背景與核心思想簡介
在LLM的長上下文推理中,KV Cache成為影響速度和內存的關鍵因素。每生成一個新token,模型需要對所有先前token的鍵(Key)和值(Value)向量執行自注意力計算。傳統方法會將所有過去的K/V向量保存在GPU上,并在每步將查詢向量與整個K緩存做點積計算,然后加權累加對應的V向量。這種全量 KV 緩存方案有兩個主要問題:
- 內存占用大:隨著序列長度增長,KV緩存的大小線性擴張。比如支持32K上下文的LLM,每一層每個注意力頭需要存儲3.2萬×頭維度的Key和Value,模型層數多時總緩存可達數GB,占滿GPU顯存,限制了批量大小。
- 計算吞吐低:每生成一個token都要與先前所有token的Key做注意力計算,時間復雜度隨上下文長度線性增加(長上下文場景下接近O(n2)O(n^2)O(n2)總復雜度),導致生成速度顯著下降。
一些現有方法嘗試緩解上述問題,例如動態稀疏注意力(僅保留部分重要的K/V參與計算)或者將KV緩存整體轉移到CPU(節省GPU顯存)。但前者往往難以充分降低內存占用,后者則因為每步需要通過PCIe來回傳輸大量數據而延遲高。
ShadowKV(“影子KV”)是字節跳動提出的一種高吞吐長上下文推理機制,其核心思想是:將KV緩存拆分成“小影子”和“大本營”,把低秩表示的Key緩存保留在GPU上(影子部分),而完整的Value緩存下放到CPU內存(大本營部分),并輔以一種準確的KV選擇策略,僅在需要時按需重建極少量的KV對供注意力使用。通過這種機制,ShadowKV在保持模型輸出幾乎無損的前提下,大幅削減了GPU顯存占用,并提高每步解碼的并行效率。簡而言之,ShadowKV讓大部分KV對“隱身”在影子中,只在必要時顯現,從而實現更高的推理吞吐量。
ShadowKV 的計算流程詳解
ShadowKV將推理過程分為兩個階段:預填充(Pre-filling)和解碼(Decoding)。下面分別介紹這兩個階段的具體計算步驟,涉及的張量形狀,以及注意力過程中各操作細節。
預填充階段:緩存壓縮與建立 “影子” KV
預填充階段在模型處理完初始長上下文(如提示或對話歷史)后進行,目的是對整段上下文的KV緩存進行壓縮和篩選,為后續高效解碼做好準備。設批量大小為 BBB,序列總長度為 LLL,注意力頭數量為 HHH,每個注意力頭維度為 DDD(即隱藏層尺寸=H×D=H \times D=H×D)。對于支持多查詢頭(Multi-Query Attention)的模型,這里我們用 H_kH\_kH_k 表示Key/Value公用的頭數(如Llama等模型通常H_k=HH\_k = HH_k=H)。
1. 將 Value 全量緩存至CPU:模型前向計算得到初始上下文的Key、Value張量后,ShadowKV首先將所有層的 Value 緩存復制到CPU內存中保存。這樣GPU上就不再保留大體積的V緩存,從源頭上緩解了顯存壓力。設某一層輸出的Value張量形狀為 [B, H_k, L, D],則在CPU中維護對應大小的 v_cache_cpu 緩存數組,用于存放該層所有批次、所有KV頭的Value向量。
2. 劃分最近局部塊(Local Chunks):考慮到最新的若干個token往往對后續生成貢獻較大,ShadowKV將上下文序列最后的一小段保留為“局部全量緩存”。具體地,設定每層一個 chunk_size 超參數(例如8),以及 local_chunk 數量(例如4),表示保留末尾444個chunk的token。在示例中,末尾局部片段長度為 Llocal=local_chunk?chunk_size=4?8=32L_{\mathrm{local}}=\mathrm{local\_chunk}\cdot\mathrm{chunk\_size}=4\cdot8=32Llocal?=local_chunk?chunk_size=4?8=32
(若LLL不能整除8,則包括余下的不滿一個chunk的部分)。這最后的約32個token的Key/Value將完整保存在GPU上,形成高頻近鄰緩存。對應地,我們在GPU上為每層分配 k_cache_buffer 和 v_cache_buffer 數組,用于存放GPU駐留的K/V塊。首先將末尾 LtextlocalL_{text{local}}Ltextlocal? 的Key、Value拷貝到該buffer的開頭位置。
3. 按固定大小分塊剩余上下文:將除最后局部塊之外的前面長上下文劃分為若干長度為 chunk_size 的等長塊。塊數可計算為:N_chunk=?L/chunk_size??local_chunkN\_{\text{chunk}} = \lfloor L / \text{chunk\_size} \rfloor - \text{local\_chunk}N_chunk=?L/chunk_size??local_chunk(例如L=131072L=131072L=131072時,Nchunk=16384?4=16380N_{\text{chunk}} = 16384 - 4 = 16380Nchunk?=16384?4=16380)。對于每一塊,我們計算該塊中所有Key向量的平均值,得到一個代表此塊的Landmark向量。經過位置編碼(RoPE)處理后的Key張量形狀為 [B,Hk,L,D][B, H_k, L, D][B,Hk?,L,D],將其視作 [B,Hk,Ntextchunk,textchunksize,D][B, H_k, N_{text{chunk}}, text{chunk_size}, D][B,Hk?,Ntextchunk?,textchunks?ize,D] 的5維張量,則對倒數第二維求平均可得 Landmark 張量形狀 [B,Hk,Ntextchunk,D][B, H_k, N_{text{chunk}}, D][B,Hk?,Ntextchunk?,D],即每個KV頭每塊一個代表向量。這些Landmark保留了各塊在Key空間的大致方向信息。
4. 檢測并保留離群Token(Outliers):雖然Landmark代表了塊的整體特征,但塊內某些離群token可能與塊均值差異較大,若僅用均值代表會損失它們的注意力信息。為此,ShadowKV對每個塊計算各token與Landmark的余弦相似度,找出相似度最低的那個token作為該塊的“最異”token,并記錄其相似度。然后在所有塊中選出相似度最低的若干塊,認為這些塊存在重要的離群Key。設超參數 outlier_chunk 表示選取的離群塊數量(如48),ShadowKV會挑選出最不代表性的48個塊。對于這些塊內的所有token,ShadowKV將它們視為outlier token并完整保留它們的Key/Value在GPU緩存中。具體來說,從前面計算的Key張量 [B,Hk,Ntextchunk,textchunksize,D][B, H_k, N_{text{chunk}}, text{chunk_size}, D][B,Hk?,Ntextchunk?,textchunks?ize,D] 中,按照選出的塊索引提取對應的所有Key向量,將它們扁平為形狀 [B,Hk,textoutlierchunk×textchunksize,D][B, H_k, text{outlier_chunk} \times text{chunk_size}, D][B,Hk?,textoutlierc?hunk×textchunks?ize,D]后,復制到GPU的 k_cache_buffer 緊接局部塊位置之后。同樣地,這些token的Value也提取并復制到 v_cache_buffer 相應位置。經過這一步,GPU上緩存了:末尾局部L_localL\_{\text{local}}L_local token的K/V,以及484848個離群塊(共48×8=38448\times 8 = 38448×8=384個token)的K/V。相比全長LLL而言,這部分token數量很小,但包含了序列中難以被均值代表的關鍵信息。
5. 構建Landmark “影子緩存”:將除離群塊以外的其余塊的Landmark保存下來,作為后續注意力查詢的影子Key緩存。具體實現是:過濾掉已選為離群的塊索引,將剩余塊的Landmark向量及其對應的塊索引列表存入k_landmark和k_landmark_idx張量中。此時,GPU上k_landmark形狀為 [B,Hk,Ntextchunk?textoutlierchunk,D][B, H_k, N_{text{chunk}} - text{outlier_chunk}, D][B,Hk?,Ntextchunk??textoutlierc?hunk,D],包含每個未標記為離群的塊一個代表Key向量;k_landmark_idx記錄了這些Landmark對應的原始塊編號,形狀為 [B,Hk,Ntextchunk?textoutlierchunk][B, H_k, N_{text{chunk}} - text{outlier_chunk}][B,Hk?,Ntextchunk??textoutlierc?hunk]。
6. 低秩分解壓縮 Key(可選):為進一步壓縮存儲和加速計算,ShadowKV利用鍵矩陣的低秩特性對所有Key進行一次SVD分解。研究發現,未經過RoPE位置編碼的Key矩陣在長序列下秩值很低。ShadowKV在預填充階段對整個序列的Key緩存(特別是經過RoPE后的Key)進行SVD,提取出秩為rrr的近似。SVD會生成左右奇異向量UUU和VVV以及奇異值SSS;實現中將SSS和VVV預先相乘簡化存儲。對于每層,我們維護U和SV兩個張量:U[layer]形狀為 [B, L, r],存儲全序列長度LLL×秩rrr的矩陣;SV[layer]形狀為 [B,Hk,r,D][B, H_k, r, D][B,Hk?,r,D],存儲秩rrr×Key維度DDD的信息(這里HkH_kHk?維度用于區分不同KV頭或頭組)。這兩個張量常駐GPU,提供了重構任意Key向量的“字典”。低秩Key緩存與Landmark/Outlier互為補充:Landmark用于粗粒度檢索,低秩U,S,VU,S,VU,S,V用于精確重建需要的Key值。
經過以上步驟,預填充階段完成:此時GPU上僅保留了低秩壓縮的Key表示(U和SV)、Landmark代表Key集合以及少量原始Key/Value(局部+離群token),總共占用的顯存遠小于完整緩存。而完整的Value緩存由于體積龐大,已完全移至CPU內存。這樣一來,GPU上的KV緩存被“瘦身”為一個影子:包含摘要信息和關鍵細節,準備支持后續高速的解碼計算。
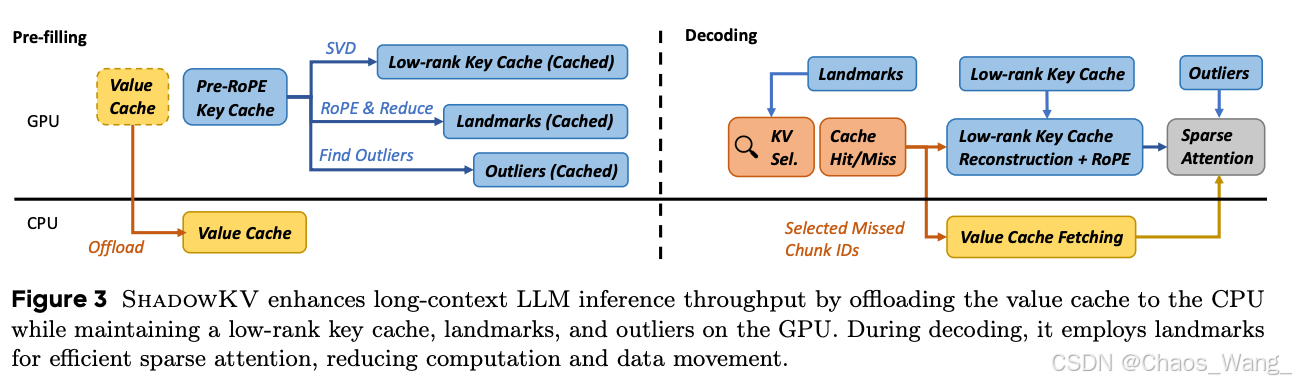
ShadowKV 預填充(左)和解碼(右)階段的機制示意圖。在預填充階段,Value緩存(黃色部分)被整體下放至CPU,Key緩存(藍色部分)經SVD低秩壓縮并結合RoPE位置編碼提取出Landmark和Outlier,形成存留GPU的“影子”KV緩存。解碼階段,通過Landmark進行高效的稀疏注意力查詢,僅針對Cache未命中的部分塊從CPU取回對應Value,并借助低秩Key表示重建所需Key向量,在GPU上完成注意力計算。
解碼階段:按需稀疏重建與注意力計算
在解碼階段,模型開始基于先前緩存生成新token。ShadowKV的解碼與標準自注意力不同之處在于引入了兩級的稀疏查詢與重建機制,以最小代價獲取所需的KV對。下面以單個新生成token為例(查詢長度為1)說明每層解碼計算流程:
1. 粗粒度塊級注意力:當有新的查詢向量 QQQ (形狀 [B, H, 1, D])需要與過去上下文計算注意力時,ShadowKV首先利用GPU上的Landmark計算塊級別的注意力分布。具體步驟為:將查詢向量與每個Landmark Key做點積,得到每個塊對查詢的相關性分數。因為某些模型存在多個查詢頭共享同一Key的情況,實現中按KV頭組數 GGG 對注意力頭分組處理,QQQreshape為 [B,Hk,G,1,D][B, H_k, G, 1, D][B,Hk?,G,1,D],Landmark reshape為 [B,Hk,1,Nchunk(remain),D][B, H_k, 1, N_{\text{chunk(remain)}}, D][B,Hk?,1,Nchunk(remain)?,D](在計算時會自動廣播組維度)。通過 Einsum 矩陣乘得到形狀 [B,Hk,G,1,Nchunk(remain)][B, H_k, G, 1, N_{\text{chunk(remain)}}][B,Hk?,G,1,Nchunk(remain)?] 的分數張量,隨后對組維度取平均或最大(等價于不同注意力頭組結果的融合,代碼中對組維度應用了softmax再max等處理),最終得到 [B,Hk,Nchunk(remain)][B, H_k, N_{\text{chunk(remain)}}][B,Hk?,Nchunk(remain)?] 大小的每個塊的注意力權重。接下來對這些權重做一次softmax歸一化(在保證數值穩定的同時通常以更高精度計算softmax)。
2. 精細選擇相關塊:根據得到的塊級注意力分布,ShadowKV從中選出得分最高的 KKK 個塊作為“與當前查詢最相關”的塊集合。這里 K=select_setsK = \text{select\_sets}K=select_sets 是根據設定的sparse_budget(GPU稀疏KV預算)決定的塊數,例如sparse_budget=2048且chunk_size=8則K=2048/8=256K=2048/8=256K=2048/8=256個塊。選出的塊索引利用之前保存的k_landmark_idx映射回原始塊編號集合,得到形如 [B, H_k, K] 的張量。這些塊將被視作需重點保留的記憶:它們涵蓋了對新查詢有主要影響的約 K×chunk_sizeK \times \text{chunk\_size}K×chunk_size 個歷史token。
3. 從CPU取回選中塊的Value:對于上一步選出的相關塊,我們需要確保其對應token的Value都在GPU上,以備計算注意力輸出。如果其中一些塊恰好是先前已緩存為Outlier或本地塊(局部塊),那么它們的Key/Value已經在GPU緩沖中,可直接使用(Cache Hit)。其余大部分塊此前僅以Landmark代表,沒有完整緩存(Cache Miss)。對于這些Miss的塊,ShadowKV現在按塊批量從CPU提取它們的Value緩存:根據塊索引計算出每個塊起始的token位置范圍,將對應的Value片段(大小為chunk_size的連續向量段)從v_cache_cpu復制到GPU的v_cache_buffer剩余空位中(預填充時已為sparse_budget預留了這一區域空間)。由于這些選中的Value總長度不超過sparse_budget(如2048個token),復制開銷相對較小。更重要的是,ShadowKV實現了一個高效的gather_copy批量拷貝CUDA kernel,將所有需傳輸的數據按連續內存段一次搬運,極大提高了PCIe帶寬利用率。
4. 重建選中塊的Key:對于Miss的相關塊,還需要獲得它們對應token的Key向量以計算注意力分數。然而這些Key并未顯式存儲在GPU或CPU內(GPU上只有Landmark代表,CPU上已不保存Key以節省空間)。ShadowKV利用預填充階段準備的低秩Key表示(U和SV)來按需重建所需的Key。具體而言,ShadowKV的自定義CUDA kernel會讀取position_ids(所選token的全局位置列表,長度K×chunk_sizeK \times \text{chunk\_size}K×chunk_size)以及低秩矩陣U、SV,直接在GPU上計算出這些位置對應的Key向量。此外,還會將RoPE位置編碼應用于這些重建的Key,以確保它們與查詢Q處于相同的旋轉相位。這個過程融合了“從低秩基重建+位置旋轉”以及必要的張量變換操作,在GPU上高效完成,而無需恢復完整的Key緩存。
5. 稀疏注意力計算:現在,GPU上的 k_cache_buffer 已包含了當前查詢所需的全部Key向量,包括先前一直存留的局部+離群Key,以及剛剛重建獲取的其他相關Key,總計數量約為 local+(outlier_chunk×chunk_size)+K×chunk_size\text{local}+(\text{outlier\_chunk}\times\text{chunk\_size})+K\times\text{chunk\_size}local+(outlier_chunk×chunk_size)+K×chunk_size。以典型參數為例,這可能是 32+384+2048≈246432 + 384 + 2048 \approx 246432+384+2048≈2464 個Key,遠小于完整的L=32000+L=32000+L=32000+。同樣,v_cache_buffer中相應保有上述Key對應的Value向量。接下來,ShadowKV對查詢Q與這數千個Key計算稀疏注意力:進行Q?KTQ \cdot K^TQ?KT點積得到注意力分數(只針對選定的小集合),然后softmax歸一化,之后用權重與Value加權求和得到輸出。由于K/V數量大幅減少,注意力乘加運算的開銷也顯著降低。此外,這一步計算也可以與前述步驟部分融合以進一步優化(例如ShadowKV將低秩重建Key和點積操作組合在同一CUDA kernel中完成)。最終得到的注意力輸出與傳統完整計算得到的結果幾乎相同——因為ShadowKV確保了對注意力貢獻最大的那些Key/Value都在這個稀疏集合中。
6. 更新緩存狀態:在生成出新token的輸出后,ShadowKV會將該新token的Key和Value追加到緩存中。對于Value,新token的Value張量會追加存儲到CPU端的v_cache_cpu對應位置;對于Key,新token的Key向量會存入GPU的k_cache_buffer末尾區域(屬于最新的局部塊一部分)。kv_offset計數會隨生成token的數量遞增,以反映當前緩存序列長度。如果積累的新生成token數達到一個chunk_size塊的長度,ShadowKV可能會將它們標記為新的塊并適時更新Landmark/Outlier信息(視實現策略決定,當前版本主要在預填充時一次性確定Landmark/Outlier)。由于新token通常逐個生成,附加的計算和數據轉移量很小,不會顯著影響整體吞吐。經過以上步驟,模型即可將新token送入下一層繼續計算,并迭代進行下一個token的解碼。
通過上述“Landmark 引導 + 按需重建”流程,ShadowKV避免了每步對全部歷史K/V的重復計算和搬移,僅用極少的候選集合就重構出了接近完整注意力的信息。這種分段式注意力重計算與KV更新策略,大大降低了長上下文解碼的平均計算復雜度和內存帶寬開銷,帶來了顯著的速度提升。
與傳統 KV 緩存機制的對比
相比傳統的KV緩存機制,ShadowKV在存儲開銷和計算效率上都引入了重要的改進:
-
顯存占用:傳統方案需要在GPU保留每一層、每個注意力頭、每個歷史token的K和V向量,空間復雜度~O(L×H×D)\sim O(L \times H \times D)~O(L×H×D),這對長序列非常不友好。而ShadowKV將V全部移出GPU,僅保留壓縮后的Key表示和少量token的Key副本。以實際數據為例,ShadowKV在支持12.2萬長度時,可將KV緩存的GPU占用減少超過6倍!這直接使得可支持的批量大小提升:以前為避免顯存溢出可能每次只能推理少數序列,而ShadowKV騰出的空間允許一次處理更多序列,實現最高6倍的批量增幅。更高的批量在服務場景中轉化為更高的吞吐量。
-
注意力計算成本:傳統自注意力在解碼時對每個新token都要與LLL個Key做乘法累加,時間復雜度線性隨LLL增長,導致長上下文下單token生成延遲顯著增大。ShadowKV通過兩級篩選,將每步參與計算的Key數量削減到~\sim~幾千(與
sparse_budget有關,是LLL的固定小比例)。雖然在每步計算前增加了一些篩選和數據拷貝開銷,但由于選擇集合很小,總體計算量近似降低為原來的(sparse_budget+overhead)/L(\text{sparse\_budget}+ \text{overhead})/L(sparse_budget+overhead)/L比例,對長序列而言這個比例非常低。例如在L=122L=122L=122K時,sparse_budget=2K意味著只需約1.6%的Key參與最終計算。實測結果表明,ShadowKV在32K甚至更長上下文下的單步計算延遲遠低于全量注意力,從而大幅提高了生成吞吐。 -
數據傳輸效率:一種簡單的思路是將全部KV緩存移至CPU,每步把所有需要的K/V取回GPU用,再扔掉。雖然省顯存,但這樣每生成一個token都要搬運O(L)O(L)O(L)的數據,PCIe帶寬成為瓶頸,反而可能使速度極慢。ShadowKV聰明地只在需要時搬運極小部分數據:Value只搬運選中的那2048個token左右,Key則通過數學重建避免了顯式搬運。這種極小化的數據傳輸,結合批量連續拷貝等優化手段,使得ShadowKV即使在PCIe受限的環境下依然高效。另外,GPU上的低秩Key和Landmark也支持并行處理:Landmark注意力的計算復雜度O(N_chunk)O(N\_{\text{chunk}})O(N_chunk)約為原始LLL的1/chunk_size1/\text{chunk\_size}1/chunk_size(如1/8),其Softmax等操作開銷相對可以忽略。總的來說,ShadowKV將原本分散的訪存和計算集中為少數幾次大塊操作與矩陣乘法,使GPU硬件的吞吐潛力得到更充分發揮。
-
輸出質量保持:稀疏/壓縮方法常面臨準確率下降的問題,而ShadowKV通過合理選擇Landmark、補充Outlier并動態調整選取策略,保證了幾乎零精度損失。實驗顯示,無論是問答、代碼還是長文理解等任務,ShadowKV與完整注意力的輸出一致性極高。這意味著研究者和工程師在使用ShadowKV加速時,無需犧牲模型效果。
綜上,ShadowKV通過在GPU維護“影子”KV緩存并利用精細的選擇策略,實現了更小的存儲、更快的計算和幾乎不變的性能,為長上下文LLM的實際部署提供了一種高效方案。
KV_Cache 類源碼解析(傳統緩存實現)
為了更清楚地理解ShadowKV的特殊之處,我們來看ShadowKV倉庫中提供的一個基準實現類——KV_Cache。這個類實現了傳統的全量KV緩存邏輯,用于對比或在不啟用Shadow機制時使用。下面附上KV_Cache類的代碼,并逐行添加中文注釋解釋其結構、成員變量含義和主要方法的執行邏輯:
class KV_Cache:"""Full Attention"""def __init__(self, config :object,batch_size :int = 1,max_length :int = 32*1024, device :str = 'cuda:0',dtype = torch.bfloat16) -> None:# 初始化 KV 緩存類,設定配置、批次大小、最大支持長度、設備和數據類型(默認為 BF16)self.config = configself.max_length = max_lengthself.device = deviceself.dtype = dtype# 分配用于存儲 Key 緩存的張量 (保存在CPU上),形狀: [層數, batch_size, KV頭數, max_length, 頭維度]self.k_cache = torch.zeros(config.num_hidden_layers,batch_size,config.num_key_value_heads,max_length,config.hidden_size // config.num_attention_heads,device='cpu',dtype=self.dtype)# 分配用于存儲 Value 緩存的張量 (同樣在CPU上),形狀與 k_cache 相同self.v_cache = torch.zeros(config.num_hidden_layers,batch_size,config.num_key_value_heads,max_length,config.hidden_size // config.num_attention_heads,device='cpu',dtype=self.dtype)# 保存層數和初始化偏移self.num_layers = config.num_hidden_layersself.kv_offset = 0 # 當前已經緩存的序列長度偏移(初始為0)# 批次預填充記錄self.prefilled_batch = 0 # 已經預填充完成的 batch 數計數self.batch_size = batch_sizedef update_kv_cache(self, new_k_cache :torch.Tensor,new_v_cache :torch.Tensor,layer_idx :int):# 將某層的新 Key/Value 張量添加到緩存中。 # new_k_cache, new_v_cache 形狀: [bsz, KV頭數, incoming, 頭維度], incoming為新加入的token數bsz, _, incoming, _ = new_v_cache.shape # 提取當前更新的批大小和新token長度if bsz == self.batch_size:self.prefilled_batch = 0 # 如果本次更新的批大小等于總batch_size,說明開始處理新一批序列,將prefilled計數清0# 將新Key復制到對應層的緩存位置:# 在第 layer_idx 層,針對本批次(prefilled_batch 起始位置),將緩存張量從 kv_offset 開始連續 incoming 長度的區域填入 new_k_cacheself.k_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, self.kv_offset:self.kv_offset + incoming].copy_(new_k_cache)# 將新Value復制到緩存self.v_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, self.kv_offset:self.kv_offset + incoming].copy_(new_v_cache)# 獲取當前批次在該層的完整Key/Value緩存切片(從序列開頭到最新添加位置)key = self.k_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, :self.kv_offset + incoming]value = self.v_cache[layer_idx][self.prefilled_batch:self.prefilled_batch + bsz, :, :self.kv_offset + incoming]if incoming > 1: # 若本次添加的incoming長度超過1,表示在進行預填充(而非生成單token)key = key.to(self.device) # 則將這一整段Key緩存提前轉移到GPU,方便后續注意力計算value = value.to(self.device)# 如果到達最后一層:if layer_idx == self.num_layers - 1:# 更新已處理的批計數self.prefilled_batch += bsz# 若該批次所有層均已填充完(prefilled_batch達到了batch_size)if self.prefilled_batch == self.batch_size:# 則整體緩存偏移kv_offset增加incoming長度,表示序列累積長度擴張self.kv_offset += incoming# 返回當前層最新的Key和Value張量(并確保在GPU上)return key.to(self.device), value.to(self.device)def print_stats(self):# 打印當前KV緩存狀態,包括最大長度、數據類型和已緩存長度print(f"KVCache | max_length {self.max_length} | dtype {self.dtype} | cached {self.kv_offset}")def H2D(self):# Host to Device:將緩存從CPU轉移到GPU的方法(需要先清理顯存,防止占用過多)gc.collect()torch.cuda.empty_cache()torch.cuda.synchronize()self.k_cache = self.k_cache.to(self.device) # 將Key緩存tensor搬到GPUself.v_cache = self.v_cache.to(self.device) # 將Value緩存tensor搬到GPUdef clear(self):# 清空緩存索引(不實際釋放tensor內存,只重置計數)self.kv_offset = 0self.prefilled_batch = 0def get_kv_len(self):# 獲取當前緩存的總長度(已經存儲的token數量)return self.kv_offset
上面的代碼展示了傳統KV緩存的工作原理:KV_Cache在初始化時為每層分配足夠長度的張量來容納所有Key/Value,并采用kv_offset追蹤當前存儲到的位置。update_kv_cache方法會在每生成新token或預填充一批序列時調用,將新產生的K/V復制到相應位置,并在最后一層時更新全局偏移。可以看到,該實現中默認將緩存保存在CPU,只有在需要計算或預取時才調用.to(self.device)挪到GPU——這是因為在超長序列場景下,緩存可能過大以至于GPU放不下,需要依賴CPU內存。ShadowKV正是基于類似思路發展而來,但它更加智能:并不簡單地把整個緩存都留在CPU、也不全放GPU,而是精挑細選一部分放GPU,其他放CPU,從而在速度和內存之間取得平衡。
通過對比可以發現,ShadowKV相比這個基礎實現主要多了:Landmark/Outlier篩選、低秩分解以及按需的增量更新策略。這些額外邏輯雖然復雜,但帶來了巨大的性能優勢。
實驗結果與內存優化補充
ShadowKV在作者的實驗中取得了非常亮眼的結果。在多個長上下文基準測試上,它在A100 GPU上實現了最高約3倍的生成吞吐提升,并且在支持更大批量的同時幾乎沒有準確率下降。例如,對于122K長度的序列批處理,ShadowKV將批大小從傳統方案的4提升到了24,吞吐從80 tokens/s提高到245 tokens/s左右,而生成結果與完整注意力計算完全一致。這些收益源于ShadowKV出色的內存管理和訪存優化。
在實現細節上,ShadowKV為提升效率做出了多種內存訪問優化策略。例如,采用塊對齊的存儲布局(8個token一組),使得選中塊的Value可以整塊拷貝;使用自定義CUDA Kernel實現如gather_copy和batch_gemm_rotary_pos_emb等操作,將數據整理、復制和運算融合,減少中間臨時數據和冗余內存讀寫;利用CUDA流和異步拷貝,在CPU-GPU傳輸Value的同時GPU可并行進行部分計算,最大化流水線利用。據作者測算,ShadowKV有效利用了GPU高帶寬,在A100上相當于每秒7TB以上的數據處理能力,逼近硬件理論峰值。
總而言之,ShadowKV通過巧妙地將 “大而全”的KV緩存拆解為“精而簡”的影子緩存,在長上下文LLM推理中實現了存儲與計算的雙重優化。對于研究者而言,這一機制提供了新的思路:在保證模型性能的前提下,可通過矩陣分解、稀疏選擇等手段大幅提升推理效率。



















)