一、信息熵(Entropy)的計算與應用
信息熵用于衡量一個概率分布的不確定性,值越大表示分布越分散(不確定性越高)。
1. 數學定義
對于離散概率分布?P,信息熵公式為:
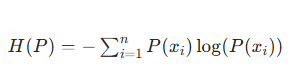
(通常以 2 為底單位是比特,以 e 為底單位是納特,實際使用中可統一底數)
import numpy as np
from scipy.stats import entropy # scipy內置熵計算函數def manual_entropy(p):"""手動計算信息熵(確保p是歸一化的概率分布)"""# 過濾0概率(避免log(0)無意義)p = p[p > 0]return -np.sum(p * np.log(p)) # 以e為底,若需以2為底可改用np.log2# 示例1:均勻分布(不確定性最高)
p_uniform = np.array([0.25, 0.25, 0.25, 0.25]) # 4個事件等概率
print("均勻分布手動計算熵:", manual_entropy(p_uniform)) # 輸出:1.386...(ln4)
print("均勻分布scipy計算熵:", entropy(p_uniform)) # 與手動計算一致# 示例2:極端分布(確定性最高)
p_deterministic = np.array([1.0, 0.0, 0.0, 0.0]) # 只有第一個事件有概率
print("極端分布熵:", entropy(p_deterministic)) # 輸出:0.0(無不確定性)# 示例3:實際應用(文本字符分布的熵)
text = "hello world"
char_counts = np.array([text.count(c) for c in set(text)])
char_probs = char_counts / len(text) # 字符概率分布
print("文本字符分布的熵:", entropy(char_probs)) # 衡量文本字符多樣性運行結果 :
均勻分布手動計算熵: 1.3862943611198906
均勻分布scipy計算熵: 1.3862943611198906
極端分布熵: 0.0
文本字符分布的熵: 1.56071040904140682. Python 實現(手動計算 + 庫函數)
import numpy as np
from scipy.stats import entropy # scipy內置熵計算函數def manual_entropy(p):"""手動計算信息熵(確保p是歸一化的概率分布)"""# 過濾0概率(避免log(0)無意義)p = p[p > 0]return -np.sum(p * np.log(p)) # 以e為底,若需以2為底可改用np.log2# 示例1:均勻分布(不確定性最高)
p_uniform = np.array([0.25, 0.25, 0.25, 0.25]) # 4個事件等概率
print("均勻分布手動計算熵:", manual_entropy(p_uniform)) # 輸出:1.386...(ln4)
print("均勻分布scipy計算熵:", entropy(p_uniform)) # 與手動計算一致# 示例2:極端分布(確定性最高)
p_deterministic = np.array([1.0, 0.0, 0.0, 0.0]) # 只有第一個事件有概率
print("極端分布熵:", entropy(p_deterministic)) # 輸出:0.0(無不確定性)# 示例3:實際應用(文本字符分布的熵)
text = "hello world"
char_counts = np.array([text.count(c) for c in set(text)])
char_probs = char_counts / len(text) # 字符概率分布
print("文本字符分布的熵:", entropy(char_probs)) # 衡量文本字符多樣性3. 應用場景
- 特征選擇:計算特征值的熵,熵越高表示特征越分散,可能包含更多信息。
- 決策樹:ID3/C4.5 算法用信息熵計算 “信息增益”,選擇最優分裂特征。
- 文本分析:通過字符 / 詞頻分布的熵衡量文本復雜度(熵越高,字符分布越均勻)。
補充:
步驟 1:計算數據集的總信息熵?H(D)
以經典的 “天氣與是否打球” 數據集為例(共 14 條樣本):
| 編號 | 天氣(A) | 溫度(B) | 濕度(C) | 風速(D) | 是否打球(標簽) |
|---|---|---|---|---|---|
| 1 | 晴 | hot | 高 | 弱 | 否 |
| 2 | 晴 | hot | 高 | 強 | 否 |
| 3 | 陰 | hot | 高 | 弱 | 是 |
| ... | ... | ... | ... | ... | ... |
| 14 | 陰 | cool | 高 | 強 | 是 |
標簽 “是否打球” 中,“是” 有 9 條,“否” 有 5 條,總熵:H(D)=?149?log2?(149?)?145?log2?(145?)≈0.940
步驟 2:對每個特征計算信息增益
以特征 “天氣(A)” 為例,其取值為 “晴、陰、雨”:
- 晴(5 條):2 條 “是”,3 條 “否” →?晴
- 陰(4 條):4 條 “是”,0 條 “否” →?陰(確定無不確定性)
- 雨(5 條):3 條 “是”,2 條 “否” →?雨
條件熵:H(D∣A)=145?×0.971+144?×0+145?×0.971≈0.693
信息增益:Gain(D,A)=H(D)?H(D∣A)=0.940?0.693=0.247
同理計算其他特征(溫度、濕度、風速)的信息增益,假設結果為:
- 濕度(C)的信息增益最大(約 0.151),則 ID3 選擇 “濕度” 作為根節點的分裂特征。
步驟 3:遞歸構建決策樹
對每個特征取值的子集(如 “濕度 = 高”“濕度 = 正常”),重復步驟 1-2,計算子數據集的信息增益,選擇下一個分裂特征,直到所有樣本屬于同一類別或無特征可分。
三、C4.5 算法步驟(改進 ID3 的信息增益比)
C4.5 的核心是用信息增益比替代信息增益,避免 ID3 偏向取值多的特征(如 “日期” 這類取值多的特征可能信息增益高,但無實際意義)。
步驟 1:計算信息增益(同 ID3)
沿用 ID3 中 “天氣(A)” 的計算,Gain(D,A)=0.247。
步驟 2:計算特征的熵?HA?(D)
特征 “天氣” 有 3 個取值,樣本占比分別為?5/14,4/14,5/14:HA?(D)=?145?log2?145??144?log2?144??145?log2?145?≈1.577
步驟 3:計算信息增益比
Gain_ratio(D,A)=1.5770.247?≈0.156
對所有特征計算信息增益比,選擇增益比最大的特征作為分裂節點(C4.5 通常先篩選信息增益高于平均的特征,再從中選增益比最大的,避免增益接近 0 的特征)。
四、Python 代碼實現(ID3 算法示例)
以下用 Python 手動實現 ID3 算法,核心包括信息熵計算、信息增益計算和決策樹構建:
import numpy as np
from math import log2 #導入對數函數,用于計算信息熵
import pprint #導入格式化打印工具,使決策樹更易讀# 1. 計算信息熵(輸入:標簽列表,如 ['是', '否', '是', ...])
def entropy(labels):"""計算標簽列表的信息熵"""# 統計每個類別的數量 字典儲存 :鍵 = 標簽, 值 = 出現次數label_counts = {}for label in labels: #遍歷所有標簽#如果標簽在字典中,次數+1,否則初始化為1label_counts[label] = label_counts.get(label, 0) + 1ent = 0.0 #初始化信息熵為0total = len(labels) #總樣本數for count in label_counts.values(): #遍歷每個類別的數量p = count / total #計算該類別的概率ent -= p * log2(p) # 信息熵公式return ent # 返回計算好的信息熵#作用:衡量數據集的不確定性,值越大表示越混亂
#關鍵邏輯:用字典統計標簽出現次數,帶入熵公式計算# 2. 計算信息增益(輸入:特征值列表、標簽列表)
def information_gain(feature_values, labels):"""計算某一特征的信息增益"""total_ent = entropy(labels) # 計算總熵total_samples = len(labels) # 總樣本數# 按特征值分組,統計每個取值對應的標簽feature_groups = {} # key: 特征值, value: 該取值對應的標簽列表for f_val, label in zip(feature_values, labels):#同時遍歷特征值和標簽if f_val not in feature_groups: #如果特征值未記錄,初始化列表feature_groups[f_val] = []feature_groups[f_val].append(label)# 計算條件熵 H(D|A):已知特征A的取值后,數據集的不確定性cond_ent = 0.0for group_labels in feature_groups.values(): # 遍歷每個特征值對應的標簽列表group_size = len(group_labels) # 該特征值的樣本數# 條件熵 = 求和(該組樣本占比 * 該組信息熵)cond_ent += (group_size / total_samples) * entropy(group_labels)return total_ent - cond_ent # 信息增益 = 總熵 - 條件熵# 3. 選擇信息增益最大的特征(輸入:特征列表、標簽列表)
def choose_best_feature(features, labels):"""選擇最佳分裂特征features: 特征列表,格式為 [[f1_val, f1_val, ...], [f2_val, ...], ...]每個子列表對應一個特征的所有取值labels: 標簽列表"""best_gain = -1best_feature_idx = 0 # 最佳特征的索引# 遍歷每個特征計算信息增益for i in range(len(features)):feature_values = features[i]gain = information_gain(feature_values, labels)if gain > best_gain: #如果當前增益更大,更新最佳增益和索引。best_gain = gainbest_feature_idx = ireturn best_feature_idx, best_gain #返回最佳的索引和對應的增益# 4. 遞歸構建ID3決策樹
def build_tree(features, labels, feature_names, depth=0, max_depth=5):"""構建決策樹features: 特征列表(格式同上)labels: 標簽列表feature_names: 特征名稱列表(用于樹結構的可讀性)"""# 終止條件1:所有標簽相同,返回該類別if len(set(labels)) == 1:return labels[0]# 終止條件2:無特征可分或達到最大深度,返回多數類if len(features) == 0 or depth >= max_depth:# 統計多數類label_counts = {}for label in labels:label_counts[label] = label_counts.get(label, 0) + 1return max(label_counts, key=label_counts.get) # 多數類標簽# 選擇最佳特征best_idx, _ = choose_best_feature(features, labels)best_feature_name = feature_names[best_idx]best_feature_values = features[best_idx] # 最佳特征的所有取值# 初始化樹結構:以最佳特征為根節點tree = {best_feature_name: {}}# 移除已選擇的特征(剩余特征用于子樹)remaining_features = [features[i] for i in range(len(features)) if i != best_idx]remaining_feature_names = [feature_names[i] for i in range(len(feature_names)) if i != best_idx]# 按最佳特征的取值分組,遞歸構建子樹unique_values = set(best_feature_values) # 最佳特征的所有 unique 取值for val in unique_values:# 篩選出該特征值對應的樣本索引sample_indices = [i for i, f_val in enumerate(best_feature_values) if f_val == val]# 提取子樣本的特征和標簽sub_labels = [labels[i] for i in sample_indices]sub_features = []for f in remaining_features: #遍歷剩余特征#提取該特征在子樣本中的取值sub_f = [f[i] for i in sample_indices]sub_features.append(sub_f)# 遞歸構建子樹,深度+1 ,并將結果存入當前樹結構tree[best_feature_name][val] = build_tree(sub_features, sub_labels, remaining_feature_names, depth + 1, max_depth)return tree# 5. 測試:用天氣數據集構建決策樹
if __name__ == "__main__":# 構造天氣數據集(不依賴pandas,用列表存儲)# 特征名稱列表feature_names = ['天氣', '溫度', '濕度', '風速']# 特征值列表:每個子列表對應一個特征的所有取值features = [['晴', '晴', '陰', '雨', '雨', '雨', '陰', '晴', '晴', '雨', '晴', '陰', '陰', '雨'], # 天氣['hot', 'hot', 'hot', 'mild', 'cool', 'cool', 'cool', 'mild', 'cool', 'mild', 'mild', 'mild', 'hot', 'mild'],# 溫度['高', '高', '高', '高', '正常', '正常', '正常', '高', '正常', '正常', '正常', '高', '正常', '高'], # 濕度['弱', '強', '弱', '弱', '弱', '強', '強', '弱', '弱', '弱', '強', '強', '弱', '強'] # 風速]# 標簽列表 (是否打球)labels = ['否', '否', '是', '是', '是', '否', '是', '否', '是', '是', '是', '是', '是', '否'] # 是否打球# 構建ID3決策樹 (最大深度為3)id3_tree = build_tree(features, labels, feature_names, max_depth=3)# 打印決策樹結構 (用pprint格式化輸出,更易讀)print("ID3決策樹結構:")pprint.pprint(id3_tree)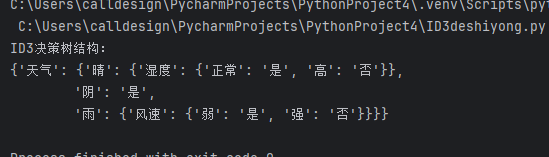
二、KL 散度(Kullback-Leibler Divergence)的計算與應用
KL 散度用于衡量兩個概率分布的差異,值越小表示分布越接近(非對稱度量)。
1. 數學定義
對于兩個離散概率分布?P(真實分布)和?Q(近似分布),KL 散度公式為:
![]()
import numpy as np
from scipy.stats import kl_div # scipy內置KL散度計算def manual_kl_divergence(p, q):"""手動計算KL散度(確保p和q是同維度的歸一化概率分布)"""# 過濾0概率(避免log(0)和除以0)p = p[p > 0]q = q[p > 0] # 只保留p有概率的位置q = np.clip(q, 1e-10, 1.0) # 防止q為0導致除零錯誤return np.sum(p * np.log(p / q))# 示例1:兩個相似分布的KL散度
p = np.array([0.4, 0.3, 0.3])
q_similar = np.array([0.35, 0.35, 0.3])
print("相似分布手動KL散度:", manual_kl_divergence(p, q_similar)) # 輸出:0.014...
print("相似分布scipy KL散度:", np.sum(kl_div(p, q_similar))) # 與手動計算一致(scipy返回每個元素的KL值,需求和)# 示例2:兩個差異大的分布的KL散度
q_different = np.array([0.1, 0.1, 0.8])
print("差異分布KL散度:", np.sum(kl_div(p, q_different))) # 輸出:0.396...(值更大)# 示例3:KL散度的非對稱性(P到Q與Q到P的散度不同)
print("D(P||Q):", np.sum(kl_div(p, q_similar)))
print("D(Q||P):", np.sum(kl_div(q_similar, p))) # 結果不同,體現非對稱性3. 應用場景
- 模型評估:衡量預測分布與真實分布的差異(如生成模型中,評估生成數據分布與真實數據分布的差距)。
- 分布對齊:在遷移學習中,用 KL 散度最小化源域與目標域的分布差異。
- 變分自編碼器(VAE):用 KL 散度約束潛在變量分布接近標準正態分布。
- 正則化:在半監督學習中,用 KL 散度限制模型對未標記數據的預測分布熵(如一致性正則化)。
?
?










Gemini Agent 使用指南)
)

 遠程登錄VirtualBox中的Ubuntu24.04,顯示圖形化(GUI)界面)


)


