
OpenAI 推出了新的旗艦 AI 模型 GPT-5,它將為該公司的下一代 ChatGPT 提供支持。
https://openai.com/index/introducing-gpt-5/
GPT-5 于周四發布,是 OpenAI 首個“統一”AI 模型,它將O 系列模型的推理能力與GPT 系列的快速響應能力相結合。下一代模型標志著 ChatGPT 及其創建者 OpenAI 的新紀元,也表明 OpenAI 的宏偉目標:開發更像代理而非聊天機器人的 AI 系統。
GPT-4使人工智能聊天機器人能夠對各種問題提供智能響應,而GPT-5 則使 ChatGPT 能夠代表用戶完成各種任務,例如生成軟件應用程序、瀏覽用戶日歷或創建研究簡報。
OpenAI也致力于通過 GPT-5 簡化 ChatGPT 的使用。GPT-5 不再要求用戶選擇正確的設置,而是配備了一個實時路由器,可以決定如何提供最佳答案,無論是快速回復用戶問題,還是花費更多時間“思考”答案。
OpenAI 首席執行官 在與記者的吹風會上聲稱 GPT-5 是“世界上最好的模型”,并表示這代表著該公司在開發能夠在最具經濟價值的工作上超越人類的人工智能(即通用人工智能 (AGI))的道路上邁出了“重要一步”。
在歷史上的任何時候,擁有像 GPT-5 這樣的東西都是幾乎不可想象的。
從周四開始,GPT-5 將作為 ChatGPT 的所有免費用戶默認模型。這是公司首次向免費用戶開放 AI 推理模型的努力之一。(此前,該公司將這些更先進的模型置于付費墻之后。)
OpenAI 的長期使命,即讓盡可能多的人享受先進的人工智能,確保這些東西真正造福人類。
人們對 GPT-5 寄予厚望,這是 OpenAI 自 2022 年推出 ChatGPT 以來最受期待的產品之一。自那時起,ChatGPT 已發展成為全球最受歡迎的消費產品之一,每周覆蓋超過 7 億用戶,據該公司稱,這幾乎占全球人口的 10%。
許多人將 GPT-5 視為人工智能廣泛進步的風向標,而硅谷對該模型的接受程度可能對大型科技公司、華爾街以及監管技術的政策制定者產生深遠影響。這些利益相關者正在關注 GPT-5 能否顯著提升人工智能的能力,就像其前身 GPT-4 一樣,后者挑戰了人們對軟件功能的預期。
GPT-5 在競爭中略占優勢
OpenAI 聲稱 GPT-5 在多個領域都達到了領先水平,在關鍵基準測試中略勝 Anthropic、谷歌 DeepMind 和埃隆·馬斯克的 xAI 等領先的 AI 模型。然而,GPT-5 在其他領域的表現略遜于前沿 AI 模型。
該公司表示,GPT-5 在編碼方面提供了前沿水平的性能;奧特曼表示,該模型尤其擅長按需啟動整個軟件應用程序,即所謂的“氛圍編碼”。
在 SWE-bench Verified(一項從 GitHub 獲取的真實世界編碼任務測試)中,GPT-5 首次嘗試得分高達 74.9%。這意味著 GPT-5 的表現略勝于 Anthropic 最新的 Claude Opus 4.1 模型(得分為74.5%)和谷歌 DeepMind 的 Gemini 2.5 Pro(得分為59.6%)。
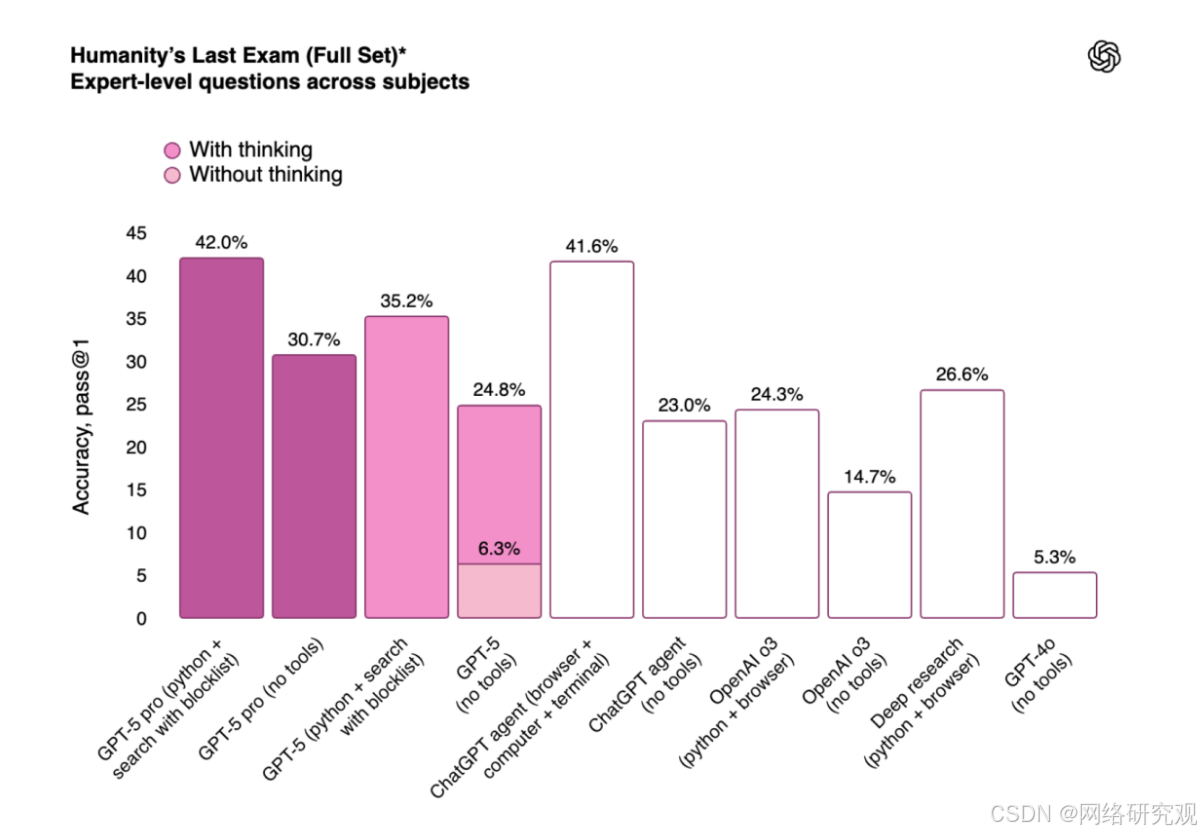
在“人類的最后考試”(一項衡量數學、人文和自然科學領域人工智能模型表現的難度較高的測試)中,具有擴展推理功能的 GPT-5 版本(GPT-5 Pro)在使用工具的情況下得分為 42%。這一得分略低于 xAI 的Grok 4 Heavy,后者在測試中的得分為 44.4%。
在 GPQA Diamond(一項針對博士級科學問題的測試)中,GPT-5 pro 首次嘗試就獲得了 89.4% 的得分,超過了得分 80.9% 的 Claude Opus 4.1 和得分 88.9% 的 Grok 4 Heavy。
OpenAI 表示,GPT-5 更適合回答健康相關問題。在 HealthBench Hard Hallucinations 測試中,OpenAI 表示,在衡量 AI 模型在醫療保健主題響應準確度的測試中,GPT-5(具有思考能力)的幻覺出現率僅為 1.6%。這遠低于該公司之前的 GPT-4o 和 o3 模型,后兩者的得分分別為 12.9% 和 15.8%。
雖然人工智能聊天機器人并非醫療專業人士,但數百萬人正在使用它們來獲取健康建議。針對這一現象,該公司表示,GPT-5 能夠更主動地標記潛在的健康問題,并幫助用戶解析醫療結果。
此外,OpenAI 表示,GPT-5 在創意設計和寫作等更難衡量的主觀領域比其他 AI 模型表現更出色。GPT-5 在創意任務上比其他 AI 模型反應更自然,并且展現出“更佳的品味”。
GPT-5 也比 OpenAI 之前的模型更準確,該公司表示,與 O 系列模型相比,GPT-5 受到幻覺(AI 模型編造信息的傾向)的影響要小得多。在 OpenAI 最新的 AI 推理模型(例如 O3)中,幻覺似乎越來越嚴重,OpenAI 此前曾表示,它不太理解為什么會出現這種情況。
OpenAI 發現,在 ChatGPT 提示的響應中,GPT-5(具有思考能力)出現幻覺并提供錯誤信息的概率為 4.8%。這與 GPT-o3 和 GPT-4o 相比顯著降低,后兩者在測試中的幻覺發生率分別為 22% 和 20.6%。
在衡量AI模型完成模擬在線任務的代理能力的基準測試Tau-bench中,GPT-5的表現參差不齊。在衡量AI瀏覽航空公司網站能力的測試部分,GPT-5的得分為63.5%,略低于o3的64.8%。在衡量AI瀏覽零售網站能力的另一部分測試中,GPT-5的得分為81.1%,低于Claude Opus 4.1的82.4%。
OpenAI 還表示,GPT-5 比之前的模型更安全。雖然人工智能推理模型偶爾會表現出針對人類的陰謀或為實現自身目標而撒謊的傾向,但 OpenAI 發現 GPT-5 的欺騙率低于其他模型。
OpenAI 安全研究負責人表示,減少欺騙不僅可以提高 GPT-5 的安全性,還可以提高用戶體驗,創建一個“更加透明和誠實,讓用戶可以信任”的模型。
GPT-5 能夠更好地識別試圖濫用 ChatGPT 的惡意用戶和提出無害請求的用戶。這使得 GPT-5 能夠拒絕更多不安全的問題,同時減少對尋求無害信息的用戶的拒絕次數。
為消費者和開發者提供升級
作為 GPT-5 發布的一部分,ChatGPT 的用戶體驗得到了一些升級。用戶現在可以在 ChatGPT 的設置中選擇四種新的性格:憤世嫉俗者、機器人、傾聽者和書呆子。該公司表示,這些性格將調整 ChatGPT 的響應方式,而無需用戶專門要求模型以某種方式響應。
ChatGPT 每月 20 美元的 Plus 套餐訂閱用戶可獲得比免費用戶更高的 GPT-5 使用限制。同時,每月 200 美元的 Pro 套餐訂閱用戶將可以無限制使用 GPT-5,以及名為 GPT-5 Pro 的增強版,該版本使用額外的計算資源來生成更準確的答案。OpenAI 的 Team、Edu 和 Enterprise 套餐用戶將于下周將 GPT-5 作為其默認模型。
對于開發者來說,GPT-5 將以三種版本(GPT-5、GPT-5-mini 和 GPT-5-nano)加入 OpenAI 的 API,它們將花費更多或更少的時間進行“推理”任務。開發者現在還可以控制 OpenAI API 中的詳細程度,決定 AI 模型的響應時長。
GPT-5 的基礎模型將花費開發人員每百萬輸入令牌 1.25 美元(約 750,000 個單詞,比整個《指環王》系列還要長),每百萬輸出令牌 10 美元。
GPT-5 的發布正值 OpenAI 忙碌的一周之后。該公司發布了一個開放權重推理模型gpt-oss,開發者和企業可以免費下載,并以極低的成本運行。該開放模型的性能幾乎與 OpenAI 之前的頂級模型 o3 和 o4-mini 相當,但 GPT-5 在某些領域(例如編碼)為前沿性能樹立了新的標準。
然而,GPT-5 似乎在多個領域與其他前沿 AI 模型大致相當。當然,基準測試只能反映任何 AI 模型的部分情況,開發者將如何在現實世界中使用 GPT-5,以及該模型是否真正領先于競爭對手,仍有待觀察。



)


)



)




|SVM-構建軟邊界拉格朗日方程)

)
)
