文章目錄
- 前言
- 一、Deepseek Moe
- 二. Moe架構
- 1. Expert
- 2. Gate
- 3. MoE Module
- 三、Auxiliary Loss
- 總結
前言
MoE(Mixture of Experts) 已經逐漸在LLM中廣泛應用,其工程部署相關目前也有了越來越多的支持,本文主要記錄一下MoE的基本模塊構造與原理。以Deepseek中的MoE構造為例。
MoE本質上可以看作一個MLP層,不過是對每個token都不一樣的MLP層,假設一個MoE模塊存在64個expert,相當于有64個并行MLP層,當有一個token送入進行處理時,會自動選擇當前最合適的幾個expert進行運算,而不是一個固定個MLP。
一、Deepseek Moe
模型整體架構如下:
Transformer((embed): ParallelEmbedding()(layers): ModuleList((0): Block((attn): MLA((wq): ColumnParallelLinear()(wkv_a): Linear()(kv_norm): RMSNorm()(wkv_b): ColumnParallelLinear()(wo): RowParallelLinear())(ffn): MLP((w1): ColumnParallelLinear()(w2): RowParallelLinear()(w3): ColumnParallelLinear())(attn_norm): RMSNorm()(ffn_norm): RMSNorm())(1-26): 26 x Block((attn): MLA((wq): ColumnParallelLinear()(wkv_a): Linear()(kv_norm): RMSNorm()(wkv_b): ColumnParallelLinear()(wo): RowParallelLinear())(ffn): MoE((gate): Gate()(experts): ModuleList((0-63): 64 x Expert((w1): Linear()(w2): Linear()(w3): Linear()))(shared_experts): MLP((w1): ColumnParallelLinear()(w2): RowParallelLinear()(w3): ColumnParallelLinear()))(attn_norm): RMSNorm()(ffn_norm): RMSNorm()))(norm): RMSNorm()(head): ColumnParallelLinear()
)
二. Moe架構
從上面的架構可以發現, moe作為一個模塊替換了原始Transformer架構mlp模塊,主要包含一個Gate和Expert。
1. Expert
Expert代碼如下:
class Expert(nn.Module):"""Expert layer for Mixture-of-Experts (MoE) models.Attributes:w1 (nn.Module): Linear layer for input-to-hidden transformation.w2 (nn.Module): Linear layer for hidden-to-output transformation.w3 (nn.Module): Additional linear layer for feature transformation."""def __init__(self, dim: int, inter_dim: int):"""Initializes the Expert layer.Args:dim (int): Input and output dimensionality.inter_dim (int): Hidden layer dimensionality."""super().__init__()self.w1 = Linear(dim, inter_dim)self.w2 = Linear(inter_dim, dim)self.w3 = Linear(dim, inter_dim)def forward(self, x: torch.Tensor) -> torch.Tensor:"""Forward pass for the Expert layer.Args:x (torch.Tensor): Input tensor.Returns:torch.Tensor: Output tensor after expert computation."""return self.w2(F.silu(self.w1(x)) * self.w3(x))可以看到Expert本質上就是一個簡單的線性層
2. Gate
如何在當前MoE模塊中選擇合適的Expert則是通過Gate操作來完成的
Gate代碼如下:
class Gate(nn.Module):"""Gating mechanism for routing inputs in a mixture-of-experts (MoE) model.Attributes:dim (int): Dimensionality of input features.topk (int): Number of top experts activated for each input.n_groups (int): Number of groups for routing.topk_groups (int): Number of groups to route inputs to.score_func (str): Scoring function ('softmax' or 'sigmoid').route_scale (float): Scaling factor for routing weights.weight (torch.nn.Parameter): Learnable weights for the gate.bias (Optional[torch.nn.Parameter]): Optional bias term for the gate."""def __init__(self, args: ModelArgs):"""Initializes the Gate module.Args:args (ModelArgs): Model arguments containing gating parameters."""super().__init__()self.dim = args.dimself.topk = args.n_activated_expertsself.n_groups = args.n_expert_groupsself.topk_groups = args.n_limited_groupsself.score_func = args.score_funcself.route_scale = args.route_scaleself.weight = nn.Parameter(torch.empty(args.n_routed_experts, args.dim))self.bias = nn.Parameter(torch.empty(args.n_routed_experts)) if self.dim == 7168 else Nonedef forward(self, x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:"""Forward pass for the gating mechanism.Args:x (torch.Tensor): Input tensor.Returns:Tuple[torch.Tensor, torch.Tensor]: Routing weights and selected expert indices."""scores = linear(x, self.weight)if self.score_func == "softmax":scores = scores.softmax(dim=-1, dtype=torch.float32)else:scores = scores.sigmoid()original_scores = scoresif self.bias is not None:scores = scores + self.biasif self.n_groups > 1:scores = scores.view(x.size(0), self.n_groups, -1)if self.bias is None:group_scores = scores.amax(dim=-1)else:group_scores = scores.topk(2, dim=-1)[0].sum(dim=-1)indices = group_scores.topk(self.topk_groups, dim=-1)[1]mask = scores.new_ones(x.size(0), self.n_groups, dtype=bool).scatter_(1, indices, False)scores = scores.masked_fill_(mask.unsqueeze(-1), float("-inf")).flatten(1)indices = torch.topk(scores, self.topk, dim=-1)[1]weights = original_scores.gather(1, indices)if self.score_func == "sigmoid":weights /= weights.sum(dim=-1, keepdim=True)weights *= self.route_scalereturn weights.type_as(x), indicesGate函數通過輸入特征向量,輸出分數

基于當前分數根據情況確定是否采用分組路由, 若采用分組路由,則會將多個expert分組,然后取每個組的最高分
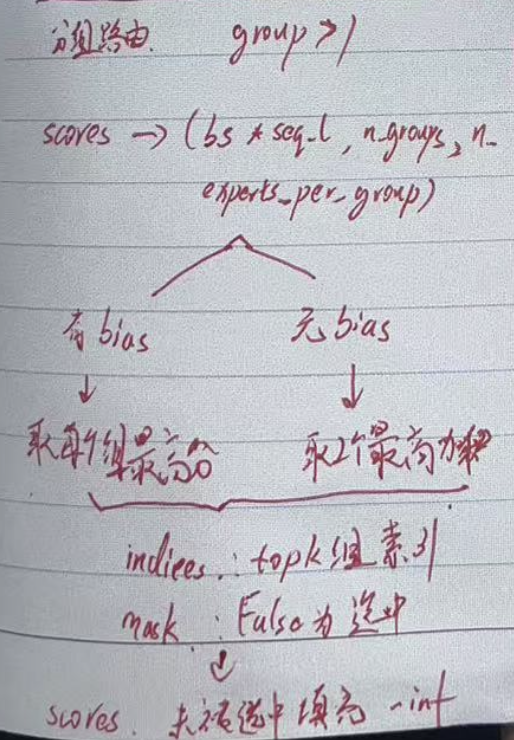
3. MoE Module
有了Gate計算的分數,就可以進行MoE的計算了,MoE模塊如下
class MoE(nn.Module):"""Mixture-of-Experts (MoE) module.Attributes:dim (int): Dimensionality of input features.n_routed_experts (int): Total number of experts in the model.n_local_experts (int): Number of experts handled locally in distributed systems.n_activated_experts (int): Number of experts activated for each input.gate (nn.Module): Gating mechanism to route inputs to experts.experts (nn.ModuleList): List of expert modules.shared_experts (nn.Module): Shared experts applied to all inputs."""def __init__(self, args: ModelArgs):"""Initializes the MoE module.Args:args (ModelArgs): Model arguments containing MoE parameters."""super().__init__()self.dim = args.dimassert args.n_routed_experts % world_size == 0, f"Number of experts must be divisible by world size (world_size={world_size})"self.n_routed_experts = args.n_routed_expertsself.n_local_experts = args.n_routed_experts // world_sizeself.n_activated_experts = args.n_activated_expertsself.experts_start_idx = rank * self.n_local_expertsself.experts_end_idx = self.experts_start_idx + self.n_local_expertsself.gate = Gate(args)self.experts = nn.ModuleList([Expert(args.dim, args.moe_inter_dim) if self.experts_start_idx <= i < self.experts_end_idx else Nonefor i in range(self.n_routed_experts)])self.shared_experts = MLP(args.dim, args.n_shared_experts * args.moe_inter_dim)def forward(self, x: torch.Tensor) -> torch.Tensor:"""Forward pass for the MoE module.Args:x (torch.Tensor): Input tensor.Returns:torch.Tensor: Output tensor after expert routing and computation."""shape = x.size()x = x.view(-1, self.dim)weights, indices = self.gate(x)y = torch.zeros_like(x)counts = torch.bincount(indices.flatten(), minlength=self.n_routed_experts).tolist()for i in range(self.experts_start_idx, self.experts_end_idx):if counts[i] == 0:continueexpert = self.experts[i]idx, top = torch.where(indices == i)y[idx] += expert(x[idx]) * weights[idx, top, None]z = self.shared_experts(x)if world_size > 1:dist.all_reduce(y)return (y + z).view(shape)為了方便理解,繪制了個草圖

通過gate函數可以獲得每個token所選的專家索引與對應的score
如上圖中畫了一個簡單的當topk=3時的索引矩陣,針對每個token,選擇三個expert進行處理,每個expert對應了一個分數用于加權。
循環所有expert,基于indices矩陣找出需要第i個expert處理的所有token ——> x[idx] ,經過expert處理后加權賦予y 作為新的特征。
獲得y后,在將x送入shared_expert 獲得z, 最后兩者相加獲得最終MoE的特征。

三、Auxiliary Loss
這里還需要補充一點,在使用MoE的同時,需要使用Auxiliary Loss。在混合專家 (MoE, Mixture of Experts) 模型中,Auxiliary Loss(輔助損失) 的主要作用是 負載均衡,即:
平衡專家的負載: 避免所有的 token 都被分配到少數幾個專家上,導致這些專家過度繁忙,而其他專家閑置。
穩定訓練過程: 防止路由器(Router,負責將 token 分配給專家)學到某種不健康的分布,例如所有 token 都集中到一個專家,或 token 分布極其稀疏。
每個 token 的路由器分數(router_logits)表示該 token 應該路由到哪些專家的偏好。
為了負載均衡,需要統計:
每個專家獲得分配的 token 的比例(fraction_tokens_per_expert)。
路由概率(softmax(router_logits))中每個專家的總概率比例(fraction_prob_per_expert)。

關于aux loss的直觀理解如下:

總結
MoE作為目前大模型在結構推理上的一大創新還是很厲害的,比較現在的LLM結構同質化蠻嚴重的。MoE確實給LLM未來的發展帶來更多可能性。





)


實現底層)









)
