🚀 Spring Boot + ShardingSphere 實現分庫分表 + 讀寫分離(涵蓋99%真實場景)
🏷? 標簽:ShardingSphere、分庫分表、讀寫分離、MySQL 主從、Spring Boot 實戰
分庫分表 vs 讀寫分離 vs 主從配置與數據庫高可用架構區別
📚 目錄導航
- 🔍 一、場景說明
- 🧱 二、架構圖
- ?? 三、核心配置
- 🗃? 四、數據庫建表SQL
- 👨?💻 五、關鍵代碼
- 🧪 六、測試驗證
- 🧠 七、總結與建議
🔍 一、場景說明
🚨 實際項目中,數據庫面臨兩類瓶頸:
- 📌 數據量太大 → 單庫單表撐不住 → 使用 分庫分表 拆解壓力
- 📌 讀操作壓力太大 → 單庫處理不過來 → 使用 讀寫分離 轉移壓力
? 本項目整合了這兩類方案,構建如下特性系統:
- 兩個邏輯庫
ds0、ds1 ds0搭建一主兩從(主庫:ds0,從庫:ds0_slave1,ds0_slave2)- 表按照用戶 ID 分片(user_id % 2)
- 主寫從讀,輕松實現讀寫分離
🧱 二、架構圖
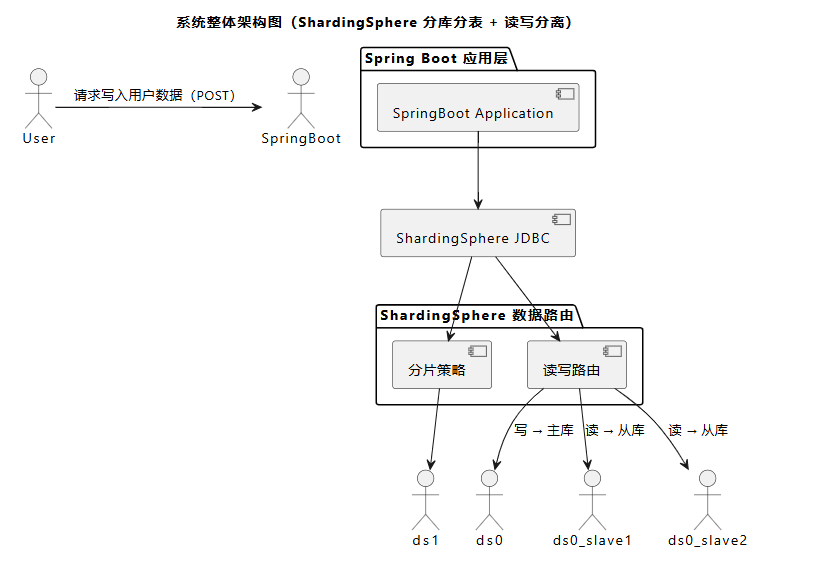
📝 說明:
- 用戶通過 Controller 發起請求
- ShardingSphere JDBC 根據操作類型選擇庫、表
- 如果是寫入操作,走
ds0或ds1的主庫 - 如果是讀取操作,優先走
ds0_slave1或ds0_slave2從庫,減輕主庫壓力
?? 三、核心配置(application.yml)
🧩 我們通過配置 ShardingSphere 的兩類規則:
sharding與readwrite-splitting實現業務目標。
spring:shardingsphere:datasource:names: ds0, ds1, ds0_slave1, ds0_slave2ds0:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://mysql-master:3307/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootds0_slave1:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://mysql-slave1:3308/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootds0_slave2:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://mysql-slave2:3309/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: rootds1:type: com.zaxxer.hikari.HikariDataSourcejdbc-url: jdbc:mysql://mysql-master:3306/testdb?useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: rootpassword: root123456rules:sharding:tables:t_user:# 注意:此處使用物理庫名(ds0、ds1)來定義 actual-data-nodesactual-data-nodes: ds$->{0..1}.t_user_$->{0..1}database-strategy:standard:sharding-column: user_idsharding-algorithm-name: database_inlinetable-strategy:standard:sharding-column: user_idsharding-algorithm-name: table_inlinekey-generate-strategy:column: idkey-generator-name: snowflakesharding-algorithms:database_inline:type: INLINEprops:algorithm-expression: ds${user_id % 2}table_inline:type: INLINEprops:algorithm-expression: t_user_${user_id % 2}key-generators:snowflake:type: SNOWFLAKEreadwrite-splitting:data-sources:rw_ds0:static-strategy:write-data-source-name: ds0read-data-source-names: [ds0_slave1,ds0_slave2]load-balancer-name: round_robinrw_ds1:static-strategy:write-data-source-name: ds1read-data-source-names: [ds1]load-balancer-name: round_robinload-balancers:round_robin:type: ROUND_ROBINprops:sql-show: truelogging:level:org.apache.shardingsphere: DEBUG1. 數據源配置 (datasource)
定義了 4 個 MySQL 數據源(2 個主庫 ds0/ds1 和 2 個從庫 ds0_slave1/ds0_slave2)。
| 配置項 | 說明 |
|---|---|
spring.shardingsphere.datasource.names | 數據源名稱列表:ds0, ds1, ds0_slave1, ds0_slave2 |
ds0.jdbc-url | 主庫 ds0 的 JDBC 連接 URL(端口 3307) |
ds0.username | 主庫 ds0 用戶名(root) |
ds0.password | 主庫 ds0 密碼(root) |
ds0_slave1.jdbc-url | 從庫 ds0_slave1 的 JDBC URL(端口 3308) |
ds0_slave2.jdbc-url | 從庫 ds0_slave2 的 JDBC URL(端口 3309) |
ds1.jdbc-url | 主庫 ds1 的 JDBC URL(端口 3306,與 ds0 不同實例) |
2. 分片規則 (sharding)
配置表 t_user 的分片策略和分布式 ID 生成。
分片表配置
| 配置項 | 作用 | 示例值 | 說明 |
|---|---|---|---|
tables.t_user.actual-data-nodes | 定義物理節點 | ds$->{0..1}.t_user_$->{0..1} | 表達式生成所有物理表,如 ds0.t_user_0、ds1.t_user_1。 |
tables.t_user.database-strategy.standard.sharding-column | 分庫列 | user_id | 根據 user_id 計算數據存儲的庫。 |
tables.t_user.database-strategy.standard.sharding-algorithm-name | 分庫算法名稱 | database_inline | 引用 sharding-algorithms 中定義的算法。 |
tables.t_user.table-strategy.standard.sharding-column | 分表列 | user_id | 根據 user_id 計算數據存儲的表。 |
tables.t_user.table-strategy.standard.sharding-algorithm-name | 分表算法名稱 | table_inline | 引用 sharding-algorithms 中定義的算法。 |
tables.t_user.key-generate-strategy.column | 主鍵列 | id | 指定自動生成主鍵的列。 |
tables.t_user.key-generate-strategy.key-generator-name | 主鍵生成器名稱 | snowflake | 使用 Snowflake 算法生成分布式 ID。 |
分片算法
| 配置項 | 作用 | 示例值 | 說明 |
|---|---|---|---|
sharding-algorithms.database_inline.type | 算法類型 | INLINE | 使用行表達式(Inline)分片算法。 |
sharding-algorithms.database_inline.props.algorithm-expression | 分庫表達式 | ds${user_id % 2} | 根據 user_id % 2 計算庫索引(0 或 1)。 |
sharding-algorithms.table_inline.type | 算法類型 | INLINE | 使用行表達式分片算法。 |
sharding-algorithms.table_inline.props.algorithm-expression | 分表表達式 | t_user_${user_id % 2} | 根據 user_id % 2 計算表索引(0 或 1)。 |
分布式 ID
| 配置項 | 作用 | 示例值 | 說明 |
|---|---|---|---|
key-generators.snowflake.type | 主鍵生成器類型 | SNOWFLAKE | 使用 Snowflake 算法生成分布式唯一 ID。 |
3. 讀寫分離規則 (readwrite-splitting)
配置讀寫分離數據源和負載均衡策略。
數據源 rw_ds0
| 配置項 | 說明 |
|---|---|
write-data-source-name | 寫庫數據源:ds0(主庫) |
read-data-source-names | 讀庫數據源列表:[ds0_slave1, ds0_slave2](兩個從庫) |
load-balancer-name | 負載均衡算法:round_robin(輪詢) |
數據源 rw_ds1
| 配置項 | 說明 |
|---|---|
write-data-source-name | 寫庫數據源:ds1(主庫) |
read-data-source-names | 讀庫數據源列表:([ds1]),表示僅使用寫庫讀 |
load-balancer-name | 負載均衡算法:round_robin(未實際生效) |
負載均衡器
| 配置項 | 說明 |
|---|---|
round_robin.type | 算法類型:ROUND_ROBIN(輪詢調度) |
4. 屬性配置 (props)
| 配置項 | 說明 |
|---|---|
sql-show: true | 打印 SQL 日志(便于調試) |
配置邏輯總結
spring:shardingsphere:datasource:names: ds0, ds1, ds0_slave1, ds0_slave2
-
定義三個數據源
ds0: 主庫ds0_slave: 從庫(ds0 復制)ds1: 第二個分片主庫
rules:sharding:tables:t_user:actual-data-nodes: rw_ds$->{0..1}.t_user_$->{0..1}
t_user分片規則:共有2 庫 x 2 表結構
table-strategy:standard:sharding-column: user_idsharding-algorithm-name: user_inline
- 按照
user_id做分片(水平拆表)
sharding-algorithms:user_inline:type: INLINEprops:algorithm-expression: t_user_${user_id % 2}
- 表名后綴 =
user_id % 2,如t_user_0、t_user_1
readwrite-splitting:data-sources:rw_ds0:static-strategy:write-data-source-name: ds0read-data-source-names: [ds0_slave1,ds0_slave1]
- 配置
rw_ds0為讀寫分離庫 ds0負責寫入,ds0_slave1,ds0_slave2負責讀取
rw_ds1:static-strategy:write-data-source-name: ds1read-data-source-names: [ds1]
ds1暫無從庫,只支持主庫寫讀
潛在問題
-
rw_ds1無讀庫- 配置中
rw_ds1.read-data-source-names為ds1,可能導致讀請求全部發往主庫ds1,增加壓力。
- 配置中
-
分片與讀寫分離結合
- 實際數據節點
rw_ds0.t_user_0和rw_ds1.t_user_1的分片邏輯需確保數據均勻分布。
- 實際數據節點
🗃? 四、數據庫建表SQL
在 db0 和 db1 上執行以下語句,創建兩個分表:
CREATE TABLE t_user_0 (id BIGINT PRIMARY KEY,username VARCHAR(100),user_id INT
);CREATE TABLE t_user_1 LIKE t_user_0;
📌 ds0_slave1, ds0_slave2 是主庫 ds0 的復制庫,MySQL 自動同步,無需手動建表。
👨?💻 五、關鍵代碼
? 項目概覽
sharding-demo/
├── src/
│ ├── main/
│ │ ├── java/com/example/shardingdemo/
│ │ │ ├── controller/
│ │ │ ├── entity/
│ │ │ ├── mapper/
│ │ │ ├── ShardingDemoApplication.java
│ └── resources/
│ ├── application.yml
├── pom.xml
? User 實體類
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
@TableName("t_user")
public class User {private Long id;private String username;private Integer userId; // 分片鍵
}
? Mapper 接口
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.shardingdemo.entity.User;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface UserMapper extends BaseMapper<User> {}
? Controller 控制器
import com.example.shardingdemo.entity.User;
import com.example.shardingdemo.mapper.UserMapper;
import lombok.RequiredArgsConstructor;
import org.springframework.web.bind.annotation.*;import java.util.List;@RestController
@RequestMapping("/user")
@RequiredArgsConstructor
public class UserController {private final UserMapper userMapper;@PostMapping("/add")public String addUser(@RequestParam String name, @RequestParam Integer userId) {User user = new User(System.currentTimeMillis(), name, userId);userMapper.insert(user);return "User added.";}@GetMapping("/list")public List<User> selectList() {return userMapper.selectList(null);}@GetMapping("/selectById")public User selectById(Long id){return userMapper.selectById(id);}}
🧪 六、測試驗證
? 添加用戶
http://localhost:8080/user/add?name=Alice&userId=11
控制臺輸出:
Actual SQL: rw_ds1 ::: INSERT INTO t_user_1 ...
? 說明:
userId = 11,落到rw_ds1(ds1)- 且表名為
t_user_1,符合% 2 = 1的路由邏輯
🧠 七、總結與建議
| 特性 | 說明 |
|---|---|
| 💡 分庫分表 | 擴展寫能力,解決單表瓶頸 |
| 💡 讀寫分離 | 減輕主庫壓力,提高系統吞吐 |
| ? 可擴展性 | 新增庫或表只需擴展路由規則,無需修改業務代碼 |
| ? 高性能 | 多線程批量插入、查詢等場景提升明顯 |
| 🔒 安全性 | 通過主從架構,規避讀阻塞或死鎖導致系統不可用 |
📢 建議配合 Docker + MySQL 主從配置部署驗證,效果最佳。
?? 如果你覺得這篇文章有幫助:
- 點贊 👍
- 收藏 ?
- 留言 💬

:輕松爬取圖片網站內容?)










)






