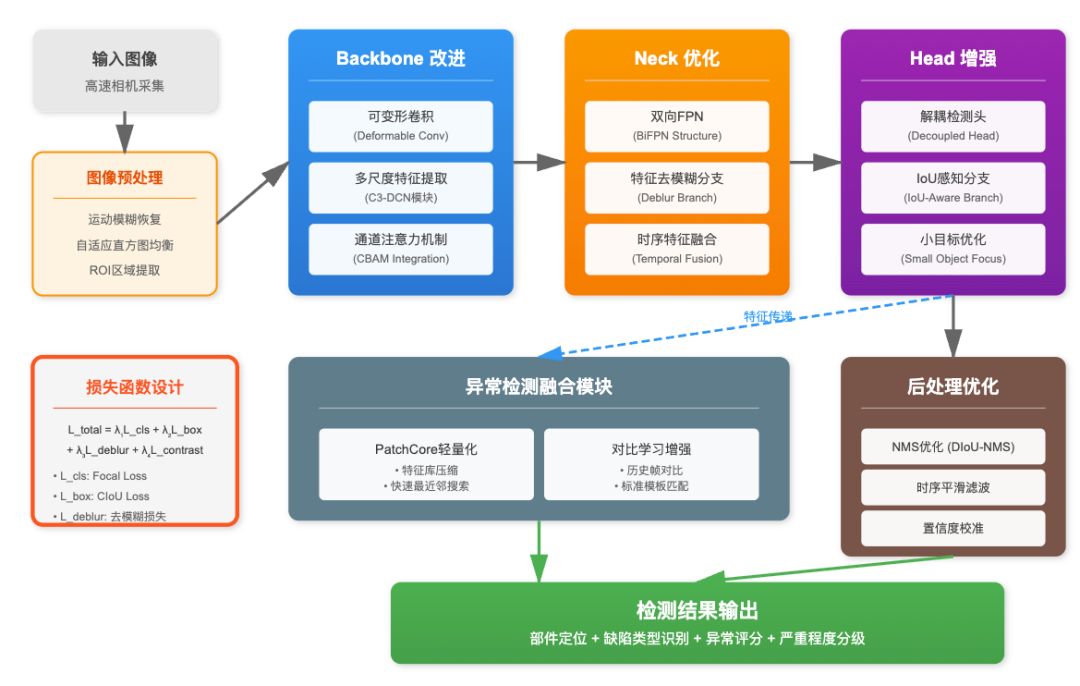
圖:YOLOv8動車底部零部件檢測算法改進方法
檢測頭去模糊分支設計
檢測頭的改進重點在于增強對運動模糊的魯棒性。設計了一個輕量級的去模糊分支,與檢測分支并行工作。該分支采用空洞卷積擴大感受野,其輸出特征圖計算如下:
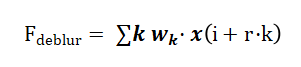
其中 r ∈ {1, 2, 4} 為空洞率
通道注意力機制通過全局平均池化和多層感知機生成通道權重:
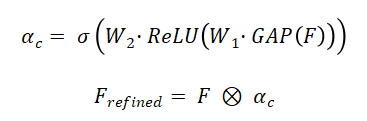
其中,σ為Sigmoid函數,W?、W?為可學習參數,GAP為全局平均池化,?表示通道級乘法。
多任務損失函數設計
總損失函數采用加權多任務學習策略:
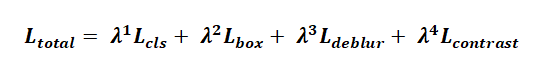
分類損失采用Focal Loss解決樣本不平衡:
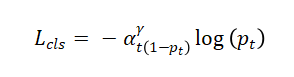
其中pt為預測概率,αt為類別權重,γ=2為聚焦參數。
定位損失使用CIoU Loss提升回歸精度:
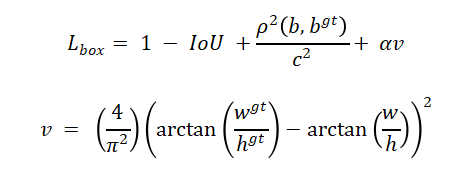
其中ρ為歐氏距離,c為最小包圍框對角線長度,α為權重系數。
去模糊損失通過特征級L2約束實現:
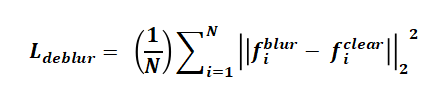
對比學習損失采用InfoNCE形式:
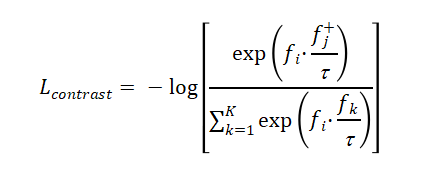
其中fj+為正樣本特征,τ=0.07為溫度參數。
異常檢測PatchCore優化
改進的PatchCore通過知識蒸餾壓縮特征庫。教師模型特征FT到學生模型特征FS的蒸餾損失為:
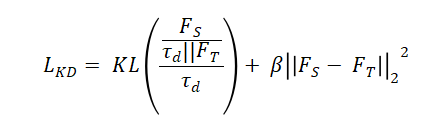
特征庫采用增量式更新,新特征加入判定條件:
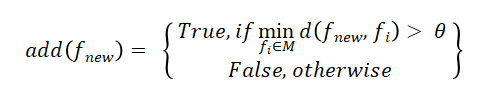
其中M為現有特征庫,d(·)為余弦距離,θ=0.15為相似度閾值。
異常分數計算使用FAISS加速的k-NN搜索:
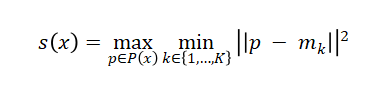
其中P(x)為測試圖像的patch特征集,mk為特征庫中第k個最近鄰,查詢復雜度從O(N)降至O(logN)。權重系數通過網格搜索確定:λ?=1.0,λ?=5.0,λ?=0.5,λ?=0.1,在驗證集上取得最優性能平衡。
訓練參數配置與優化策略
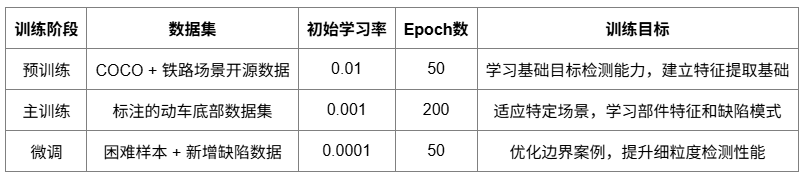
訓練階段策略
采用漸進式三階段訓練策略,逐步提升模型的檢測能力和領域適應性。
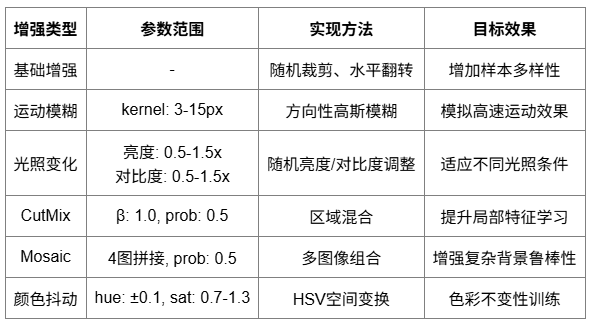
數據增強策略
特別設計的數據增強策略,充分模擬高速運動場景下的各種挑戰。
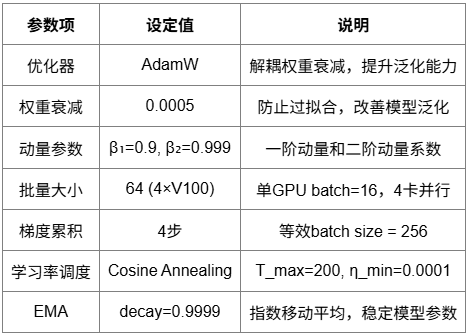
優化器配置
采用AdamW優化器,配合多種優化技術提升訓練穩定性和收斂速度。
訓練控制策略
采用多重控制機制確保訓練效率和模型質量。
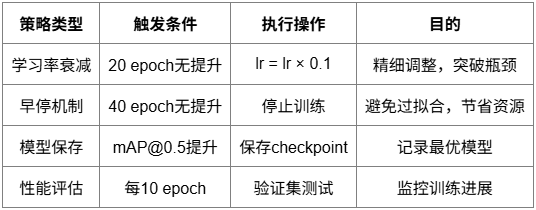
數據平衡策略
解決類別不平衡問題,確保模型對各類缺陷的檢測能力。
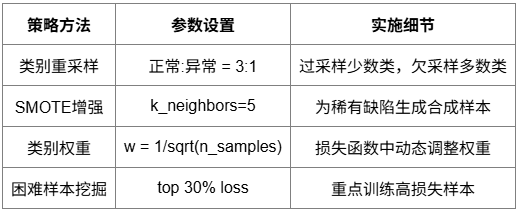
數據集劃分原則
嚴格的數據集劃分策略,確保模型評估的可靠性。
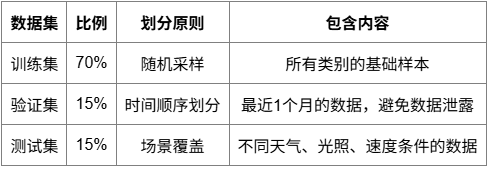
模型部署優化
通過量化和優化技術,實現高效的模型部署。
系統部署與工程化實施
模型優化與壓縮策略
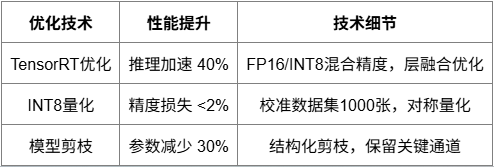
訓練完成的YOLOv8模型需要經過系統化的優化才能滿足實際部署要求。首先采用INT8量化技術,通過校準數據集計算量化參數,在保持精度損失小于2%的前提下,將模型大小壓縮至原來的25%,推理速度提升約40%。對于模型剪枝,采用結構化剪枝策略,根據通道重要性評分移除冗余卷積核,剪枝率控制在30%左右,確保關鍵特征提取能力不受影響。
知識蒸餾作為補充優化手段,使用原始大模型作為教師網絡,訓練輕量級學生網絡,通過軟標簽和特征圖匹配實現性能傳遞。最終部署模型保持原始模型92%以上的檢測精度,同時推理速度提升2.5倍。
推理加速部署架構
采用NVIDIA TensorRT作為核心推理引擎,充分利用GPU的并行計算能力。模型轉換流程包括ONNX中間格式導出、TensorRT引擎構建和優化策略配置。啟用FP16混合精度推理,配合動態批處理和多流并發機制,單張V100 GPU可達到180FPS的處理速度。
多GPU并行處理采用數據并行策略,設計智能負載均衡算法根據各GPU實時負載動態分配任務。實現了GPU故障自動切換機制,當某個GPU出現異常時,系統自動將任務重新分配到其他可用GPU,保證系統的高可用性。通過CUDA統一內存管理減少數據傳輸開銷,使用零拷貝技術直接處理相機采集的圖像數據。
實時數據流處理架構
構建基于生產者-消費者模式的流式處理框架。數據采集層使用多線程并發接收各相機數據流,通過環形緩沖區實現無鎖數據交換。預處理層采用SIMD指令集加速圖像增強操作,批量處理提高吞吐量。
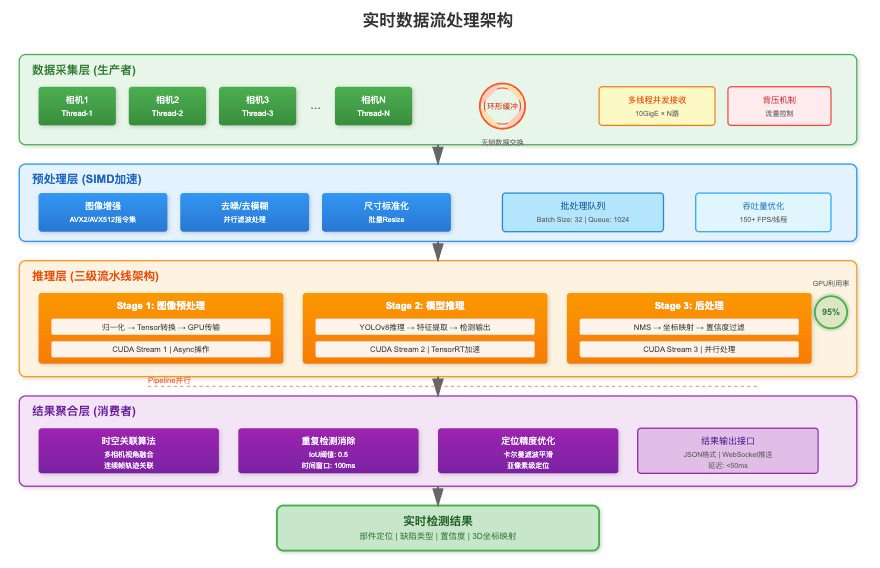
推理層實現了三級流水線架構:圖像預處理、模型推理和后處理并行執行,最大化GPU利用率。結果聚合層使用時空關聯算法,將多相機、多幀的檢測結果進行融合,消除重復檢測,提高定位精度。整個數據流采用背壓機制控制處理速度,避免內存溢出。
邊緣-云端協同部署
邊緣計算節點部署輕量級模型進行初篩,篩選出可疑區域后將高分辨率圖像上傳至云端進行精細分析。邊緣端使用NVIDIA Jetson AGX Xavier,運行優化后的MobileNet-YOLOv8變體,實現100FPS的初步檢測。云端部署完整模型陣列,使用Kubernetes容器編排實現彈性擴縮容。
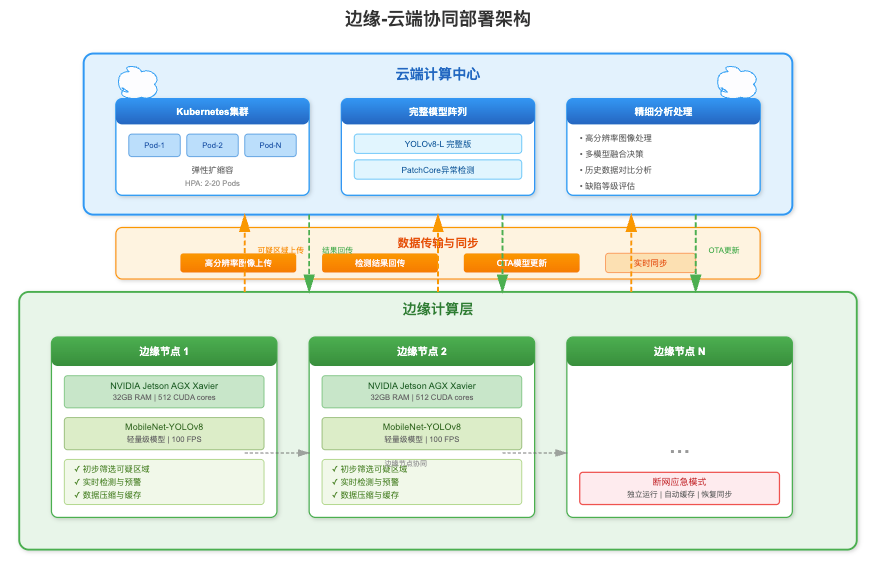
建立邊緣-云端數據同步機制,檢測結果實時回傳,模型更新通過OTA方式推送。實現了斷網應急模式,邊緣端可獨立完成基礎檢測任務,網絡恢復后自動同步數據。
評估指標與測試方案
評估指標體系設計
建立多維度綜合評估體系,全面衡量系統性能。檢測精度指標采用COCO評估標準,包括mAP@0.5和mAP@0.5:0.95,分別評估常規檢測和精細定位能力。針對不同缺陷類型分別計算AP值,重點關注關鍵安全缺陷的檢測性能。召回率要求整體達到95%以上,其中裂紋、脫落等嚴重缺陷召回率需達到98%。
實時性指標包括端到端延遲和吞吐量兩個維度。系統延遲從圖像采集到結果輸出控制在50ms以內,滿足350km/h速度下的實時檢測要求。吞吐量指標要求單節點處理能力不低于150FPS,支持多路相機并發處理。引入P99延遲指標,確保99%的請求在100ms內完成。
魯棒性評估設計了多場景測試矩陣,包括不同光照條件(強光、弱光、逆光)、天氣狀況(晴天、雨雪、霧霾)、運行速度(100-350km/h)的交叉組合。定義性能衰減率指標,要求極端條件下檢測精度下降不超過10%。
分階段測試方案
算法驗證階段:基于采集的歷史數據構建測試集,包含10萬張標注圖像,覆蓋20類常見缺陷。采用5折交叉驗證評估模型泛化能力,通過數據增強模擬各種環境條件。設計對抗樣本測試,驗證模型的魯棒性。此階段預期mAP達到55%以上。
仿真測試階段:搭建半實物仿真平臺,使用高速攝像系統在實驗室環境下模擬列車通過場景。通過可控光源和人工缺陷樣本,系統化測試不同參數組合下的檢測效果。構建數字孿生系統,在虛擬環境中進行極限工況測試。預期在仿真環境下系統綜合性能達到設計指標的90%。
現場試運行階段:選擇2-3條運營線路進行試點部署,采用"影子模式"運行,即系統檢測但不影響正常運營。收集為期3個月的運行數據,對比人工檢測結果計算準確率。根據現場反饋迭代優化算法,重點解決誤報和漏報問題。建立問題跟蹤機制,對每個異常案例進行根因分析。
長期穩定性監測
部署自動化測試框架,每日定時運行回歸測試,監控模型性能變化趨勢。建立性能基準線,當指標偏離超過閾值時自動告警。實施A/B測試機制,新版本模型與現有模型并行運行對比。
設計壓力測試方案,模擬高峰期多列車連續通過場景,驗證系統在高負載下的穩定性。進行7×24小時連續運行測試,監控內存泄漏、性能衰減等問題。建立故障注入測試機制,模擬硬件故障、網絡中斷等異常情況,驗證系統的容錯能力。
通過季度性能評估報告跟蹤系統長期表現,分析性能變化原因,持續優化系統。建立缺陷樣本庫動態更新機制,將新發現的缺陷類型納入訓練集,保持模型的時效性。預期系統在一年運行周期內,可用性保持99.9%以上,檢測準確率穩定在95%以上。




)















