Myoelectric Signal Classi?cation Using Convolutional Neural Networks with Pre-Extracted Features
原文:DOI:?10.1109/ICICS55353.2022.9811218
2022
翻譯:靠岸學術
目錄
摘要
1引言
2背景
A. 卷積神經網絡
B. 特征工程
3材料與方法
A. CNN集成
4結果
5討論
6結論
摘要
This paper presents a model in which time and frequency domain data are pre-extracted from electromyographic (EMG) signals and used as input to a Convolutional Neural Network (CNN) to classify a patient’s limb movements. EMG is a source of information for the development of prostheses, but its classi?cation still represents a challenge due to its inherent variability and non-stationary nature. The proposed approach provides representative information about the EMG signal to CNN, which then selects the relevant features and performs the classi?cation more accurately. The investigation evaluated the work using six data sets, with upper and lower limb movements (p < 0.05). The comparison with other similar approaches demonstrates its potential, reaching 98.84% of accuracy, superior to the traditional algorithms. The study suggests the feasibility of employing CNN-type networks in the case of the EMG signal, combined with a pre-processing technique.
Index Terms—Signal Processing, Convolutional Neural Network, Pattern Recognition, Feature Selection, Rehabilitation, BioPatRec.
本文提出了一種模型,該模型從肌電圖(EMG)信號中預先提取時域和頻域數據,并將其用作卷積神經網絡(CNN)的輸入,以對患者的肢體運動進行分類。肌電圖是假肢開發的信息來源,但由于其固有的變異性和非平穩性,其分類仍然是一個挑戰。所提出的方法向CNN提供關于EMG信號的代表性信息,然后CNN選擇相關特征并更準確地執行分類。該研究使用六個數據集評估了這項工作,包括上肢和下肢運動(p < 0.05)。與其他類似方法的比較表明了它的潛力,達到了98.84%的準確率,優于傳統算法。該研究表明,結合預處理技術,在EMG信號的情況下采用CNN型網絡是可行的。
索引詞—信號處理、卷積神經網絡、模式識別、特征選擇、康復、生物模式識別。
1引言
肌電信號 (EMG) 被多個研究領域用作工具或信息來源。生物醫學信號的正確處理和濾波必須特別注意。EMG 從大腦通過脊髓傳遞到肌肉,負責控制運動。該信號具有隨機性,但在組織收縮的最初 200 毫秒內,可以識別個體希望執行的運動。它的一些應用包括運動員的身體評估、診斷肌肉問題和康復 [1]。
康復工程利用肌電圖(EMG)來創建智能假肢,人工手臂的控制通過殘肢信號進行[2]。然而,科學研究提出的解決方案與市售設備之間仍然存在差距。在臨床環境中獲得的結果與實際應用有很大差異。目前,商業產品不能被認為是穩健的,并且它們的控制并不完全自然[3],這導致了[4]用戶的高拒絕率。
模式識別算法經常被用于根據人們希望執行的動作來分類EMG信號。根據文獻,信號特征的提取和選擇可以改善分類過程,并且專注于特征工程的研究很常見[5]。提取非冗余特征并為給定的分類器選擇最合適的特征是費力的任務。因此,對具有自動特征提取和選擇的機器學習算法(如卷積神經網絡(CNN)[6])的研究已經變得流行,因為它們從過程中消除了這些步驟。然而,最近一項使用深度學習技術進行生物信號分類的研究[8]指出,由于此類信號的固有特性(尤其是噪聲和干擾),直接在原始信號上使用CNN是值得懷疑的。通過這種方式,預處理步驟可以緩解這個問題,并為模型提供更全面的穩定性。
本文提出了一種分類方法,該方法不是將原始EMG信號輸入CNN,而是輸入一組先前從信號中提取的特征,從而為分類器提供格式化的低維信息。所提出的模型分為兩個階段。首先,從原始信號中提取數據,以減輕系統負載,并提供一組具有代表性的特征,這些特征不易受到變異性和噪聲的影響。在第二階段,CNN網絡自動從先前的集合中提取最相關的特征,并利用其分類能力來區分運動類別。該方法測試了幾種排列方式,以找到一個理想的工作范圍,該范圍表達了訓練和準確性之間最佳的成本效益比。
研究人員已經在許多應用中使用 CNN,包括 EMG 信號分類并獲得高質量的結果。然而,他們沒有考慮到訓練時間的重要性,并且該指標經常達到很高的值 [7, 20]。在這項研究中,我們提出了一個模型,該模型呈現高質量的結果并且可以減輕網絡負載,從而實現效率和快速訓練。所提出的方法降低了系統輸入的維度,從而降低了其計算成本,從而實現了在線訓練。某些條件,如疲勞、壓力、溫度、濕度,甚至電極的位置,都會改變信號的特性,這將不是同質的。此外,在初步測試中,用原始 EMG 信號饋送 CNN,我們沒有獲得好的結果。這項工作的主要貢獻是:
- 在輸入 CNN 之前進行信號預處理:加速訓練并提高網絡準確性;
- 與BioPatRec集成:使網絡矩陣適應任何數據集。 這一步驟允許與該軟件的統計模塊集成,為我們提供了比較的基礎;
- 總體性能評估:此類網絡計算成本高昂,嵌入式設備可以受益于更輕量級的版本;
- 肌電信號模式識別的一般性討論。
2背景
模式識別模型可以分為三個步驟,如圖1所示:1) 信號采集、捕獲、采樣和處理;2) 特征提取和選擇;3) 分類。以下小節描述了用于執行該操作的技術——用一組特征而不是原始信號來饋送分類模型。有必要結合 CNN 和 BioPatRec。
A. 卷積神經網絡
CNN旨在學習輸入和輸出之間的關系,并將其知識存儲在其濾波器權重中[24]。第一層是卷積層,負責通過卷積的數學運算執行濾波。此操作的結果稱為“特征映射”。下一層負責歸一化,計算每個輸入通道的均值和方差。此步驟減少了訓練時間。ReLU(Rectified Linear Unit,修正線性單元)層執行閾值操作,其中小于零的值被賦值為零。全連接層結合了前一步驟學習到的特征,以識別正確的模式。最后,這個分類層根據互斥類別創建輸出標簽[26]。
Ortiz等人開發了一個用于創建康復策略的開源研究平臺,名為BioPatRec [9, 10]。它允許世界各地的研究人員擁有一個集中的研究環境。該軟件是模塊化的,包含許多分類算法和用于EMG處理的不同資源。這項工作將使用CNN網絡增加BioPatRec的功能,以自動調整算法輸入到所選數據集。
B. 特征工程
在人工智能領域,最能描述類之間邊界的特征集合始終是一個非常重要的議題[11, 12]。隨著機器學習技術的進步,為了消除特征提取步驟,涌現出能夠自動完成此任務的網絡。其他工作以通常的方式實現了用于EMG分類的此類網絡,即直接將原始信號輸入算法[7, 13, 20]。在本文中,我們提出了一種不同的方法。我們沒有提供原始信號(其是非平穩或非同質的),而是首先在時域和頻域中提取一組特征,然后將其輸入到CNN中。因此,作為分類器輸入的信息在數學上更有意義,并且更不易受到噪聲的影響。
肌電信號分類通常采用 LDA(線性判別分析)[1],這是一種簡單的數學方法,能夠提取最具區分性的特征。另一種經過充分研究的算法是 MLP(多層感知器)[14]。作者在 [7] 中進行了一項有趣的研究,使用 Python 和 TensorFlow 評估肌電信號(測試 CNN 網絡)。另一項研究 [13] 也實施了一種使用 CNN 的方法,并顯示出有希望的結果。最近的一項研究 [20] 采用原始信號來饋送 CNN,并在兩個數據集(Ninapro,[15])中獲得了 98.31% 和 68.98% 的準確率。
3材料與方法
該研究在一臺12核AMD Ryzen 5微處理器上進行了測試,該處理器配備16GB內存和250GB固態硬盤。BioPatRec在Manjaro Linux操作系統上運行。
在本文中,我們將提出的模型與 6 種通用分類器進行了比較。對于這些測試,使用了 6 個數據集 [9]。這些數據代表兩種類型的包容性數據:個體(10mov4ch 和 10mov4ch-2)和下肢運動(TMC、TBC 和 UMC),以及一種類型的排他性數據(同步)。它們之間的變化是設置,例如電極放置和其他 [9]。表 I 顯示了每組信號的記錄協議。圖 2 顯示了運動的組成及其各自的自由度。
每個數據集都有一個輸入和輸出大小,因此有必要對 CNN 進行矩陣調整。該工作以自動化的方式將 Matlab 的 CNN 網絡集成到 BioPatRec 中,而無需考慮數據集(具有特定格式)。濾波器的調整取決于輸入大小、特征數量和要預測的類別。開發者不需要為每種類型的輸入創建網絡,因為有一個調整矩陣可以適應所有配置。圖 III 顯示了與數據集相關的運動。
表 I 數據存儲庫

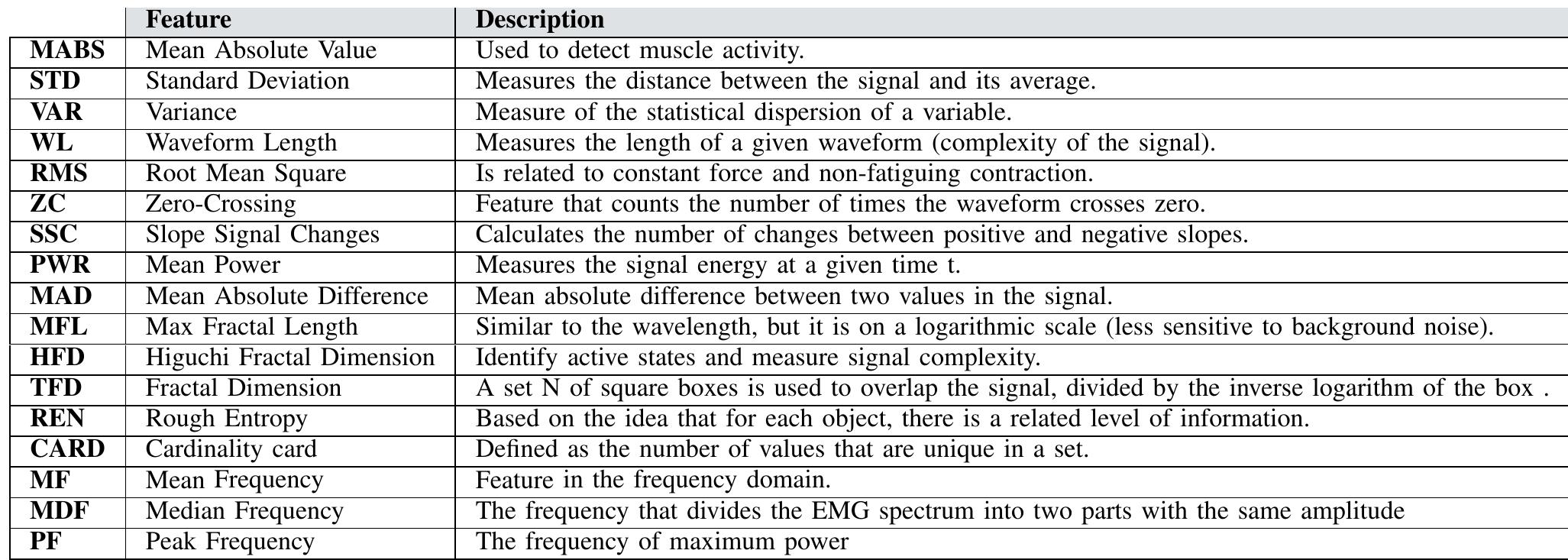
BioPatRec平臺對來自每組信號的數據執行了過濾和分割。每個窗口為200毫秒,重疊50毫秒。對于本研究,該方法采用了標準的BioPatRec過濾程序。特征提取的目的是突出重要信息,拒絕不相關的數據和噪聲。本研究中使用的時間-頻率特征總結在表II [16, 17, 18, 21]中。
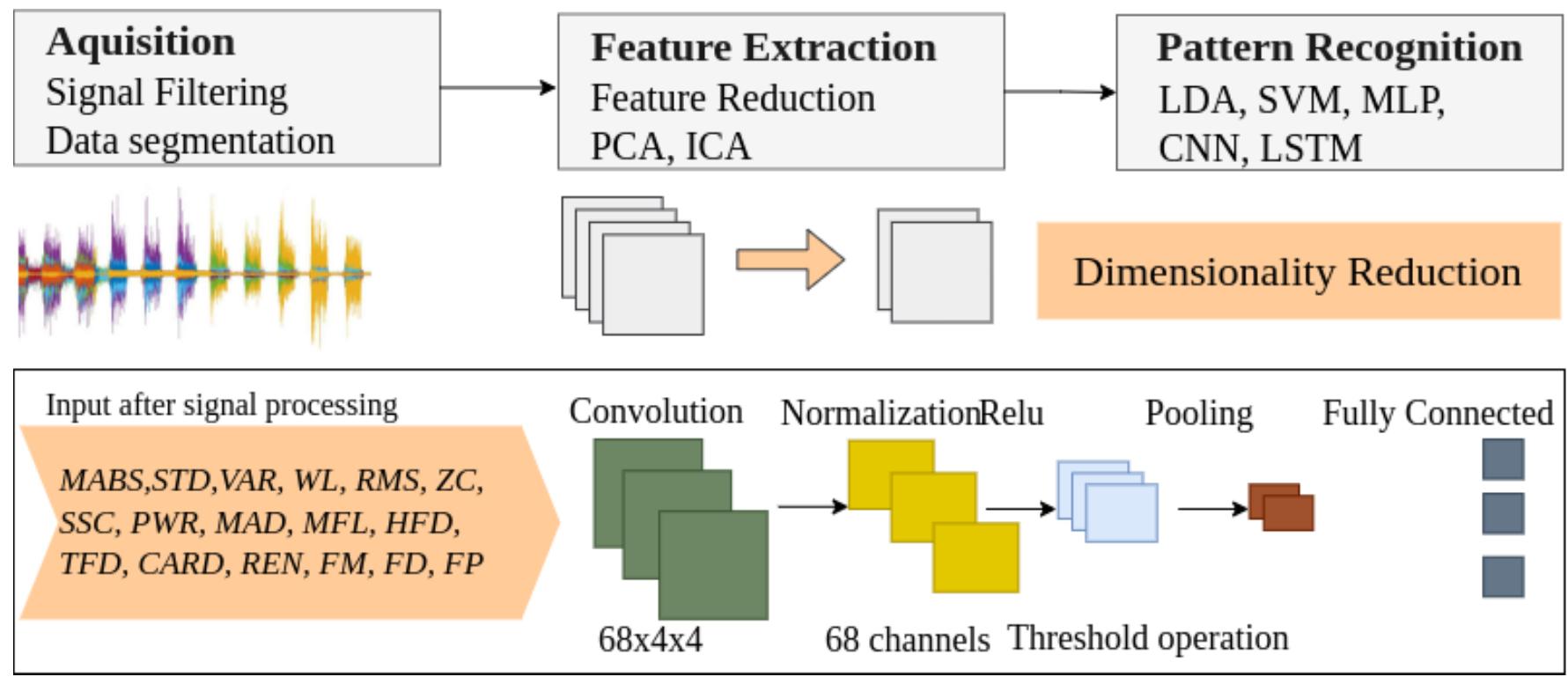
圖1. 對信號進行采樣后,需要進行濾波并將其分割成窗口。從窗口中提取特征,并以向量形式組織。CNN網絡的一般化,展示了卷積、歸一化、ReLu和池化層。直接使用原始信號而不進行特征預選擇的方法會受到噪聲和干擾的影響,這是由于波的性質和可變性造成的。
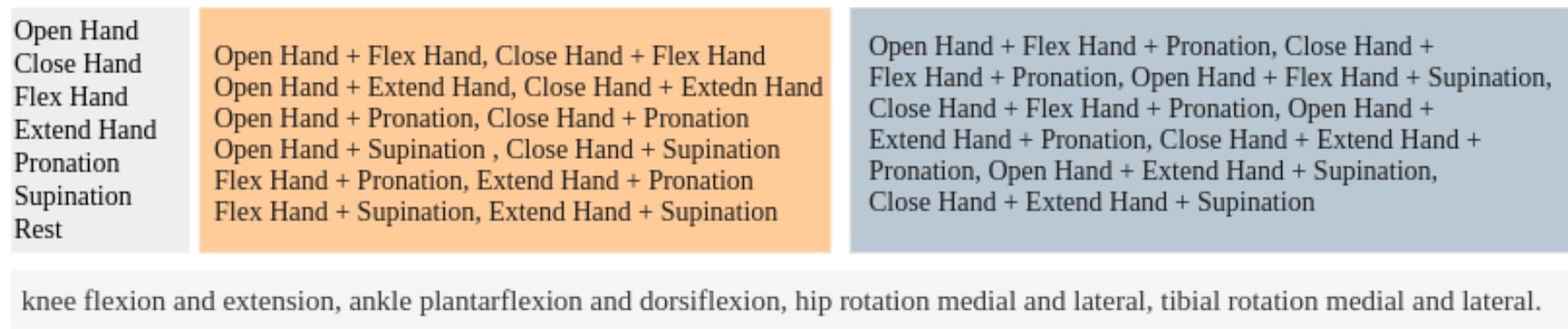
圖 2. 第一個框展示了具有 1 個自由度的運動。第二個框展示了具有 2 個自由度的組合。第三個四邊形展示了具有 3 個自由度的可能性。下面的矩形展示了下肢的運動。
A. CNN集成
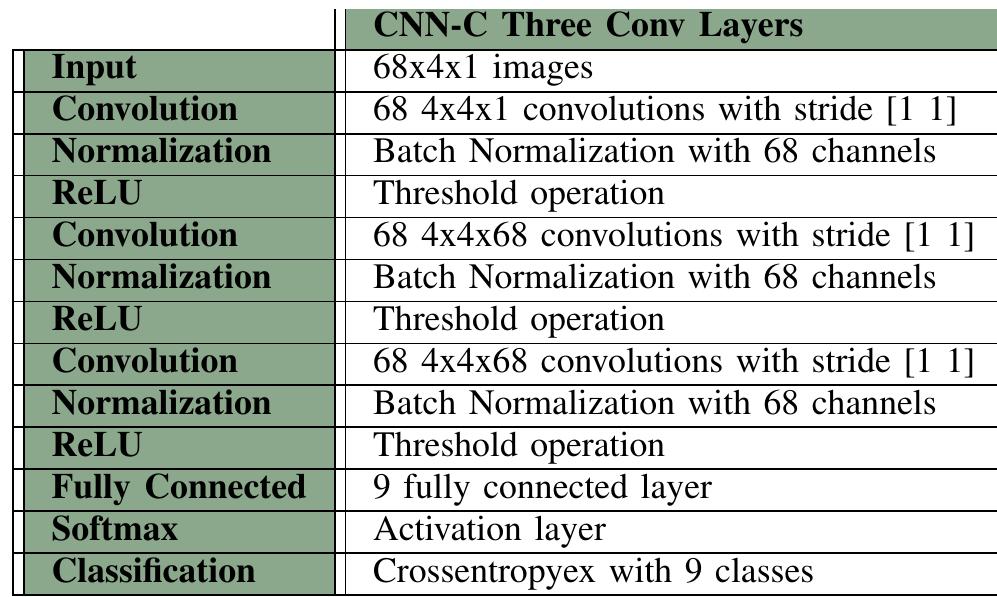
該研究將 CNN 算法與 BioPatRec 平臺相結合。有必要創建一個架構,使輸入向量的大小與第一個卷積層相匹配。由于每個數據集都有其采集協議,因此網絡輸入在信號之間不會是統一的。集合 SimultaneousForearm 是使用八個雙極氯化銀電極采集的,因此擬合矩陣會將十七個特征組織成一個長度為 136 (8x17) 的一維向量。該調查使用三種不同的架構進行了實驗:第一種只有一層卷積層 (CNN-A),第二種有兩層 (CNN-B),第三種有三層 (CNN-C)。可以直接在代碼中進行更改,用戶可以自由地提出不同的網絡。例如,表 III 總結了 CNN-C 網絡在由 Lower Limb UMC 集合饋送時的狀態。
調整超參數:為了找到網絡的最佳工作范圍,有必要調整一些參數。此步驟沒有通用規則,因此需要對多個值進行窮舉搜索。該研究使用了 Adam 訓練方法(自適應矩估計)。該技術允許自適應學習率,并使用一階和二階梯度矩估計來調整學習率。該研究使用的學習率為 0.003,最大 epoch 數為 20,衰減因子等于 0.9。對于批次,它代表在每次迭代中呈現給網絡的信息塊 [25],我們選擇了默認大小 128。正如 [13] 指出的那樣,此屬性的小值通常會導致較長的訓練時間。使用的損失函數是交叉熵。對于參數的選擇,使用了網格搜索掃描協議。
統計分析:該研究考慮了兩個用于統計分析的指標。第一個是準確率,它衡量算法區分不同運動類別的能力。評估的第二個標準是在訓練網絡上花費的時間。測試時間在分類器之間無關緊要,因為在所有情況下,它們都很廉價,并且不限制假肢的任何要求。訓練時間在計算上是昂貴的,并且在實踐中,會使校準和重新校準假肢變得困難。因此,訓練時間是比預測時間更相關的指標。
所有測試在數據采集和算法上都遵循相同的協議。所有分析的患者都重復實驗10次,獲得的值用于計算一組測試的平均值。使用配對t檢驗來比較兩個接近的結果,以驗證獲得的值是否可以被認為在統計學上相等(p < 0.05)。為了進行比較,還測試了其他四個分類器:多層感知器(MLP)、線性判別分析(LDA)、自組織映射(SOM)和調節反饋網絡(RFN)。
表二 特征
表三 網絡架構 C
4結果
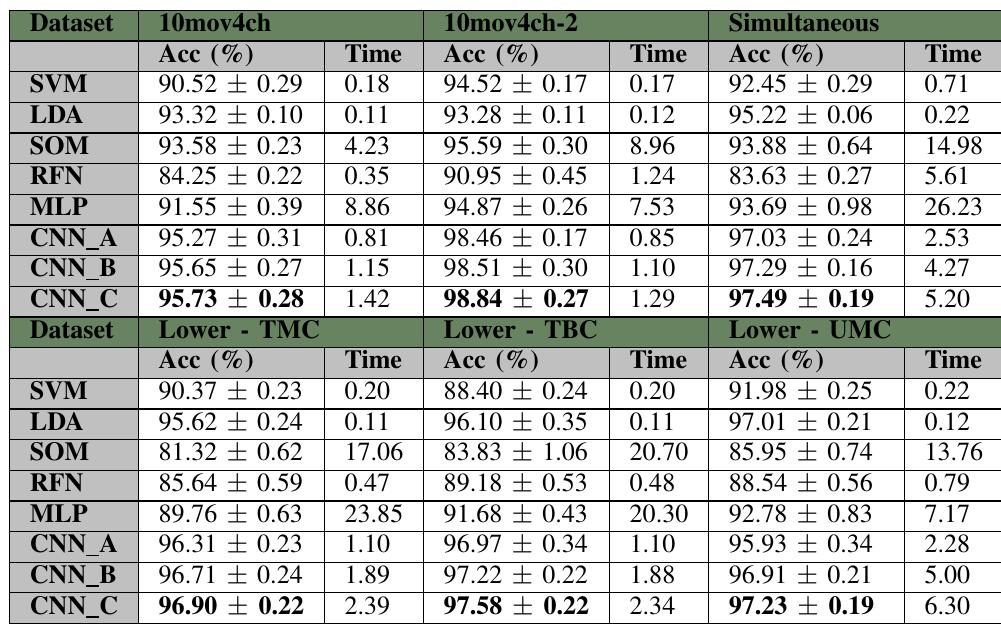
個體動作:定量結果見表四。在代表個體動作的兩個數據集中,CNN-C均取得了較高的準確率(95.73%和98.84%),超過了所有其他評估方法。該方法使用了CNN-C網絡和SOM算法之間的配對t檢驗,以驗證所提出的概念與最佳評估算法之間是否存在統計差異。t檢驗結果保證了兩個分類器之間存在統計差異:CNNC優于其他通用算法。關于訓練時間,CNN-C在第一組中平均花費1.14秒,在第二組樣本中平均花費1.29秒。雖然沒有呈現最佳結果(LDA - 0.11秒),但CNN算法的性能具有競爭力。
同步運動:兩種CNN模型在此測試中均獲得了高準確率:是本研究中的最佳結果。CNNC獲得了97.49%的平均準確率,而LDA方法獲得的平均準確率為95.22%。在這兩種情況下,都存在統計學差異(p < 0.05)。CNN-C獲得的訓練時間為5.20秒,并非本研究的最佳時間:LDA分類器僅用0.12秒即可完成訓練。
下肢:在第一組(TMC)中,CNN-C獲得了研究的最佳結果,達到了96.90%的準確率,其次是CNN-B分類器,準確率為96.65%。在分析時間時,CNN-C獲得了良好的數值,分別花費了1.42秒。最佳結果再次來自LDA網絡,僅用時0.11秒。
分析第二組信號(TBC),CNN混合模型表現出最佳數值,配置C、B和A的平均精度分別為97.58%、97.22%和96.97%。本研究中測試的算法的平均訓練時間分別為2.34、1.88和1.10秒。LDA獲得了最佳時間,平均時間為0.11。
CNN-C 在 UMC 配置中呈現最佳結果 (97.23%)。第二好的值是 LDA (97.01%),考慮到統計差異 (p < 0.05)。時間分析沒有呈現關于其他實驗的顯著變化:LDA 算法是最好的(訓練耗時 0.11 秒),CNN 網絡耗時不到 7 秒。
5討論
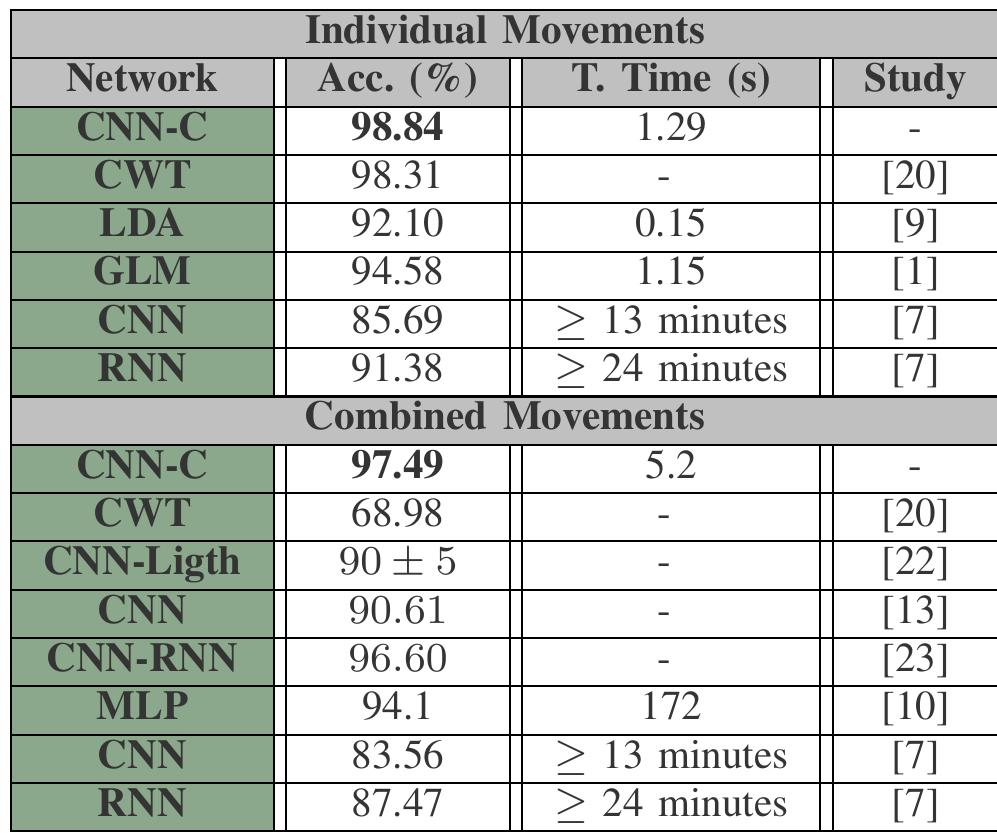
表V顯示了所提出的模型與其他研究的比較。最近的工作[22]使用了一個輕量級卷積神經網絡,并達到了90±5的準確率。作者沒有考慮訓練時間,而是考慮了系統的總延遲。我們的工作不關注測試時間的測量,因為在所有情況下,測試時間都很短(在CNN情況下為0.0012秒)。另一項最近的工作[23]使用了一個CNN-RNN用于EMG信號的情況,并獲得了96.60%的準確率。這些工作表明,在EMG信號的情況下,存在使用深度學習技術的趨勢,因為這種網絡可以提供更強大的解決方案。我們的方法提供了具有競爭力的結果,且計算成本可接受,這支持了在嵌入式設備中使用此類算法。
表四 實驗的總體結果
表五 對比表
在最初的實驗中,我們使用了一種直接將原始信號饋送到網絡的方法。與其他模型相比,結果并不令人滿意。對此的一種假設是,這些類別有很多相似之處,這使得分類過程變得困難。一個動作和另一個動作之間的差異是細微的,這可能增加了分類過程的復雜性。這就是特征提取過程有意義的原因:除了減少可變性之外,它還向網絡傳遞信息,從而增加了類之間的分離邊界。圖3顯示了4個不同信號樣本之間的相似性。與例如代表行人或汽車的圖像具有明顯的差異不同,肌肉信號可能具有非常相似的特征。
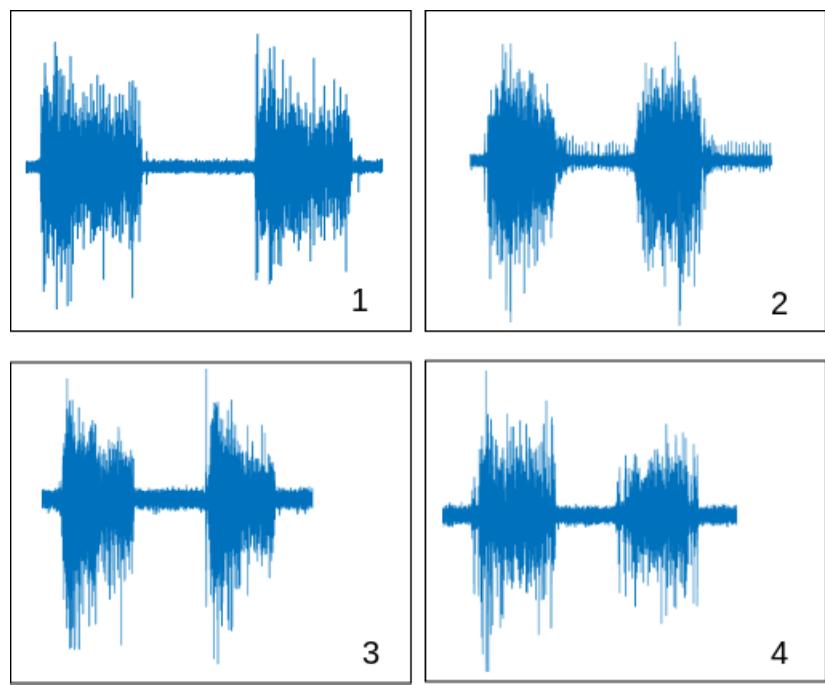
圖3. 4種不同運動重復兩次之間的相似性。
最后,我們可以說深度架構具有更大的潛力。我們的13層CNN-C網絡在所有測試中都提供了最佳的準確性,并且訓練時間具有競爭力。此外,在我們其他的作品[21]中,我們使用了這里介紹的思想來為整個人群訓練一個通用的神經網絡,這加強了該方法的潛力。
6結論
本文提出了一種模型,該模型從肌電信號中提取時域和頻域的數據特征,并將其用作卷積神經網絡的輸入。卷積神經網絡具有很高的分類能力,并且能夠執行自動特征提取。因此,這種類型的網絡被用于原始信號。然而,由于肌電信號固有的變異性和非平穩性,我們已經證明,對波形進行預處理并向網絡提供代表性的數據特征可以提高分類性能并節省處理時間。此外,由于不同的運動會產生非常相似的信號,因此使用原始肌電信號進行分類的過程變得更加困難。
所提出的模型使用六個不同的數據集進行評估,并與其他流行的分類器進行比較,在所有測試組中均超過了它們。此外,它還與其他最先進的模型進行了比較,并獲得了比所有模型更好的性能指標,同時保持了更低的訓練時間。目前的方法適用于未來在具有硬件限制的系統上進行部署,并允許對設備進行重新校準。結果令人鼓舞,并可能提高對智能假肢使用的依從性。該分類器已包含在 BioPatRec 分類模塊中,并且可以在互聯網上免費獲得 [19]。


















--鏈表01)
