目錄
一、Redis主從
1. 主從集群結構
2. 主從同步原理
2.1 全量同步
2.2 增量同步
3. 主從同步優化
4. 總結
二、Redis哨兵
1. 哨兵工作原理
1.1 哨兵作用
1.2 狀態監控
1.3 選舉新的master節點
2. 總結
三、Redis分片集群
1. 散列插槽
2. 故障轉移
四、Redis數據結構
1. RedisObject
2. SkipList
3. SortedSet
五、Redis內存回收
1. 內存過期處理
2. 內存淘汰策略
3. 總結
一、Redis主從
單節點Redis的并發能力是有上限的,要進一步提高Redis的并發能力,就需要搭建主從集群,實現讀寫分離。
1. 主從集群結構
下圖是一個簡單的Redis主從集群結構:
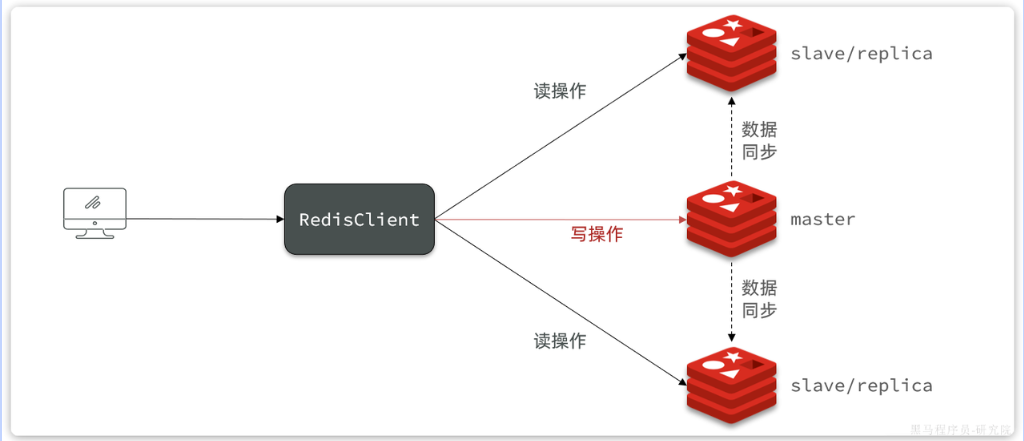
集群中有一個master節點(主),兩個slave節點(從)。當我們通過Redis的Java客戶端訪問主從集群時,應該做好路由:
-
如果是寫操作,應該訪問master節點,master會自動將數據同步給兩個slave節點
-
如果是讀操作,建議訪問各個slave節點,從而分擔并發壓力
2. 主從同步原理
我們向master節點寫入數據之后,在兩個slave節點上也可以看到對應的數據,這說明主從之間完成了數據的同步。那么這個同步是如何完成的呢?
2.1 全量同步
當主從第一次建立連接的時候,會執行全量同步,將master節點的所有數據都拷貝給slave節點,流程如下:
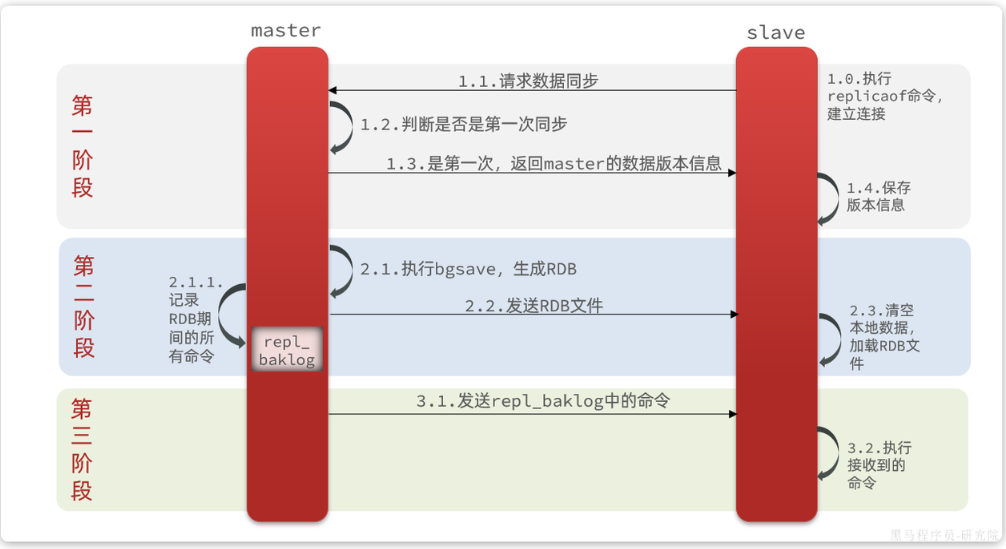
但是主節點如何知道是不是第一次同步呢?
每一個節點在創建出來的時候,都會認為自己是master節點,因此每一個節點就會有一個唯一的ID,即replid。當該節點成為其他節點的從節點時,它就會繼承master節點的ID。因此,如果請求數據同步的節點ID與master節點ID不同,就可以判斷是不是第一次進行同步。
2.2 增量同步
全量同步需要先生成RDB文件,然后將RDB文件通過網絡傳輸個slave,成本太高了。因此除了第一次做全量同步,其它大多數時候slave與master都是做增量同步,流程如下:

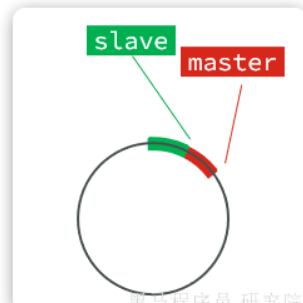
做增量同步之前,需要知道一個重要的概念:偏移量(offset),隨著記錄在repl_baklog中的數據增多而逐漸增大。slave完成同步時也會記錄當前同步的offset。如果slave的offset小于master的offset,說明slave數據落后于master,需要更新。
repl_baklog文件:是一個固定大小的環形數組,也就是說角標到達數組末尾后,會再次從0開始讀寫,這樣數組頭部的數據就會被覆蓋。
repl_baklog文件中會記錄Redis處理過的命令及offset,包括master當前的offset,和slave已經拷貝到的offset,slave與naster的offset之間的差異,就是slave需要增量拷貝的數據。
紅色部分是需要進行同步的數據。
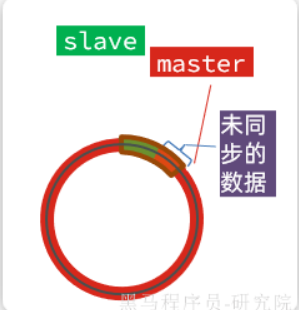
但是會有一種特殊情況,slave出現了網絡阻塞,導致master的offset遠遠超過slave的offset,最終導致還沒有進行數據同步,master就將slave的offset覆蓋了。此時就只能進行全量同步。
3. 主從同步優化
主從同步可以保證主從數據的一致性,非常重要。
可以從下面幾個方面來優化Redis主從集群:
-
在master中配置
repl-diskless-sync yes啟用無磁盤復制(即主節點直接通過網絡向從節點同步數據,不會先保存到磁盤中,再從磁盤取),避免全量同步時的磁盤IO。 -
Redis單節點的內存占用不要太大,減少RDB導致過多的磁盤IO
-
適當提高repl_baklog的大小,發現slave宕機時盡快實現故障恢復,盡可能的避免全量同步
-
限制一個master節點上的salve節點數量。
4. 總結
二、Redis哨兵
主從結構中master節點的作用非常重要,一旦故障就會導致集群不可用。Redis提供了哨兵(Sentinel)機制來監控主從集群監控狀態,確保集群的高可用性。
1. 哨兵工作原理
1.1 哨兵作用
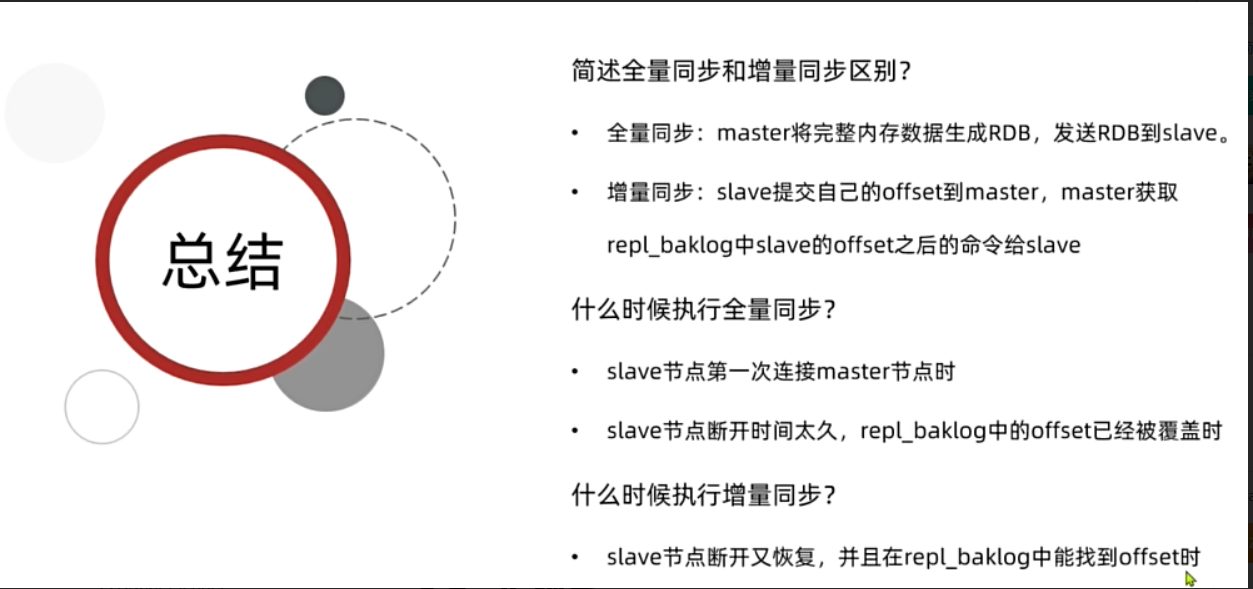
哨兵集群作用原理圖:
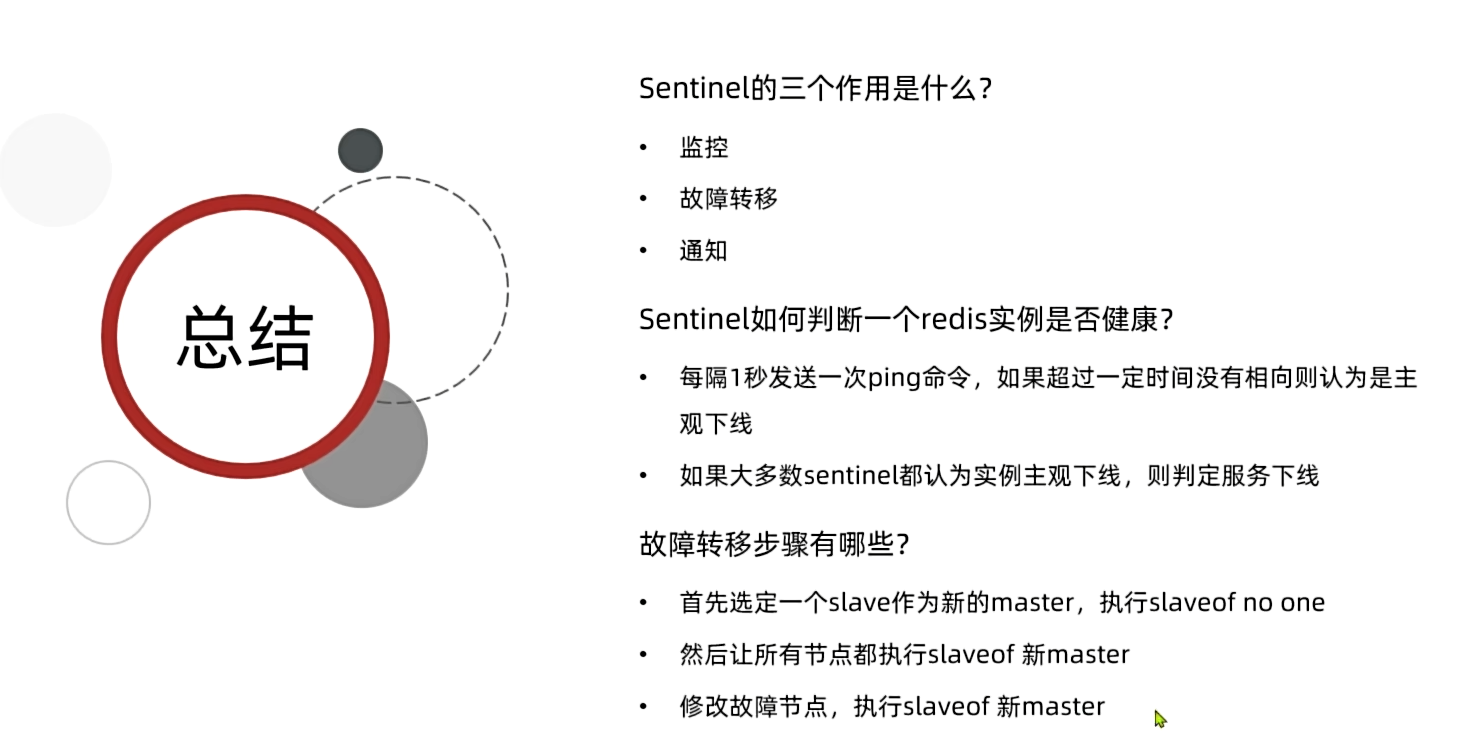
哨兵的作用如下:
-
狀態監控:
Sentinel會不斷檢查master和slave是否按預期工作 -
故障恢復(failover):如果
master故障,Sentinel會將一個slave提升為master。當故障實例恢復后會成為slave -
狀態通知:
Sentinel充當Redis客戶端的服務發現來源,當集群發生failover時,會將最新集群信息推送給Redis的客戶端,客戶端就會知道有了一個新的master,就不會向舊的master中寫數據了。
1.2 狀態監控
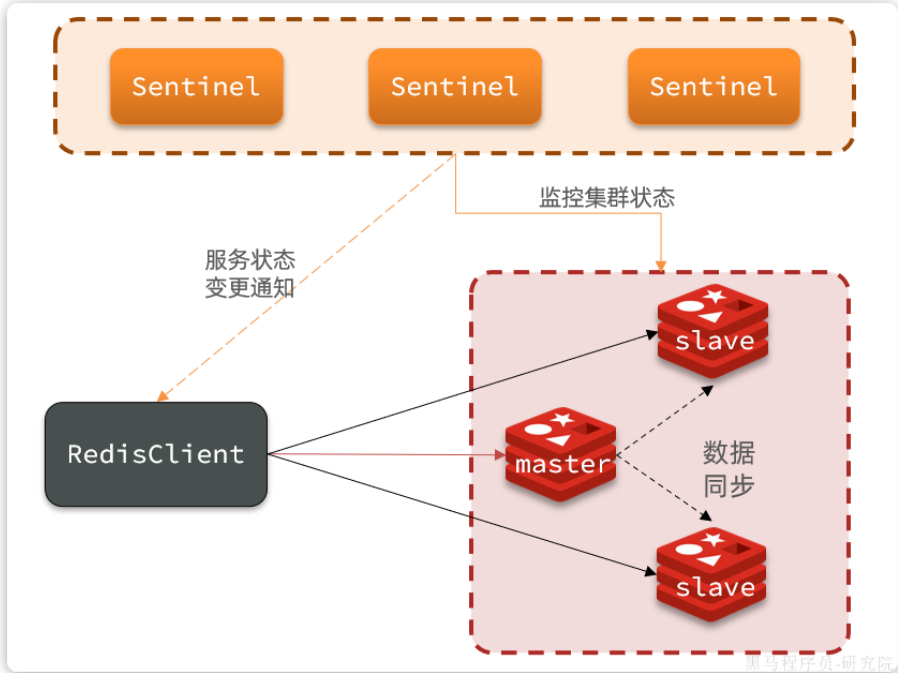
sentinel基于心跳機制監測服務狀態,每隔1秒向集群的每個節點發送ping命令,并通過實例的響應結果來做出判斷:
-
主觀下線(sdown):如果某sentinel節點發現某Redis節點未在規定時間響應,則認為該節點主觀下線。
-
客觀下線(odown):若超過指定數量(通過
quorum設置)的sentinel都認為該節點主觀下線,則該節點客觀下線。quorum值最好超過Sentinel節點數量的一半,Sentinel節點數量至少3臺。
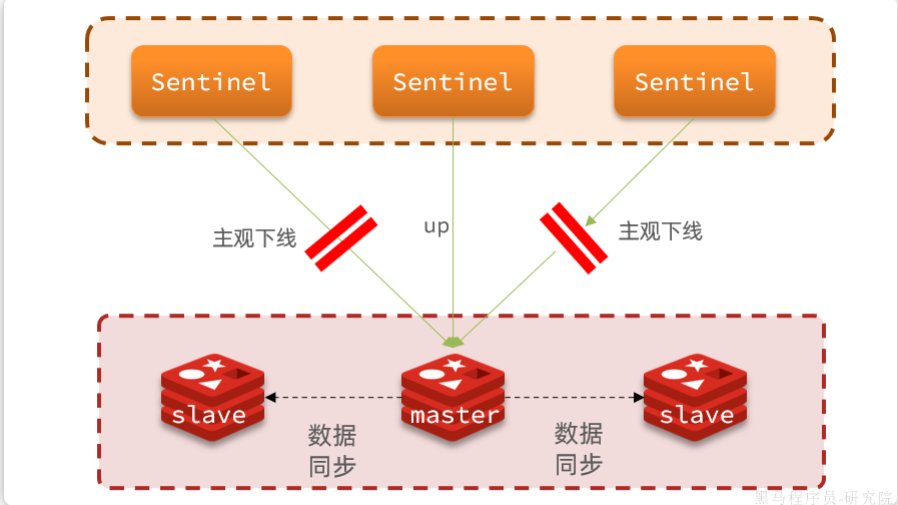
一旦發現故障,sentinel需要在slave中選擇一個作為新的master,選擇依據如下:
-
首先會判斷slave節點與master節點斷開時間長短,如果超過一定時間則會排除該slave節點
-
然后判斷slave節點的
slave-priority值,越小優先級越高,如果是0則永不參與選舉(默認都是1)。 -
如果
slave-prority一樣,則判斷slave節點的offset值,越大說明數據越新,優先級越高
1.3 選舉新的master節點
首先sentinel集群會先選擇出一個執行failover的節點,第一個確認master客觀下線的人會立刻發起投票,一定會成為leader(執行failover的節點)。
執行failover的流程如下:
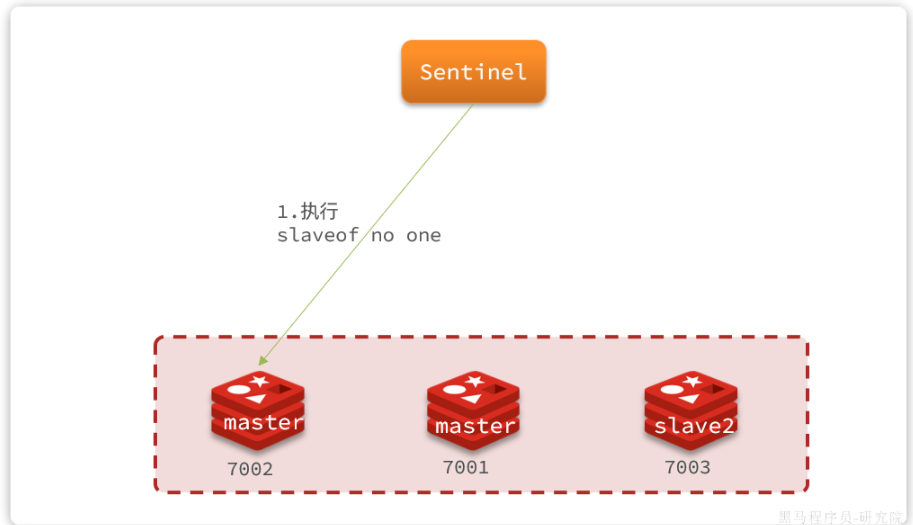
假設我們有一個集群,初始狀態下7001為master,7002和7003為slave:
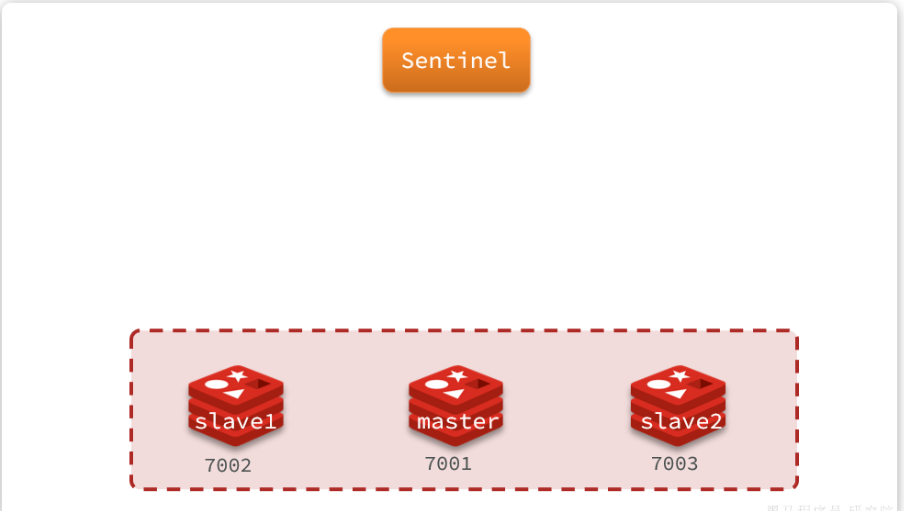
此時master發生故障,sentinel會給備選的slave1節點發送slaveof no one命令,讓該節點成為master:
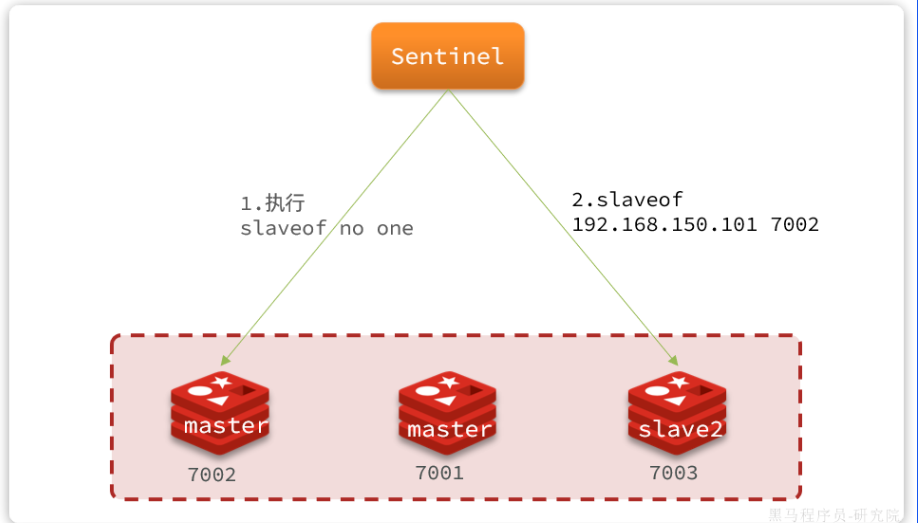
然后sentinel給所有其它slave發送slaveof 192.168.150.101 7002 命令,讓這些節點成為新master,也就是7002的slave節點,開始從新的master上同步數據。
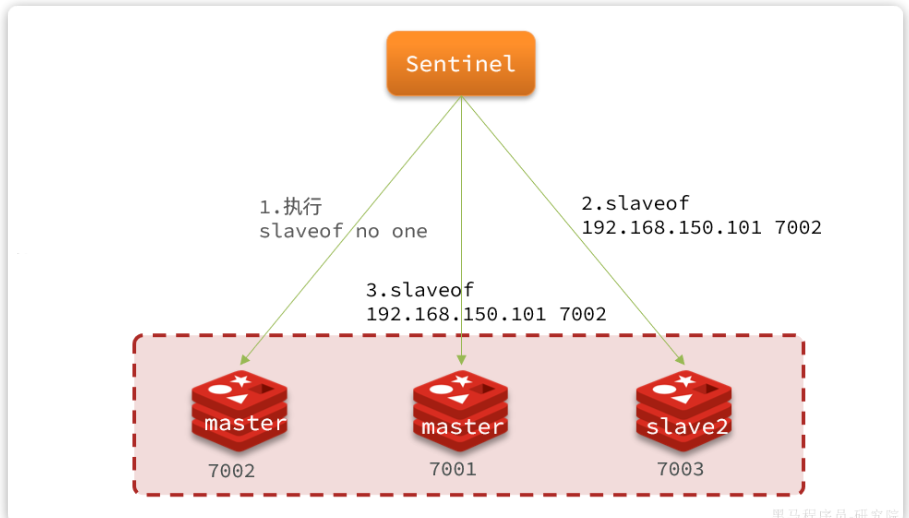
等故障節點恢復之后會接收到哨兵信號,執行slaveof 192.168.150.101 7002命令,成為slave:
2. 總結
三、Redis分片集群
主從模式可以解決高可用、高并發讀的問題。但依然有兩個問題沒有解決:
-
海量數據存儲
-
高并發寫
要解決這兩個問題就需要用到分片集群了。分片的意思,就是把數據拆分存儲到不同節點,這樣整個集群的存儲數據量就更大了。
可以將分片集群理解為多個主從集群集群到一起了。
結構如圖:
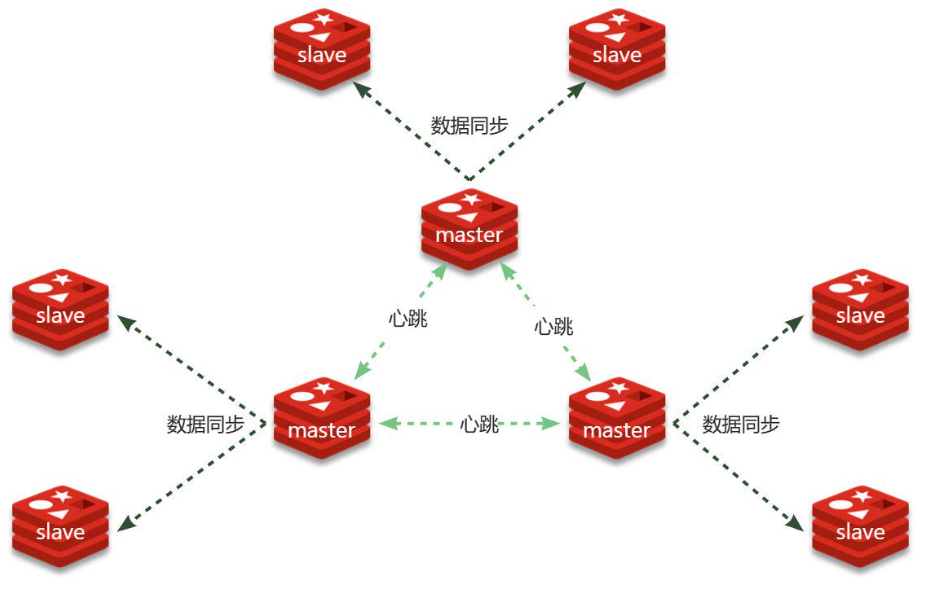
分片集群特征:
-
集群中有多個master,每個master保存不同分片數據 ,解決海量數據存儲問題
-
每個master都可以有多個slave節點 ,確保高可用
-
master之間通過ping監測彼此健康狀態 ,類似哨兵作用
-
客戶端請求可以訪問集群任意節點,最終都會被轉發到數據所在節點
1. 散列插槽
當使用分片集群時,數據要分片存儲到不同的Redis節點,肯定需要有分片的依據,這樣下次查詢的時候才能知道去哪個節點查詢。redis是利用散列插槽(hash slot)的方式實現數據分片的。
在Redis集群中,共有16384個hash slots,集群中的每一個master節點都會分配一定數量的hash slots。具體的分配在集群創建時就已經指定了:
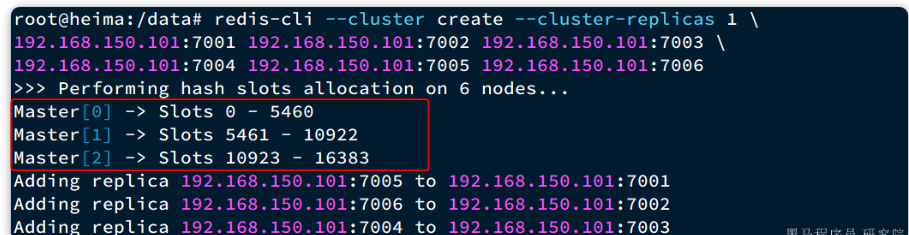
redis中一共有16384個插槽,在分片集群中,會將這些插槽分配給不同的示例。例如上圖,三個主從集群,每一個會被分配5461個插槽。然后根據key計算哈希值,對16384取余,余數作為插槽,尋找插槽所在的實例即可。
不過hash slot的計算也分兩種情況:
-
當
key中包含{}時,根據{}之間的字符串計算hash slot -
當
key中不包含{}時,則根據整個key字符串計算hash slot
例如:
-
key是
user,則根據user來計算hash slot -
key是
user:{age},則根據age來計算hash slot
2. 故障轉移
分片集群的節點之間會互相通過ping的方式做心跳檢測,超時未回應的節點會被標記為下線狀態。當發現master下線時,會將這個master的某個slave提升為master。
例如某個分片集群master節點為7002,有個從節點7006。如果7002發生故障,那么7006就會變成主節點,7002恢復后就會變成7006的slave節點。
四、Redis數據結構
1. RedisObject
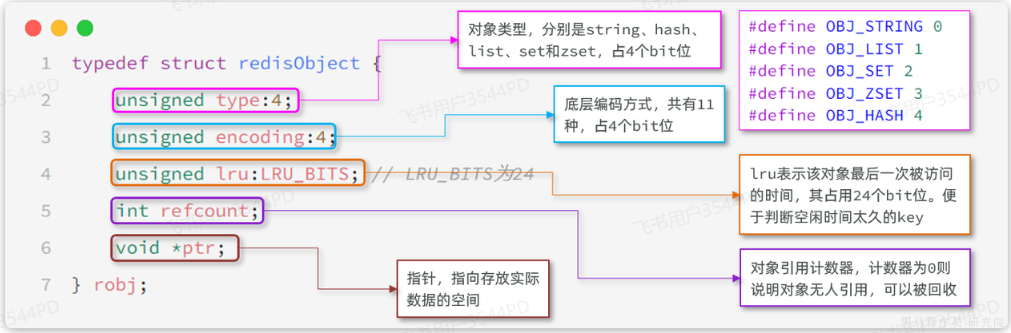
不管是任何一種數據類型,最終都會封裝為RedisObject格式,它是一種結構體。
結構如下圖所示:
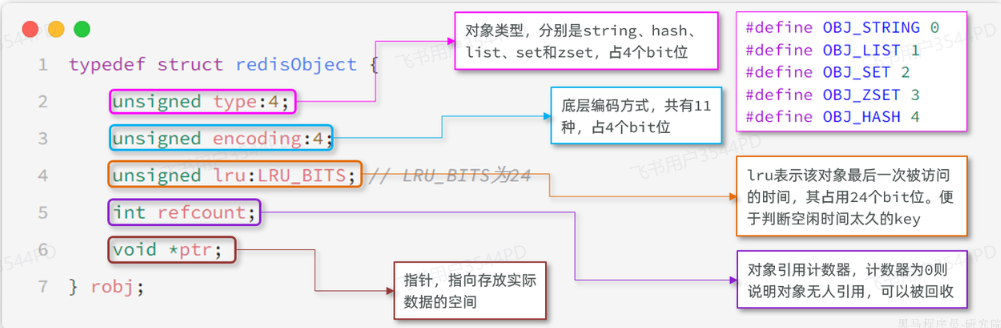
屬性中的encoding就是當前對象底層采用的數據結構或者編碼方式。
下面要說的SkipList(跳表)就是一種encoding。
2. SkipList
SkipList(跳表)首先是鏈表,但與傳統鏈表相比有幾點差異:
-
元素按照升序排列存儲
-
節點可能包含多個指針,指針跨度不同。
傳統鏈表只有指向前后元素的指針,因此只能順序依次訪問。如果查找的元素在鏈表中間,查詢的效率會比較低。而SkipList則不同,它內部包含跨度不同的多級指針,可以讓我們跳躍查找鏈表中間的元素,效率非常高。
結構如圖所示:
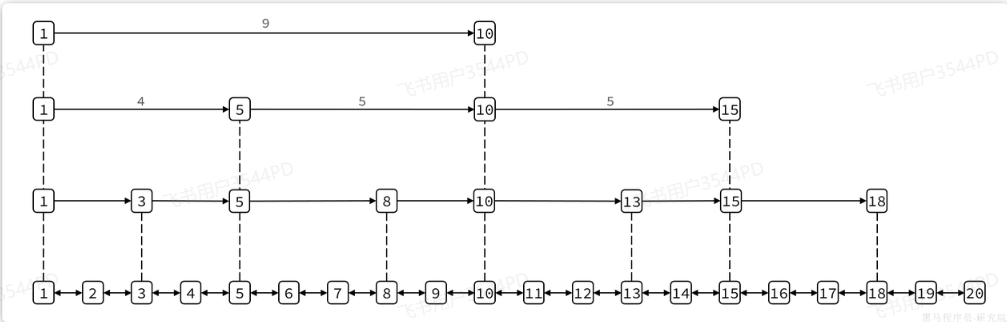
我們可以看到1號元素就有指向3、5、10的多個指針,查詢時就可以跳躍查找。例如我們要找大小為14的元素,查找的流程是這樣的:
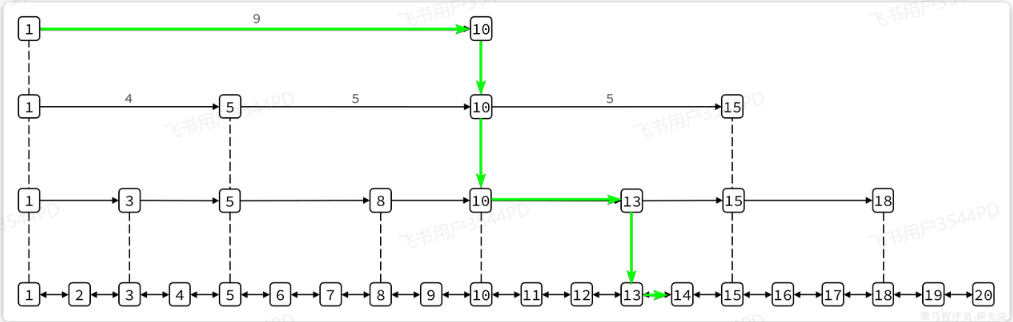
3. SortedSet
SortedSet就是有序集合Zset。
SortedSet的結構體如下所示:
typedef struct zset {dict *dict; // dict,底層就是HashTablezskiplist *zsl; // 跳表
} zset;Redis的SortedSet底層數據結構是怎么樣的?
SortedSet是有序集合,底層的存儲的每個數據都包含element和score兩個值。score是得分,element則是字符串值。SortedSet會根據每個element的score值排序,形成有序集合。
它支持的操作很多,比如:
-
根據element查詢score值
-
按照score值升序或降序查詢element
要實現根據element查詢對應的score值,就必須實現element與score之間的鍵值映射。SortedSet底層是基于HashTable來實現的。
要實現對score值排序,并且查詢效率還高,就需要有一種高效的有序數據結構,SortedSet是基于跳表實現的。
五、Redis內存回收
1. 內存過期處理
過期處理指的就是存入Redis中的數據可以配置過期時間,到期后再次訪問會發現這些數據都不存在了,也就是被過期清理了。
Redis是如何判斷一個KEY是否過期呢?
在Redis中會有兩個Dict,也就是HashTable,其中一個記錄KEY-VALUE鍵值對,另一個記錄KEY和過期時間。要判斷一個KEY是否過期,只需要到記錄過期時間的Dict中根據KEY查詢即可。
Redis是何時刪除過期KEY的呢?
Redis的過期KEY刪除策略有兩種:惰性刪除、周期刪除。
惰性刪除顧名思義Redis不會定期去看內存中的KEY是否過期,而是在訪問某個KEY的時候判斷當前KEY是否過期,如果過期就直接刪除。
周期刪除就是通過一個定時任務,周期性的抽樣部分過期的key,然后執行刪除。
2. 內存淘汰策略
對于某些特別依賴于Redis的項目而言,僅僅依靠過期KEY清理是不夠的,內存可能很快就達到上限。因此Redis允許設置內存告警閾值,當內存使用達到閾值時就會主動挑選部分KEY刪除以釋放更多內存。這叫做內存淘汰機制。
Redis支持多種內存淘汰策略,:
-
noeviction: 不淘汰任何key,但是內存滿時不允許寫入新數據,默認就是這種策略。 -
volatile-ttl: 對設置了TTL的key,比較key的剩余TTL值,TTL越小越先被淘汰 -
allkeys-random:對全體key ,隨機進行淘汰。也就是直接從db->dict中隨機挑選 -
volatile-random:對設置了TTL的key ,隨機進行淘汰。也就是從db->expires中隨機挑選。 -
allkeys-lru: 對全體key,基于LRU算法進行淘汰 -
volatile-lru: 對設置了TTL的key,基于LRU算法進行淘汰 -
allkeys-lfu: 對全體key,基于LFU算法進行淘汰 -
volatile-lfu: 對設置了TTL的key,基于LFI算法進行淘汰
其中volatile-lru和volatile-lfu是比較常用的兩種策略。
-
LRU(
LeastRecentlyUsed),最近最久未使用。用當前時間減去最后一次訪問時間,這個值越大則淘汰優先級越高。 -
LFU(
LeastFrequentlyUsed),最少頻率使用。會統計每個key的訪問頻率,值越小淘汰優先級越高。
在RedisObject結構當中,其中的lru就是記錄最近一次訪問時間和訪問頻率的。
當然,選擇LRU和LFU時的記錄方式不同:
-
LRU:以秒為單位記錄最近一次訪問時間,長度24bit
-
LFU:高16位以分鐘為單位記錄最近一次訪問時間,低8位記錄邏輯訪問次數。
3. 總結
當Redis內存不足時會怎么做?
這取決于配置的內存淘汰策略,Redis支持很多種內存淘汰策略,例如LRU、LFU、Random. 但默認的策略是直接拒絕新的寫入請求。而如果設置了其它策略,則會在每次執行命令后判斷占用內存是否達到閾值。如果達到閾值則會基于配置的淘汰策略嘗試進行內存淘汰,直到占用內存小于閾值為止。
邏輯訪問次數是如何計算的?
由于記錄訪問次數的只有8bit,即便是無符號數,最大值只有255,不可能記錄真實的訪問次數。因此Redis統計的其實是邏輯訪問次數。這其中有一個計算公式,會根據當前的訪問次數做計算,結果要么是次數+1,要么是次數不變。但隨著當前訪問次數越大,+1的概率也會越低,并且最大值不超過255.
除此以外,邏輯訪問次數還有一個衰減周期,默認為1分鐘,即每隔1分鐘邏輯訪問次數會-1。這樣邏輯訪問次數就能基本反映出一個key的訪問熱度了。




詳細講解Linux調試器 gdb/cgdb使用)


)

)









